深度學習《CNN架構》
摘要:今天來寫第一篇深度學習的博文,也是學習CNN的第一篇。
騷話一下:
今天是2020年10月1號,是祖國的71歲生日,也是傳統節日中秋節,而我由於工作的安排身在海外不得回家,懷念祖國的鄉土,倍加思念遠方的親人。
由於疫情,在這裡哪裡也去不了,只能好好學習,用學習來充實這八天假期。
一:CNN的靈感起源
也許CNN就是深度學習過程中的必須且最基礎的網路結構了,下面我們先來回顧下傳統的神經網路的網路結構。
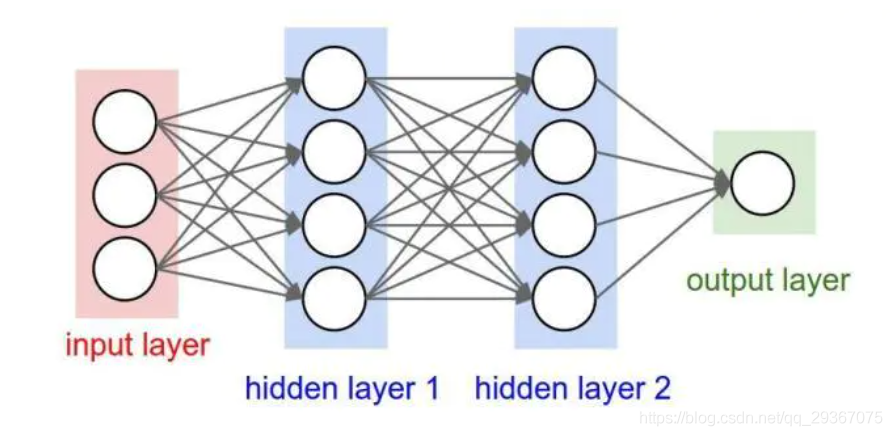
每一層的節點都是和前一層或者後一層的每個節點都是相連線的,分為輸入層,隱藏層和輸出層。我們所學習的CNN在層次結構和層次深度上都是發生了改變,但也是一種網路,是在傳統神經網的基礎上發展出來的一種新的網路,其靈感來自於腦神經。
人類的視覺原理是這樣的:從原始的畫素訊號攝入開始,接著做初步處理(大腦皮層某些細胞發現影象的邊緣和方向),然後進一步抽象(大腦判定物體的形狀),然後進一步抽象(大腦進一步對物體進行識別)。如下圖是一個臉部辨識的例子:
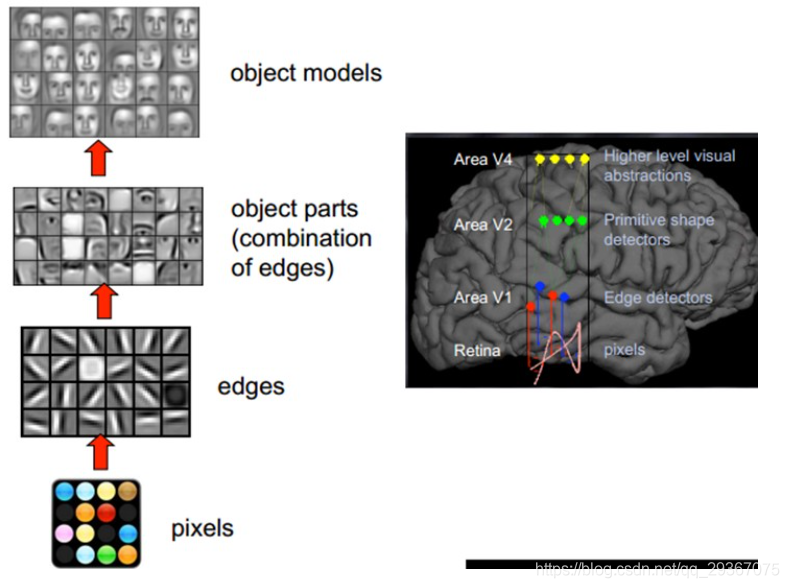
我們的大腦視覺神經是逐層分級的,在最底層特徵基本上是類似的,就是各種邊緣,越往上,越能提取出此類物體的一些特徵(輪子、眼睛、軀幹等),到最上層,不同的高階特徵最終組合成相應的影象,從而能夠讓人類準確的區分不同的物體。
CNN的靈感就是來自於大腦神經細胞視覺分層處理,模仿人類大腦的這個特點,構造多層的神經網路,較低層的識別初級的影象特徵,若干底層特徵組成更上一層特徵,最終通過多個層級的組合,最終在頂層做出分類。
也可以說是,我們看物體不是一上來就是全部,而是第一反應是看到了某個區域,再看到另外個區域,逐漸由多個區域拓展到整體,不斷抽取特徵組合起來,最後發現視覺範圍內的所有資訊。
二:CNN的結構
上面我們提到了傳統神經網路的結構圖,我們可以建立不同維度的層次節點,通過前向傳播和後向傳播直接訓練出一個網路模型。
先來看看CNN的網路結構,以著名的先驅者網路LeNet-5網路為例。
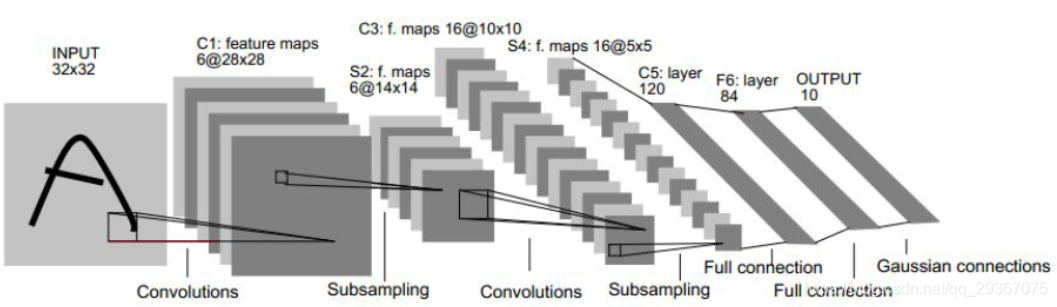
其層次結構包含如下:
1)資料輸入層(input layer)
2)折積計算層(Conv layer)
