從Google Mesa到百度PALO(數倉)
最近在研究OLAP相關的技術,正好看到Google 2014年的論文《Mesa: Geo-Replicated, Near RealTime, Scalable Data Warehousing》,以及百度最近2017年開源的基於Mesa+Impala的實現系統PALO,本篇就嘗試結合起來看下二者,主要是學習介紹性質的文章。
1. Mesa
Mesa是一個Google內部使用的資料倉儲系統,從論文的標題可以抓住幾個關鍵詞:可實現跨DC複製的、近實時的、可延伸的。這幾點算是Mesa的特色所在,同時和Mesa要解決的問題背景有很大關係,Mesa主要解決Google線上廣告報表和分析業務,論文裡提到的use cases包括reporting, internal auditing, analysis, billing和forecasting等方面。舉個例子,廣告主需要通過Google的AdWords業務系統檢視報告:2017.1整月的預算消費情況,包括所有推廣計劃(Campaign)的展現量、點選量、消費等指標,這就是一個典型的應用場景。
為了滿足Google內部的業務功能需求,需要設計一個data store,它的非功能需求要滿足:
1. Atomic Updates. 原子更新。
一個使用者的動作,比如一個點選行為,會被影響成百上千的檢視的指標,比如影響推廣計劃、分網站、創意等等一系列具體報表,這個點選行為要麼全部生效,要麼全不生效,不能存在中間狀態。
2. Consistency and Correctness. 一致性和正確性。
強一致性必須保證,可重複讀,即使是跨DC也需要保證讀出來的一致,這麼高的要求和廣告系統的嚴謹性有直接關係。
3. Availability. 高可用。
不能存在單點(SPOF),不能停服(downtime)。
4. Near RealTime Update Throughput. 近實時的高吞吐更新。
系統要支援增量實時更新,吞吐要達到百萬行/秒。增量在分鐘級即可被查詢到的queryability,這麼高的要求和廣告系統角度來說很必要,每秒鐘Google都會有百萬級別的廣告展現,而廣告主或者系統的其他模組需要更短的時間看到報表,輔助決策。
5. Query Performance. 高效能查詢。
系統既要支援低延遲的使用者報表查詢請求,也要支援高吞吐的Ad-hoc即席分析查詢。低延遲要保證99分位平響在百毫秒。
6. Scalability. 高擴充套件。
隨著資料量和存取量增量,系統的能力可線性(linear)的增長。
7. Online Data and Metadata Transformation. 線上的schema變更。
業務不斷變化,對於schema的變更,包括加表、刪表、加列、減列,新建索引,修改物化檢視等的都必須不能停服的線上完成,而且不能影響資料更新和查詢。
有了需求,那麼就一句話總結下Google把Mesa看做一個什麼系統。
Mesa is a distributed, replicated, and highly available data processing, storage, and query system for structured data. Mesa ingests data generated by upstream services, aggregates and persists the data internally, and serves the data via user queries.
