Python和TensorFlow2實現ELMO(Embedding From Language Model)模型,並對原始碼做了一些改進
一、ELMO模型簡介
1.1、模型概要
該模型主要是結合了字元折積神經網路和雙向LSTM網路。其中字元折積網路是生成上下文無關的詞向量表示,接著將該字元折積神經網路的輸出大小調整的LSTM需要的大小512(論文裡面是這個)。再利用LSTM結構提取上下文相關的詞向量表示。
在這裡我想要介紹下這個完整的模型,花了我很多時間,看了無數部落格和文章以及近2000行的論文原始碼才把這個模型徹底搞清楚。啊哈哈哈,也不能說徹底吧,我自己的理解肯定是有限的。希望各位能批評指正,大家一起進步
1.2 、字元折積模組
折積層的構成:
對這個filters二維列表裡面的每個元素,比如[1,32],將使用大小為[1,1,1,32]的折積核大小對輸入大小為[batch_size,unroll_steps,max_word_len,char_vector_dim]的輸入資料進行折積,折積核的第二個位置均為1,因為我們不對時間步維度進行折積,如果這樣,會造成單詞的數量減少。
再比如對於filters列表的第四個元素[4,128],將生成一個大小為[1,1,4,128]的折積核對輸入資料進行折積。
最重要的一點是這些折積層都是並行的,不是串聯。折積層的輸入資料都是同樣的[batch_size,unroll_steps,max_word_len,char_vector_dim],不是將一層的折積輸出作為下一層的折積輸入。
對輸入資料使用不同的折積層作用之後,接著進行最大池化,池化之後的輸出資料大小是[batch_size,unroll_steps,out_channel],這裡的out_channel的取值就是上面的filters的32,32,64,128,256,512,512.因此不同的折積和池化之後並行輸出為[batch_size,unroll_steps,32],[batch_size,unroll_steps,32],[batch_size,unroll_steps,64],[batch_size,unroll_steps,128],[batch_size,unroll_steps,256],[batch_size,unroll_steps,512],[batch_size,unroll_steps,512]大小的資料。
接著將這不同大小的資料在第二個維度進行拼接生成大小為[batch_size,unroll_steps,32+32+64+128+256+512+512]的資料。
1.3 highway net高速公路層
這個不做介紹啦,很簡單的,在網上看到說這個是殘差連線的推廣版,而且是比resnet優先發表的論文,但是效果好像沒有殘差連線效果好。具體我也沒有深究,別的大佬這樣說的,暫時先這樣接受吧,以後再看。
1.4 Projection Layer投影層
由上面可以看出,折積池化輸出的資料大小為[batch_size,unroll_steps,1536],因為32+32+64+128+256+512+512=1536. 啊哈哈哈
那麼就需要經過該層將資料大小調整為雙向LSTM要求的大小[batch_size,unroll_steps,512].我是就是使用了一個Dense層來直接調整的。
1.5 LSTM模型
不想做過多介紹 看圖
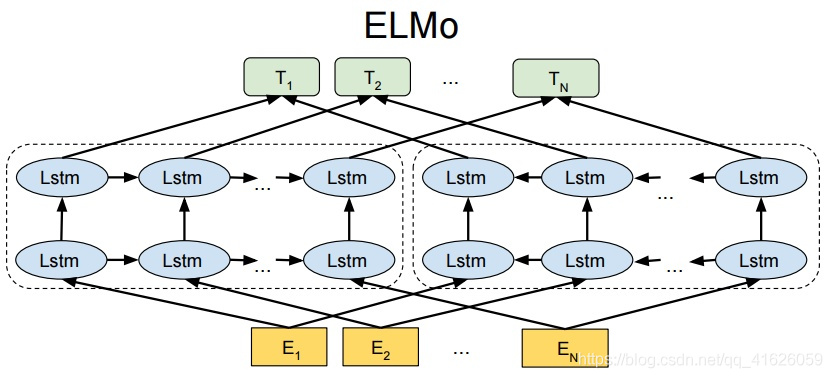
該模型使用輸入預測下一個單詞。不如這句話:今天是國慶節和中秋節。我們可以使用「今天是國慶節」預測「天是國慶節和」,使用「天是國慶節和」預測「是國慶節和中」,使用「是國慶節和中」預測「國慶節和中秋」。
二、ELMO程式碼(程式碼我都加了註釋)
首先是資料處理模組,沒有原始碼處理的那麼複雜,也是結合一點我自己的理解吧,有錯誤歡迎指正。
2.1、建立py檔案ELMO_para.py
該檔案主要用來儲存模型的引數
import argparse
class Hpara():
parser = argparse.ArgumentParser()#構建一個引數管理物件
filters=[
[1, 32],
[2, 32],
[3, 64],
[4, 128],
[5, 256],
[6, 512],
[7, 512]
]
nums=0
for i in range(len(filters)):
nums+=filters[i][1]
parser.add_argument('--datapath',default='./data/test.txt',type=str)
parser.add_argument('--filters',default=filters,type=list)
parser.add_argument('--n_filters',default=nums,type=int)
parser.add_argument('--n_highway_layers',default=2,type=int)