3)啟用層(activate layer)
4)池化層(pooling layer)
5)全連線層(Fully connection)
6)損失層(softmax loss layer)
我們可以發現,傳統的神經網路存在於CNN的最後一層結構,也就是CNN在傳統的神經網路前加了很多其他的不同的層次結構,下面我將分別進行描述各個層次。
三:資料輸入層
CNN主要運用於影象的處理,這裡的資料輸入主要是對影象進行一些預處理,比如我們常見的二值化處理,灰度化處理,去均值化處理,PCA降維處理(保留主要特徵),還有一些歸一化(去除由於各個維度的範圍差異帶來的干擾)的處理,甚至我們的影象還可以保留RGB三色通道也是可以。
根據自己的設計,設計出一些其他的預處理細節,還比如統一尺寸大小等。
四:折積計算層
至於折積的含義,以及在連續資料的折積和離散資料的折積概念和公式我就不說了,不清楚的化請自行百度,我就直接上過程,直接給出影象的折積,這一層也是非常重要的概念,CNN的名字也是來源於此,所以這裡會多講一些。
至於對影象的折積操作,可以參考上一篇發的相關文章《影象折積》。
這裡需要對摺積層注意幾個問題。
1)維度表示問題
2)Padding問題
3)Stride問題
下面我通過這個範例圖來進行詳細說明:
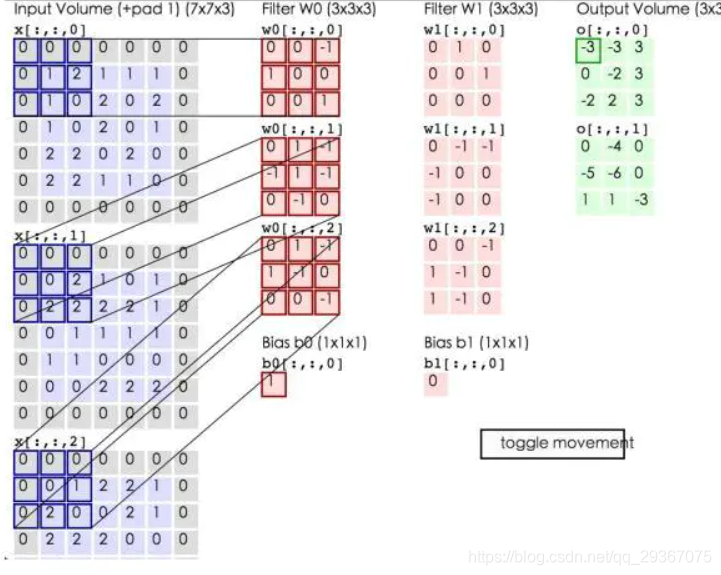
用上圖來表示一下,我們先來一些定義:
1:Input_channel:[N, W, H, C]
N:輸入層的影象個數
C:輸入層的每個影象的通道數,比如每個彩色影象的RGB三通道
W:輸入層影象的寬度
H:輸入層影象的高度
如上圖:輸入層僅一個影象,維度可表示為[1,7,7,3]
2:Kernel_ channel:[M, W, H, C]
M:折積個數。這kernel也可以叫做過濾器Filter。
C:每一個折積的通道數,這個需要和輸入層的每個影象的通道數保持一致。
W:kernel的寬度
H:kernel的高度
某個輸入層影象Img和某個折積kernel_K 做折積,因為通道相同,於是將對應的通道進行折積再相加就可以得到一個輸出影象X,X作為該折積的一個輸出。那麼某個Img跟所有折積對應的通道折積再相加後會得到M個X的影象輸出,這些X就是該原始影象Img折積後對應於輸出層的新的通道,輸出層的通道數就一共有M個。
該層折積層全部完成後,輸出層的影象的個數是依然N,每個影象的通道數是M,至於輸出層影象的大小是多少,且看後續分析。
如上圖:折積層有2個,每個折積層3個通道,維度可表示為[2,3,3,3]
3:Bias:[M, 1, 1, 1]
M:和折積個數一致,都是一個數位,或者是一個111的矩陣,分別對應於某個折積核。當某個Img和某個kernel_K對應通道折積後,再相加,還需要和這個Bias進行相加,作為影象的整體偏置,該引數可選。
如上圖:折積層有2個,所以偏置也有兩個,維度可表示為[2,1,1,1],分別對應於某個折積核。
4:Padding:輸入層的影象外圍補0的層數。
5:Stride:在折積過程中,kernel滑動的步長。
由於,折積得到的影象的大小會有降低,如果那個讓影象大小降低的話,就可要使用padding技巧,邊界的填充,一般選擇補0進行填充。比如,3232的影象,經過55的折積,就得到了一個2828的影象,因為我們沒法對原影象外層的畫素進行折積,因此,我們還可以對原影象進行補0操作,比如給影象外層補上2圈0,原影象變成了3636,折積後,依然是32*32的大小。記做P=2,P是補充的0的圈數。
Stride是步長的意思,也就是折積核沒有刺激在原影象上的移動的步長,預設是1個畫素,也可以設定為其他值,如果stride>1,那麼得到的影象也會縮小大小。比如原影象3232,步長為2折積,那麼得到的影象大小是1616。記做S=2,S是折積滑動的步長。

五:啟用層
一層節點得到了輸入,如果要輸出傳遞給下一層網路之前,一定是需要一個啟用層的,在我們學習過的傳統的神經網路也是經過見到的,那時候我們用的是sigmoid函數,其實有很多可選。
在DL中,我們可選的啟用函數也有很多,在此我列舉了四個啟用函數。
1)sigmoid函數
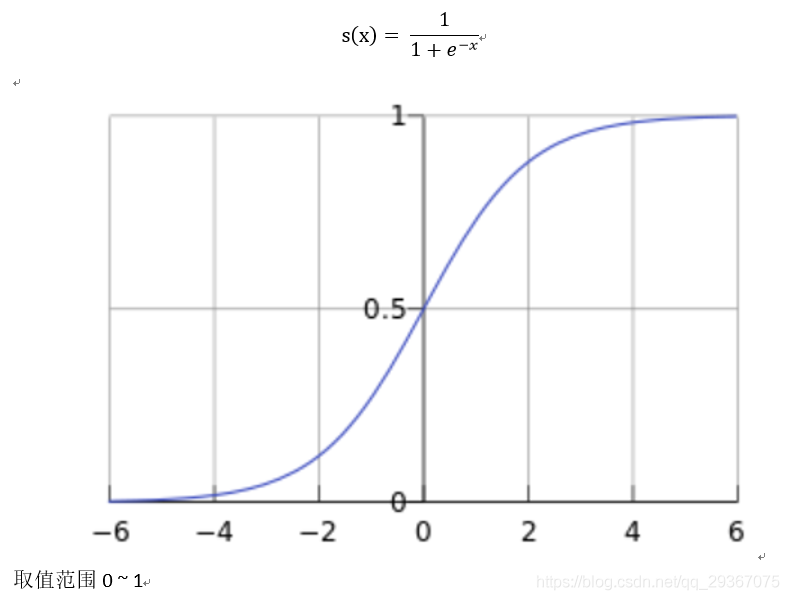
2)tanh函數
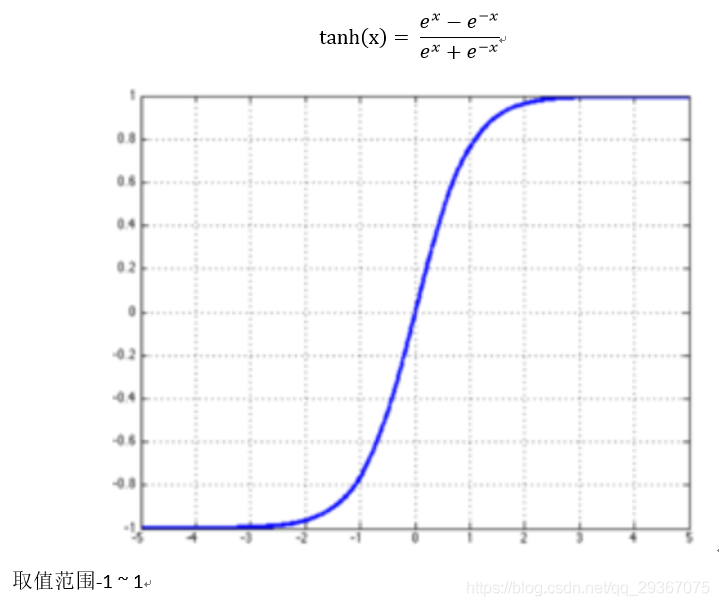
3)Relu(Rectified Liner Uint)函數
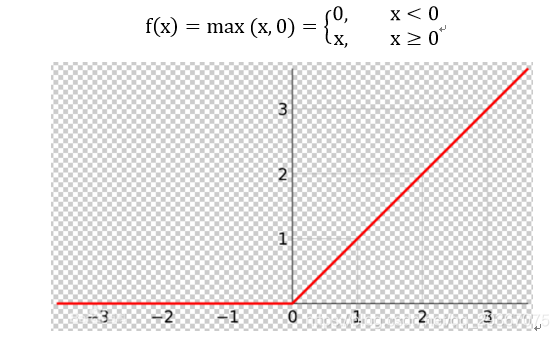
