Going deeper with Convolutions-GoogLeNet Inception v1詳細解讀
作者: 18屆 CYL
日期: 2020-7-25
標籤: Inception GoogleNet 網路結構
論文期刊:2014年CVPR
一、寫在前面的話:若有差錯,歡迎指正
閒話區:
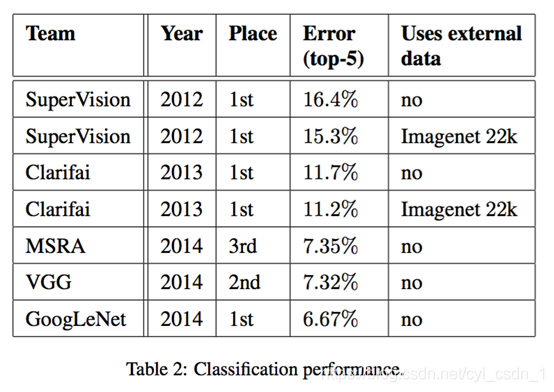
1、2014年GoogLeNet獲得ImageNet挑戰賽分類專案的第一名。(同年另一個大牛VGG網路獲得第二,但是由於引數過多,計算量太大導致VGG的光環相對來說要暗淡一些,由於後續優化較少,應用有限,後續我不再講解,其中的VGG的一個重要改進會應用在inception v2)
2、神經網路深度與正確率呈正相關(注意:正相關是指對正確率有效,並不是只要深度深正確率就會更高),在增加深度的時候要有數學依據:優化網路結構,層與層之間傳遞的有效性,折積核的大小,正則化選擇,歸一化選擇等等等等,如果可以解決過擬合和梯度彌散,引數爆炸等問題同時也有一個較好的網路結構,確實是層數越多正確率越好,如2015年的ResNet殘差神經網路解決了過深(上百層)帶來的一些問題,也取得了不錯的效果。(GoogLeNet為22層)
3、深度越深計算量一般會爆炸性增長如VGG,雖然可能正確率會相對較好(VGG正確率大於AlexNet),但是計算量過大會影響實時分析性,需要更多的訓練資料集還可能會有梯度彌散的問題,增加成本,從而深刻影響這個模型的實際應用。笨重的模型中絕對是有大量的無效引數,完全可以通過改善網路結構來提高層與層之間資料傳輸的有效性,實現在提高層數的同時順便還降低了計算量(VGG雖然引數量為GoogLeNet的36倍,但正確率卻不如GoogLeNet)。
4、在設計神經網路模型時不僅要考慮正確率也要考慮計算量,在沒有好方法去消除過深的網路帶來的梯度彌散問題時還要控制網路深度。本模型就是一個提出新的模型結構然後獲得巨大成功的典型例子。
5、相比於學習與瞭解整個GoogLeNet的網路架構,個人認為學習構建inception結構的思想更為重要。 GoogLeNet一開始為inception思想上的一種引數組合v1,後續陸續進行少量優化提出了inception v2、v3、v4網路結構。Inception與ResNet結合為inception-ResNet。Inception v3保留網路結構,更改網路組成形成xception,讓引數數量減少,計算效率提高。
6、本論文敘述了一個重要的待解決問題:提高神經網路的最直接方式是增加他的深度和寬度,而增加深度和寬度又會帶來引數爆炸,為了減少引數而引入稀疏性,即讓全連線層變為稀疏的全連線甚至是折積層(本模型中就將原來網路中總存在在最後幾層的全連線層砍掉,只留了一個全連線層方便用於分類),這一操作的理論來源是:由Arora等人已經證明了最優的神經網路結構是一個稀疏的大型結構,也就是說全連線層中很多引數都沒有必要,最優的網路結構可以通過分析前一層的啟用情況來構建後一層的網路結構。而稀疏的矩陣計算速度是非常慢的,這就又帶來了計算速度問題,而同時解決這兩個問題的方向是:一個可以結合折積層水平的稀疏性,又能利用密集矩陣計算來利用硬體的方法是將稀疏矩陣聚類為相對密集的子矩陣會有更加好的效能。在不久的將來可能可以自動構建非均勻的深度學習架構。
7、不同模型的正確率和引數大小(2017年統計圖)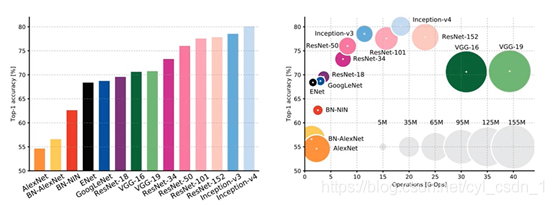
8、彩蛋:GoogLeNet的名字中L大寫是為了向LeNet致敬,論文題目來源是盜夢空間小李子的一句臺詞,GoogLeNet的另一個名字是inception(v1)名稱與盜夢空間英文名一致。
