Opencv影象處理基礎
文章目錄
一、 圖片讀取
import matplotlib.pyplot as plt
import cv2
def main():
image = cv2.imread('1.jpg')
print('height:{} pixels'.format(image.shape[0])) # 第0行為高
print('width:{} pixels'.format(image.s hape[1])) # 第1行為寬
print('channels:{} pixels'.format(image.shape[2])) # 第2行為通道數
plt.imshow(image) # 讀入影象,進行處理
plt.axis('off')
plt.show()
if __name__ == '__main__':
main()

可以看到我們用 cv2.imread() 讀取的圖片和原圖顏色不一樣,原因在於 opencv 讀取的格式是 BGR 的格式,而 matplotlib 顯示的又是 RGB 的格式,所以根據程式碼中的變數image的畫素值以 RGB 格式顯示的和原圖有差別。
解決辦法: 把 R 和 B 的畫素點的值對換
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
二、 圖片切分
image = cv2.imread('2.jpg')
h, w, c = image.shape
lu = image[0:h//2, 0:w//2] # 切取左上部分圖片
ru = image[0:h//2, w//2:w] # 切取右上部分圖片
ld = image[h//2:h, 0:w//2] # 切取左下部分圖片
rd = image[h//2:h, w//2:w] # 切取右下部分圖片
三、 修改圖片
image[0:h//2, 0:w//2] = (0, 0, 255) # RGB,左上部分改成藍色
show(image)

四、 移動圖片
def show(image):
plt.imshow(image)
plt.axis('off')
plt.show()
def image_read(path):
image = cv2.imread(path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return image
def main():
image = image_read('1.jpg')
h, w = image.shape[:2]
# 水平方向向右平移250個畫素,豎直方向向上平移500個畫素
M = np.float32([[1,0,250],[0,1,500]])
shift_image = cv2.warpAffine(image, M, (w,h))
show(shift_image)

五、 旋轉圖片
image = image_read('1.jpg')
h, w = image.shape[:2]
cX, cY = w//2, h//2
# (cX,cY)表示旋轉中心點
# 45表示逆時針旋轉角度
# 0.5 表示縮放比例
M = cv2.getRotationMatrix2D((cX,cY), 45, 0.5)
image = cv2.warpAffine(image, M, (w,h))
show(image) # 自定義函數,見上面程式碼

六、 重塑圖片
image = image_read('1.jpg')
width = image.shape[1]
height = image.shape[0]
image = cv2.resize(image, (width//10, height//10)) # 將畫素點的數量變為原來的1/100
show(image)

很明顯,畫素點減少後,圖片變得很模糊
def detectFace():
image = image_read('huge.jpg')
detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
rects = detector.detectMultiScale(image, scaleFactor=1.1, minNeighbors=3, minSize=(10, 10),flags=cv2.CASCADE_SCALE_IMAGE)
# 畫出綠色的矩形框
for (x, y, w, h) in rects:
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
show(image)