Relu具有求導容易,梯度下降時候計算快,且避免了前倆函數在網路深度很深的情況下的梯度消失的問題(淺顯的網路可以考慮繼續使用前倆啟用函數),因此在深度網路中明收斂速度也會快。這個問題後面會講解。
其缺點就是 Relu的輸入值為負的時候,輸出始終為0,其一階導數也始終為0,這樣會導致神經元不能更新引數,也就是神經元不學習了,這種現象叫做「Dead Neuron」。為了解決Relu函數這個缺點,在Relu函數的負半區間引入一個洩露(Leaky)值,所以稱為Leaky Relu函數。
4)Leaky Relu函數
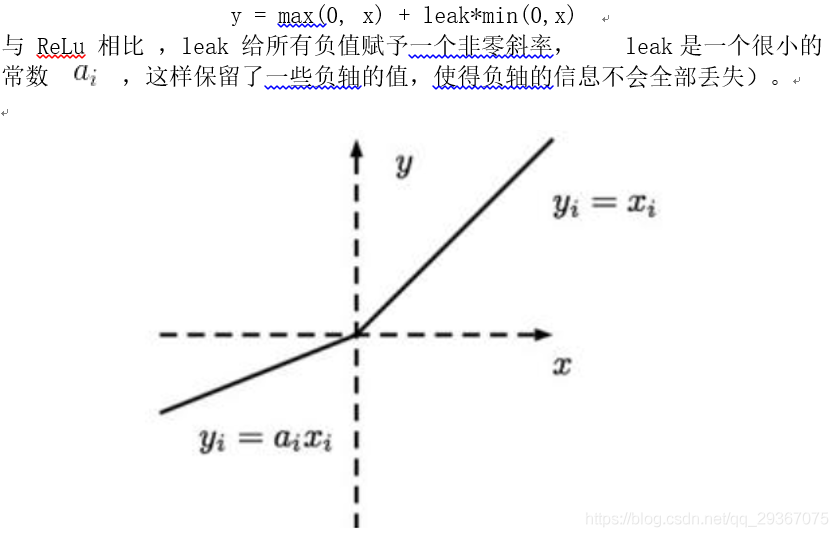
除此之外還有ELU【指數線性單元】、PReLU【引數化的ReLU 】、RReLU【隨機ReLU】等啟用函數,這裡不一一列舉。
ReLU是目前最常用的啟用函數。
六:池化(Pooling)層
為了減少引數,CNN設計了一個取樣層,或者也可以叫做池化層,為了就是將上一層的輸入減少,引數也提取減少。主流的分下面三個
1)Subsample:下取樣,就是對上層影象進行隔行隔列取樣,這樣能原來影象縮小一倍。
2)MaxPooling:用一個F*F的視窗進行取樣,Stride也是設定為F,在每一個視窗內,取畫素的最大值,作為輸出畫素。
3)AvgPooling:用一個F*F的視窗進行取樣,Stride也是設定為F,在每一個視窗內,取畫素的和計算平均值,作為輸出畫素。
下面用一個視窗大小2*2,Stride=2的舉例,截圖自視訊。

七:損失層
這個是CNN的最後一層,計算模型輸出和實際預期的差距和代價損失,這裡介紹一種新的對分類問題的代價計算方式,softmax loss。這裡會稍微詳細介紹下這個損失函數的計算方式和求導過程,分為分類和迴歸兩種。
假設輸出層有C個輸出,在輸出層,暫時不設定啟用函數,因為下面我們要討論的是softmax啟用,我們希望在分類問題中,歸一化成概率描述,就是C個分類,我們希望得出每個分類的概率是多少,挑選出最大的那個概率作為分類結果,而且整個概率相加是1,看似還是很自然的。那麼就有個歸一化的過程。來看看具體的具體計算吧。






至此得到了,最後損失層的代價損失求導過程,在後面梯度下降過程的過程中是有用到的。
至於迴歸問題的代價計算方式,還是使用平方差誤差的計算方式。
八:訓練過程
引數初始化:引數需要隨機初始化,隨機初始化到比較小的數,根據經驗,切記不要隨機初始化到0,不然每一層的每一個節點都會表現一樣。這樣是沒有意義的。
