Java中自動型別轉換溢位問題引發的探究
語言型別的強弱並沒有好壞之分
程式設計鼻祖C語言是有型別的語言,在C語言中的變數必須滿足:「在使用前定義,並確定型別」。在C語言之後的程式語言向著兩個方向發展:
- C++、Java為代表的強型別語言
更加強調型別,對型別的檢查比C語言更嚴格。 - JavaScript、Python、PHP為代表的弱型別語言
不看重型別,甚至不需要事先定義。
一般來說,面向底層的語言更加強調型別;而越是面向應用的語言會越忽視型別,而去重視事務邏輯的處理。
Java中所有的數值型別所佔據的位元組數量與平臺無關
C/C++中int和long等型別的大小與目標平臺相關,因為程式需要針對不同的處理器選擇最為高效的整型,例如,在32位元處理器上long值為4位元組;在64位元處理器上則為8位元組。這樣就有可能造成一個在64位元處理器上執行的很好的C程式在32位元處理器上執行卻發生整數溢位。這就為編寫跨平臺程式帶來了很大的難度。
而在Java中,所有的數值型別所佔據的位元組數量與平臺無關,即數值型別的範圍與執行Java程式碼的機器無關,這也是Java跨平臺的一個表現。
另外,Java中的int、long、short、byte型別都是有符號的。底層的二進位制形式中,首位如果是 0,就是正的;首位是1就是負的。另外,char則是0-65535的無符號數,從char轉換到int型別時,缺少的高16位元位元組用0擴充套件。
| Java - Type | 預設值 | 大小 | 取值範圍 |
|---|---|---|---|
| byte | 0 | 1位元組 | -128 - 127 |
| short | 0 | 2位元組 | -32768 - 32767 |
| int | 0 | 4位元組 | -2147483648 to 2147483647(21億多) |
| long | 0L | 8位元組 | -232-1 to (232-1-1) |
| float | 0.0f | 4位元組 | ±1.4E-45 to ±3.4028235E+38(有效位數為6~7位) |
| double | 0.0d | 8位元組 | ±4.9E-324 to ±1.7976931348623157E+308(有效位數為15位) |
| char | ‘\u0000’ | 2位元組 | 0-65535 |
| boolean | false | 取決於Java虛擬機器器 | true 或 false |
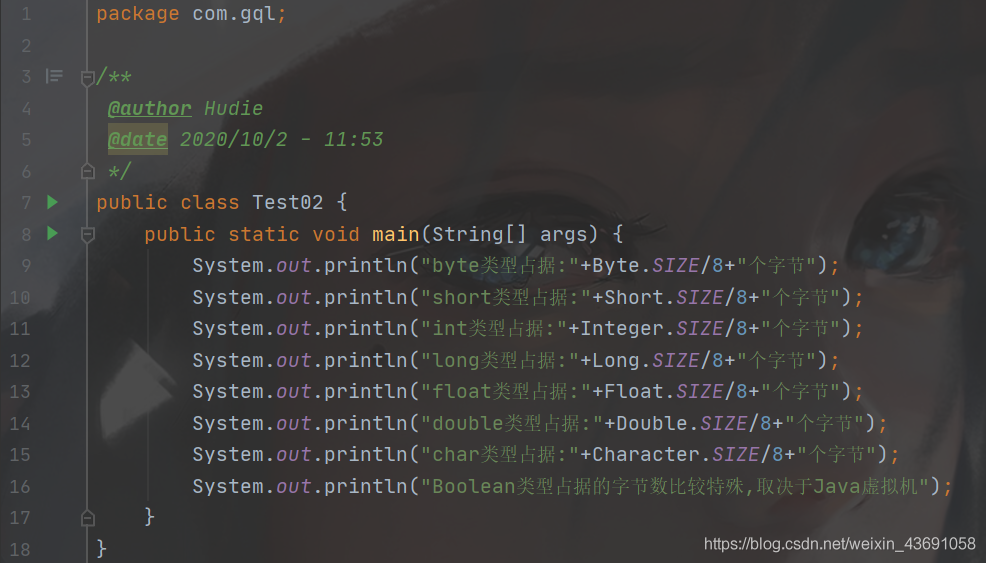
輸出如下:
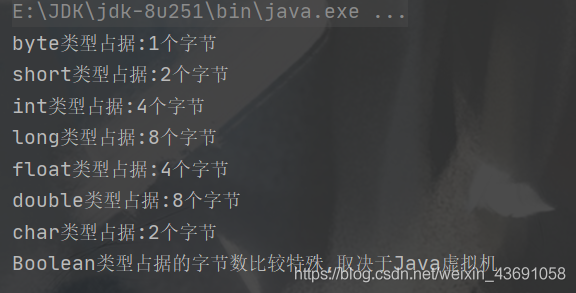
- 不同型別的變數在記憶體中的表現形式是不同的,整型變數在記憶體中表現為
2進位制數,浮點型變數在記憶體中表現為編碼形式。
資料型別之間的轉換
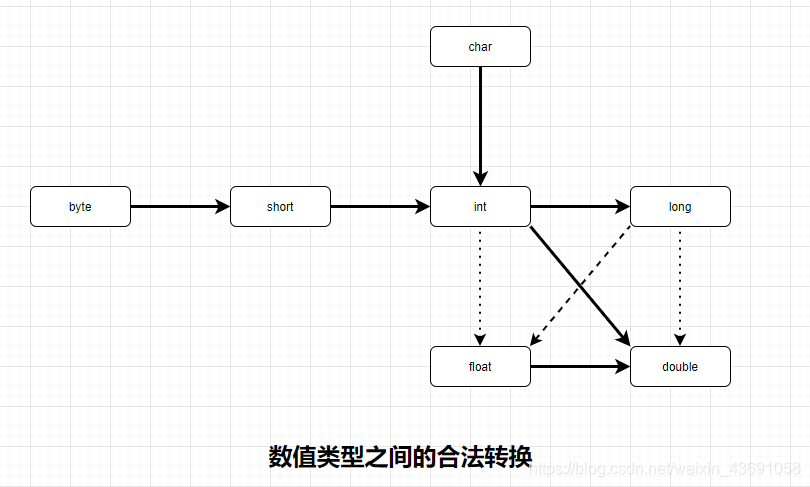
上圖中,6個實心箭頭的轉換表示無資訊丟失的轉換;3個虛箭頭的轉換表示可能有精度損失的轉換。如果兩個不同的數值型別進行二元操作時,先要將兩個運算元轉換為同一種型別,然後再進行計算,計算規則如下:
- 如果兩個運算元中,有一個是double型別,另一個運算元就會轉換為double型別。
- 否則,如果其中一個運算元是float型別,另一個運算元就會轉換為float型別。
- 否則,如果其中一個運算元是long型別,另一個運算元就會轉換為long型別。
- 否則,兩個運算元都將被轉換為int型別。
特別的:整型向字元型轉換時,JVM會把數位當成字元的ASCII編碼來處理。
//將整型型別強制轉換為字元型時,JVM會把數位當成字元的ASCII編碼來處理.
