Rich feature hierarchies for accurate oject detection and semantic segmentation-RCNN詳細解讀
作者:中南大學視覺化實驗室 可解釋性機器學習專案組 18屆本科生研究員 WXY
日期:2020-9-18
論文期刊:2014-CVPR
標籤:RCNN 目標檢測
一、寫在前面的知識
選擇性搜尋
https://www.cnblogs.com/zyly/p/9259392.html
提取region proposal是目標檢測、目標跟蹤中的基本環節。
目標檢測的第一步是選擇更小的區域,然後利用演演算法去識別區域中物品的得分。
最直接的方法是滑動視窗,但是明顯這很耗時,因為區域的尺寸和位置是不一定的。
region proposal是更優秀的區域候選演演算法,它將影象輸入,輸出邊界框作為候選區域,它們大多與目標很接近,selective search是代表性演演算法。
selective search:通過顏色、紋理、形狀等特徵將原始影象分為等級區域(即將其分割)

但分割後後的圖片不能直接做目標檢測,因為大多數物體包含兩種以上的顏色(一個物體肯包含豐富的顏色資訊);如果物體有重疊,這種方法無法處理。
selective search的步驟:
- 根據前面的分割的圖片畫出多個框,把所有框放入region列表中
- 更具相似程度(顏色、紋理、形狀等),計算框的兩兩相似圖,把相似度放入另一個列表A
- 從A中找到相似度最大的框a,b,將它們合併
- 把合併的框加入region列表,從A中刪除和a,b相關的相似度,重複此過程,直到A為空。
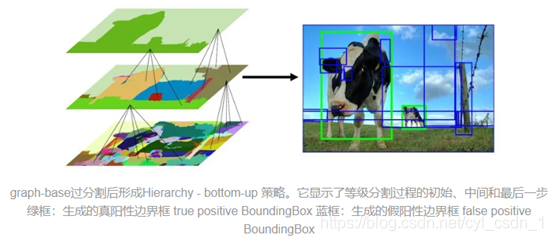
候選框的數量層數十萬降到幾千
解釋一下相似度:
顏色:每個顏色通道生成25-bin的直方圖,共75維
紋理:每個顏色通道使用高斯差分對8個方向計算提取紋理特徵,使用10-bin直方圖表示
尺寸:鼓勵尺寸小的區域合併
形狀相容相似度:兩區域重合比例程度
相似度是四個特徵的線性組合
BoundingBox迴歸
selective search得到的候選區可能與實際目標存在偏差
selective search選出紅色的框,ground truth是綠色框,飛機已經檢測出來,但是IoU<0.5導致識別失敗,觀察只需要對其進行線性變換(縮放、平移)就可以成功識別。
CNN輸出的特徵向量裡包含了資訊,所以在CNN輸出的特徵向量上做一個loss計算,調整原來框的位置(即縮放、平移操作)。
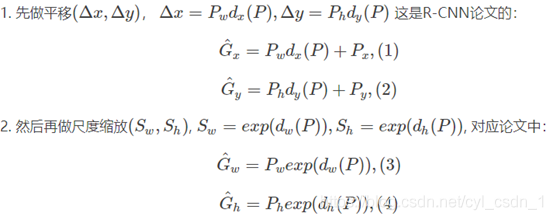
實際上這就是一個線性迴歸的過程,給定輸入的特徵向量X,學習一組引數W,使迴歸後的值與真實值Y非常接近,即 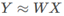
對每種類都設計邊界框迴歸,需要設計好的loss函數,那麼學習到的引數可以使loss收斂,就可對邊界框進行修正。
在實踐中,由於資料集不夠大,很少有人從頭開始訓練網路。常見的做法是使用預訓練的網路(例如在ImageNet上訓練的分類1000類的網路)來重新fine-tuning(也叫微調),或者當做特徵提取器。
以下是常見的兩類遷移學習場景:
1 折積網路當做特徵提取器。使用在ImageNet上預訓練的網路,去掉最後的全連線層,剩餘部分當做特徵提取器(例如AlexNet在最後分類器前,是4096維的特徵向量)。這樣提取的特徵叫做CNN codes。得到這樣的特徵後,可以使用線性分類器(Liner SVM、Softmax等)來分類影象。