parser.add_argument('--model_dim',default=512,type=int)
parser.add_argument('--max_sen_len',default=8,type=int)
parser.add_argument('--max_word_len',default=50,type=int)
parser.add_argument('--char_embedding_len',default=16,type=int)
parser.add_argument('--drop_rate',default=0.2,type=float)
parser.add_argument('--learning_rate',default=0.02,type=float)
parser.add_argument('--vocab_size',default=74,type=int)
parser.add_argument('--batch_size',default=2,type=int)
parser.add_argument('--char_nums',default=259,type=int)
parser.add_argument('--epochs',default=1,type=int)
2.2 建立py檔案data_processing_modules.py
from tensorflow import keras
import numpy as np
def Create_word_ids(datapath,sen_max_len,n): #n是要控制迴圈的次數,來生成訓練資料train_data和語言模型的標籤target
'''
Parameters
----------
datapath : str
儲存資料的路徑.
sen_max_len : int
訓練資料的長度.
vocab_size: int
詞典大小
n: int
複製多少次訓練資料
Returns
-------
詞典,訓練資料,訓練資料對應的標籤target.
'''
f=open(datapath,'r',encoding='utf-8')
lines=f.readlines()
lines=[line.strip() for line in lines]#去除每行的換行符
t = keras.preprocessing.text.Tokenizer()
t.fit_on_texts(lines)
word_index=t.word_index#生成字典
l=len(word_index)
#向字典裡面新增特殊字元,這裡只新增了一個特殊字元,因為我在資料集裡面已經新增了句子的開始和結束特殊字元
word_index['<unk>']=l+1
whole_sens=' '.join(lines)
whole_sens=whole_sens.split(' ')
len_whole_sens=len(whole_sens)
#構造訓練資料和標籤
train_data=[]
target=[]
for i in range(len_whole_sens-sen_max_len):
train_data.append(' '.join(whole_sens[i:i+sen_max_len]))
target.append(' '.join(whole_sens[i+1:sen_max_len+i+1]))#將資料後移一位,構造標籤,這個模型使用一個文字,然後預測下一個單詞
#比如 對於 ‘我今天吃了一個蘋果’ 可以使用‘我今天’作為一個訓練資料,預測‘今天吃’。使用‘今天吃’預測‘天吃了’ 等等,上面這個迴圈就實現了這個
#下面將訓練資料複製n次
train_data=train_data*n
target=target*n
#下面將句子都轉化為對應id的形式
train_data=t.texts_to_sequences(train_data)
target=t.texts_to_sequences(target)
train_data=keras.preprocessing.sequence.pad_sequences(train_data,maxlen=sen_max_len,padding='post')
target=keras.preprocessing.sequence.pad_sequences(target,maxlen=sen_max_len,padding='post')
return word_index,train_data,target
#上面已經完成將word轉化為id的程式,接下面將單詞轉化為字元的utf-8編碼的id
def Create_char_id_embedding(word_index,max_word_length):
'''
Parameters
----------
word_index : dict
詞典,是單詞和id 的對應關係.
max_word_length : int
因為單詞的長度不一致,因而我們希望傳入一個整數,來控制單詞的長度.
Returns
-------
一個二維矩陣,類似嵌入矩陣,可以將單詞轉化為對應的utf-8編碼.
'''
bow=256 #單詞的起始id begin of word
eow=257 #單詞的結束id end of word
padding=258 #將單詞轉化為utf-8(0-255)編碼的時候,不能使用0填充,因為0也是字元的ascii碼
bos=259 #句子的開始id begin of sentence
eos=260 #句子的結束id end of sentence
dict_len=len(word_index)+1#字典裡面單詞的個數
word_embedding=np.ones([dict_len,max_word_length])*padding#都先初始化為填充的值
#下面開始根據字典構造char_embedding矩陣
for word,id in word_index.items():
l=len(word)
word=word.encode('utf-8','ignore')
word_embedding[id][0]=bow
for i in range(1,l+1):
word_embedding[id][i]=word[i-1]
word_embedding[id][l+1]=eow
return word_embedding
def Create_char_Vector(dim):
'''
隨機生成一個每個字元的vector 比如 a--->[22,55,....],根據上面那個方法,這裡其實是
a對應的ascii碼97轉化為[22,55,....],輸入一個batch的句子,最終生成的資料是[batch_size,time_steps,max_word_len,max_char_vector_len]
,然後對這個四維資料進行折積操作之後調整為LSTM需要資料維度大小[batch_size,time_steps,dim]
Parameters
----------
dim : int
生成字元嵌入的維度.
Returns
-------
一個大小為259*dim的矩陣.
259是因為utf-8編碼有256位字元因為是8位元2進位制,再加上bow,eow和padding,所以總共259個
這是我根據我自己理解弄的,可能和別的程式碼不太一樣
'''
return np.random.normal(0,1,size=[259,dim])
2.3、建立py檔案Model_modules.py
import tensorflow as tf
from tensorflow.keras import layers
class Highway_layers(layers.Layer):
'''
構造ELMO模型裡面的高速公路層
filters': [
[1, 32],
[2, 32],
[3, 64],
[4, 128],
[5, 256],
[6, 512],
[7, 512]
]
'''
def __init__(self,n_filters):
super().__init__(self)
self.carrygate_dense=layers.Dense(n_filters,activation='sigmoid')
self.transform_gate_dense=layers.Dense(n_filters, activation='relu')
def call(self,inputs):
'''
我看網上是這個是殘差連線的一般形式,但是卻沒有殘差連線有效
'''
carrygate=self.carrygate_dense(inputs)
transformgate=self.transform_gate_dense(inputs)
return carrygate*transformgate+(1.0-carrygate)*inputs
#下面是投影層
class ProjectionLayer(layers.Layer):
'''
將資料輸出為LSTM要求的大小,最終是[batch_size,time_steps,dim=512]
'''
def __init__(self,lstm_dim=512):
super().__init__(self)
self.dense=layers.Dense(lstm_dim,activation='relu')
def call(self,inputs):
return self.dense(inputs)
class All_Con_MP_Layers(layers.Layer):
'''
該類主要用來做折積和最大池化操作,並且將七個折積層經過池化後的輸出在最後一個維度拼接起來,最終的輸出的大小是
[batchsize,time_steps,32+32+64+128+256+512+512]的矩陣,然後經過高速公路層和投影層,將矩陣的大小調整為LSTM的
需求的大小,其實也就是為每個單詞生成了一個維度為512的嵌入表示,不過這個嵌入表示是上下文無關的,然後輸入給雙向LSTM,
生成上下文相關的詞向量
'''
def __init__(self,filters):
super().__init__(self)
self.ConvLayers=[layers.Conv2D(num,kernel_size=[1,width]) for i,(width, num) in enumerate(filters)]
self.MaxPoolLayers=[layers.MaxPool2D(pool_size=(1,50-width+1),strides=(1, 1), padding='valid') for i,(width,num) in enumerate(filters)]
