分散式鏈路追蹤技術適⽤場景和技術核⼼思想
分散式鏈路追蹤技術適⽤場景(問題場景)
場景描述
為了⽀撐⽇益增⻓的龐⼤業務量,我們會使⽤微服務架構設計我們的系統,使得我們的系統不僅能夠通過叢集部署抵擋流量的衝擊,⼜能根據業務進⾏靈活的擴充套件。
那麼,在微服務架構下,⼀次請求少則經過三四次服務調⽤完成,多則跨越⼏⼗個甚⾄是上百個服務節點。那麼問題接踵⽽來:
1)如何動態展示服務的調⽤鏈路?(⽐如A服務調⽤了哪些其他的服務—依賴關係)
2)如何分析服務調⽤鏈路中的瓶頸節點並對其進⾏調優?(⽐如A—>B—>C,C服務處理時間特別⻓)
3)如何快速進⾏服務鏈路的故障發現?
這就是分散式鏈路追蹤技術存在的⽬的和意義
分散式鏈路追蹤技術
如果我們在⼀個請求的調⽤處理過程中,在各個鏈路節點都能夠記錄下⽇志,並最終將⽇志進⾏集中視覺化展示,那麼我們想監控調⽤鏈路中的⼀些指標就有希望了~~~⽐如,請求到達哪個服務範例?請求被處理的狀態怎樣?處理耗時怎樣?這些都能夠分析出來了…
分散式環境下基於這種想法實現的監控技術就是就是分散式鏈路追蹤(全鏈路追蹤)。
市場上的分散式鏈路追蹤⽅案
分散式鏈路追蹤技術已然成熟,產品也不少,國內外都有,⽐如
Spring Cloud Sleuth + Twitter Zipkin
阿⾥巴巴的「鷹眼」
⼤眾點評的「CAT」
美團的「Mtrace」
京東的「Hydra」
新浪的「Watchman」
另外還有最近也被提到很多的Apache Skywalking。
分散式鏈路追蹤技術核⼼思想
本質:記錄⽇志,作為⼀個完整的技術,分散式鏈路追蹤也有⾃⼰的理論和概念
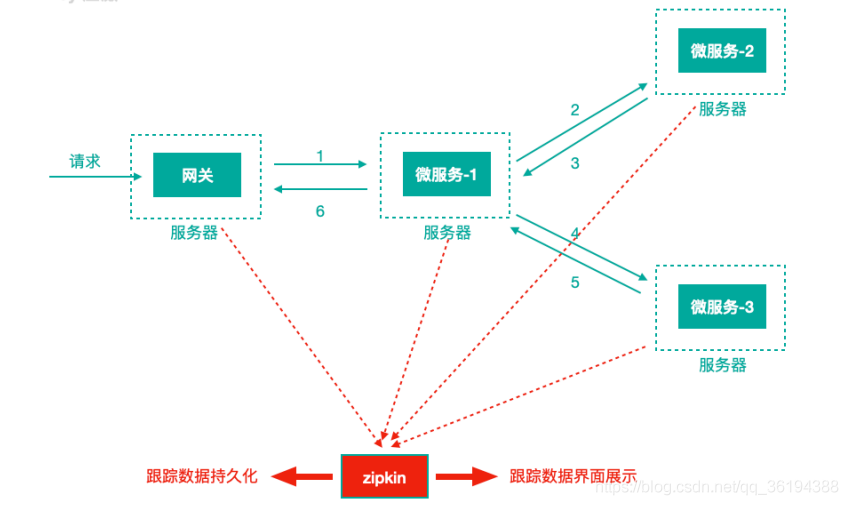
微服務架構中,針對請求處理的調⽤鏈可以展現為⼀棵樹,示意如下