haarcascade_frontalface_default.xml
七、 畫圖
畫線和矩形
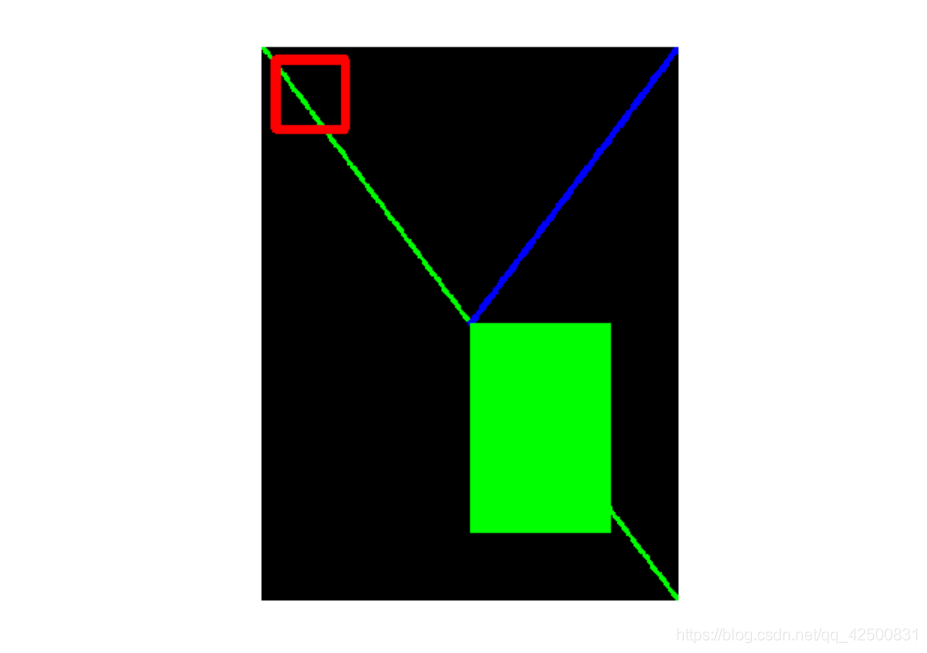
image = np.zeros((400, 300, 3), dtype='uint8') # 一張全黑圖片
w = image.shape[1]
h = image.shape[0]
cv2.line(image, (0, 0), (w, h), (0,255,0), 2) # 綠色線
cv2.line(image, (w, 0), (w//2, h//2), (0,0,255), 4) # 藍色線
cv2.rectangle(image, (10,10), (60,60), (255,0,0), 6) # 紅色矩形
cv2.rectangle(image, (w//2, h//2), (w-50, h-50), (0,255,0), -1) # 填充綠色
畫圓
image = np.zeros((400, 400, 3), dtype='uint8') # 一張全黑圖片
w = image.shape[1]
h = image.shape[0]
for r in range(0, w//2, 15):
color = np.random.randint(0,255,size=(3,)).tolist()
cv2.circle(image, (w//2, h//2), r, color, 2)
show(image)

填充
image = np.zeros((400, 400, 3), dtype='uint8') # 一張全黑圖片
w = image.shape[1]
h = image.shape[0]
for i in range(1, 10):
color = np.random.randint(0,255,size=(3,)).tolist() # 可以不是元組
center = tuple(np.random.randint(0,255,size=(2,))) # 必須是元組
radius = np.random.randint(5, 200) # 半徑隨機
cv2.circle(image, center, radius, color, -1) # 圓心 半徑 顏色 填充
show(image)

八、翻轉
image = cv2.flip(image, 1) # 1 表示水平翻轉
image = cv2.flip(image, 0) # 0 表示豎直翻轉
image = cv2.flip(image, -1) # -1 表示水平 + 垂直翻轉
九、 加減法
# 影象加法
print(cv2.add(np.uint8([200]), np.uint8([100]))) # 300超過255就顯示255
# 普通加法
print(np.uint8([200]) + np.uint8([100])) # 44 因為255 + 1 = 0
# 影象減法
print(cv2.subtract(np.uint8([100]), np.uint8([200]))) # -100小於0就顯示0
# 普通減法
print(np.uint8([100]) - np.uint8([200])) # 156 ,因為256-100 = 156
image = image_read('huge.jpg')
M = np.ones(image.shape, dtype='uint8')*100 # 生成和圖片形狀相同的並且全為100的資料
image = cv2.add(image, M) # 畫素值變大,偏白
image = cv2.subtract(image, M) # 畫素值變小,偏黑

十、位運算
rectangle = np.zeros((300, 300, 3), dtype='uint8')
cv2.rectangle(rectangle, (25,25), (275,275), (255,255,255), -1) # 左上 右下 顏色 填充
circle = np.zeros((300, 300, 3), dtype='uint8')
cv2.circle(circle, (150, 150), 150 , (255, 255, 255), -1) # 圓心 半徑 顏色 填充(線寬)

1. 與操作
image = cv2.bitwise_and(rectangle, circle) # 有0結果就是0,有黑就是黑

2. 或運算
image = cv2.bitwise_or(rectangle, circle) # 有1結果就是1,有白就是白

image = cv2.bitwise_xor(rectangle, circle) # 同0異1,白白或黑黑變黑,黑白變白

3. 取反
image = cv2.bitwise_not(circle)

4. 位運算對圖片進行遮擋
image = image_read('huge.jpg')
mask = np.zeros(image.shape, dtype='uint8')
white = (255,255,255)
cv2.circle(mask, (image.shape[1]//2, image.shape[0]//2-20), 100, white, -1) # 圓心,半徑,顏色,填充
# 對原始圖片進行遮擋
# 和白色區域與運算結果不變,和黑色區域與運算結果為黑色
masked = cv2.bitwise_and(image, mask)
show(masked)