翻譯下,Mesa是一個分散式、多副本的、高可用的資料處理、儲存和查詢系統,針對結構化資料。一般資料從上游服務產生(比如一個批次的spark streaming作業產生),在內部做資料的聚合和儲存,最終把資料serve到外面供使用者查詢。
對於Mesa的技術選型,論文裡提到了Mesa充分利用了Google內部已有的building blocks,包括Colossus (對應Hadoop的HDFS)、BigTable(對應Hadoop的HBase)和MapReduce。Mesa的儲存是多副本的並且分割區做sharding的,很好理解,分治策略幾乎是分散式系統的必備元素。批次更新,包括大批次,小批次(mini-batch)。使用MVCC機制,每個更新都有個version。為實現跨DC工作,還需要一個分散式一致性技術支援,例如Paxos。
論文裡還對比了業界的其他方案,比如基於資料立方體cube的方案,很難做近實時更新(當年是了,現在kylin也支援了),Google內部的系統中BigTable不支援跨行事務,Megastore、Spanner和F1都是OLTP系統,不支援海量資料的高吞吐寫入。
下面進入正題,在海量資料規模下,實時性和吞吐率兩個指標,魚與熊掌不可兼得,Mesa基於廣告資料可聚合性的特質,從儲存,查詢等角度進行了大量針對性的設計,那麼Mesa到底提出了什麼創新的設計來應對它提出的需求呢?其實就兩方面,1)儲存設計,2)系統架構。其中我認識1)是這個論文最大的contribution。
1.1 儲存設計
1.1.1 資料模型(data model)
Mesa僅支援結構化資料,邏輯上儲存在一張表(table)裡,表包括很多列,表都有一個schema,和傳統的資料庫類似,schema會定義各個列的型別,比如int32、int64、string等。
Mesa的列要能分成兩類,分別是維度列(dimensional attributes)和指標列(measure attributes),這實際可以看做是一種KV模型,Keys就是維度,Values就是指標。
同時指標列需要定義一個聚合函數aggregation function,例如SUM,MIN,MAX,COUNT等等,用於作用於Key相同的記錄,做聚合使用,聚合函數必須滿足結合律,可以選擇性滿足交換律。
Mesa中定義的索引Index其實只能是被動的符合Key的順序(因為物理上沒有多餘的儲存索引,全靠資料有序儲存,後面儲存格式章節會細講)。
一個記錄或者使用者行為,叫做single fact會原子地、一致的影響多個物化檢視(materilized view),物化檢視一般利用維度列做上卷表(roll-up),這樣就可以做多維分析(MOLAP)的下鑽(drill down)和上卷(roll up)查詢了。
Google中Mesa儲存了上千張表,每張表最多幾百列。
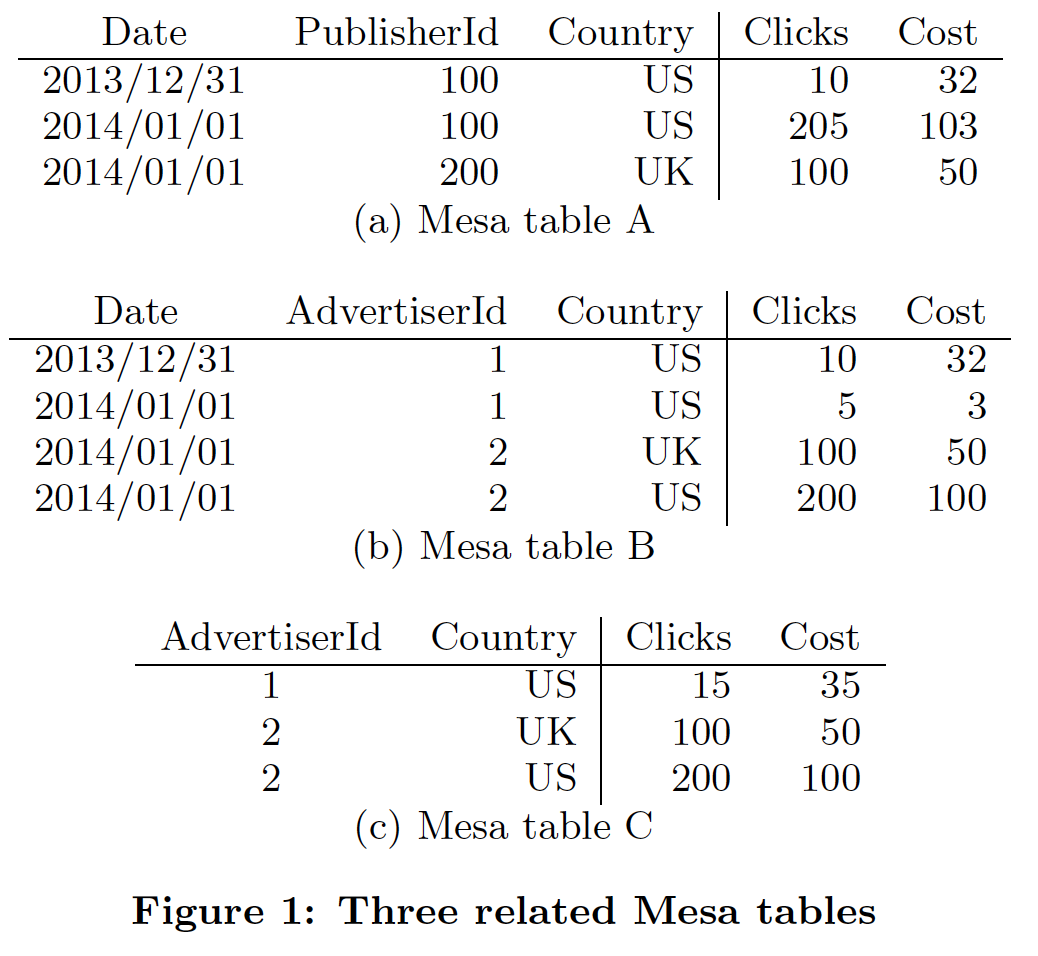
下圖是論文中的例子,三張典型的表。
Table A的維度列包括Date, PublisherId, Country,指標列是Clicks, Cost,聚合函數是SUM。
Table B的維度列包括Date, AdvertiserId, Country,指標列是Clicks, Cost,聚合函數是SUM。
Table C是Table B的物化檢視,維度列是AdvertiserId, Country,指標列是Clicks Cost,聚合函數是SUM。
1.1.2 資料更新和查詢