2 Fine-tuning折積網路。替換掉網路的輸入層(資料),使用新的資料繼續訓練。Fine-tune時可以選擇fine-tune全部層或部分層。通常,前面的層提取的是影象的通用特徵(generic features)(例如邊緣檢測,色彩檢測),這些特徵對許多工都有用。後面的層提取的是與特定類別有關的特徵,因此fine-tune時常常只需要Fine-tuning後面的層。
預訓練模型
在ImageNet上訓練一個網路,即使使用多GPU也要花費很長時間。因此人們通常共用他們預訓練好的網路,這樣有利於其他人再去使用。例如,Caffe有預訓練好的網路地址Model Zoo。
何時以及如何Fine-tune
決定如何使用遷移學習的因素有很多,這是最重要的只有兩個:新資料集的大小、以及新資料和原資料集的相似程度。有一點一定記住:網路前幾層學到的是通用特徵,後面幾層學到的是與類別相關的特徵。這裡有使用的四個場景:
1、新資料集比較小且和原資料集相似。因為新資料集比較小,如果fine-tune可能會過擬合;又因為新舊資料集類似,我們期望他們高層特徵類似,可以使用預訓練網路當做特徵提取器,用提取的特徵訓練線性分類器。
2、新資料集大且和原資料集相似。因為新資料集足夠大,可以fine-tune整個網路。
3、新資料集小且和原資料集不相似。新資料集小,最好不要fine-tune,和原資料集不類似,最好也不使用高層特徵。這時可是使用前面層的特徵來訓練SVM分類器。
4、新資料集大且和原資料集不相似。因為新資料集足夠大,可以重新訓練。但是實踐中fine-tune預訓練模型還是有益的。新資料集足夠大,可以fine-tine整個網路。
實踐建議
預訓練模型的限制。使用預訓練模型,受限於其網路架構。例如,你不能隨意從預訓練模型取出折積層。但是因為引數共用,可以輸入任意大小影象;折積層和池化層對輸入資料大小沒有要求(只要步長stride fit),其輸出大小和屬於大小相關;全連線層對輸入大小沒有要求,輸出大小固定。
學習率。與重新訓練相比,fine-tune要使用更小的學習率。因為訓練好的網路模型權重已經平滑,我們不希望太快扭曲(distort)它們(尤其是當隨機初始化線性分類器來分類預訓練模型提取的特徵時)。
二、RCNN正式開始
目標識別:在給定影象中識別給定的物體,將整張影象輸入,輸出類別標籤並給出影象中物體出現的概率。
目標檢測:輸入影象,返回影象中包含的物體,還要對物體進行定位。
在RCNN之前基於PASCAL VOC資料集的目標檢測已經到達一個瓶頸期,之前的目標檢測大多基於SIFT和HOG來提取特徵,PASCAL VOC目標檢測發展很緩慢,每次只是對之前的系統進行很小的調整。當Alexnet出現後,人們又開始重視CNN,作者就是希望將通過CNN在目標分類和目標檢測之間構建橋樑。
這篇文章首次展現了CNN可以很大程度地提升基於PASCAL VOC的目標檢測能力,它展示了一個簡單可測量的目標檢測演演算法,在VOC 2012上將mAP(平均準確率)提升了30%,達到了53.3%。
兩個主要問題:在深層網路中定位目標、在帶標籤資料量不足時如何訓練高能力的網路
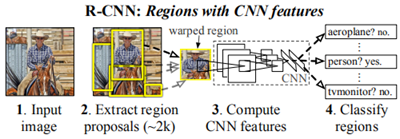