十一、 切分合並通道
image = image_read('huge.jpg')
print(image.shape)
R, G, B = cv2.split(image) # 拿到三個通道的資料
print(R.shape, G.shape, B.shape) # shape和圖片大小一樣
cv2.imshow('R', R) # 單通道顯示,顯示的黑白顏色
cv2.imshow('G', G)
cv2.imshow('B', B)
merged = cv2.merge([R,G,B]) # 三個通道合併後就是原圖
show(merged) # 顯示原圖
十二、 影象金字塔
影象金字塔是影象多尺度表達的一種,是一種以多解析度來解釋影象的有效但概念簡單的結構。一幅影象的金字塔是一系列以金字塔形狀排列的解析度逐步降低,且來源於同一張原始圖的影象集合。我們將一層一層的影象比喻成金字塔,層級越高,則影象越小,解析度越低。
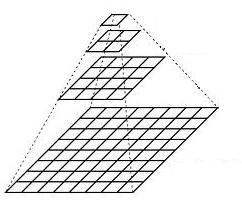
1. 高斯金字塔
高斯金字塔的頂部通過將底部影象中 連續的行和列去除 得到。頂部影象的每個畫素值相當於下一層影象中5個畫素的高斯加權平均值。操作一次就會將一個M*N 的影象變成一個M/2 * N/2的影象,影象面積變為原來的1/4。在python中我們通過函數 cv2.pyrDown() 和 cv2.pyrUp() 構建影象金字塔
cv2.pyrDown() 對影象的向下取樣操作,即縮小影象
-
對影象進行高斯核心折積,進行高斯模糊;
-
將所有偶數行和列去除。
cv2.pyrUp() 對影象的向上取樣,即放大影象
-
將影象在每個方向擴大為原來的兩倍,新增的行和列以0填充
-
使用先前同樣的核心(乘以4)與放大後的影象折積,獲得 「新增畫素」的近似值
image = image_read('huge.jpg')
print('原始大小:{}'.format(image.shape))
for i in range(4):
image = cv2.pyrDown(image)
print(image.shape)
show(image)


縮小為原圖的1/16 後,已經全部都是馬賽克了
十三、 腐蝕和膨脹
原理: 通過折積的方式,在原圖的小區域內取得區域性最小值,會使得一些黑色的點向外擴張。這個折積核也叫結構元素,結構元素可以是矩形、橢圓、十字形,可用 c v 2. g e t S t r u c t u r i n g E l e m e n t ( ) cv2.getStructuringElement() cv2.getStructuringElement() 生成不同形狀的結構元素(折積核)
# 矩形折積核
rec_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5,5))
# 橢圓折積核
ellipse_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5,5))
# 十字形折積核
cross_kernel = cv2.getStructuringElement(cv2.MORPH_CROSS, (5,5))
1. 利用腐蝕去除白色的點
image = image_read('night.jpg')
erosion = cv2.erode(image, rec_kernel)
show(erosion)

注: 由於折積核選取區域最小的畫素值形成新的圖片,畫素值減小了,整體顏色會偏暗,也會去除白色的點
2. 利用膨脹操作去除黑色的點
dilation = cv2.dilate(image, rec_kernel)
show(dilation)

注:因為膨脹操作是選取區域性畫素 最大的,故會把圖片整體變白,白色的點也會變成白色方塊
3. Gradient形態學梯度
膨脹圖 - 腐蝕圖,可提取物體輪廓
gradient = cv2.morphologyEx(image, cv2.MORPH_GRADIENT, rec_kernel)
show(gradient)

十四、開閉運算
1. 開運算
先腐蝕後膨脹,可去除圖片中的白點
opened = cv2.morphologyEx(image, cv2.MORPH_OPEN, rec_kernel)
2. 閉運算
先膨脹後腐蝕,可去除圖片中的黑點
closed = cv2.morphologyEx(image, cv2.MORPH_CLOSE, rec_kernel)
十五、 白帽和黑帽
1. 白帽
原圖 - 開運算,src - opened,可顯示被去掉的白色部分
whiteHat = cv2.morphologyEx(image, cv2.MORPH_TOPHAT, rec_kernel)
show(whiteHat)