為實現高吞吐的更新,Mesa必須按照批次的方式來實現,這些更新的小資料集合通常從upstream系統來,一般是分鐘級別產生一個,這個可以理解為Storm或者Spark Streaming產生的資料。所有的更新批次就是序列處理的。每個更新批次都會帶一個自增的版本號,其實這就是MVCC機制,這樣就可以做到無鎖的更新,對於查詢就需要指定一個版本號。同時,Mesa要求查詢除了包含版本號,還得有一個Predicate,也就是在Key space上做filter的謂詞條件。
論文中舉了一個例子,如下圖所示,在剛剛的資料模型中Table A和Table B是通過兩個更新的批次來的,經歷了兩次版本變化而來,可以看做是fact table。同時Table C是Table B的物化檢視,rollup的SQL如下:
SELECT SUM(Clicks), SUM(Cost) GROUP BY AdvertiserId, Country |
對於Table B的每個mini-batch更新,物化檢視都保持了和fact table的一致原子更新。
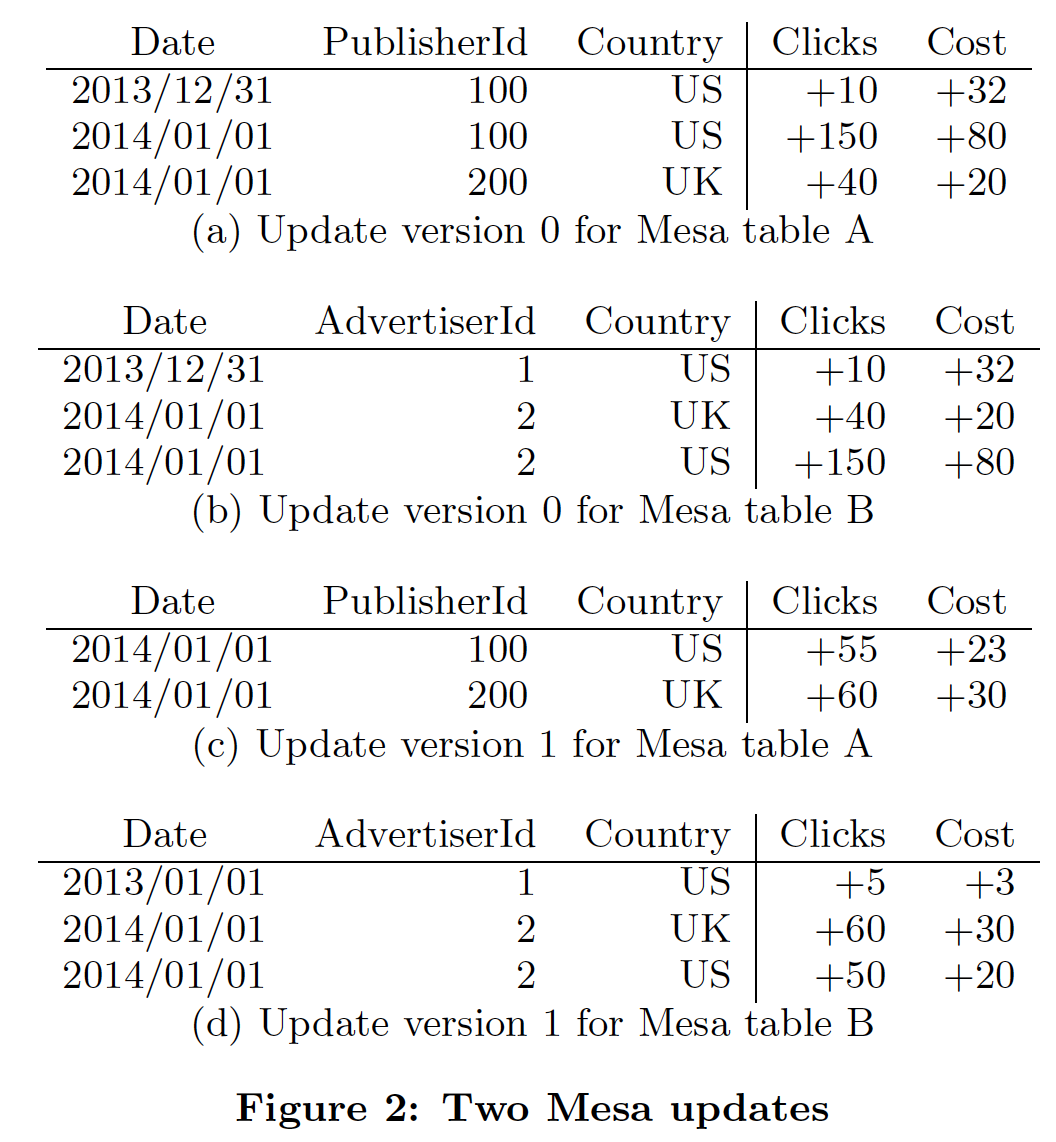
另外對於一些backfill和回滾資料的需求,比如某天的資料有問題,通常廣告領域就是反作弊後而後知,那麼Mesa提出了negative facts的概念,也就是做減法即可,從最終一致的角度來做回滾。
1.1.3 資料版本化
上一節提到了每個批次都版本化的概念,但是具體實現的困難要考慮:
1)每個版本獨立儲存很昂貴,浪費空間(而聚合後的資料往往更加的小)。
2)在查詢的時候going over所有的的版本並且做聚集,考慮每個版本是分鐘級生成了,那麼每天的量也會很大,這種expensive的操作很影響線上的查詢延時。
3)傻傻的針對每一次更新,都在所有的版本上做預聚合,也非常的expensive。(看看bigtable、leveldb的多級儲存結構,就知道merge sort實時做每一個批次,系統是吃不消的)
為了解決這三個問題,Mesa的方案是:
提出Delta的概念,對於每次的更新,相同的Key都做預聚合,形成一個獨立的Singleton delta,一個Singleton delta包括很多rows,以及一個version = [V1, V2]。在某些場景下可能會不儲存原始資料,也就不能drill down到最細的粒度了,但是做了上卷所以會非常節省空間。
Delta之間可以做merge,例如[V1, V2]和[V2+1, V3]可以合併成[V1, V3],下面物理儲存章節會提到每個delta內部資料都是有序的,所有隻需要線性時間複雜度(linear time),即最簡單的merge sorted array就可以合併好兩個delta。
Mesa要求查詢指定的版本號不能無限的小,需要在一個時間範圍前(比如24小時之內),這是因為還會存在一個Base compaction的策略,用來歸併所有的歷史delta,這和bigtable中的概念一樣,主要從查詢效率來說,通過合併小檔案來減少隨機I/O的次數。合併了base之後,這些老版本的delta就可以刪除掉了。
但是base compaction往往是天級別做,因為很expensive,但是考慮分鐘級別的匯入,也會有成百上千的小檔案需要在runtime的時候做查詢,也就多了非常多的隨機I/O。為了加速實時的線上查詢,並且平衡匯入的高吞吐,Mesa提出了多級的compaction策略,這裡Mesa實際用了兩級儲存,會存在一個cumulative compaction的過程,例如每當積累到10個Singleton delta,就做一次小的多路歸併,合併成一個cumulative delta。再積累了10個之後再做一次多路歸併即可。
舉個例子,下圖的中Base是24小時之前的檔案,天粒度聚合而成。存在61-92這些個singleton delta,它們都是每個mini-batch匯入的預聚合好的資料,如果不存在cumulative delta,那麼假如查詢條件的版本指定到91,那麼就需要base,外加61-91這32次的隨機I/O,這種延遲明顯太大了,那麼如果有了cumulative就可以按照最短路徑的演演算法,做一次查詢只需要base,加61-90這個cumulative,加91這一個delta,一共3次隨機I/O就可以查詢出來結果。

1.1.4 物理儲存格式
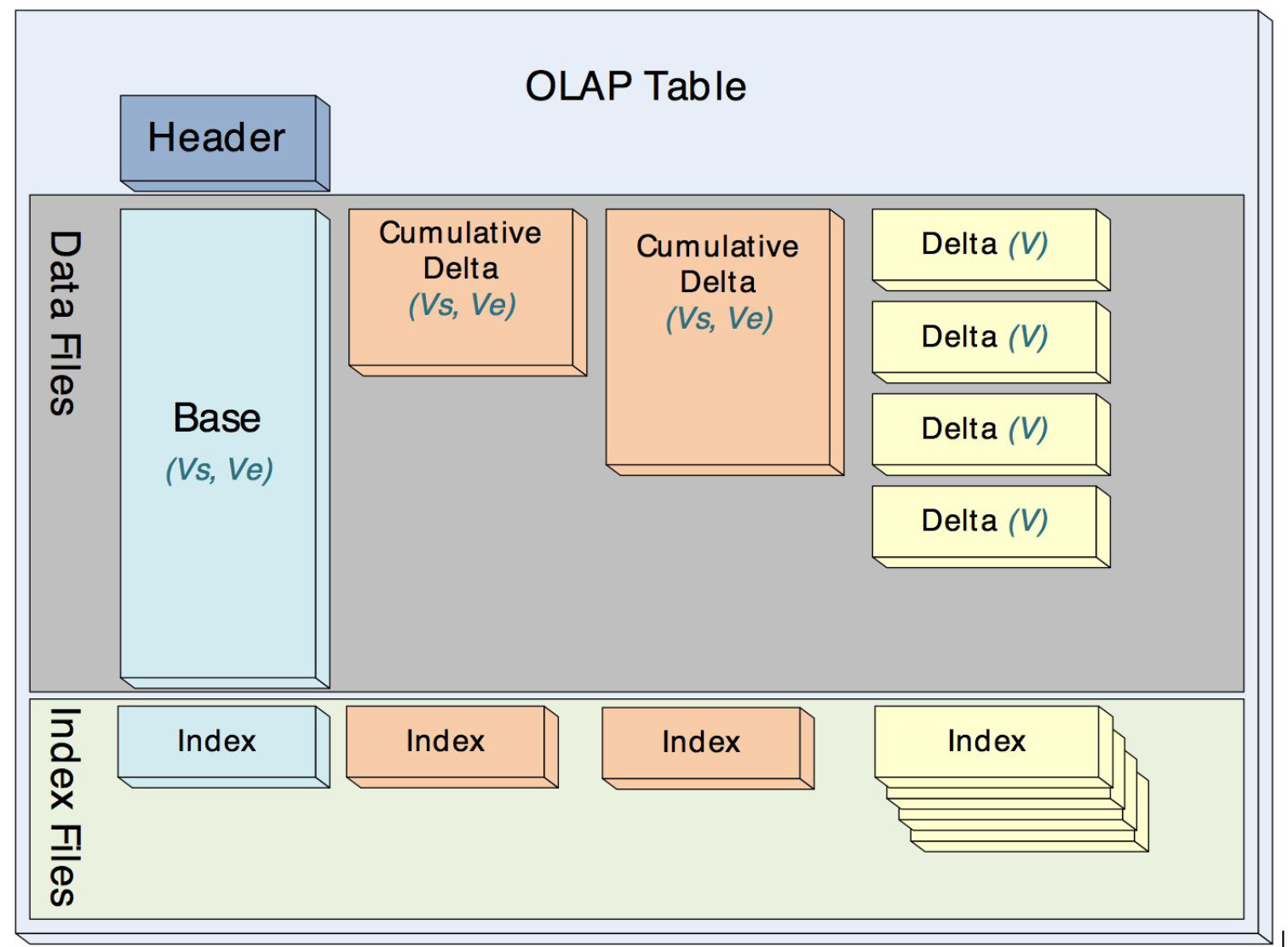
Mesa中的delta、cumulative和base在物理儲存上格式一樣,它們都是immutable的,這樣就很方便做mini-batch的增量的更新,而不至於很影響吞吐,因為compaction過程都是非同步的。
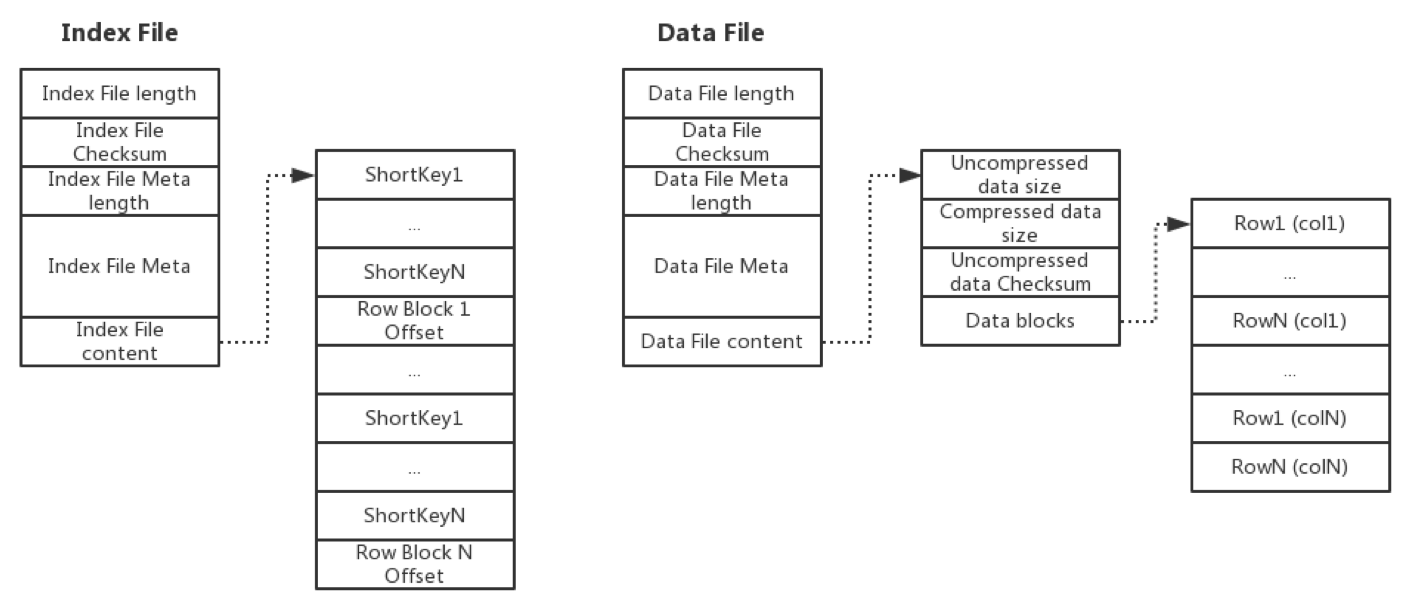
Mesa的儲存格式要儘可能的節約空間,同時支援點查(fast seeking to a specific key),Mesa設計了索引Index和資料Data檔案,物理上Index和Data資料是分開的,每個Index實際就是Short Key的順序排列外加offset偏移量,每個Data就是Key+Value的順序儲存。每個表都是這樣多個Index和多個Data的集合。
Mesa對於儲存格式並沒有展開說很多,但是提到了一些重點。Data檔案中的資料按照Key有序排列,按行切塊形成row block,按列儲存,這種格式和現在的ORC、Parquet很像,Row Block的大小一般不大,它是從磁碟load到記憶體的最小粒度,使用這種格式很容易做壓縮,因為每一列的格式都是相同的,可以做一些輕量級的編碼比如RLE、字典編碼、Bitpacking等,在這個基礎之上再做重量級的壓縮,比如LZO、Snappy、GZIP等,就可以實現壓縮比很高的儲存。
Index檔案儲存了Short Key,Short Key關聯一個Row Block,這樣只需要把Index載入到記憶體,在Index檔案中做naive的二分查詢定位Row Block在Data檔案中偏移量offset,然後load Row Block載入到記憶體,再做一些Predicate filter的Scan,對於Key相同的按照聚合函數做聚合即可把結果查到。
對於Mesa的儲存模型,實際的物理上的檔案可能會存在多個,如下圖所示。
每一對Index file和Data file的格式如果實現的最簡單,可以如下圖所示。如果按列儲存可以設計的更豐富,比如Parquet的資料儲存格式就為了支援巢狀的資料結構、方便做謂詞下推做了很多的設計。
1.2 系統架構
這一部分分為兩塊,第一是單DC(Datacenter)部署,第二是跨DC部署。這裡不得不說Google的論文雖然丟擲來的,但是細節都是很模糊的。
1.2.1 單DC部署
兩個子系統Update/Maintenance Subsystem和Query Subsystem分開,這樣也是為了滿足其高吞吐準實時匯入,低延遲查詢的系統要求而做的技術選型。
Update/Maintenance Subsystem
主要職責包括,
1)載入update,並且按照儲存模型儲存到Mesa的物理儲存上。
2)執行多級的compaction。
3)線上做schema change。
4)執行一些表的checksum檢查。
系統架構圖如下:
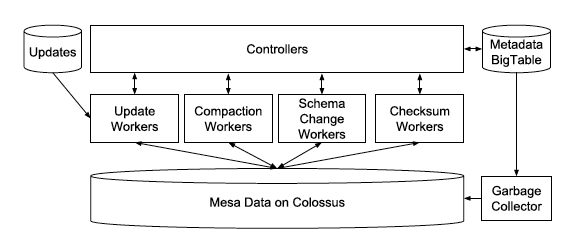
Controller可以看做是一個metadata的cache,worker的排程和queue的管理都它來。所有的metadata都儲存在BigTable中,所以Controller可以是一個無狀態的stateless的服務。Controller管理了4類worker,就是剛在提到的4個職責,各對應4種worker,Controller通過RPC接收外部的請求,然後把任務Task投遞到queue中。
Worker採用隔離的策略,4種職責各4個Worker Pool。Worker採用「拉」的策略,從queue中取任務,然後執行,例如載入update,取到任務後從任務的metadata中獲取原始資料(比如CSV檔案)儲存的位置以及做一些資料校驗工作,然後做預聚合形成Singleton delta,儲存在Google的HDFS即Colussus中,然後再更新metadata commit這個版本已經incorperate到系統中形成了delta,外部可供查詢。圖中還有一個GC(Garbage Collector),這個就是Worker銷燬的,防止Worker死掉從而saturate整個Worker Pool。
這套Controller/Worker的架構,從下面要說的查詢系統中分離出來,充分體現了分治的策略,互不干擾。這裡Table可能很大,所以Controller也是做了sharding的,來更好的做擴充套件,同時Controller不存在單點(SPOF),一旦有問題handoff到另外一個stand by即可,因為所有的metadata都在BigTable中儲存。
Query Subsystem
查詢子系統架構如下圖所示。
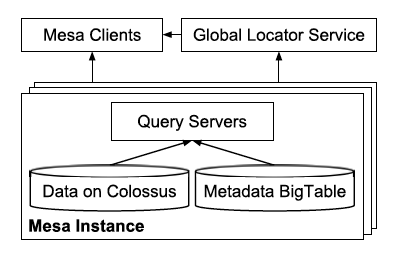
一次查詢的步驟如下:獲取使用者請求,例如SQL,根據metadata,做校驗、語法解析、詞法解析、查詢計劃生成等,決定了需要查詢哪些檔案;發起查詢請求,並且做歸併聚合處理;將結果轉換為使用者端需要的格式,響應回去。
Mesa作為一個簡單的通用儲存查詢系統,只提供了有限的語意,包括filter和group-by,剩下的Higher-level的語意包括JOIN、子查詢等等都由上層系統做,比如Google的Dremel或者MySQL。
這裡論文還提到查詢系統的lable化,因為線上的reporting要求低延遲,一般是點查,而Ad-hoc的分析查詢一般要求高吞吐,為了防止二者互相干擾,還是採用了分治策略,把不同的query system貼上不同的label,這樣在查詢的時候可以有選擇的路由。
圖中的global locator service是每個query system啟動時候去註冊的,這樣client就可以根據label或者要查詢的表路由到正確的query server上。
1.2.2 跨DC部署
架構圖如下。
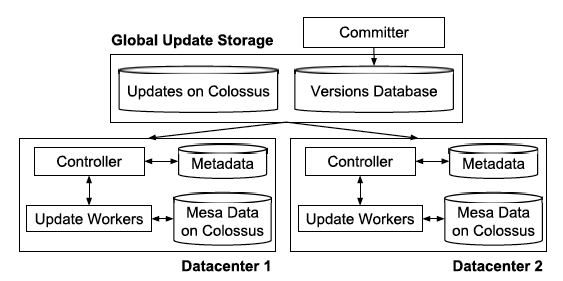
由於每個更新批次都是版本化的,所以採用MVCC機制,存在一個committer做upstream service和mesa的橋樑,對於每個update都儲存在一個versions database – a globally replicated and consistent data store build on top of the Paxos consensus algorithm,實際可以看做spanner/F1中,然後依次的下發各個DC,每個DC內部都是剛剛提到的架構,Controller負責監聽新的version,拉取update並且更新本DC,成功後notify versions database,committer不斷的檢查是否commit criteria滿足了,比如5個裡面3個成功了,那麼commit這個version,再繼續下個批次的更新。
這種方案的好處在於,多個DC無鎖化和非同步化,用以滿足高吞吐的匯入和低延遲的查詢。
最後,論文還提到了一些Enhancements,包括query server的,使用MapReduce並行化處理worker任務的,如何做線上schema變更的,如果防止資料損壞(包括儲存的checksum,和非同步的檢查等等)。一些lesson learned,可以說是分散式系統設計裡面的common patter和容易踩到的坑的總結,可以好好讀讀。剩下的就是metrics對比了,這裡不再贅述。
基本來說,Mesa論文還是很偏理論的,並且集中聚焦在資料模型上,這點我認為是貢獻最大的,下面要講的PALO也是借鑑了其資料模型。
2. PALO
2.1 簡介
說完了Mesa,說說PALO,PALO是百度2017年開源的專案,由於筆者之前有百度6年的工作的經歷,也使用過該專案的前身OlapEngine,所以這裡簡單的介紹下。
Palo名字的由來是「玩轉OLAP」,把OLAP倒過來就是PALO。還是抓住github首頁的介紹關鍵詞:
A MPP-based Interactive Data Analysis SQL DB
PALO是基於MPP架構的,一個互動式的資料分析的SQL DB。注意其定位是一個DB,而不是像巨量資料領域的MPP比如開源的Presto、Impala那樣的純查詢引擎(query engine),所以PALO即包含儲存引擎,也包含查詢引擎(這裡借鑑了Impala),而Presto、Impala的儲存都採用了開源的格式和儲存引擎,比如ORC、Parquet等,PALO的儲存格式借鑑了Mesa,所以這就是PALO和Mesa的聯絡,PALO=Mesa的儲存引擎+Impala查詢引擎的開源實現。
百度內部一直有各種需求,比如statistics廣告統計報表就是典型。要支援增量更新,近實時,還需要提供低延遲的查詢,又要給批次的、高吞吐的Ad-hoc查詢做多維分析(比如BI系統)。過去用Mysql、Doris支援,但是都不理想。 而大家真正需要的是一個MPP SQL Engine。所以大家就有的搞MPP類的SparkSQL、Impala、Presto、Drill,有的搞MOLAP類的Druid、Kylin,有的考慮買商業資料庫(比如Greenplum,Vertica,AtScale),有的考慮用Amazon Redshift、Google BigQuery,有的嘗試了MonetDB等,所有方案基本都是因為較為複雜,或者不免費,或者不穩定,或者並不能很好的各種滿足需求,所以才逐步研發了PALO。
PALO是面向百TB ~ PB級別的查詢的產品,僅支援結構化資料,可供毫秒/秒級分析,是由百度巨量資料部團隊研發的,經歷了三代的產品Doris -> OlapEngine ->PALO,其中Doris是2012年之前廣告團隊採用的報表查詢系統,而OlapEngine是基於MySQL的一個查詢引擎,類似InnoDB或者MyISAM,也是借鑑了Mesa,最早是James Peng在鳳巢、網盟實施指導研發的專案,2014著手改造OlapEngine到PALO,PALO代表了當下state of the art的該類系統,目前廣泛應用於百度,150+產品線使用,600+臺機器,單一業務最大百TB。
PALO也可以看做是一個資料倉儲DW,因為借鑑的Mesa的模型,所以兼具低延遲的點查和高吞吐的Ad-hoc查詢功能。PALO支援batch loading和mini-batch即近實時的loading。和其他SQL-on-hadoop不同的是,PALO官方給出的特殊賣點是:
1)低成本的構建穩定可延伸的OLAP系統,開源免費並且可工作在普通機器上。
2)簡單易用的單一系統,拒絕hybrid architectures,不依賴Hadoop那套,架構簡單,並且可以使用MySQL協定接入。
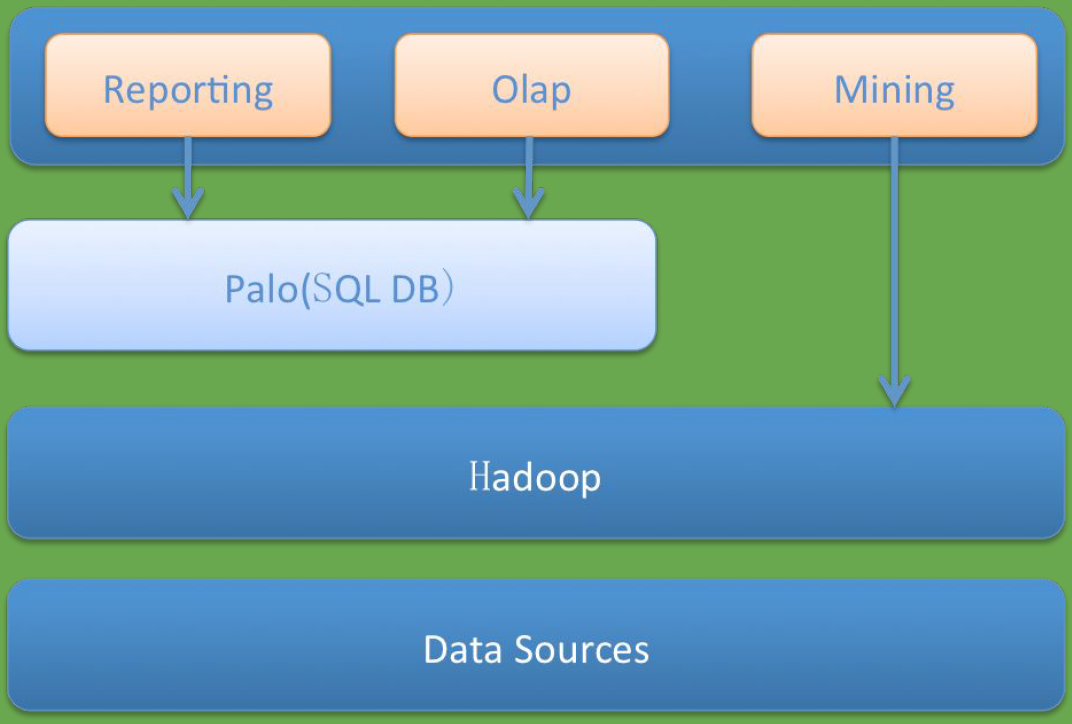
下圖展示了PALO的定位。
2.2 PALO的特點
- 1) 高效能的行列儲存引擎
- 2) 小批次更新,批次原子提交,多版本支援
- 3) 高效的分散式資料匯入
- 4) 支援Rollup Table, Scheme Change, Data Recovery
- 5) 較完備的分散式管理框架,使得整個PALO易用易運維
- 6) Range partition: 全域性key排序,自動分裂還沒有滿足
- 7) MPP Query Engine – 低並行大查詢 + 高並行低延遲小查詢
- 8) 排程和資源隔離還在完善,支援優先順序劃分和多租戶
- 9) 儲存分級支援,老資料用SATA,熱的新資料用SSD
- 10) 實現了Mysql網路協定,可以很容易與各種上層工具打通
- 11) 支援多表join(這點由於自己實現了查詢引擎,所以彌補了Mesa儲存引擎的不能實現的)
- 12) Rollup表智慧選擇
- 13) 支援謂詞下推
2.3 PALO的系統架構
架構圖如下。
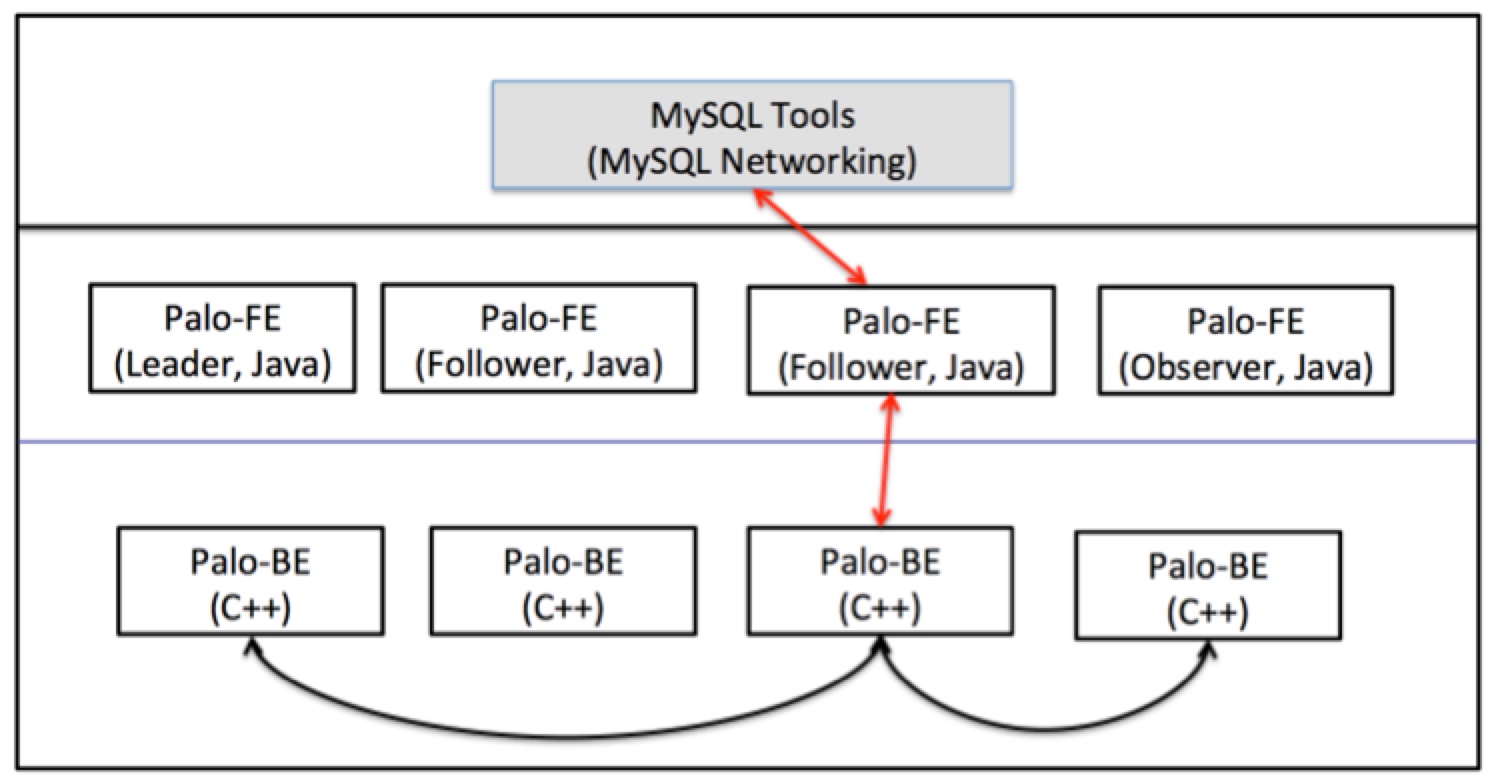
FE包含query coordinator and catalog manager。Query coordinator接收SQL請求,根據後設資料,編譯成query plan,然後建立query plan fragments,生成一個DAG執行的pipeline用於分發給BE執行(如下圖所示,是impala中的query plan到實際物理執行的DAG的轉換,可以把at HDFS和at HBase看做是BE執行的節點),Query coordinator統籌管理排程執行,這相當於Impalad的Query coordinator。Catalog manager存metadata,包括資料庫、表、分割區、副本位置等等。多個FE可以保證HA和負載均衡。
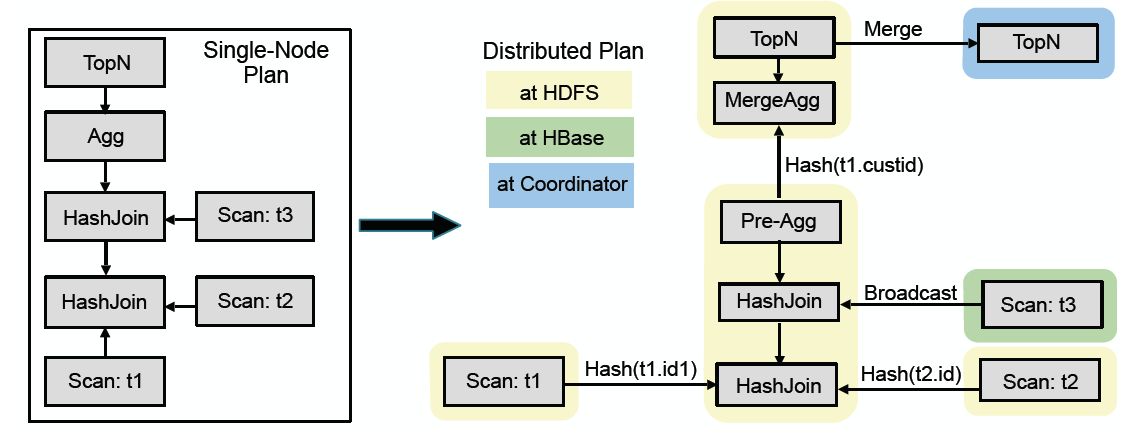
(圖片來源:Impala論文)
FE是非對稱的架構,這和Hive、Impala等的中心架構不同,所有的metadata不是儲存在一個公共的服務上,在FE當中做了一個基於Paxos-like consensus演演算法的複製狀態機,這樣可以可靠的儲存資料,並且檢具擴充套件性,滿足高並行的查詢。FE分為三個角色,包括leader, follower和observer,leader負責寫入,follower用分散式一致性演演算法做同步紀錄檔,quorum方式使得follower成功,然後再commit。高並行場景下,多個follower會有問題,就像Zookeeper一樣,所以引入了observer角色,專門做非同步同步。FE中的複製狀態機用Berkeley DB java version實現,FE和BE的通訊使用Thrift框架。
PALO易用性好的一個方面也體現在其FE相容MySQL協定上,也就是可以用MySQL client,JDBC等直接連線FE,發起DML、DDL語句,這樣也就非常好的可以和BI系統整合。
BE負責儲存資料、執行query fragments(這是impala論文裡面提到的),BE就是一個query engine。BE沒有依賴任何分散式儲存,例如HDFS,而是自己負責管理多個副本,副本數量是可以指定的,由寫入的updater負責寫入多個副本,檔案系統全是PALO自己管理的,所以PALO是一個DB,而不是一個其他巨量資料開源產品,例如Presto、Impala那樣的查詢引擎。FE在做query排程的時候會考慮資料的本地性(locality)以及最大化scan的能力。多個BE部署可以達到scalability and fault-tolerance。
PALO中的資料是水平分割區的。按照桶bucket分割區,但是Single-level不管是hash或者range都可能會有問題,比如hash(userid)或者range(date)都會不均勻,存在資料傾斜現象,所以PALO把這個shard的策略做成了可以支援Two-level。第一級是range partitioning,一般採用日期,方便做冷熱資料區分不同的儲存媒介(SATA或者SSD),第二級是hash partitioning,可以看做是分桶,所以PALO要求使用者做好這個分割區分桶。如果使用者執意把1TB大小的資料放到一個桶裡面,那麼這種不合理的使用和規劃,會影響PALO BE的查詢效能,因為BE執行一個Scan query fragments就是去按照Mesa的模型讀取Index和Data資料,一個MPP的思想就是並行化,這種大分桶也就限制了系統發揮能力,目前PALO還不支援自動分裂,不像HBase那這樣,所以這個分割區和分桶的策略是做schema design的時候要提前考慮好的。
這裡要提下PALO基於Mesa的資料模型和儲存模型,但是Mesa需要區分維度列和指標列,而一個通用的OLAP系統往往不能區分這些列,所以PALO為了做一個通用的OLAP,可以做到不區分這個維度列和指標列。即使不區分維度列和指標列,但是PALO借鑑了Mesa的儲存模型,所以如果沒有Key Space,那麼就必須指定一個排序列,用於儲存需要。
PALO在效能追求上也是儘量做到最好。PALO的核心BE是使用C++開發的,這和Impala的思路很類似,Java的GC和記憶體控制一直是詬病,為了追求效能的極致,PALO選擇了C++作為開發語言更好的控制。同時PALO支援一些流行的OLAP優化手段,包括向量化執行和JIT,C++使用LLVM。PALO支援分割區剪枝(Partition pruning),支援bloomfilter做某列的索引,同時Index中會儲存MIN/MAX等基本資訊,方便做Predicate pushdown謂詞下推。由於基於Mesa,會利用預聚合的方式,使用物化檢視和做上卷表,在某些場景下可以大大加速查詢效率。綜上,這些都加速了OLAP的查詢效能。
2.4 PALO總結
這裡由於筆者的精力有限,還沒有大規模使用PALO,暫且對於PALO的認識就限上面所述。作為一個前老百度人,對於百度開源產品還是很看好的,在公司內這可是明星級別的並且廣泛應用的產品,雖然現在剛剛開源,在產品化、檔案、工具、排查、穩定性等方面還需要完善和經受考驗,但是如果這個產品可以解決大家的痛點,作為building blocks可以幫助企業快速解決問題,我想社群的力量是巨大的,一定會把它發揚光大好,希望PALO未來的路越走越好。