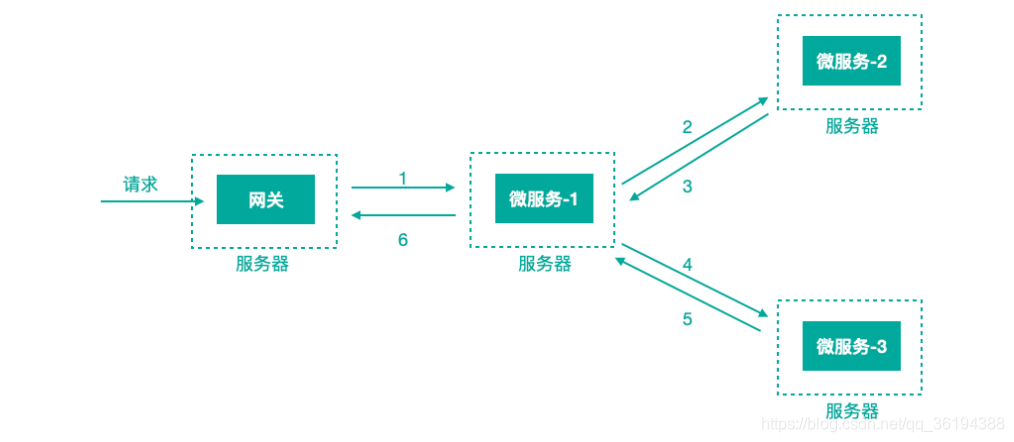
上圖描述了⼀個常⻅的調⽤場景,⼀個請求通過⽹關服務路由到下游的微服務-1,然後微服務-1調⽤微服務-2,拿到結果後再調⽤微服務-3,最後組合微服務-2和微服務-3的結果,通過⽹關返回給⽤戶
為了追蹤整個調⽤鏈路,肯定需要記錄⽇志,⽇志記錄是基礎,在此之上肯定有⼀些理論概念,當下主流的的分散式鏈路追蹤技術/系統所基於的理念都來⾃於Google的⼀篇論⽂《Dapper, a Large-ScaleDistributed Systems Tracing Infrastructure》,這⾥⾯涉及到的核⼼理念是什麼,我們來看下,還以前⾯的服務調⽤來說
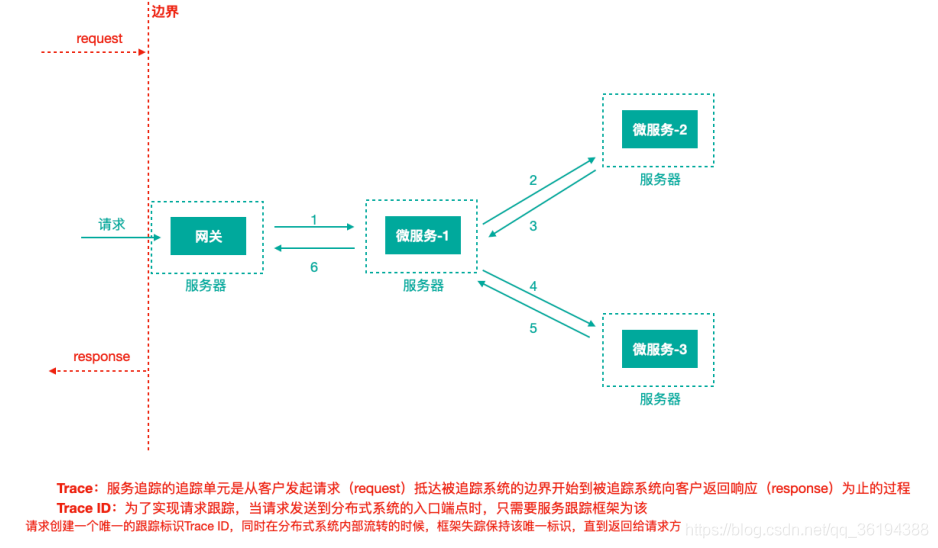
上圖示識⼀個請求鏈路,⼀條鏈路通過TraceId唯⼀標識,span標識發起的請求資訊,各span通過parrentId關聯起來
Trace:服務追蹤的追蹤單元是從客戶發起請求(request)抵達被追蹤系統的邊界開始,到被追蹤系統向客戶返回響應(response)為⽌的過程
Trace ID:為了實現請求跟蹤,當請求傳送到分散式系統的⼊⼝端點時,只需要服務跟蹤框架為該請求建立⼀個唯⼀的跟蹤標識Trace ID,同時在分散式系統內部流轉的時候,框架失蹤保持該唯⼀標識,直到返回給請求⽅⼀個Trace由⼀個或者多個Span組成,每⼀個Span都有⼀個SpanId,Span中會記錄TraceId,同時還有⼀個叫做ParentId,指向了另外⼀個Span的SpanId,表明⽗⼦關係,其實本質表達了依賴關係
Span ID:為了統計各處理單元的時間延遲,當請求到達各個服務元件時,也是通過⼀個唯⼀標識SpanID來標記它的開始,具體過程以及結束。對每⼀個Span來說,它必須有開始和結束兩個節點,通過記錄開始Span和結束Span的時間戳,就能統計出該Span的時間延遲,除了時間戳記錄之外,它還可以包含⼀些其他後設資料,⽐如時間名稱、請求資訊等
每⼀個Span都會有⼀個唯⼀跟蹤標識 Span ID,若⼲個有序的 span 就組成了⼀個 trace。
Span可以認為是⼀個⽇志資料結構,在⼀些特殊的時機點會記錄了⼀些⽇志資訊,⽐如有時間戳、spanId、TraceId,parentIde等,Span中也抽象出了另外⼀個概念,叫做事件,核⼼事件如下
CS :client send/start 使用者端/消費者發出⼀個請求,描述的是⼀個span開始
SR: server received/start 伺服器端/⽣產者接收請求 SR-CS屬於請求傳送的⽹絡延遲
SS: server send/finish 伺服器端/⽣產者傳送應答 SS-SR屬於伺服器端消耗時間
CR:client received/finished 使用者端/消費者接收應答 CR-SS表示回覆需要的時間(響應的⽹絡延遲)
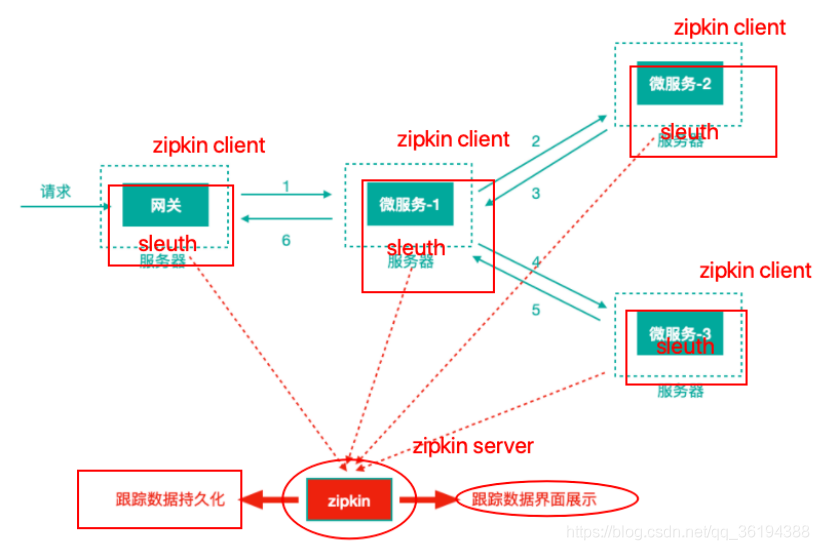
Spring Cloud Sleuth (追蹤服務架構)可以追蹤服務之間的調⽤,Sleuth可以記錄⼀個服務請求經過哪些服務、服務處理時⻓等,根據這些,我們能夠理清各微服務間的調⽤關係及進⾏問題追蹤分析。
**耗時分析:**通過 Sleuth 瞭解取樣請求的耗時,分析服務效能問題(哪些服務調⽤⽐較耗時)
**鏈路優化:**發現頻繁調⽤的服務,針對性優化等
Sleuth就是通過記錄⽇志的⽅式來記錄蹤跡資料的
注意:我們往往把Spring Cloud Sleuth 和 Zipkin ⼀起使⽤,把 Sleuth 的資料資訊傳送給 Zipkin 進⾏聚合,利⽤ Zipkin 儲存並展示資料。