第一個問題:定位。第一種考慮是將其看做是一個迴歸問題,但是別人做出的結果只有30.5%的準確率,不夠優秀。第二種是考慮使用滑動視窗,之前滑動視窗已經在CNN中使用了20年了,用於檢測人臉和行人。但之前的網路都很簡單,只有兩層折積層,如果在深層的網路中使用(比如這裡的5層),後面的單元有很大的感受野195*195,這使得精確定位變成了不可實現的系統問題(同時滑動視窗會消耗過多時間)。作者使用的是「使用區域識別(recognition using regioins),它適合目標檢測與語意分割。總的來說,這種方法對輸入影象產生大約2000個對類獨立的區域建議,然後CNN會從每個區域建議中提取定長的特徵向量,然後將其輸入到類特定的線性SVM中。
第二個問題:帶標籤資料不足。作者使用了遷移學習中的微調(fine-tuning),首先在ILSVRC上進行有監督的預訓練,然後在PASCAL(較小的資料集)上進行微調。微調帶來的提升是顯著的,mAP上升了8%。
補充:作者使用了bounding-box regression,對降低錯誤定位率有顯著作用。
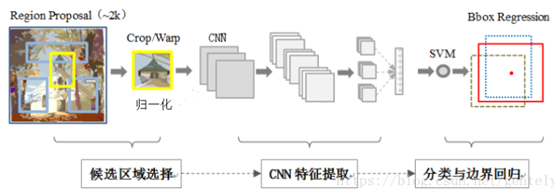
1. 使用RCNN進行目標檢測
目標檢測系統分為三個模組:產生類獨立的區域建議;一個大型CNN,從每個區域提取定長特徵向量;一組類特定的線性SVM
區域建議:使用了selective search演演算法
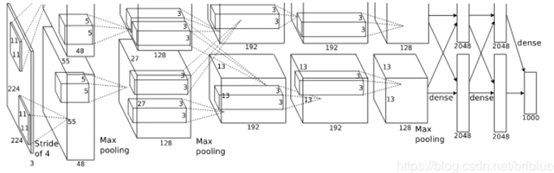
特徵提取:使用Caffe,CNN包括5個折積層和兩個全連線層,從每個區域建議中提取4096維的特徵向量。CNN的輸入必須是227*227大小,但是區域建議的大小是不固定的,作者採取了簡單的方法,直接將區域扭曲到需要的大小

2、訓練
有監督的預訓練:在大型輔助資料集ILSVRC2012上進行預訓練,僅使用影象基本的註釋,沒有box標記。預訓練得到的網路在ILSVRC2012上得到了2.2%的top-1錯誤率。
域特定的微調:為了使這個CNN能應用到目標檢測和新的域(扭曲後的區域建議),繼續在這個基礎上使用區域建議訓練。除了將原來的1000類的分類器替換為N+1類的分類器(N是目標類數,1是背景,對於VOC N為20),CNN的其他部分不變。對於與真實框的IoU大於0.5的結果認為是positive,其他是negative,隨機梯度下降的學習率是0.001,每次迭代中取樣32個積極視窗,96個背景視窗,mini-batch為128。
3、測試時的檢測:
在測試影象上使用selective search提取約2000個區域建議,將其扭曲後輸入CNN得到特徵,對每個類使用訓練得到的SVM對這個特徵進行評分。然後使用非極大抑制,如果一個區域與得分最高的區域的IoU大於一個閾值,就丟棄這個區域。
(簡單說一下什麼是IoU,非極大抑制)

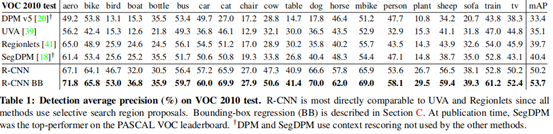
4. 在PASCAL VOC 2010-12的結果
檢測準確率超過其他模型,消耗的時間更少
5、 在ILSVRC2013檢測的結果
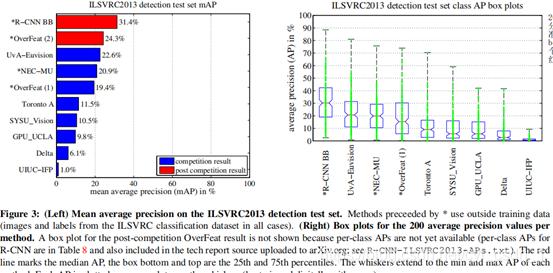
左邊是平均準確率,右邊是200個類的準確率的分佈,線的最高點是準確率最高的類,box的最高線是第25個,最低線是第75,紅線是中間值。
視覺化、消融學習、誤差模式
1、對特徵的視覺化
想法是選出一個unit(特徵圖),將它作為自己的目標檢測器。在一個大的區域建議集合上計算這個單元的啟用值,根據結果從大到小地對區域排序後,使用非最大抑制,然後展示得分最高的一些區域。
對第五層折積層經過池化後進行視覺化,選取其中6個單元,每個單元選了16個得分最高的。有些單元可以檢測目標,比如第一行檢測人,有些只能檢測紋理,比如第二行。
2、消融實驗:去掉一些特徵觀察影響
微調:
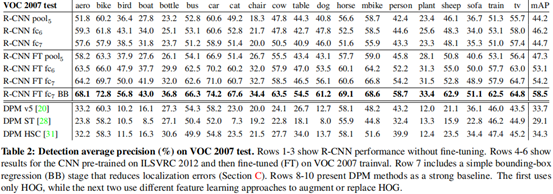
展示了不加FT與加FT的模型,在第五層折積層和後兩層全連線層的識別能力。
1.明確的是RCNN比之前的演演算法準確率高
2.不加FT的準確率低於加FT
3.如果不加FT甚至不如直接去掉全連線層,直接使用折積層輸出。
作者給出一個結論:CNN的分類能力來自於折積層,而不是全連線層,有時甚至可以直接不加全連線層。
Bounding-box Regression:帶來了3-4%的提升

ILSVRC2013檢測資料集
將資料集分為train, val, test三部分,val和test是詳細標記的(帶有bounding box標記),train訓練集來自ILSVRC2013分類影象集,不是詳細標記的。
訓練集會被用在CNN微調、SVM訓練、bounding-box迴歸訓練
對照實驗:
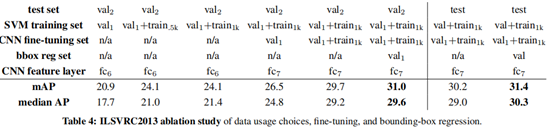
總結一下:RCNN是將CNN用到目標檢測的開端,相比以前的方法帶來了大幅度的效能提升(30%)。它的亮點是將regoin proposal與高效能的CNN結合來定位目標,以及通過微調等技巧在較少的資料集上得到較好的結果。
RCNN的缺點:需要事先提取多個候選區域對應的影象,佔用大量的磁碟空間;每個region proposal都需要進入CNN網路計算,導致多次重複的特徵提取;因為CNN的輸入時固定的,但之前說過會對候選區域進行扭曲,會帶來形變、過小、損失特徵等,這對CNN的特徵提取有致命的壞處。
Fast RCNN在資料輸入上不對其限制,加入了ROI Polling層,可以在任意大小的特徵對映上為每個輸入ROI區域提取固定的維度特徵表示,然後確保每個區域的後續分類可以正常執行。
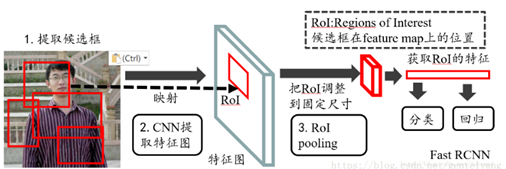
Faster RCNN:候選區生成、特徵提取、分類器分類、迴歸器迴歸都在神經網路中完成,執行都在GPU上,提高了效率。
對上文的一些修正
檢測過程(這部分沒問題,只是回顧):
輸入影象,使用SS演演算法提取約2000個區域
將每個區域扭曲後輸入CNN,對其輸出使用SVM為每個類打分,然後使用非極大抑制選擇更優的區域減少數量
輸入到bounding-box迴歸進行優化
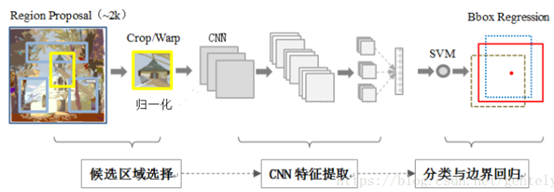
訓練過程(明確一下預訓練和微調的作用):
預訓練:
使用或訓練一個分類模型(如AlexNet,VGG),資料集是不充分標記的大型輔助資料集(沒有box標記),預訓練是在訓練識別能力,而不是預測位置的能力
微調:
將CNN的輸出層替換為所需大小的輸出層(N+1),從影象中提取區域,扭曲後輸入CNN進行訓練,將第五個折積層的池化輸出儲存到硬碟,使用這些資料訓練SVM,以及bounding-box迴歸。
也就是說,
預訓練只訓練CNN,微調的訓練過程是分段的,微調時訓練CNN、SVM、bounding-box regression是獨立進行的。所以上次說的同時訓練CNN和SVM是錯誤的,將多段學習合併為一段學習是Fast RCNN的改進點之一。
注:
學長的問題:用於學習的應該是整張打了標籤的圖片,裁剪的圖片的作用是什麼?