def call(self,inputs):
conout=[conlayer(inputs) for conlayer in self.ConvLayers]
mpout=[]
for i in range(len(conout)):
mpout.append(tf.squeeze(self.MaxPoolLayers[i](conout[i]),axis=2))#使用maxpooling作用並且在第三個維度也就是axis=2壓縮張量,經過池化之後的第二個維度的大小是1
#下面在axis=2粘接張量
out=mpout[0]
for i in range(1,len(mpout)):
out=tf.concat([out,mpout[i]], axis=2)
return out
class LSTM_Layers(layers.Layer):
'''
該類主要用來實現雙向LSTM層,並且定義三個引數來將不同的LSTM層輸出的隱向量結合起來
論文中的是直接定義了一個維度為3的隱含層權值,我覺得這樣是不合理的,我認為應該是權值應該是隨
不同的句子而發生變化的,因而我這裡這定義了一個Dense layer,啟用函數使用softmax來輸出一個[batch_size,time_steps,3]
這樣做的目的就是輸出的權值可以根據不同的句子發生變化。
'''
def __init__(self,dim,drop_rate,vocab_size):
super().__init__(self)
#下面定義所需要的LSTM層
self.Lstm_fw_layers1=layers.LSTM(dim,return_sequences=True,go_backwards= False, dropout = drop_rate)
self.Lstm_bw_layers1=layers.LSTM(dim,return_sequences=True,go_backwards= True, dropout = drop_rate)
self.Lstm_fw_layers2=layers.LSTM(dim,return_sequences=True,go_backwards= False, dropout = drop_rate)
self.Lstm_bw_layers2=layers.LSTM(dim,return_sequences=True,go_backwards= True, dropout = drop_rate)
self.layers_weights=layers.Dense(3, activation='softmax')
self.outlayer=layers.Dense(vocab_size+1,activation='softmax')
def call(self,inputs):
self.bilstm1=layers.Bidirectional(merge_mode = "sum", layer =self.Lstm_fw_layers1, backward_layer =self.Lstm_bw_layers1)
self.bilstm2=layers.Bidirectional(merge_mode = "sum", layer =self.Lstm_fw_layers2, backward_layer =self.Lstm_bw_layers2)
h1=self.bilstm1(inputs)
h2=self.bilstm2(h1)
#下面計算權重,在這裡我選擇了將兩個隱層和一個輸入inputs相加在輸入進dense層來計算各層每個隱層和輸入的權重
w=self.layers_weights(inputs+h1+h2)
w=tf.expand_dims(w, axis=2)
out=tf.concat([tf.expand_dims(inputs, axis=2),tf.expand_dims(h1, axis=2),tf.expand_dims(h2, axis=2)],axis=2)
out=tf.squeeze(tf.matmul(w,out),axis=2)
out=self.outlayer(out)
return out
2.4、建立py檔案ELMO_Model.py
import tensorflow as tf
from tensorflow.keras import layers
from Model_modules import Highway_layers,ProjectionLayer,All_Con_MP_Layers,LSTM_Layers
class ELMO(tf.keras.Model):
def __init__(self,para,word_to_char_ids_matrix,char_ids_to_vector_matrix):
'''
該類來搭建完整的ELMO
Parameters
----------
para: 一個引數收納器,用來儲存下面的引數
n_highway_layers : int
進行多少次高速公路層.
n_filters : int
所有折積輸出通道數加起來.
model_dim : int
輸入進LSTM的詞向量的維度大小.
filters : 2d-list
儲存摺積的核大小和輸出的通道數.
drop_rate : float
丟棄率.
vocab_size : int
字典大小.
Returns
-------
[batch_size,max_sen_len,vocab_size+1]是預測的每個詞的概率.