9、注1:以2014年論文going deeper with convolutions 介紹的inception網路結構為開端,並以inception中的一個特例GoogLeNet(inception v1)為基礎介紹其中在前兩次講解中沒出現過的重點技術和策略,然後陸續展開inception的優化方案V2、V3、V4.這時時間線已經到2017年。
二、Inception 的策略:(建議深度理解上述6,來逐步消化策略的)
1、大量應用11折積層bottleneck(這部分主要知道11折積操作是什麼,下面會用)
-
目的1:作為降維模組來移除折積瓶頸,提高網路深度,否則會限制網路大小
-
目的2:大大降低計算量
-
目的3:增加模型非線性表達能力
-
目的4:增加跨通道交流的作用
-
問題1:什麼是1*1折積層
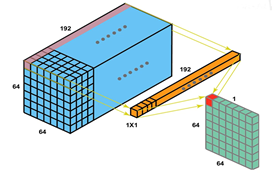
用一個與輸入的深度相同的11depth的折積核進行折積操作,讓折積後的特徵圖變為與輸入中的一層的大小相同。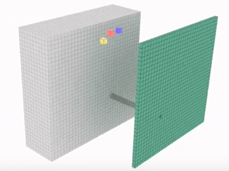

-
問題2:為什麼11折積層可以降維,提高網路深度
經過折積核操作從原來的6464192變為了6464*1顯然降維了 -
問題3:為什麼1*1折積層可以減少計算量,增加模型非線性表達能力,增加跨通道交流的作用
直觀的看,也很好理解。過!
思考:
提高網路效能的直接方式是增加他們的尺寸。這不僅包括增加深度(網路層次的數目)也包括他的寬度(每一層的單元數目)。但是更大的尺寸意味著更多的引數,是增大的網路容易過擬合,尤其是在訓練集的標註樣本有限的情況下。另一個缺點是計算資源使用的顯著增加。那麼如何適量增加網路深度而解決這兩個問題呢?(注:引數的絕大部分集中在全連線層)
2、 Inception 的基本結構是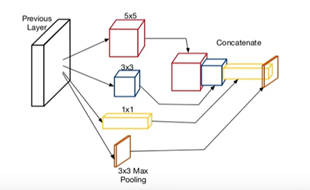
核心思想:近似實現折積神經網路的最優稀疏結構並用密集元件進行覆蓋,在設計網路的時候簡化為以折積構建塊為基礎。然後找到最優區域性結構來重複搭建。在設計區域性結構時假設較早層的每個單元對應輸入層的某些區域,並且這些單元被分成濾波器組。(我的理解是:不同大小的濾波器組相當於對稀疏矩陣有了一定的聚類效果)。在較低的層相關單元集中在區域性區域,那麼通過1*1折積覆蓋,就相當於將稀疏矩陣轉變為稠密矩陣。折積核的大小1 3 5 是基於方便性,而並沒有其他特殊的原因。(上述思想是期望該結構會有效果,inception也取得了正確性的巨大成功,但是否是由於網路結構而導致的正確率飆升,需要進一步的觀察。)
貼圖的小問題:這張圖上展示的折積核大小不一樣導致折積過後的模型不一樣,這點影象其實錯誤的,折積過後的大小都一樣才可以進行下一次的折積。
解釋:假如上圖輸入是11113影象。第一種折積核為553的,padding = 2 strip = 1那麼折積過後的影象大小為(11+22-5)/1+1 = 11 所以為11111的特徵影象 第二種折積核為333的,padding = 1,strip = 1 那麼折積過後的影象大小為(11+12-3)/1 +1=11 所以為11111的特徵影象,第三種折積核為113的折積核,padding = 0 strip = 1那麼為11111的特徵影象。(折積核的厚度預設與輸入一致)
我的不同理解:ZFNet對AlexNet的改進是將第一層1111的大折積核改成77來達到提升網路效能的目的,但是每一張圖片的第一層都用77這件事直觀的想,合理嗎?有的照片裡面人臉大,有的照片人臉小,同一張照片也有大特徵也有小特徵,但是每一層都用固定大小的折積核合適嗎?顯然不合適,那麼是不是可以每一層設定不同大小的折積核。這樣做會有什麼問題,又怎麼樣解決?