2. 黑帽
閉運算 - 原圖,closed - src,可顯示被去掉的黑色部分
blackHat = cv2.morphologyEx(image, cv2.MORPH_BLACKHAT, rec_kernel)
show(blackHat)
十六、 影象平滑
1. 平均平滑
計算折積框覆蓋區域所有畫素的平均值得到折積的結果,此時的折積核為N*N的矩陣
image = image_read('lixian.jpg')
kernel_sizes = [(3,3), (9,9), (15,15)]
plt.figure(figsize=(15, 15))
for i, kernel in enumerate(kernel_sizes):
plt.subplot(1,3, i+1)
blur = cv2.blur(image, kernel) # 平均平滑,折積視窗越大,圖片越模糊
plt.axis('off')
plt.title('Blurred' + str(kernel))
plt.imshow(blur)
plt.show()

2. 高斯模糊
折積核內的值是符合高斯分佈的,方框中心的值最大,其餘方框根據距離中心的距離遞減,構成一個高斯小山包。原來的 求平均數 現在變成 求加權平均數,權就是方框裡的值
image = image_read('lixian.jpg')
kernel_sizes = [(3,3), (9,9), (15,15)]
plt.figure(figsize=(15, 15))
for i, kernel in enumerate(kernel_sizes):
plt.subplot(1,3, i+1)
blur = cv2.GaussianBlur(image, kernel, 0) # 0是標準差
plt.axis('off')
plt.title('Blurred' + str(kernel))
plt.imshow(blur)
plt.show()

3. 中值模糊
可對方框中的畫素點取中值,會使得顏色鮮明的點被周圍顏色的點 「同化」
image = image_read('night.jpg')
kernel_sizes = (3,9,15)
plt.figure(figsize=(15, 15))
for i, kernel in enumerate(kernel_sizes):
plt.subplot(1,3, i+1)
blur = cv2.medianBlur(image, kernel)
plt.axis('off')
plt.title('Blurred' + str(kernel))
plt.imshow(blur)
plt.show()

可以看到,當折積核比較大時,白色的點都被周圍的黑色 「同化」 了
4. 雙邊濾波
作用:能在保持邊界清晰的情況下有效去除噪音。
我們已經知道高斯濾波器是求中心點臨近區域畫素的 高斯加權平均值 。這種高斯濾波器 只考慮畫素之間的空間關係 ,而不會考慮畫素值之間的關係(畫素的相似度),故這種方法會導致 邊界模糊 ,而這不是我們想要的。
雙邊濾波同時使用 高斯加權平均值 和 灰度值相似性高斯權重
- 空間高斯函數確保只有臨近區域的畫素對中心點有影響
- 灰度值相似性高斯函數確保只有 與中心畫素灰度值相近的 才會用來做模糊運算
由於 邊界處灰度值變化比較大,所以這種方法不會使得邊界模糊。
image = image_read('man.jpg')
params = [(11,21,7), (11,41,21), (30,75,75)]
plt.figure(figsize=(15, 15))
# 鄰域直徑
# 灰度值相似性高斯函數標準差
# 空間高斯函數標準差
for i, (diameter, sigmaColor, sigmaSpace) in enumerate(params):
plt.subplot(1,3, i+1)
blur = cv2.bilateralFilter(image, diameter, sigmaColor, sigmaSpace)
plt.axis('off')
plt.title('Blurred' + str((diameter, sigmaColor, sigmaSpace)))
plt.imshow(blur)
plt.show()
十七、顏色空間轉換
1. RGB
image = image_read('lixian.jpg')
(R, G, B) = cv2.split(image)
zeros = np.zeros(image.shape[:2], dtype='uint8')
for i in range(3):
plt.subplot(1, 3, i + 1)
plt.axis('off')
if i == 0:
plt.imshow(cv2.merge([R, zeros, zeros]))
elif i == 1:
plt.imshow(cv2.merge([zeros, G, zeros]))
else:
plt.imshow(cv2.merge([zeros, zeros, B]))
plt.show()

十八、影象二值化
-
灰度值:影象灰度化就是讓畫素點矩陣中的每一個畫素點都滿足下面的關係:R=G=B,此時的這個值叫做 灰度值
-
灰度圖:灰度圖只有一個通道,有256個灰度等級,255代表全白,0表示全黑。在python中 彩色 圖片每個畫素點包含三個值(分別表示BGR三種顏色),而 灰度圖 每個畫素點只有一個值
-
二值化:就是讓影象的畫素點矩陣中的每個畫素點的灰度值為0(黑色)或者255(白色),也就是讓整個影象呈現只有黑和白的效果。在灰度化的影象中灰度值的範圍為0~255,在二值化後的影象中的灰度值範圍是0或者255
1. 二值化處理:
thresh, ret = cv2.threshold (src, thresh, maxval, type)
| 引數 | 含義 |
|---|---|
| thresh | 閾值,同形參 |
| ret | 處理後的圖片 |
| src | 源圖片,必須是單通道 |
| thresh | 閾值,取值範圍0~255 |
| maxval | 填充色,取值範圍0~255 |
| type | 閾值型別 |
| type | 含義 |
|---|---|
| THRESH_BINARY | 二進位制閾值化,非黑即白 |
| THRESH_BINARY_INV | 反二進位制閾值化,非白即黑 |
| THRESH_TRUNC | 截斷閾值化 ,大於閾值設為閾值 |
| THRESH_TOZERO | 閾值化為0 ,小於閾值設為0 |
| THRESH_TOZERO_INV | 反閾值化為0 ,大於閾值設為0 |
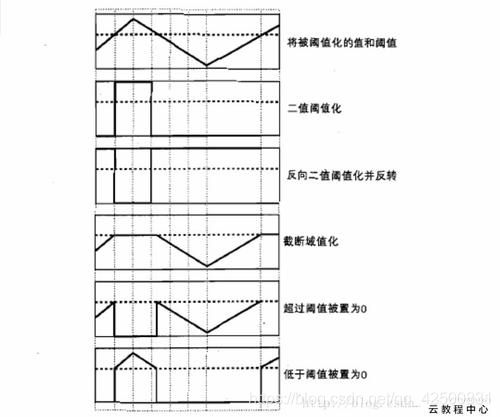
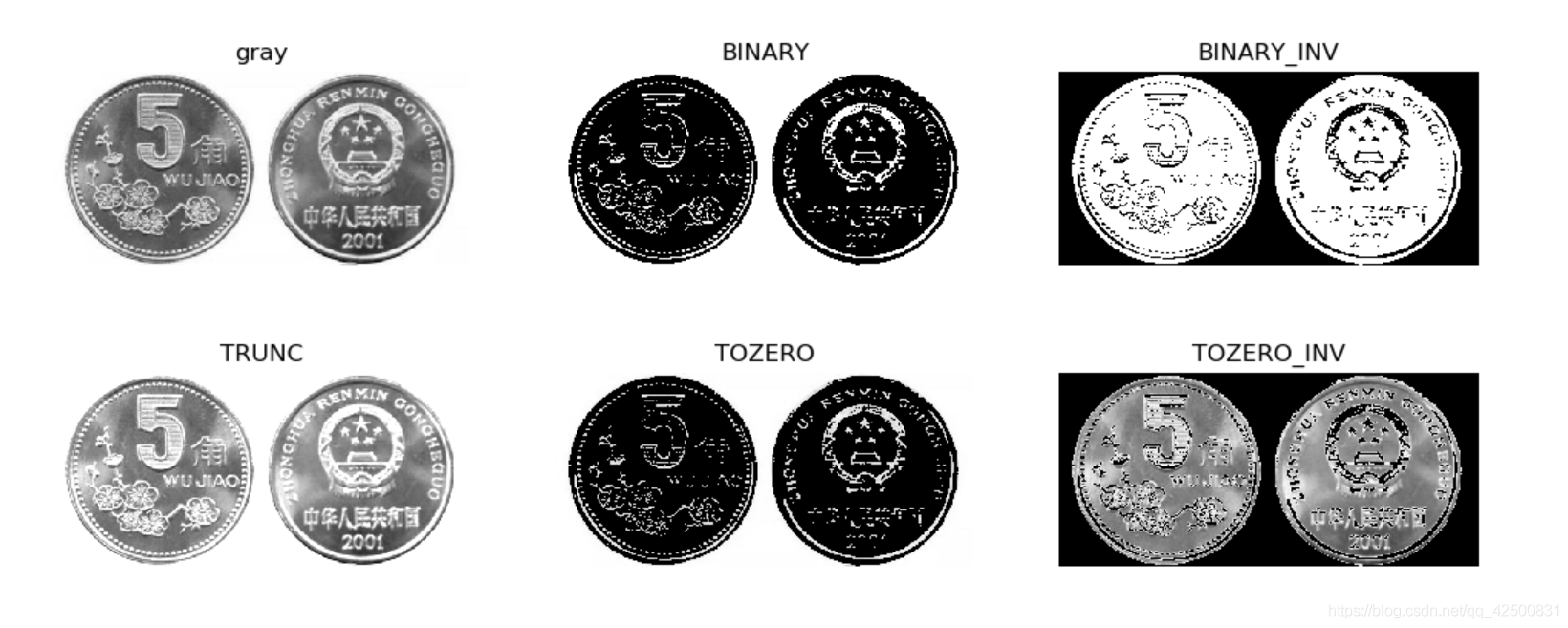
image = image_read('coin.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY) # 轉成灰度圖
thresh1, ret1 = cv2.threshold(gray, 200, 255, cv2.THRESH_BINARY) # 進行二值化,127為閾值,255為最大值
thresh2, ret2 = cv2.threshold(gray, 200, 255, cv2.THRESH_BINARY_INV) # ret為圖片處理的結果,thresh為閾值
thresh3, ret3 = cv2.threshold(gray, 200, 255, cv2.THRESH_TRUNC)
thresh4, ret4 = cv2.threshold(gray, 200, 255, cv2.THRESH_TOZERO)
thresh5, ret5 = cv2.threshold(gray, 200, 255, cv2.THRESH_TOZERO_INV)
titles = ['gray', 'BINARY', 'BINARY_INV', 'TRUNC','TOZERO','TOZERO_INV']
images = [gray, ret1, ret2, ret3, ret4, ret5]
plt.figure(figsize=(15, 5))
for i in range(len(images)):
plt.subplot(2,3,i+1)
plt.imshow(images[i], 'gray')
plt.axis('off')
plt.title(titles[i])
plt.show()
2. 自適應閾值
thresh1, ret1 = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU) # 進行二值化,127為閾值,255為最大值
thresh2, ret2 = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)

3. 不同區域選取不同閾值
dst = cv2.adaptiveThreshold(src, maxval, thresh_type, type, BlockSize, C)
| 引數 | 含義 |
|---|---|
| dst | 輸出圖 |
| src | 輸入圖,只能輸入單通道影象,通常來說為灰度圖 |
| maxval | 當畫素值超過了閾值(或者小於閾值,根據type來決定),所賦予的值 |
| thresh_type | 閾值的計算方法,包含以下2種型別:cv2.ADAPTIVE_THRESH_MEAN_C; cv2.ADAPTIVE_THRESH_GAUSSIAN_C |
| type | 二值化操作的型別,與固定閾值函數相同,包含以下5種型別: cv2.THRESH_BINARY; cv2.THRESH_BINARY_INV; cv2.THRESH_TRUNC; cv2.THRESH_TOZERO;cv2.THRESH_TOZERO_INV. |
| BlockSize | 鄰域大小,用於計算閾值區域的大小 |
| C | 是一個常數,計算公式為【閾值 = 平均值(加權平均值)- C】 |
image = image_read('license.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY) # 轉成灰度圖
_, ret1 = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY) # 普通二值化
ret2 = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 3) # 閾值取自相鄰區域的平均值
ret3 = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 3) # 閾值取自相鄰區域的加權和,權重為一個高斯視窗
titles = ['Origin', 'Global Threshold', 'Adaptive Mean Threshold', 'Adaptive Gaussian Threshold']
images = [gray, ret1, ret2, ret3]
plt.figure(figsize=(15, 5))
for i in range(len(images)):
plt.subplot(2,2,i+1)
plt.imshow(images[i], 'gray')
plt.axis('off')
plt.title(titles[i])
plt.show()