反向傳播,這裡需要根據自定義的網路結構,數學工程,根據連發求導法則自行推匯出每個引數的偏導數,利用梯度下降來搞定。這個後面的文章我會詳細說明。因為梯度下降也有一些優化的技術,比如Batch梯度下降 / 隨機梯度下降 / mini-Batch梯度下降,momentum, RMSprop,Adam,學習率衰減等優化技術。這些我後面會專門寫一篇。
正則化技術:這是為了防止過擬合,這個後面我也會專門寫一篇詳細說明,這個一般情況下,L2正則化,之前也寫過,就基本足夠了,但是還有一個更為先進的方法,dropout方式,以及其他的一些防止過擬合的方式。
九:其他先進的技術
1)batch normalization
2)skip connection
3)group convolution
4)1*1折積運用
這些內容不鋪開,依然是留給後續的文章講解,我不想讓一篇文章過於長了。
十:經典的一些網路設計
著名的網路包括:LeNet5,AlexNet,VGG,ResNet。
這裡依然留給後面再講解,希望能從別人的設計中汲取一些思想,哪怕一點點。
最後感謝如下文章對我的幫助
學習檔案/視訊來自於:
https://www.jianshu.com/p/1ea2949c0056
https://www.cnblogs.com/alexcai/p/5506806.html
https://blog.csdn.net/weixin_38368941/article/details/79983603
https://blog.csdn.net/jiaoyangwm/article/details/80098866
https://blog.csdn.net/jiaoyangwm/article/details/80011656
https://blog.csdn.net/luoxuexiong/article/details/90062937
https://blog.csdn.net/chaipp0607/article/details/101946040
https://www.cnblogs.com/makefile/p/dropout.html
https://v.qq.com/x/page/f03734am317.html