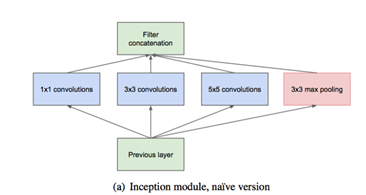
問題:如果採用這種結構,會讓網路中的每一層越來越厚,引數爆炸——max pooling的厚度與原模型大小一樣,再加上不定量的11,33,55 別提有多大了。解決方式如下:
3、 大量應用NIN(Network in Network)
- 好處1:控制網路中每一層的厚度,防止每一層的厚度爆炸。即:降維 具體解釋如:上述1
- 好處2:起初NIN是為了增加神經網路表現能力而提出的一種方法。在他們的模型中,網路中新增了額外的1*1折積層,增加網路的深度。
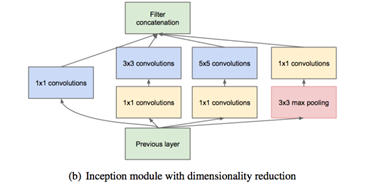
4、額外的並行池化層
整個網路是由上述的inception module堆疊形成的,其輸出濾波器組連線成單個輸出向量形成了下一階段的輸入。另外,由於池化操作對於目前折積網路的成功至關重要,,因此建議在每個這樣的階段新增一個替代的並行池化路徑,這個操作應該有額外的有益效果(此部分為論文翻譯)
5、整體網路結構
整個inception v1(GoogLeNet)是有上述模組相互堆疊組成的網路,偶爾會有步長為2的最大池化層將網路的解析度減半。
由於這些inception模組在彼此的頂部堆疊,其輸出相關統計必然有變化:由於較高層會捕獲較高的抽象特徵,其空間集中度預計會減少,這就意味著在更高層的時候33與55的比例應該會增加。
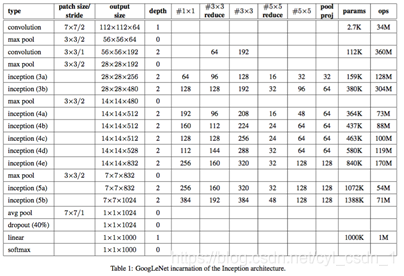
33reduce是在33折積之前降維層使用的1*1濾波器的數量
6、輔助分類器的使用
由於深度較大的網路,讓梯度下降反向傳播有效的通過所有層是一個問題。在這個任務上,通過在中間層引入輔助分類器來在一定程度上消除此問題。
- 問題1:輔助分類器是什麼?
實質是增加了正則化項(與L2正則化項相似,對誤差進行一定的修改) - 問題2:如何操作?
使用inception(4a)與inception(4b)模組的輸出,進行分類操作,然後將誤差乘上0.3加到整個網路的損失之上。(在推斷時,把這部分去掉就好)
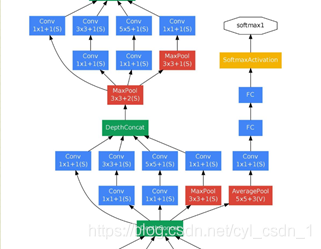
具體結構如下:
一個折積層55,步長為3的平均池化層
具有128個濾波器的11折積,用於降維和修正線性啟用
一個全連線層,具有1024個單元
Softmax的線性層作為分類器
7、最終網路結構
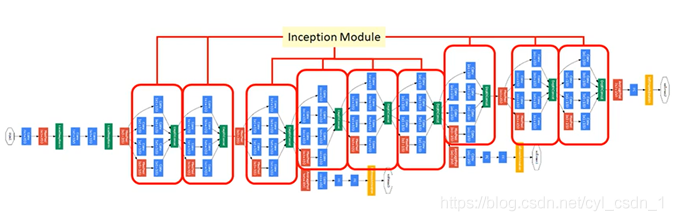
結果: