Python爬蟲 帶你一鍵爬取王者榮耀英雄面板桌布
2020-10-03 11:00:01
一、前言
王者榮耀這款手遊,想必大家都玩過或聽過,遊戲裡英雄有各式各樣的面板,製作得很精美,有些拿來做電腦桌布它不香嗎。本文帶你利用Python爬蟲一鍵下載王者榮耀英雄面板桌布。
1. 目標
建立一個資料夾, 裡面又有按英雄名稱分的子資料夾儲存該英雄的所有面板圖片
URL:https://pvp.qq.com/web201605/herolist.shtml
2. 環境
執行環境:Pycharm、Python3.7
需要的庫
import requests
import os
import json
from lxml import etree
from fake_useragent import UserAgent
import logging
二、分析網頁
首先開啟王者榮耀官網,點選英雄資料進去。
進入新的頁面後,任意選擇一個英雄,檢查網頁。
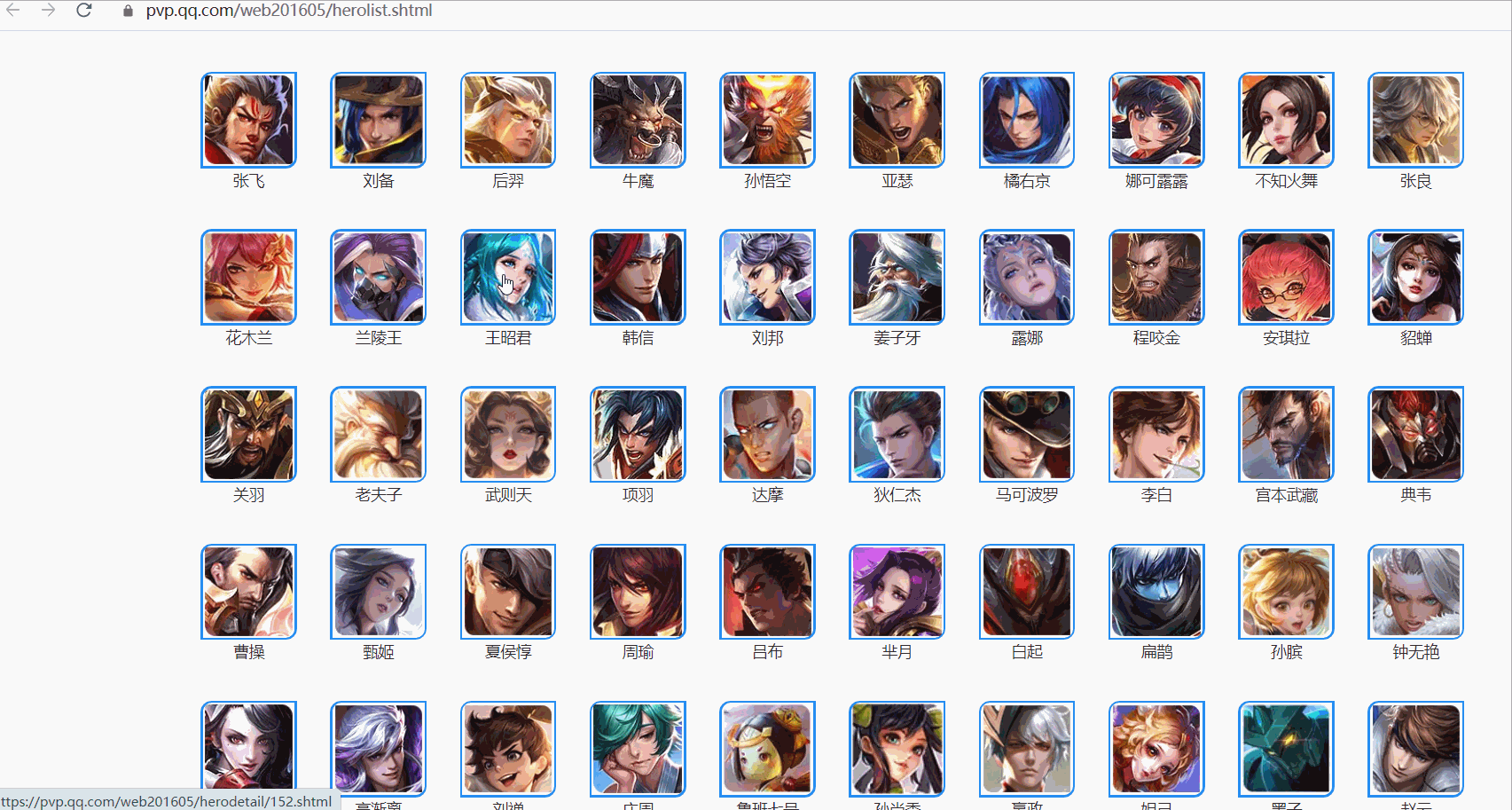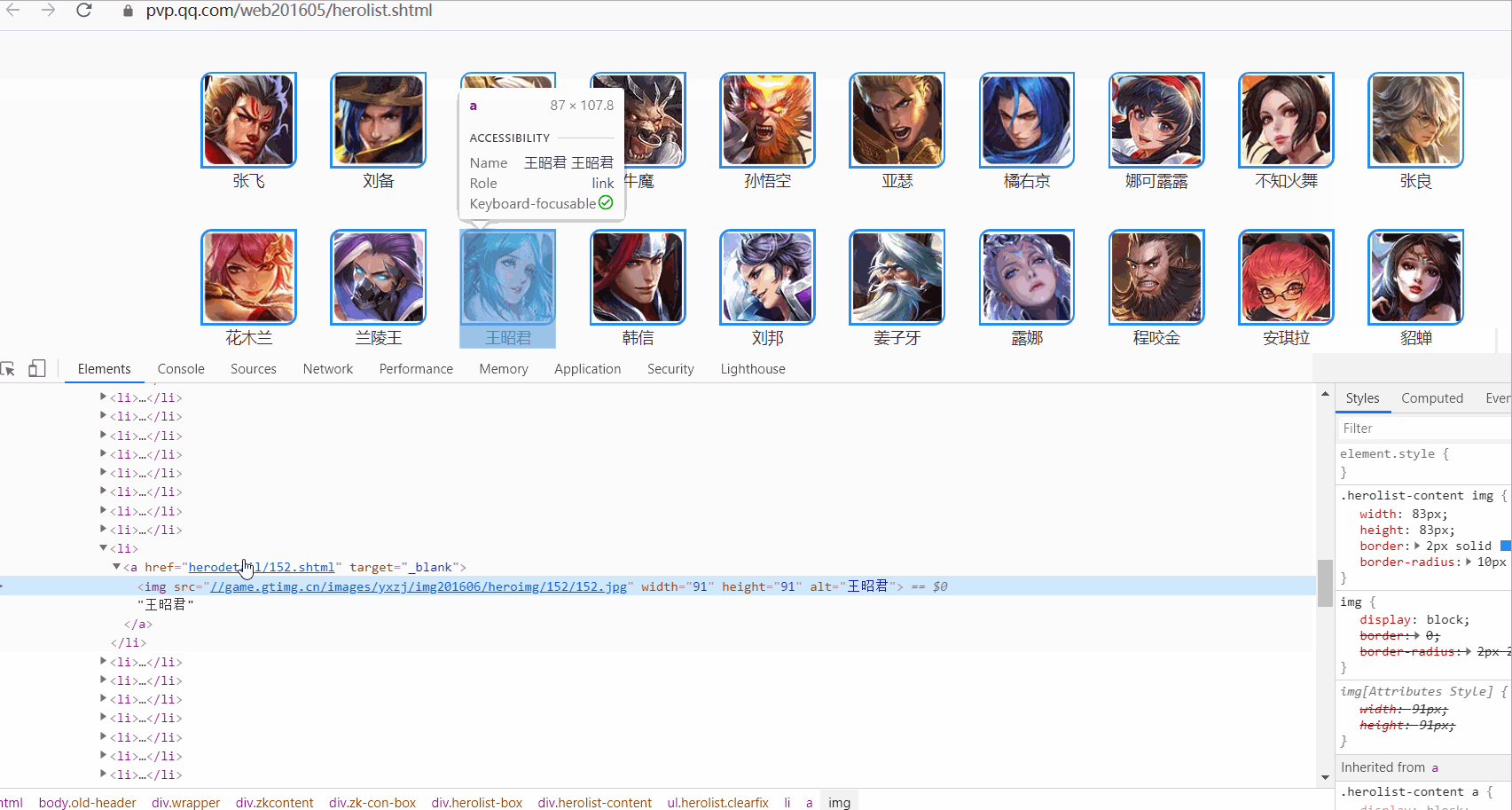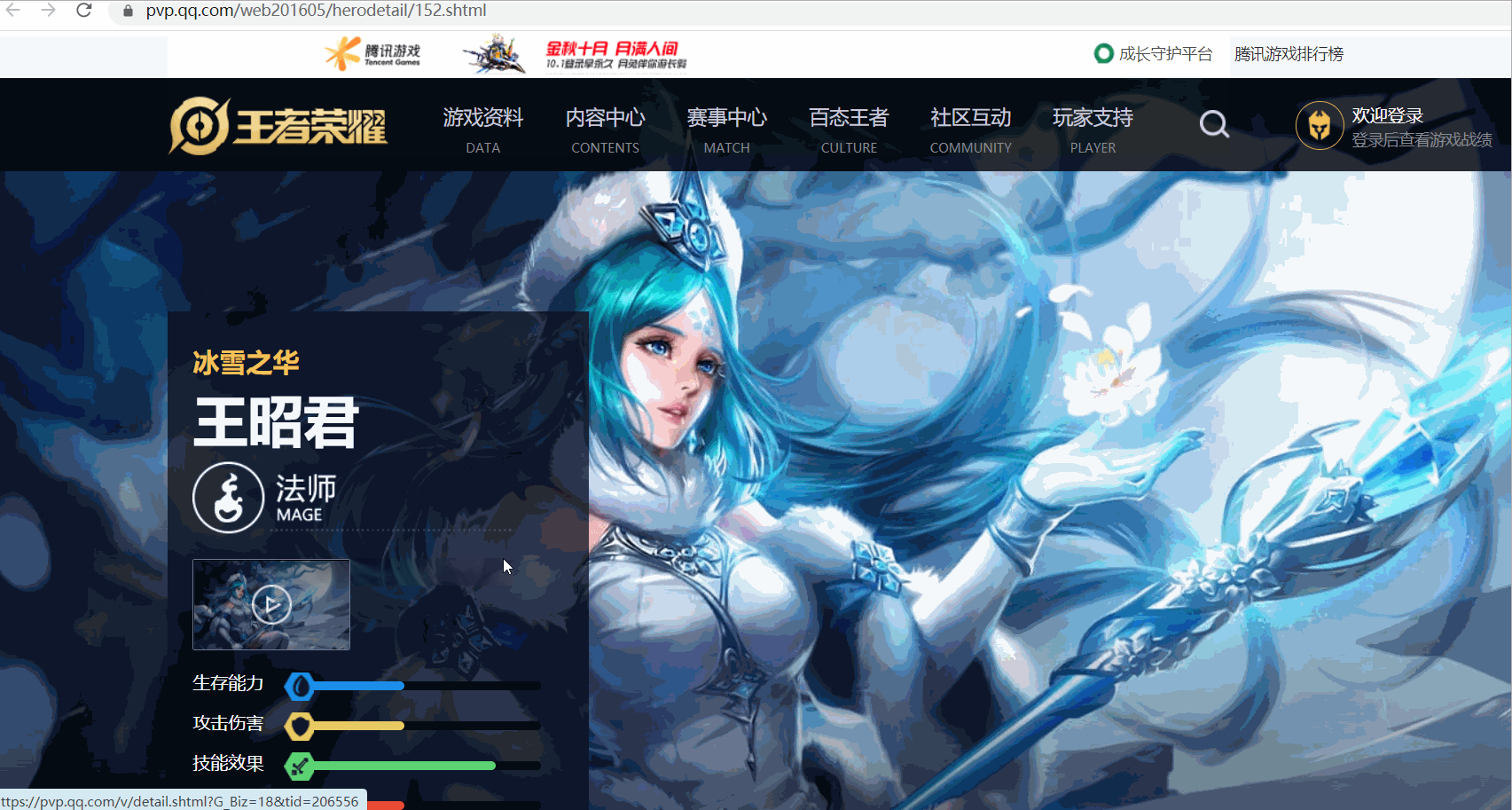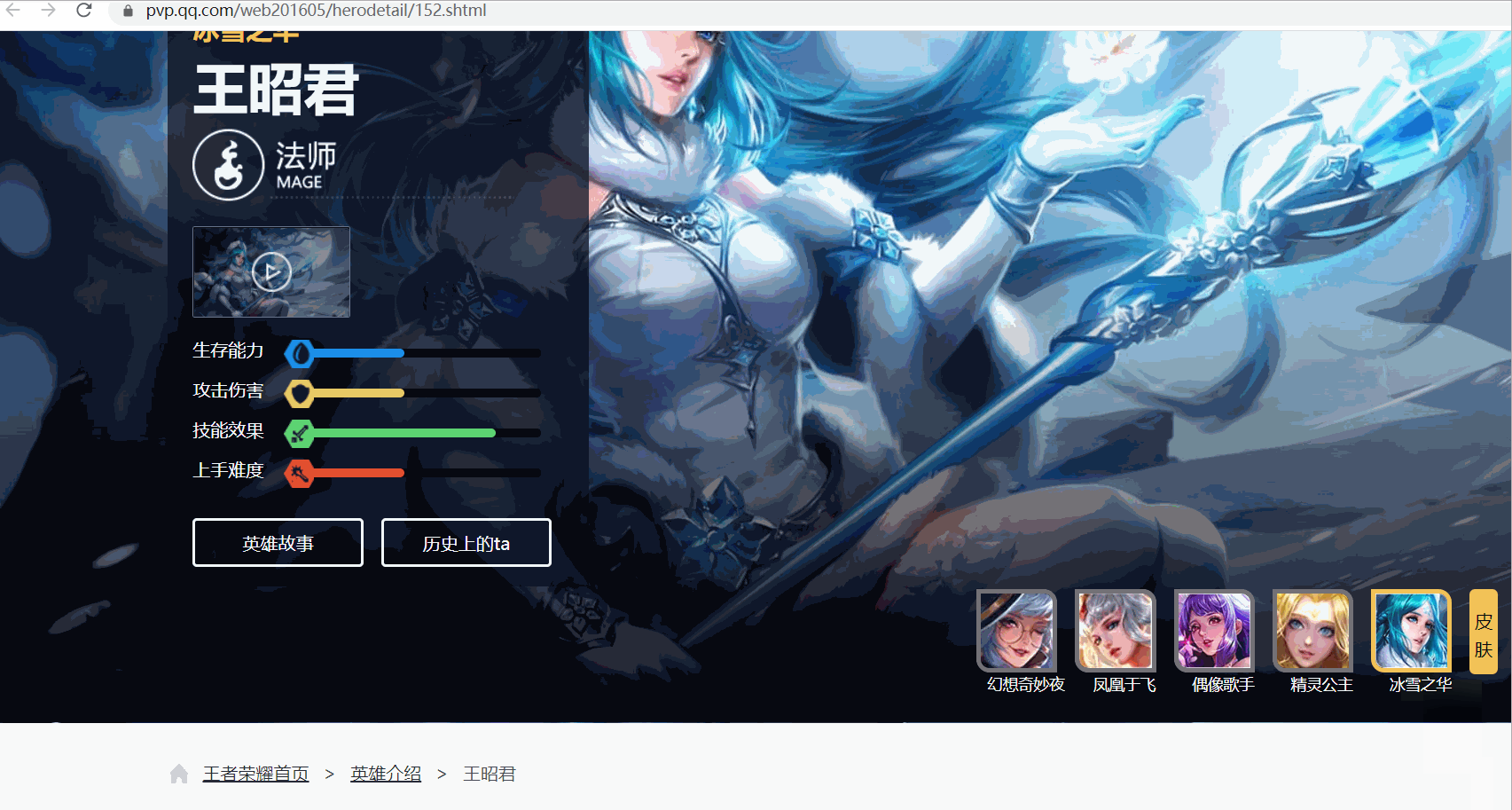
多選擇幾個英雄檢查網頁,可以發現各個英雄頁面的URL規律
https://pvp.qq.com/web201605/herodetail/152.shtml
https://pvp.qq.com/web201605/herodetail/150.shtml
https://pvp.qq.com/web201605/herodetail/167.shtml
發現只有末尾的數位在變化,末尾的數位可以認為是該英雄的頁面標識。
點選Network,Crtl + R 重新整理,可以找到一個 herolist.json 檔案。

發現是亂碼,但問題不大,雙擊這個 json 檔案,將它下載下來觀察,用編輯器開啟可以看到。
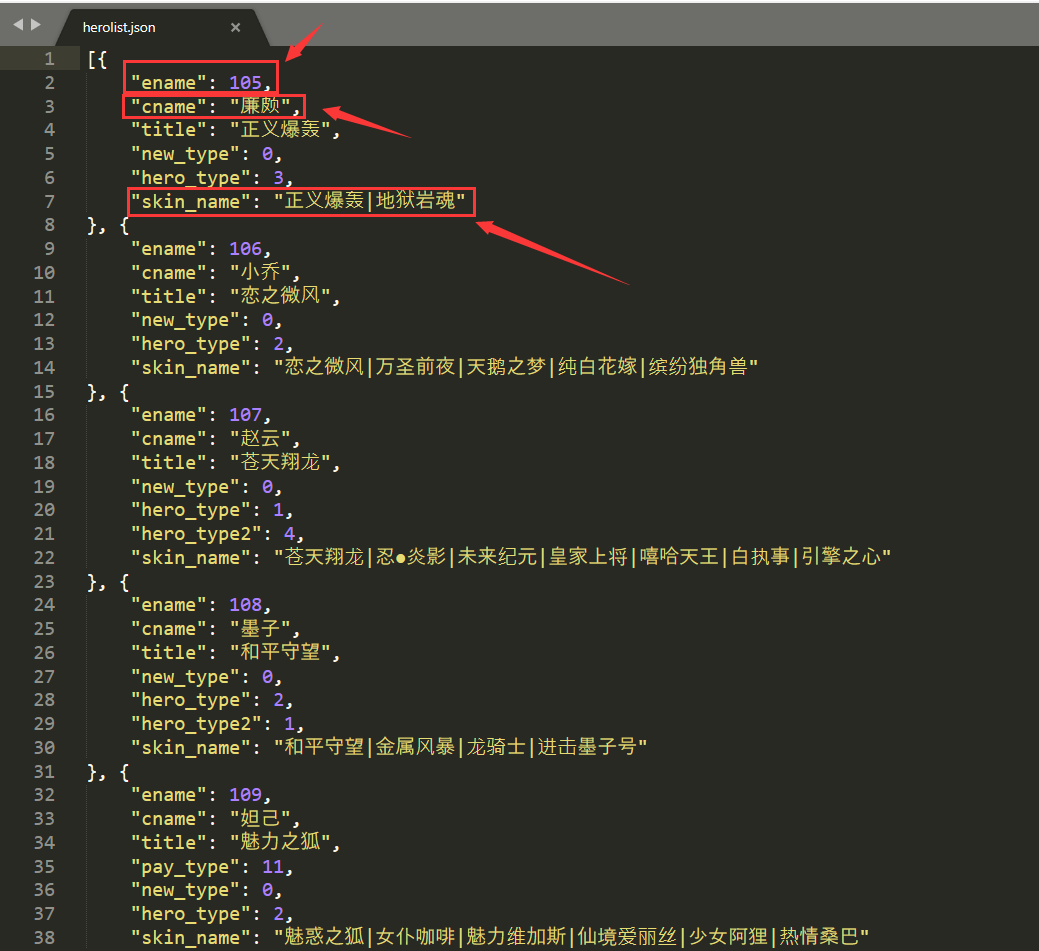
ename是英雄網址頁面的標識;而 cname 是對應英雄的名稱;skin_name為對應面板的名稱。
任選一個英雄頁面進去,檢查該英雄下面所有面板,觀察url變化規律。
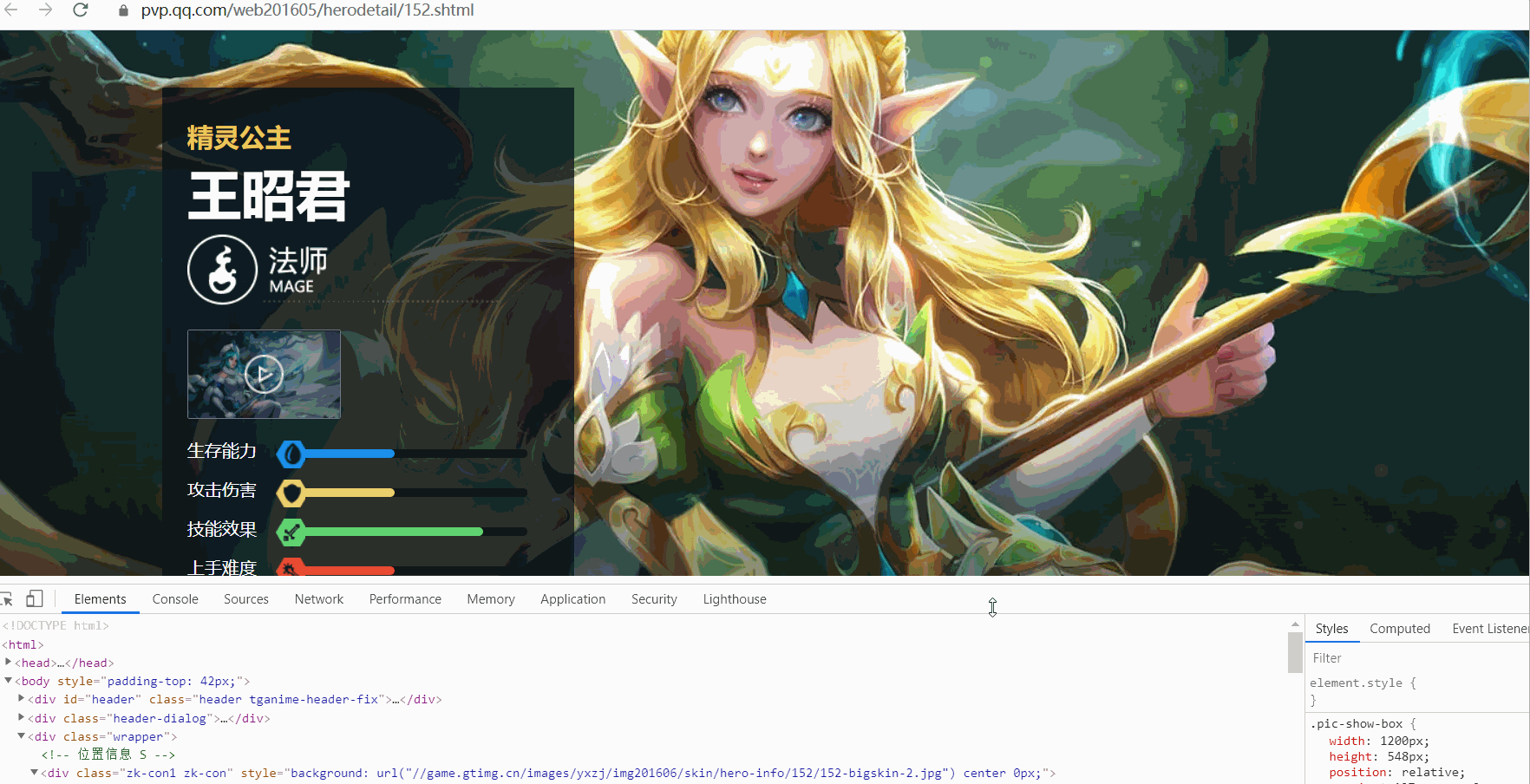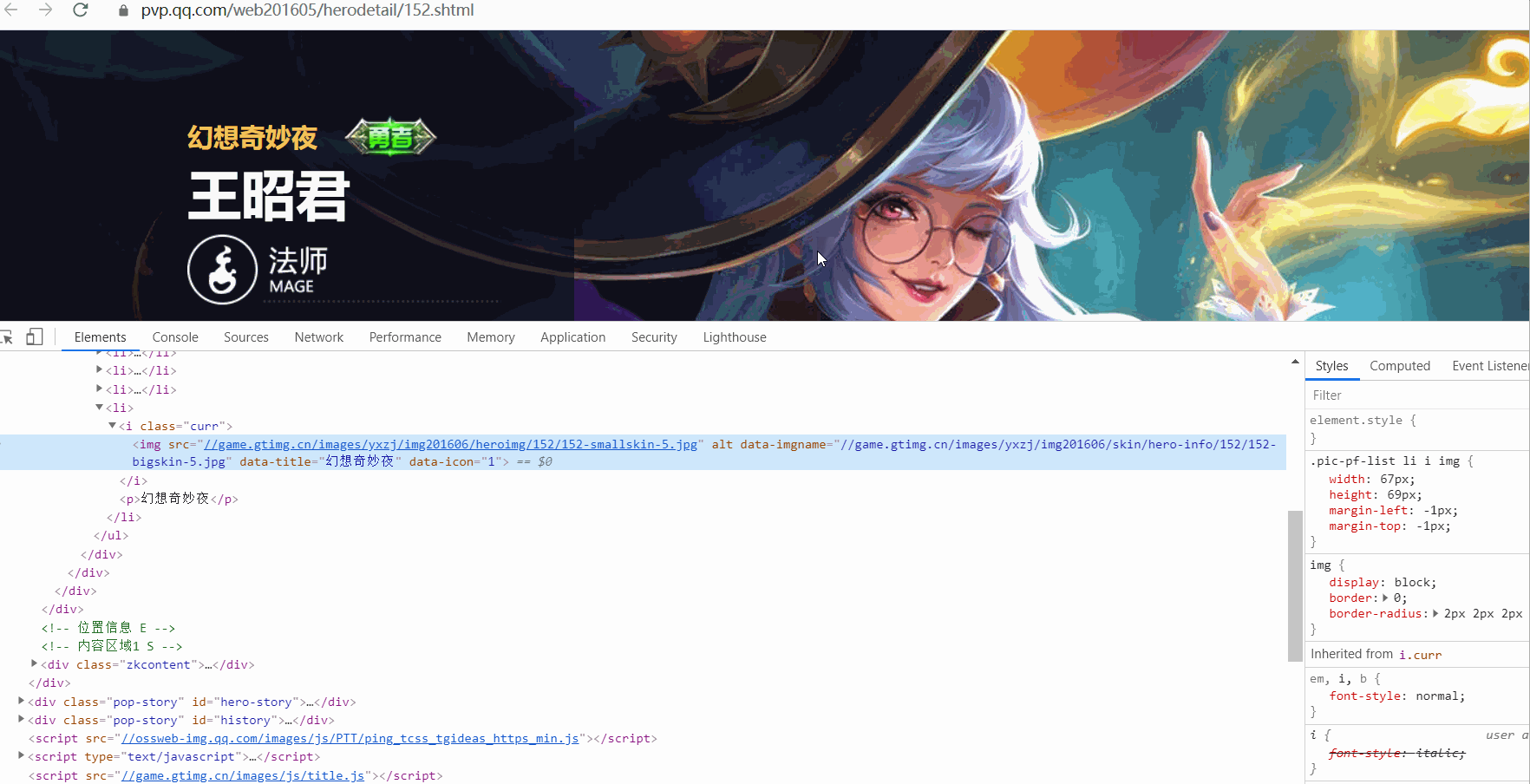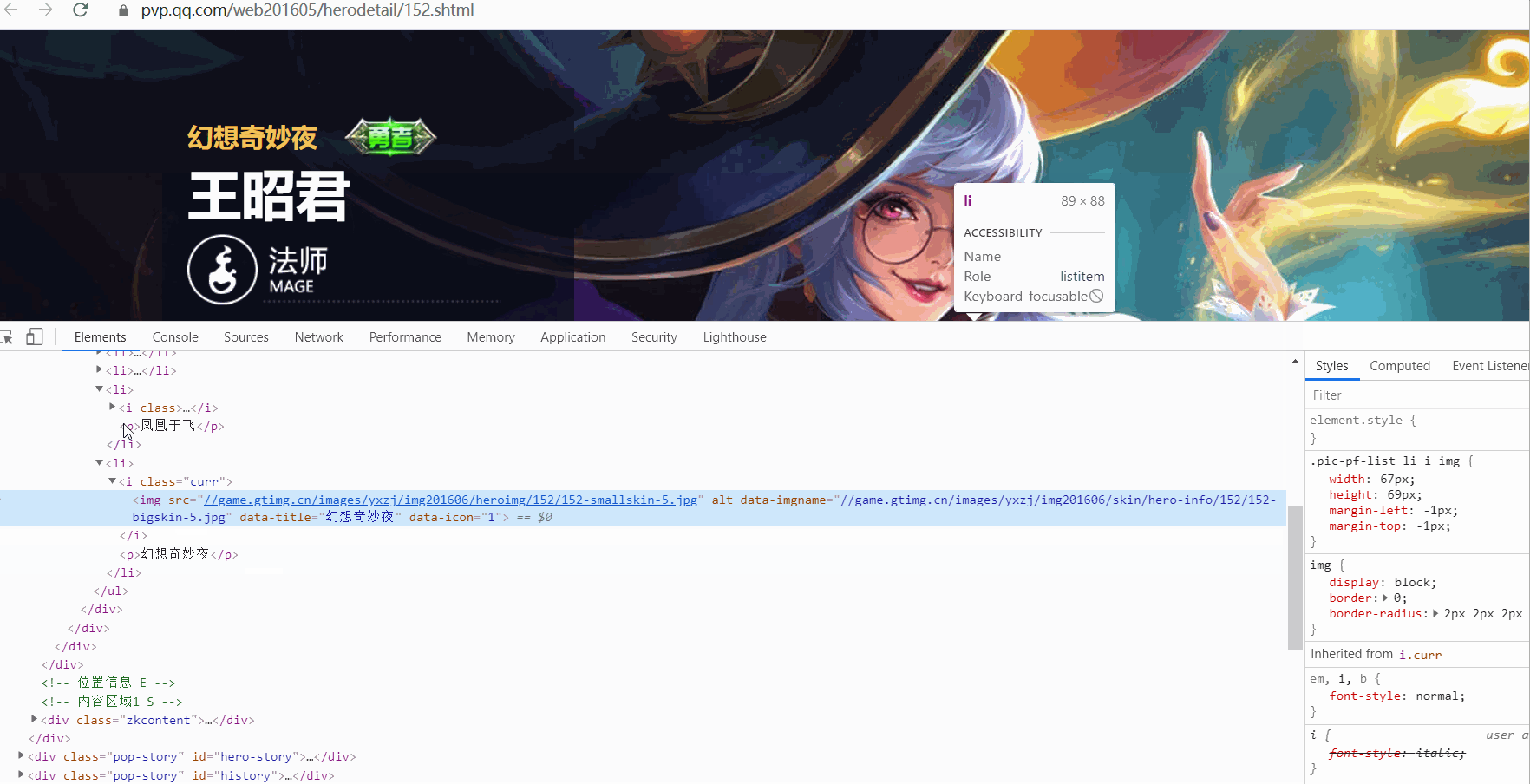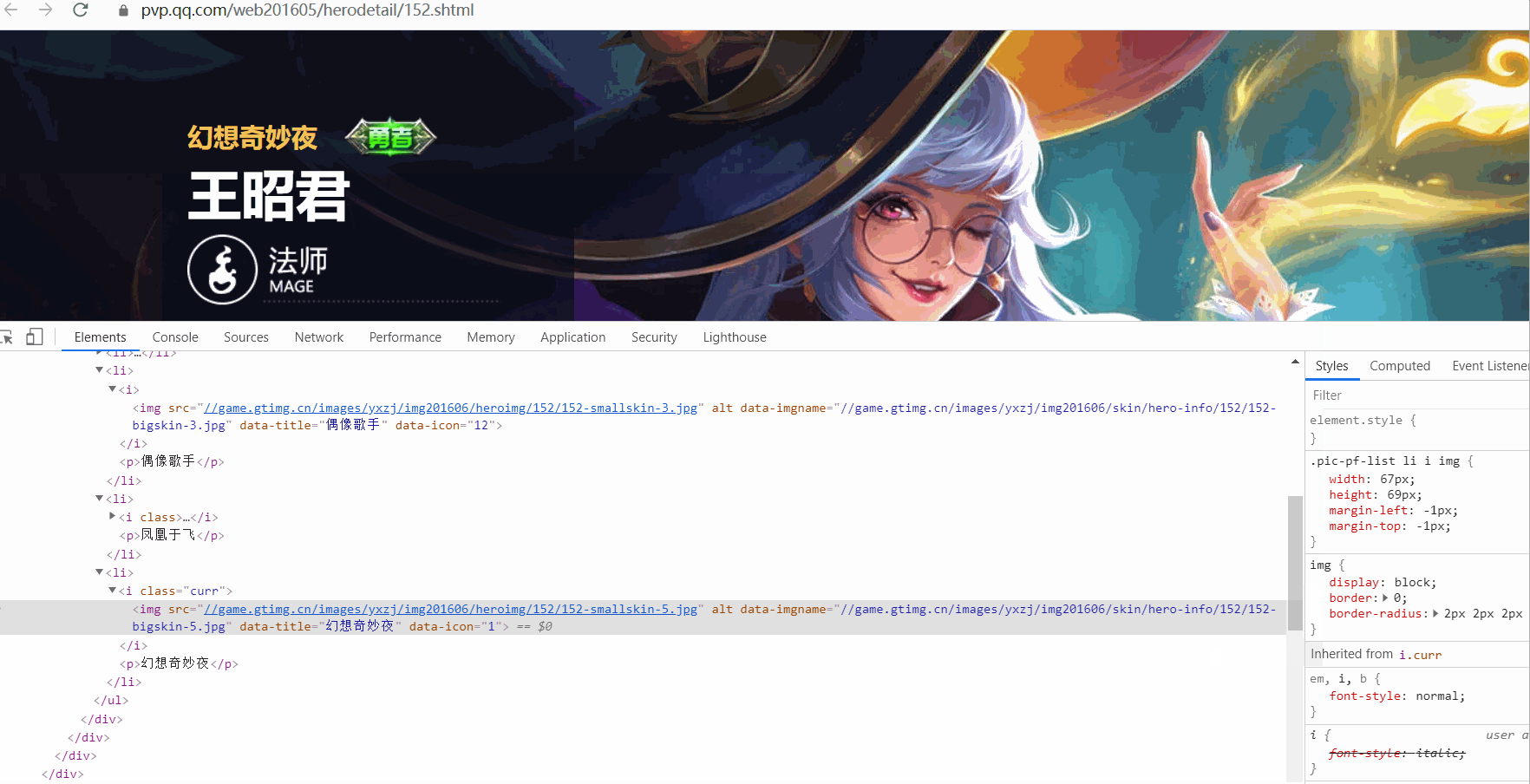
url變化規律如下:
https://game.gtimg.cn/images/yxzj/img201606/heroimg/152/152-bigskin-1.jpg
https://game.gtimg.cn/images/yxzj/img201606/heroimg/152/152-bigskin-2.jpg
https://game.gtimg.cn/images/yxzj/img201606/heroimg/152/152-bigskin-3.jpg
https://game.gtimg.cn/images/yxzj/img201606/heroimg/152/152-bigskin-4.jpg
https://game.gtimg.cn/images/yxzj/img201606/heroimg/152/152-bigskin-5.jpg
複製圖片連結到瀏覽器開啟,可以看到高清大圖。
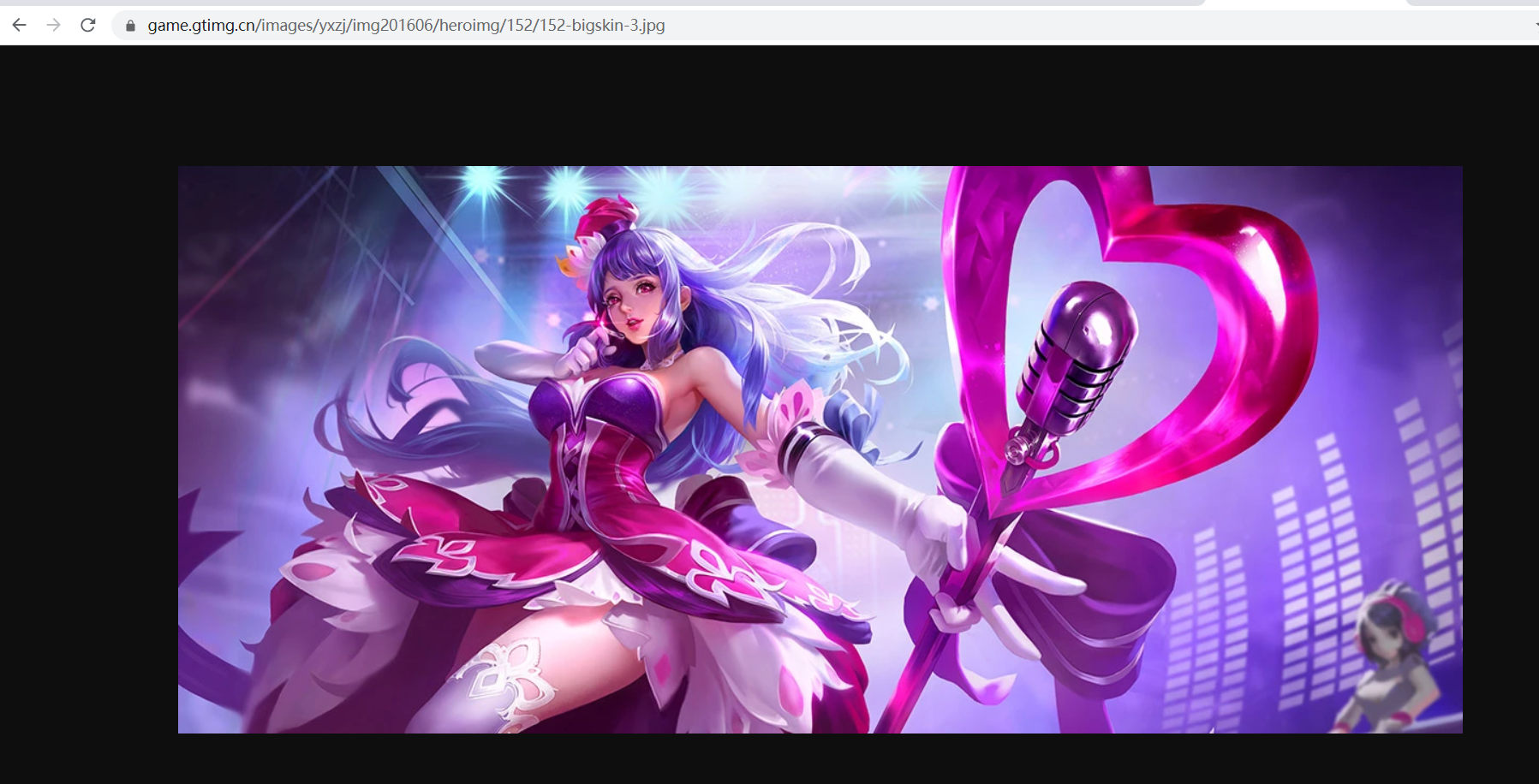
觀察到同一個英雄的面板圖片 url 末尾 -{x}.jpg 從 1 開始依次遞增,再來看看不同英雄的面板圖片 url 是如何構造的。會發現, ename這個英雄的標識不一樣,獲取到的圖片就不一樣,由 ename 引數決定。
https://game.gtimg.cn/images/yxzj/img201606/heroimg/152/152-bigskin-1.jpg
https://game.gtimg.cn/images/yxzj/img201606/heroimg/150/150-bigskin-1.jpg
https://game.gtimg.cn/images/yxzj/img201606/heroimg/153/153-bigskin-1.jpg
# 可構造圖片請求連結如下
https://game.gtimg.cn/images/yxzj/img201606/heroimg/{ename}/{ename}-bigskin-{x}.jpg
三、爬蟲程式碼實現
# -*- coding: UTF-8 -*-
"""
@File :王者榮耀英雄面板桌布.py
@Author :葉庭雲
@Date :2020/10/2 11:40
@CSDN :https://blog.csdn.net/fyfugoyfa
"""
import requests
import os
import json
from lxml import etree
from fake_useragent import UserAgent
import logging
# 紀錄檔輸出的基本設定
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
class glory_of_king(object):
def __init__(self):
if not os.path.exists("./王者榮耀面板"):
os.mkdir("王者榮耀面板")
# 利用fake_useragent產生隨機UserAgent 防止被反爬
ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random
}
def scrape_skin(self):
# 傳送請求 獲取響應
response = requests.get('https://pvp.qq.com/web201605/js/herolist.json', headers=self.headers)
# str轉為json
data = json.loads(response.text)
# for迴圈遍歷data獲取需要的欄位 建立對應英雄名稱的資料夾
for i in data:
hero_number = i['ename'] # 獲取英雄名字編號
hero_name = i['cname'] # 獲取英雄名字
os.mkdir("./王者榮耀面板/{}".format(hero_name)) # 建立英雄名稱對應的資料夾
response_src = requests.get("https://pvp.qq.com/web201605/herodetail/{}.shtml".format(hero_number),
headers=self.headers)
hero_content = response_src.content.decode('gbk') # 返回相應的html頁面 解碼為gbk
# xpath解析物件 提取每個英雄的面板名字
hero_data = etree.HTML(hero_content)
hero_img = hero_data.xpath('//div[@class="pic-pf"]/ul/@data-imgname')
# 去掉每個面板名字中間的分隔符
hero_src = hero_img[0].split('|')
logging.info(hero_src)
# 遍歷英雄src處理圖片名稱。
for j in range(len(hero_src)):
# 去掉面板名字的&符號
index_ = hero_src[j].find("&")
skin_name = hero_src[j][:index_]
# 請求下載圖片
response_skin = requests.get(
"https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{}/{}-bigskin-{}.jpg".format(
hero_number, hero_number, j + 1))
# 獲取圖片二進位制資料
skin_img = response_skin.content
# 把面板圖片儲存到對應名字的檔案裡
with open("./王者榮耀面板/{}/{}.jpg".format(hero_name, skin_name), "wb")as f:
f.write(skin_img)
logging.info(f"{skin_name}.jpg 下載成功!!")
def run(self):
self.scrape_skin()
if __name__ == '__main__':
spider = glory_of_king()
spider.run()
執行效果如下:
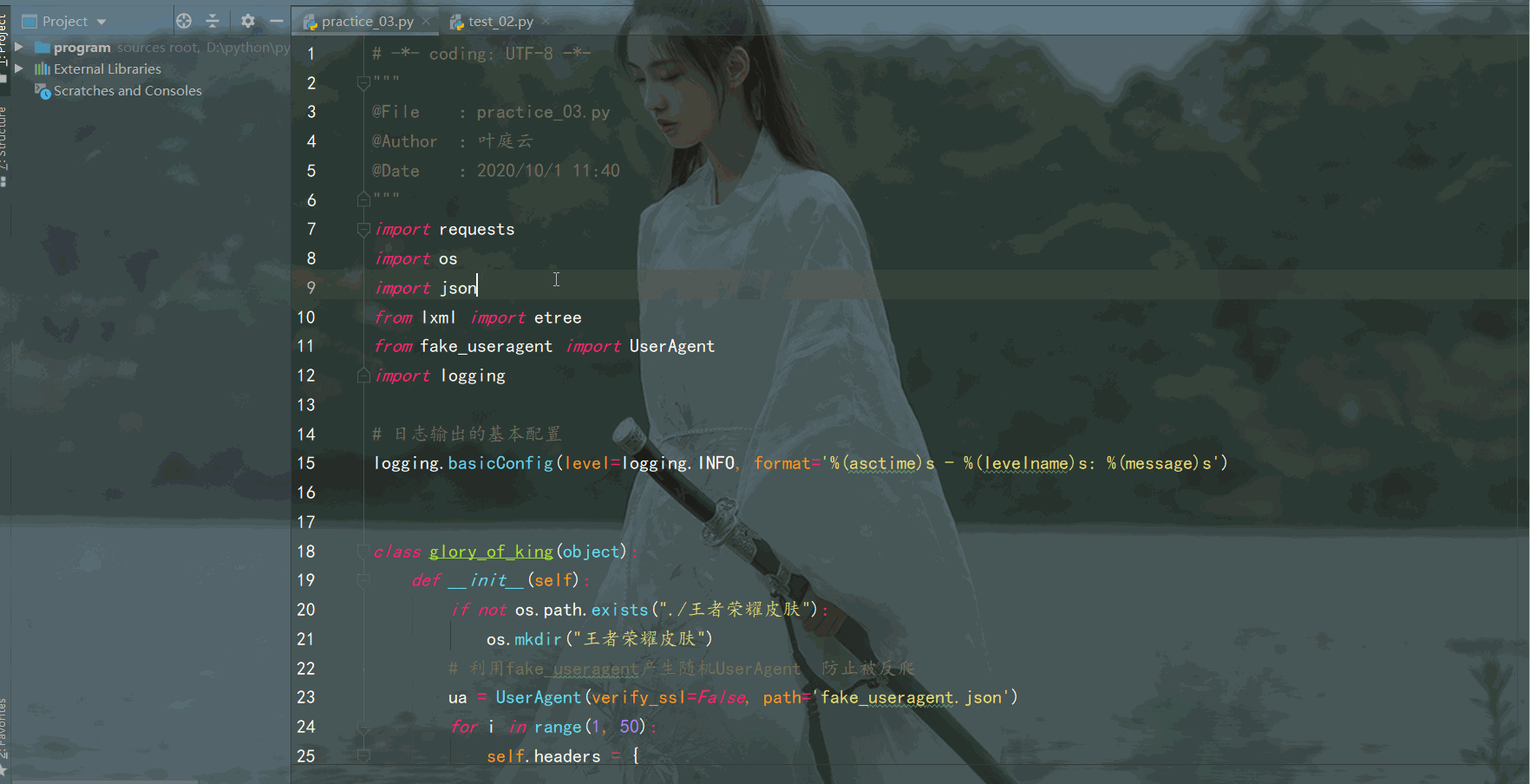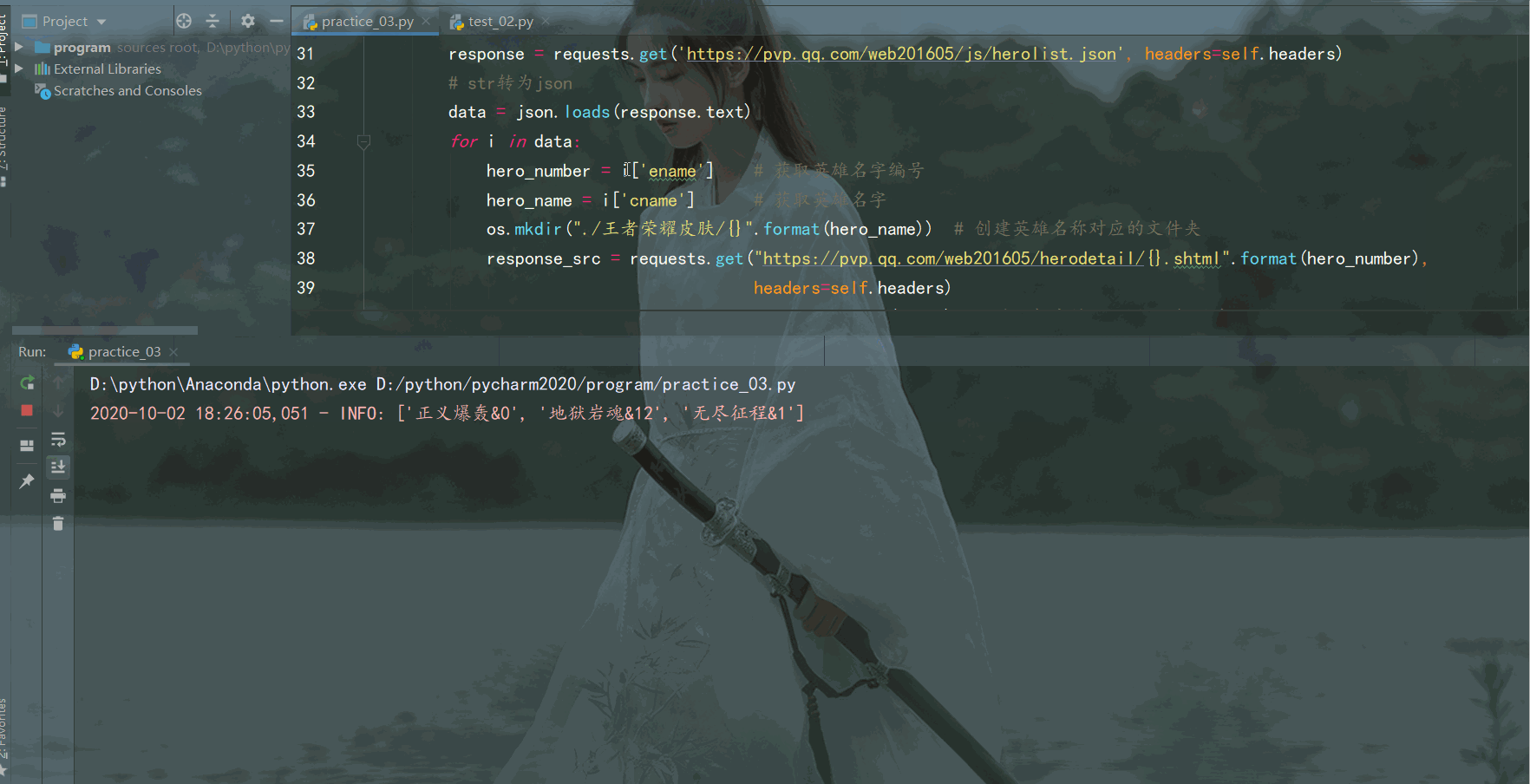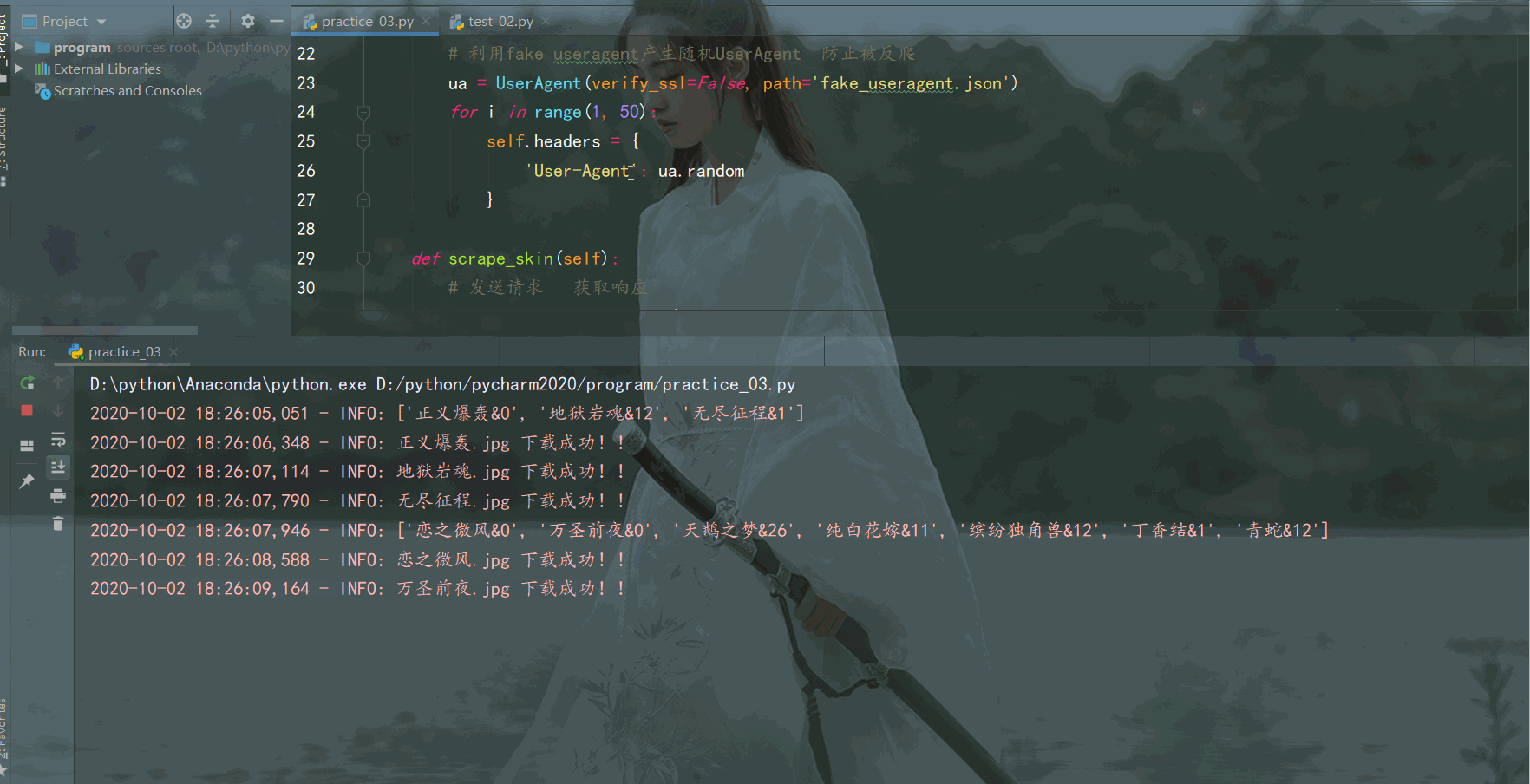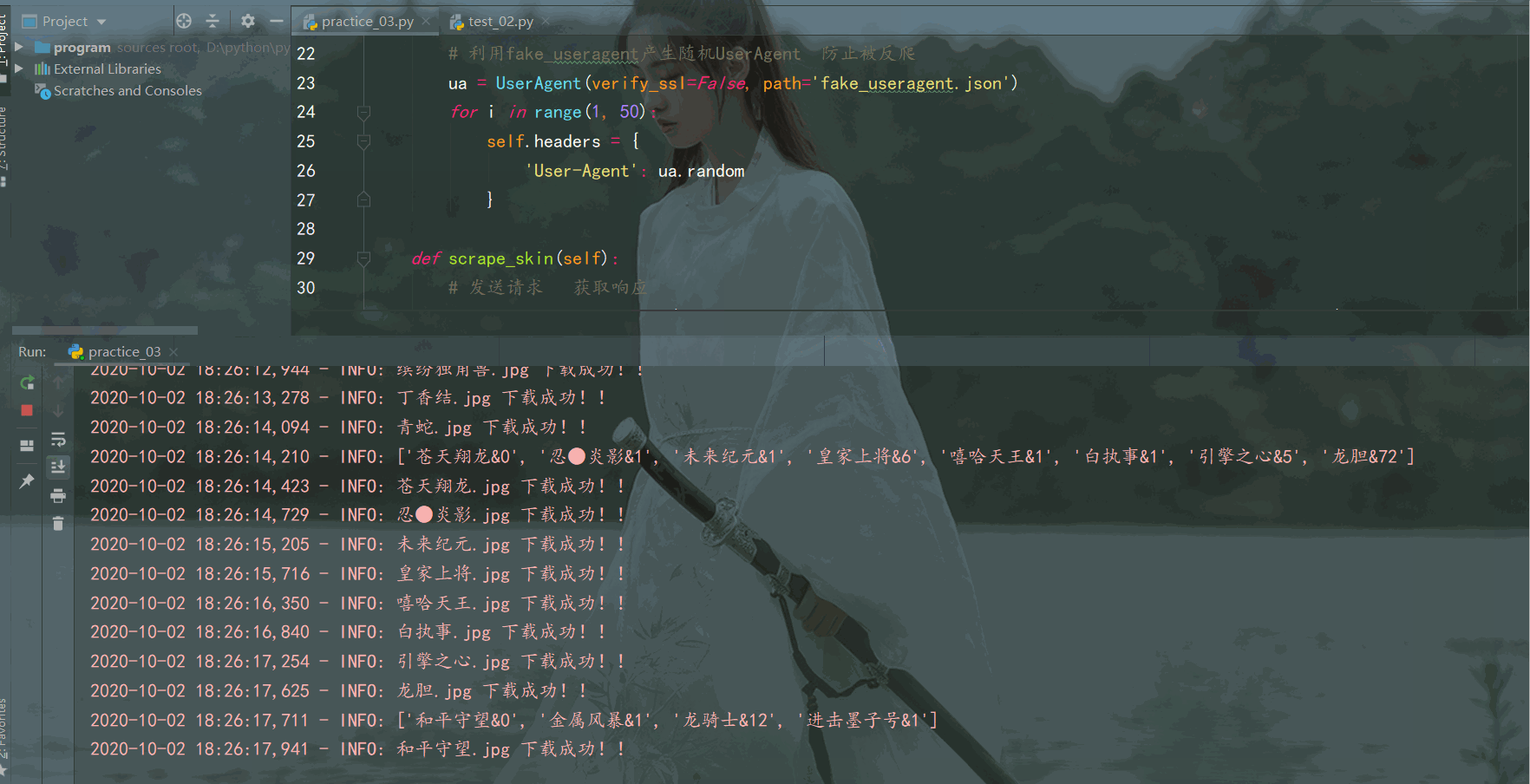
程式執行一段時間,英雄面板桌布就都儲存在本地資料夾啦,結果如下:
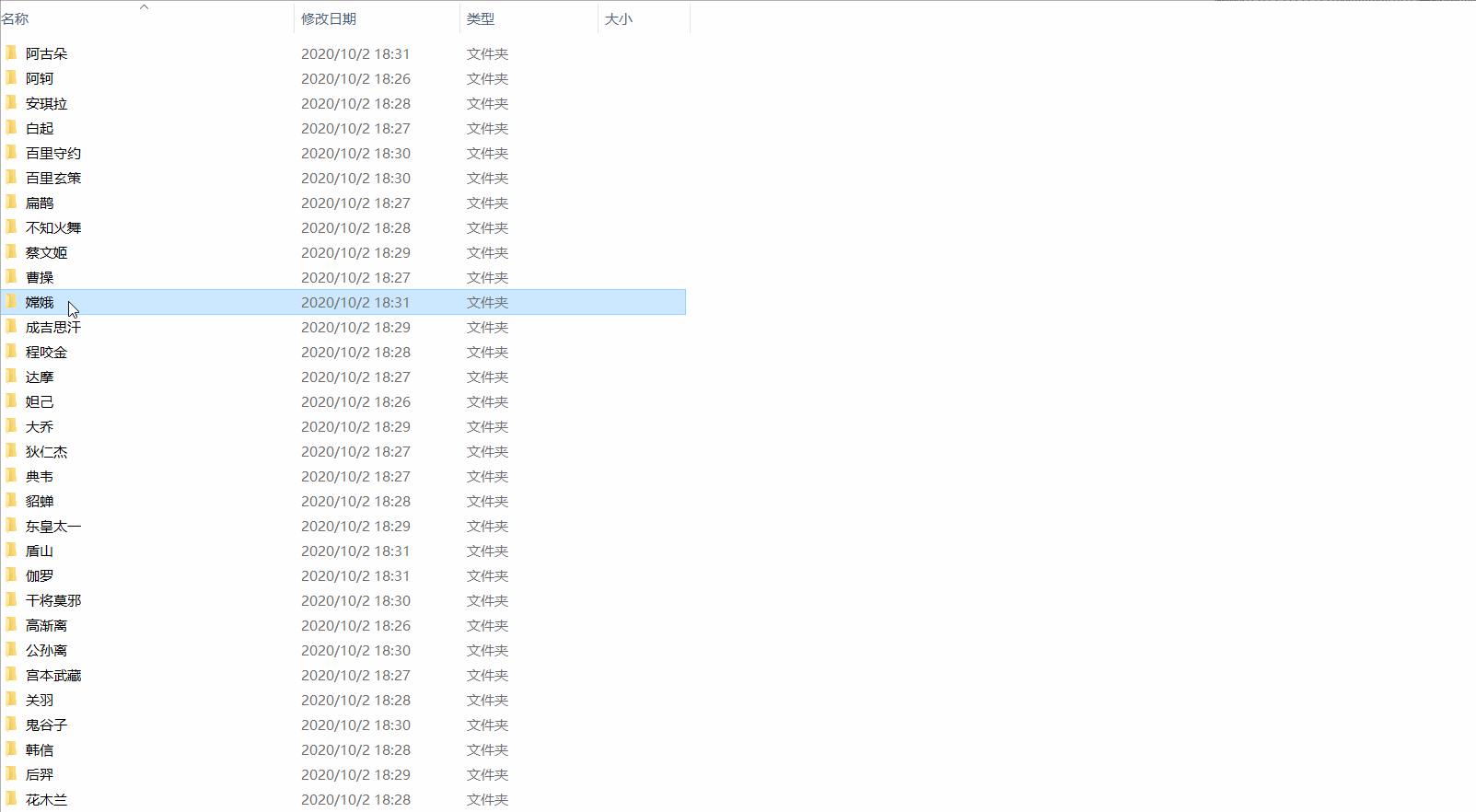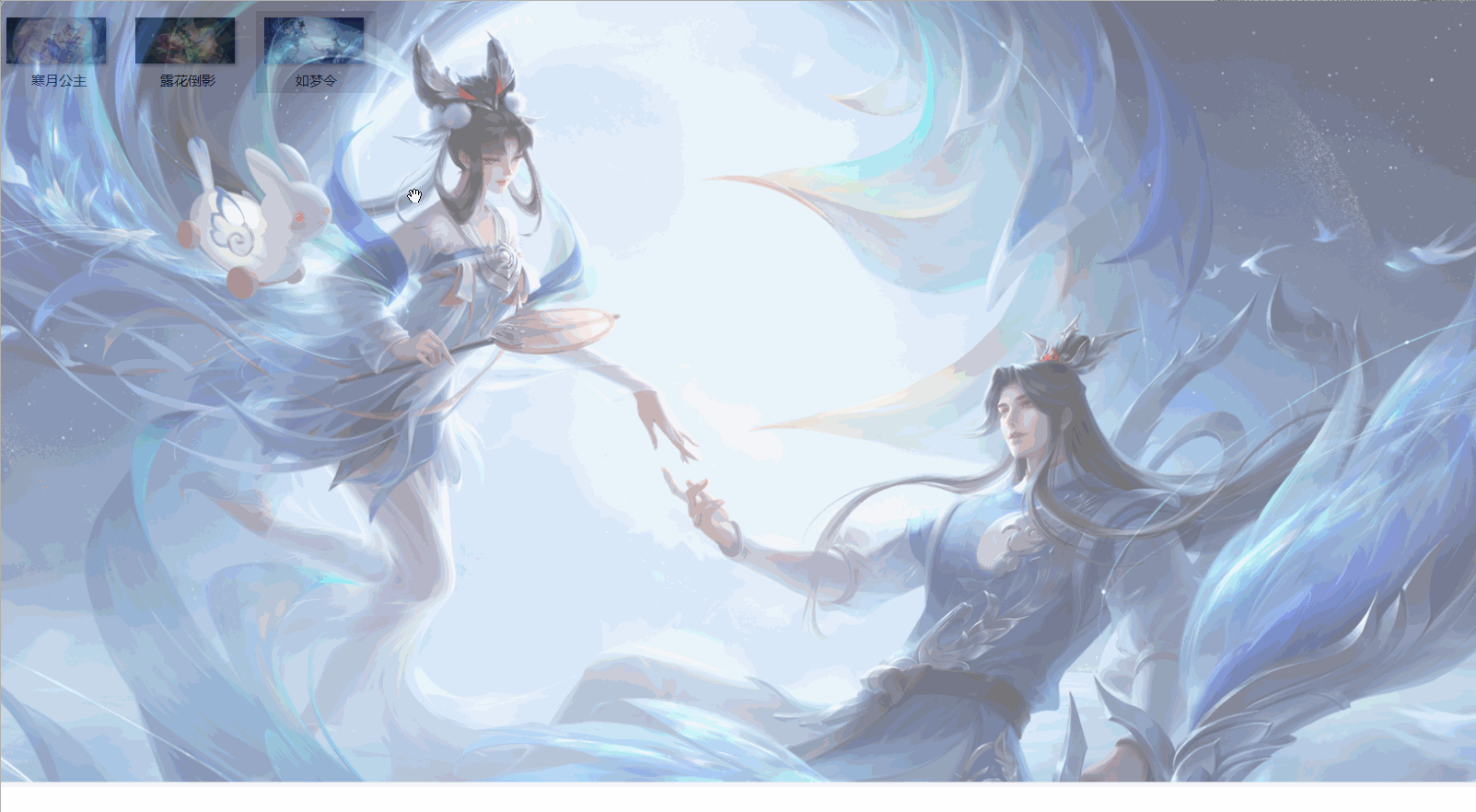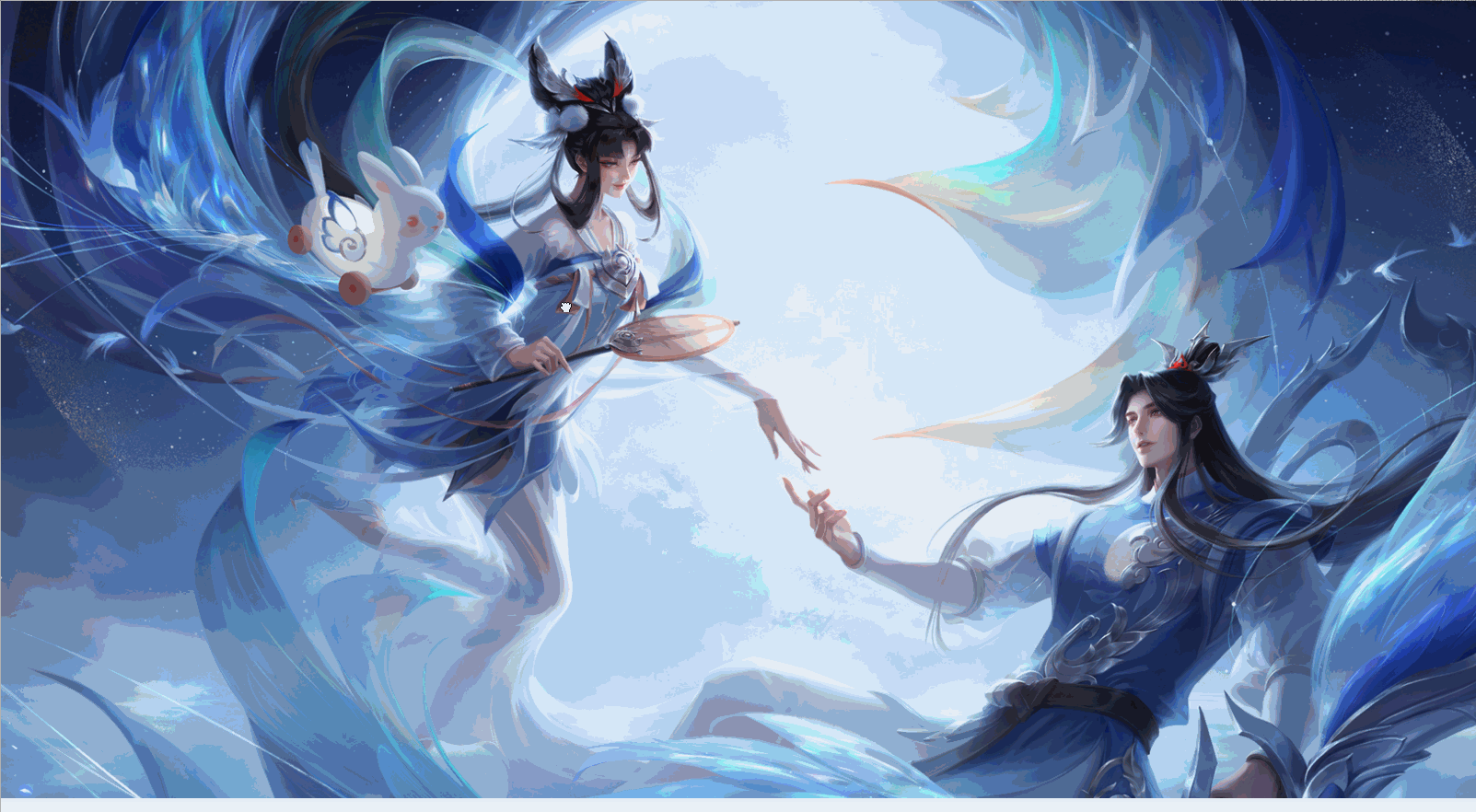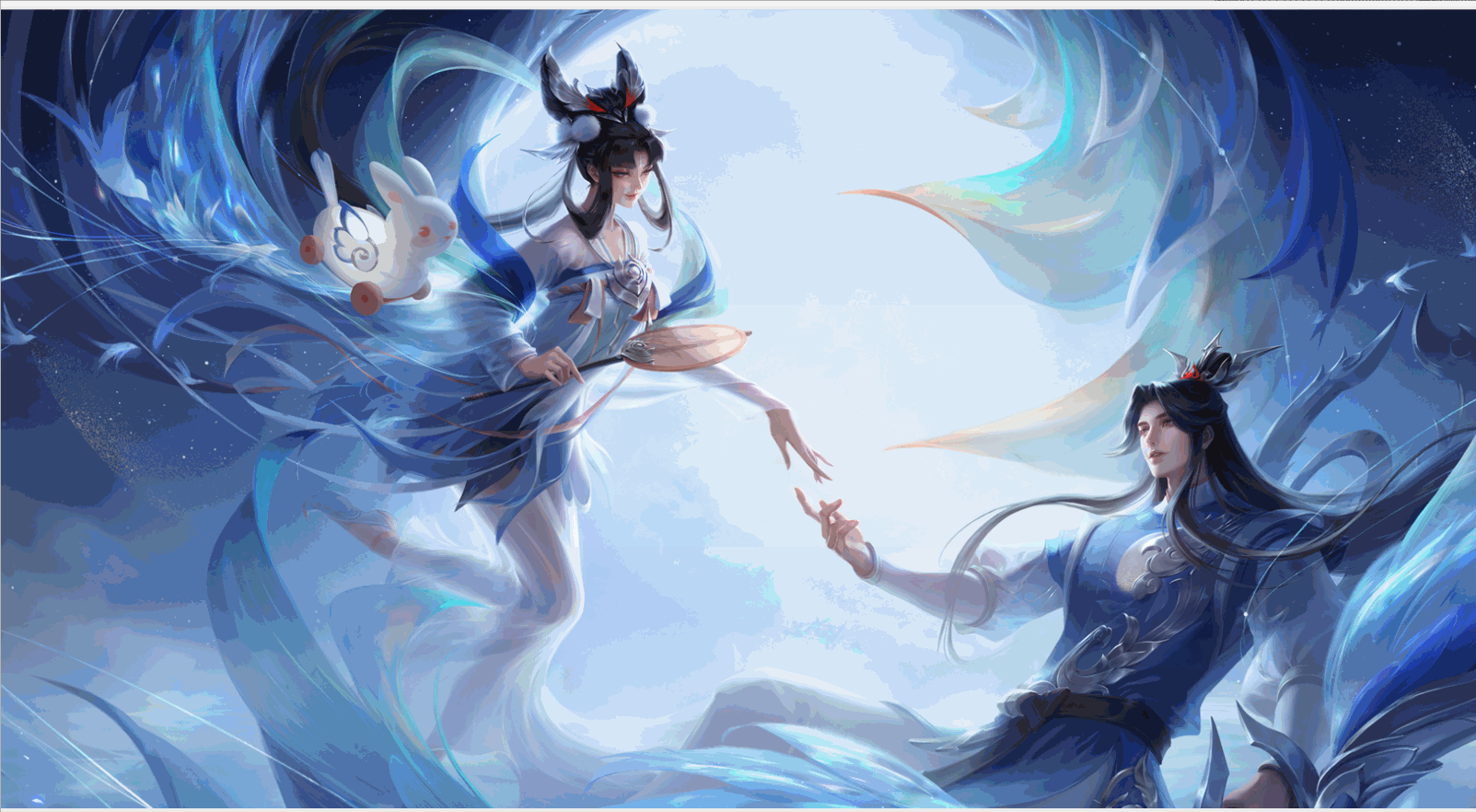
四、其他說明
- 不建議抓取太多資料,容易對伺服器造成負載,淺嘗輒止即可。
- 通過本文爬蟲,可以幫助你瞭解 json 資料的解析和提取需要的資料,如何通過字串的拼接來構造URL請求。
- 本文利用 Python 爬蟲一鍵下載王者榮耀英雄面板桌布,實現過程中也會遇到一些問題,多思考和偵錯,最終解決問題,也能理解得更深刻。
- 程式碼可直接複製執行,如果覺得還不錯,記得給個贊哦,也是對作者最大的鼓勵,不足之處可以在評論區多多指正。
解決報錯:fake_useragent.errors.FakeUserAgentError: Maximum amount of retries reached
# 報錯如下
Error occurred during loading data. Trying to use cache server https://fake-useragent.herokuapp.com/browsers/0.1.11
Traceback (most recent call last):
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 1318, in do_open
encode_chunked=req.has_header('Transfer-encoding'))
File "/usr/local/python3/lib/python3.6/http/client.py", line 1239, in request
self._send_request(method, url, body, headers, encode_chunked)
File "/usr/local/python3/lib/python3.6/http/client.py", line 1285, in _send_request
self.endheaders(body, encode_chunked=encode_chunked)
File "/usr/local/python3/lib/python3.6/http/client.py", line 1234, in endheaders
self._send_output(message_body, encode_chunked=encode_chunked)
File "/usr/local/python3/lib/python3.6/http/client.py", line 1026, in _send_output
self.send(msg)
File "/usr/local/python3/lib/python3.6/http/client.py", line 964, in send
self.connect()
File "/usr/local/python3/lib/python3.6/http/client.py", line 1392, in connect
super().connect()
File "/usr/local/python3/lib/python3.6/http/client.py", line 936, in connect
(self.host,self.port), self.timeout, self.source_address)
File "/usr/local/python3/lib/python3.6/socket.py", line 724, in create_connection
raise err
File "/usr/local/python3/lib/python3.6/socket.py", line 713, in create_connection
sock.connect(sa)
socket.timeout: timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/python3/lib/python3.6/site-packages/fake_useragent/utils.py", line 67, in get
context=context,
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 223, in urlopen
return opener.open(url, data, timeout)
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 526, in open
response = self._open(req, data)
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 544, in _open
'_open', req)
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 504, in _call_chain
result = func(*args)
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 1361, in https_open
context=self._context, check_hostname=self._check_hostname)
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 1320, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error timed out>
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/python3/lib/python3.6/site-packages/fake_useragent/utils.py", line 154, in load
for item in get_browsers(verify_ssl=verify_ssl):
File "/usr/local/python3/lib/python3.6/site-packages/fake_useragent/utils.py", line 97, in get_browsers
html = get(settings.BROWSERS_STATS_PAGE, verify_ssl=verify_ssl)
File "/usr/local/python3/lib/python3.6/site-packages/fake_useragent/utils.py", line 84, in get
raise FakeUserAgentError('Maximum amount of retries reached')
fake_useragent.errors.FakeUserAgentError: Maximum amount of retries reached
解決方法如下:
# 將https://fake-useragent.herokuapp.com/browsers/0.1.11裡內容複製 並另存為本地json檔案:fake_useragent.json
# 參照
ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
print(ua.random)
執行結果如下:
Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1500.55 Safari/537.36