注:
- 原圖中由於左側較亮,畫素值較大,普通二值化時直接將畫素點的值置為255,故沒有保留下來
- 而自適應閾值可以根據圖片不同區域的亮度,對每個區域選取不同的閾值
十九、Canny邊緣檢測
-
噪聲去除:我們知道梯度運算元可以用於增強影象,本質上是通過增強邊緣輪廓來實現的,也就是說是可以檢測到邊緣的。但是,它們受噪聲的影響都很大。那麼,我們第一步要先去除噪聲,因為噪聲就是灰度變化很大的地方,所以容易被識別為偽邊緣
-
計算影象梯度:計算影象梯度能夠得到影象的邊緣,因為梯度是灰度變化明顯的地方,而邊緣也是灰度變化明顯的地方。當然這一步只能得到可能的邊緣。因為灰度變化的地方可能是邊緣,也可能不是邊緣。這一步就有了所有可能是邊緣的集合。
-
非極大值抑制:非極大值抑制。通常灰度變化的地方都比較集中,將區域性範圍內的梯度方向上,灰度變化最大的保留下來,其它的不保留,這樣可以剔除掉一大部分的點。將有多個畫素寬的邊緣變成一個單畫素寬的邊緣。即「胖邊緣」變成「瘦邊緣」。如下所示:
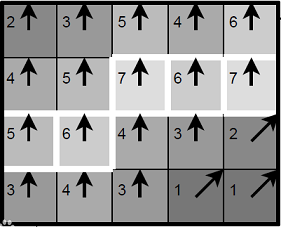
上圖中的數位代表了畫素點的梯度強度,箭頭方向代表了梯度方向。以第二排第三個畫素點為例,由於梯度方向向上,則將這一點的強度(7)與其上下兩個畫素點的強度(5和4)比較,由於這一點強度最大,則保留。 -
雙閾值篩選:通過非極大值抑制後,仍然有很多的可能邊緣點,進一步的設定一個雙閾值,即低閾值(minVal),高閾值(maxVal)。灰度變化大於maxVal的,設定為強邊緣畫素,低於minVal的,剔除。在minVal和maxVal之間的設定為弱邊緣。進一步判斷,如果其領域內有強邊緣畫素,保留,如果沒有,剔除。
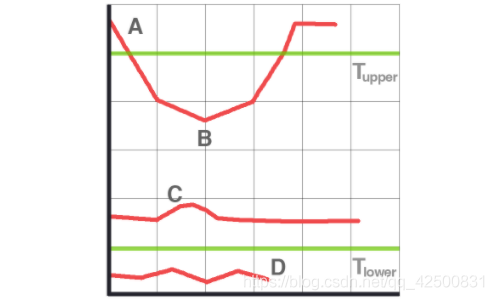
- A 高於閾值 maxVal 所以是真正的邊界點
- B 雖然低於 maxVal 但高於minVal 並且與 A 相連,所以也被認為是真正的邊界點
- C 就會被拋棄,因為他不僅低於 maxVal 而且不與真正的邊界點相連
- D 也會被拋棄,因為低於minVal
所以選擇合適的 maxVal和 minVal 對於能否得到好的結果非常重要。在這一步一些小的噪聲點也會被除去,因為我們假設邊界都是一些長的線段。
image = image_read('coin.jpg')
image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
image = cv2.GaussianBlur(image, (3, 3), 0)
Value = [(10, 150), (100, 200), (180, 230)]
plt.figure(figsize=(20, 5))
for i, (minVal, maxVal) in enumerate(Value):
plt.subplot(1, 3, i + 1)
edges = cv2.Canny(image, minVal, maxVal)
edges = cv2.GaussianBlur(edges, (3, 3), 0) # 折積核 標準差
plt.imshow(edges, 'gray')
plt.title('maxVal={}\nminVal={}'.format(maxVal, minVal))
plt.axis('off')
plt.show()