1)CNN的引數與微調是否有關?
是有關的,原文:為了使CNN適應新的任務(檢測)和新的域(扭曲的區域視窗),我們使用扭曲後的區域繼續對CNN的引數通過隨機梯度下降進行訓練。
微調訓練的部分:CNN、SVM、bounding-box regression,只不過有順序地分別進行
2)有爭議的標籤
訓練CNN:在劃分割區域後,如果某區域與真實框的IoU大於0.5將其認為是對應類的正例(positive),其餘是反例。在CNN的每次迭代中,從所有類的所有區域中取樣32個正例,96個反例組成128大小的mini-batch,使用這些資料進行訓練。所以訓練CNN的輸入時各個區域(region proposal),真實框(ground truth box)是來自原影象。(這個從所有類的區域進行取樣的方法被Fast RCNN稱為使用來自不同圖片的區域進行訓練對引數更新是高度低效的,但是還是會訓練CNN,FRCN對取樣方法進行了改進)
在訓練SVM進行分類前,還需要為資料打上標籤。只將真實框認為是每個類的正例,對於與一個類的所有範例的IoU小於0.3的proposal被標記為negative。作者設定了IoU=0.3的閾值,超過則表示可以被打上這個類的標籤(前面這部分打標籤的實際意義我不是特別明白,按我理解是在講正向傳播時候怎麼判斷一個區域是不是一個類,就是通過與真實框的IoU是否達到閾值來判斷)。核心問題是IoU是與誰相交,原文「正例被簡單定義為每個類的真實框(ground-truth bounding boxes)」,這種說法與前面提取區域後與真實框進行IoU比較的用詞相同(似乎這個問題被我做成了英文閱讀理解),這個真實框應該來自未分割的原圖,也就是說區域通過CNN得到特徵,與原圖的真實框進行IoU計算。
上面是前兩天的想法,今天看視訊時候又想到這個問題
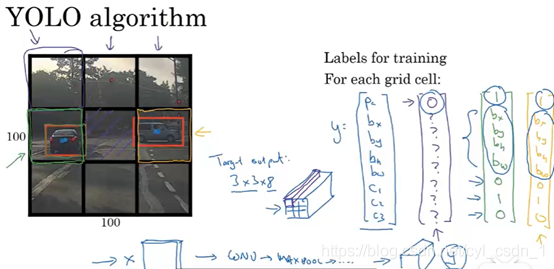
這張圖右邊是人工為每個柵格打好的標籤,8維,包含邊界框和目標分類的資訊,這都是已經做好的工作。我們做的是有監督的學習,所以輸入不光只有影象,還有真實值,也就是圖片裡的y矩陣,至於y矩陣是從原圖中來還是從每個區域中來,我覺得沒什麼區別,要擬合的東西實際上是y矩陣。那麼YOLO裡的柵格和RCNN的區域建議究竟起什麼作用,實際上在圖片生成的一堆區域和柵格中,包含我們需要的最好的一批可以很好地框住目標,我們將這些區域選出來,這些區域的位置也就成為了我們預測的位置,所以所有RCNN裡裁剪得到的區域和YOLO裡劃分的柵格就是目標位置的候選區域。(至於這些區域、柵格的不準確問題,讓他們通過bounding-box迴歸就能更好地描述位置。)因為真實值來自原影象,也就能解釋SVM和bounding-box到底向誰學習。