如何用Stata完成(shui)一篇經濟學論文(十二):描述性統計、迴歸與結果儲存
描述性統計
描述性統計的命令我一般使用summerize,用法為summerize加上你所想要總結的變數名稱,如果summerize後什麼都不加,則表示描述所有變數。
sysuse auto
* 表示描述性統計所有變數 *
summarize
* 表示描述統計mpg,weight兩個變數 *
summarize mpg weight
論文中資料部分一般要報告描述性統計和資料說明。描述性統計一報告均值、標準差、最大值、最小值,而資料說明則報告資料指標說明(可省略),單位及資料來源。有些論文會把兩個部分合在一起報告,也有的論文直接在正文裡報告資料來源,只放描述性統計的表。這個沒有統一標準。(表來源在最後)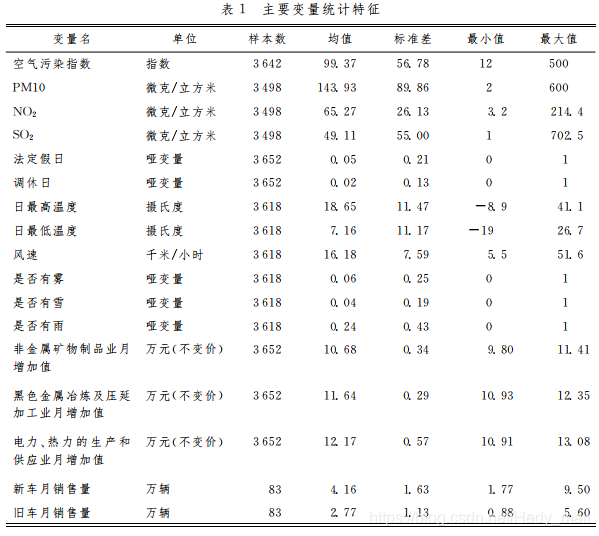
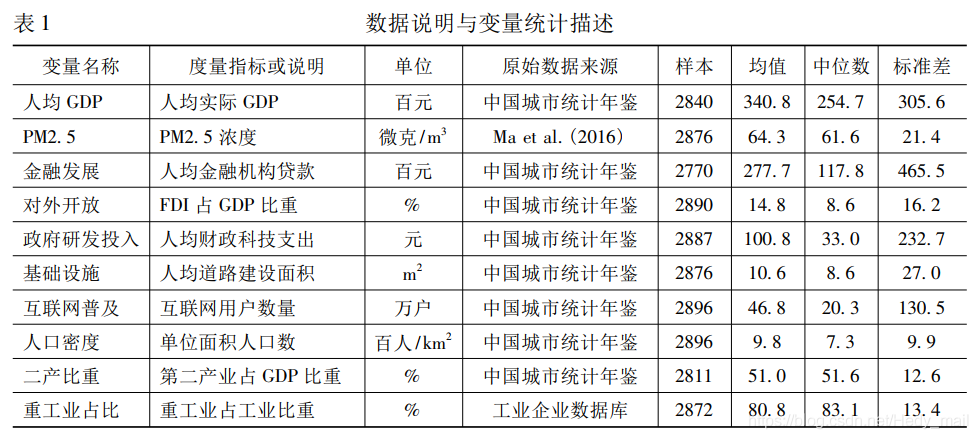
描述性統計的主要作用為確認資料是否準確,有無出現極端異常值,主要通過觀察:
1. 資料的最大最小值。 通過資料的最大最小值,結合資料本身的一些特性,我們可以初步判斷資料是否有問題,比如AQI設定的最大值為500,而且空氣汙染值一般不會出現0,如果資料中出現AQI超過500,或者等於0,就說明資料有問題。順帶提一句,因為AQI可能出現500「爆表」後濃度與資料不再成正比上升的現象,所以空氣汙染衡量一般輔以其他的幾個指標共同觀察。
2. 均值和標準差。 如果標準差>>均值,則資料中可能已經出現極端值和異常值,這時就要對資料進行其他的一些處理。具體可以參考經管之家上的資料預處理。
迴歸命令
迴歸我一般使用reg命令,關於隨機效應、固定效益、DID、RD之類的貌似有已經專門的命令,不過我還是習慣自己用reg這個最原始的命令寫:
* 基本命令 *
reg y x1 x2 x3
* 可以與if連用 *
reg y x1 x2 x3 if x3=0
另外reg後加","可以加上option選項,常用的有robust和vce(cluster variable)。
robust 表示考慮了異方差後對標準誤進行調整,一般適用於大樣本。從目前我的經驗來看,這個用用對迴歸顯著性不會有太大影響。
vce(cluster )是聚類標準誤,如果某個變數在一個層級上高度相關時,就要用聚類標準誤,具體參考這個討論。聚類標準誤會讓迴歸更不容易顯著(真的把我結果一下拉低了幾個檔次!),如果是投期刊一般會被審稿人要求使用,但如果大家是水論文,也就不一定要虐待自己了。
使用方法:
reg y x1 x2 x3,r
reg y x1 x2 x3, vce(cluster var)
結果儲存
把迴歸結果匯入到word,我用的asdoc命令,好處是匯出結果美觀,使用也簡單,壞處是,這個命令比較小眾,像outreg2的結果好像就可以直接導進latex(我沒試過),但如果你的論文全程word操作,也就影響不大。使用方法:
* 第一次使用前要下載 stata命令欄中直接輸入*
ssc install asdoc
* 具體命令 *
asdoc 你的命令, 相關選項
* 舉個例子 *
asdoc reg y x1 x2 x3, vce(cluster var) replace/append drop(x1 x2) cnames(regression1) dec(2) save(filename)
我們把選項具體來說明一下:
1.replace/append,使用replace意思是替換原有檔案(如果原來沒有就新建一個);append是在原有檔案裡繼續加回歸結果,但append不能在同一個word里加太多,加太多會出現Bug,所以建議大家還是多用replace, 多建立幾個檔案。
2. drop(),意思是匯出結果中不匯出這幾個變數的迴歸結果,像我經常會加城市或者時間固定效應的啞變數,這些啞變數的迴歸係數不重要,通常就會用drop(i.citycode i.date)把這些啞變數的結果省略掉。
3. cnames()是在匯出結果後,你的給這一列命的名字,會出現在迴歸列的上方。
4. dec()是保留幾位小數,這裡保留兩位。
5. save()是你儲存這個word迴歸檔案所使用的名字,像這裡把這個迴歸的word命名為filename。
迴歸結果用asdoc匯出後就長這樣:
這個命令不僅可以用來匯出迴歸,描述性統計的結果也可以這樣匯出,就用類似asdoc summarize var_list,dec(2)的命令,大家可以自己探索。
References
曹靜, 王鑫, 鍾笑寒. 限行政策是否改善了北京市的空氣品質?[J]. 經濟學 (季刊), 2014, 13(3): 1091-1126.
陳詩一,陳登科.霧霾汙染、政府治理與經濟高品質發展[J].經濟研究,2018,(2):20-34.
https://bbs.pinggu.org/thread-3651449-1-1.html