二十、讀取攝像頭資料
- cap.read() 返回一個布林值(True/False)。如果幀讀取的是正確的,就是 True。所以最後你可以通過檢查他的返回值來檢視視訊檔是否已經到了結尾。有時 cap 可能不能成功的初始化攝像頭裝置。這種情況下上面的程式碼會報錯
- cap.isOpened(),來檢查是否成功初始化了。如果返回值是True,那就沒有問題
- cap.get(propId) 來獲得視訊的一些引數資訊,這裡propId 可以是 0 到 18 之間的任何整數。每一個數代表視訊的一個屬性
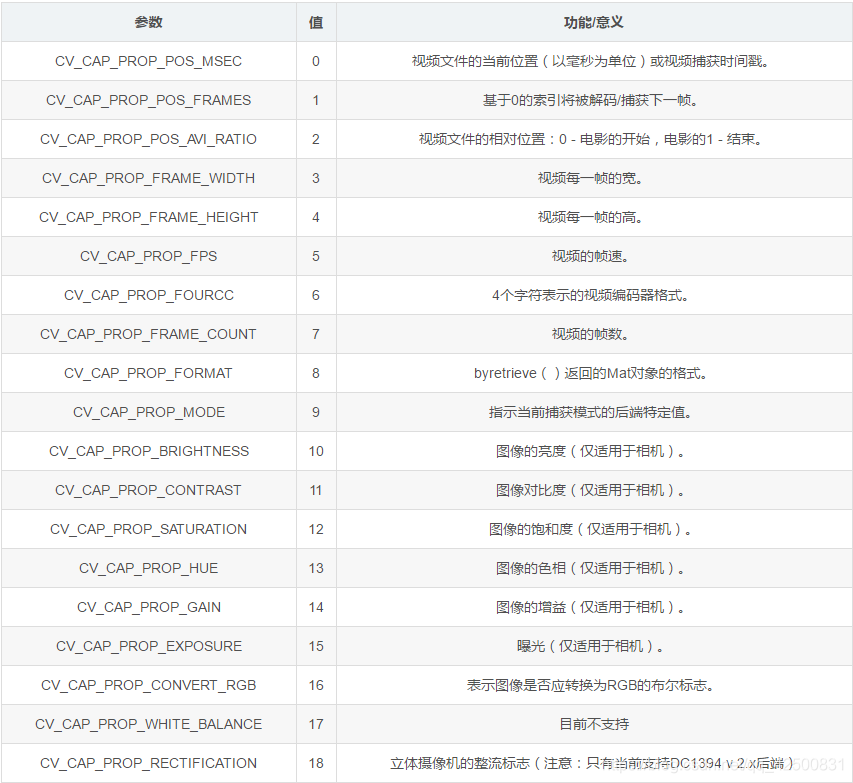
其中的一些值可以使用 cap.set(propId,value) 來修改, value 就是你想要設定成的新值
例如,我可以使用 cap.get(3) 和 cap.get(4) 來檢視每一幀的寬和高。預設情況下得到的值是 640X480。但是我們可以使用 ret=cap.set(3,320)和 ret=cap.set(4,240) 來把寬和高改成 320X240
# 從攝像頭獲取影象資料
cap = cv2.VideoCapture(0)
# 檢視是否成功獲取攝像頭
if not cap.isOpened():
exit('there is no camera exists')
while (True):
# ret 讀取成功True或失敗False
# frame讀取到的影象的內容
# 讀取一幀資料
ret, frame = cap.read()
# 將讀取的該幀轉為灰度圖
# gray = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', frame)
# waitKey功能是不斷重新整理影象,單位ms,返回值是當前鍵盤按鍵值
# ord返回對應的ASCII數值
if cv2.waitKey(1) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
二十一、讀取視訊檔
# 從檔案讀取視訊內容
cap = cv2.VideoCapture('cats.mp4')
# 視訊每秒傳輸幀數
fps = cap.get(cv2.CAP_PROP_FPS)
# 視訊影象的寬度,get返回float型別
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
# 視訊影象的長度
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
while (True):
# ret 讀取成功True或失敗False
# frame讀取到的影象的內容
# 讀取一幀資料
ret, frame = cap.read()
if ret != True:
break
cv2.imshow('frame', frame)
# waitKey功能是不斷重新整理影象,單位ms,返回值是當前鍵盤按鍵值
# 如果waitkey的用於掩飾的引數太小,會導致視訊播放的很快,因為程式讀取一幀影象很快
# ord返回對應的ASCII數值
if cv2.waitKey(25) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
二十二、視訊寫入
我們要建立一個 VideoWriter 的物件,應該確定一個輸出檔案的名字。接下來指定 FourCC 編碼、播放頻率、幀的大小
FourCC 就是一個 4 位元組碼,用來確定視訊的編碼格式。可用的編碼一般為:DIVX, XVID, MJPG, X264, WMV1, WMV2
主要操作:讀取一幀,翻轉一幀,寫入一幀
# 從檔案讀取視訊內容
cap = cv2.VideoCapture('cats.mp4')
# 視訊每秒傳輸幀數
fps = cap.get(cv2.CAP_PROP_FPS)
# 視訊影象的寬度
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
# 視訊影象的長度
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 寫入視訊的編碼方式
fourcc = cv2.VideoWriter_fourcc(*'XVID')
# 設定寫入視訊的編碼、每秒幀數、每一幀的長寬,返回寫入物件
out = cv2.VideoWriter('output.avi', fourcc, fps, (frame_width, frame_height))
while True:
ret, frame = cap.read()
if ret is True:
# 0:豎直翻轉,1:水平翻轉,-1:表示水平 + 垂直翻轉
frame = cv2.flip(frame, 0)
out.write(frame)
cv2.imshow('frame', frame)
if cv2.waitKey(1) == ord('q'):
break
else:
break
out.release()
cap.release()
cv2.destroyAllWindows()
這樣我們就完成了一個視訊的豎直翻轉