char i = (char)97;
System.out.println(i);//輸出:a
資料溢位問題
資料溢位問題就是:當某一種型別的數值已經達到了此型別能夠儲存的最大值之後,再繼續擴大,或者達到了最小值後再繼續縮小,就會出現資料溢位問題。
整型型別溢位
下面的程式碼以int型別為例,測試對int型別進行溢位測試:
package com.gql;
/**
int型別的溢位測試
@author Hudie
@date 2020/10/2 - 11:53
*/
public class Test {
public static void main(String[] args) {
//int型別的最小值為:-2^31
int a = -2147483648;
System.out.println("int型別的最小值為:"+a);
System.out.println("int型別的最小值減1為:"+(a-1));
System.out.println("int型別的最小值減2為:"+(a-2));
System.out.println("int型別的最小值減3為:"+(a-3));
System.out.println("int型別的最小值減4為:"+(a-4));
System.out.println("//總結:超過最小值的資料會向下溢位變成正數.\n");
//int型別的最大值為2^31 - 1
a = 2147483647;
System.out.println("int型別的最大值為:"+a);
System.out.println("int型別的最大值加1為:"+(a+1));
System.out.println("int型別的最大值加2為:"+(a+2));
System.out.println("int型別的最大值加3為:"+(a+3));
System.out.println("int型別的最大值加4為:"+(a+4));
System.out.println("總結:超過最大值的資料會向上溢位變成負數.\n");
}
}
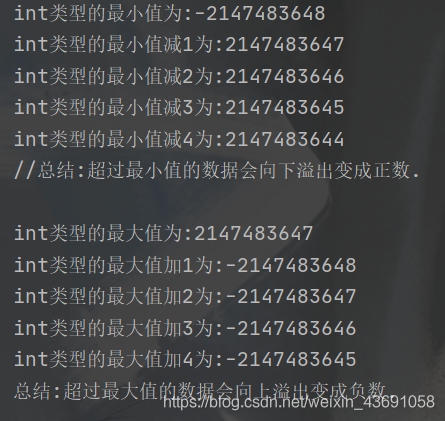
上面的程式碼符合了整型的資料溢位規則:即超過最大值的整型數值會向上溢位變成負數;超過最小值的整型數值會向下溢位變成正數。
前文提到過,Java中的int、long、short、byte型別都是有符號的。而在C/C++語言中,溢位規則分為兩種:
- 有符號的整型溢位:「undefined behavior」,即由編譯器實現,通常的編譯器都是按照上面測試的整型資料溢位規則。
- 無符號的整型溢位:溢位後的數會以2^(8*sizeof(type))作模運算
整型轉換為字元型的溢位
字元型資料在記憶體中一般情況下下佔據一個位元組(如今有些Unicode字元需要用兩個char來描述),其存放的就是這個字元對應的ASCLL碼的整數值,所以字元型資料和整型資料之間可以通用。
ASCCLL碼錶畢竟範圍有限,在轉換時也可能會出現字元型的溢位:
下面的程式碼演示整型向字元型轉換時出現的溢位情況。
int j = (char)0;
System.out.println(j);
j = (char)-1;
System.out.println(j);
j = (char)-2;
System.out.println(j);
j = (char)-3;
System.out.println(j);
System.out.println("總結:超過最小值的資料會向下溢位變成正數");
System.out.println("-------");
j = (char)65535;
System.out.println(j);
j = (char)65536;
System.out.println(j);
j = (char)65537;
System.out.println(j);
System.out.println("總結:超過最大值的資料會向下溢位仍變成正數(因為char型別的符號位永遠是0,即正數)");

可以發現整型轉換為字元型時的溢位規律:
- 當超過最小值的資料時會向下溢位,變成正數,所以直接取了char型別的最大值65535。
- 當超過最大值的資料時會向上溢位,由於字元型不能變成負數,所以直接取了最小值0。
- 可以將上面兩條概括理解為,超過最大值後,取最小值;超過最小值後,取最大值。