'''
super().__init__(self)
#將word轉化為字元編碼
self.word_embedding=layers.Embedding(input_dim=para.vocab_size+1, output_dim=para.max_word_len, input_length=para.max_sen_len, weights=[word_to_char_ids_matrix],trainable=False)
#下面這個嵌入矩陣是將字元id表示為嵌入向量,是可以訓練的,因為我是隨機初始化的
self.char_embedding=layers.Embedding(input_dim=para.char_nums, output_dim=para.char_embedding_len, input_length=para.max_word_len,weights=[char_ids_to_vector_matrix],trainable=True)
self.HighWayLayers=[Highway_layers(para.n_filters) for i in range(para.n_highway_layers)]
self.Projection=ProjectionLayer(para.model_dim)
self.con=All_Con_MP_Layers(para.filters)
self.lstm=LSTM_Layers(para.model_dim,para.drop_rate,para.vocab_size)
def call(self,inputs):
out=self.word_embedding(inputs)
out=self.char_embedding(out)
out=self.con(out)
for i in range(len(self.HighWayLayers)):
out=self.HighWayLayers[i](out)
out=self.Projection(out)
out=self.lstm(out)
return out
2.5、建立py檔案Train.py
from ELMO_para import Hpara
import numpy as np
hp=Hpara()
parser = hp.parser
para = parser.parse_args()
import tensorflow as tf
from data_processing_modules import Create_word_ids,Create_char_id_embedding,Create_char_Vector
from ELMO_Model import ELMO
def Create_whole_model_and_train(para):
wordindex,traindata,target=Create_word_ids(para.datapath,para.max_sen_len,2)
word_embedding=Create_char_id_embedding(wordindex,para.max_word_len)
char_embedding=Create_char_Vector(para.char_embedding_len)
model=ELMO(para,word_embedding,char_embedding)
optimizer = tf.keras.optimizers.Adam(0.01)#優化器adam
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy() #求損失的方法
accuracy_metric = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')#準確率指標
def batch_iter(x, y, batch_size = 2):#這個函數可以好好看看,確實不錯的
data_len = len(x)
num_batch = (data_len + batch_size - 1) // batch_size#獲取的是
indices = np.random.permutation(np.arange(data_len))#隨機打亂下標
x_shuff = x[indices]
y_shuff = y[indices]#打亂資料
for i in range(num_batch):#按照batchsize取資料
start_offset = i*batch_size #開始下標
end_offset = min(start_offset + batch_size, data_len)#一個batch的結束下標
yield i, num_batch, x_shuff[start_offset:end_offset], y_shuff[start_offset:end_offset]#yield是產生第i個batch,輸出總的batch數,以及每個batch的訓練資料和標籤
def train_step(input_x, input_y):#訓練一步
with tf.GradientTape() as tape:
raw_prob = model(input_x)#輸出的是模型的預測值,呼叫了model類的call方法,輸入的每個標籤的概率,過了softmax函數
#tf.print("raw_prob", raw_prob)
pred_loss = loss_fn(input_y, raw_prob)#計算預測損失函數
gradients = tape.gradient(pred_loss, model.trainable_variables)#對損失函數以及可以訓練的引數進行跟新
optimizer.apply_gradients(zip(gradients, model.trainable_variables))#應用梯度,這裡會可以更新的引數應用梯度,進行引數更新
# Update the metrics
accuracy_metric.update_state(input_y, raw_prob)#計算準確率
return raw_prob
for i in range(para.epochs):
batch_train = batch_iter(traindata,target, batch_size = para.batch_size)
accuracy_metric.reset_states()
for batch_no, batch_tot, data_x, data_y in batch_train:#第幾個batch,總的batch,以及訓練資料和標籤
predict_prob = train_step(data_x, data_y) #對資料集分好batch之後,進行一部訓練
if __name__=='__main__':
Create_whole_model_and_train(para)
上述程式碼還有很多不完整之處,比如測試,評估,模型儲存與載入都沒寫,用的資料集也很小,我的電腦實在是扛不住,望大家理解。窮人不配深度學習。
三、改進之處
上面的程式碼我已經對原始碼做了改進,我看原始碼裡面是在將LSTM隱含層的加權輸出作為詞向量時,只是簡單設定了三個引數用來訓練,我認為這裡應該權重是和不同的句子相關的,於是我將權重設定為inputs的函數,經過softmax輸出權值,這會隨不同的句子輸入而改變LSTM隱含層的權值大小。當然這個改進完全可能來自我對該模型的不熟悉之處,如果有大佬知道,十分歡迎批評指正,萬分感謝。
四、一個小疑問
在看很多文章的時候,看到很多人都在問,既然這個詞向量是動態的,比如apple的詞嵌入,在不同句子裡面是不一樣的,那麼,我將該模型用於下游任務時,該使用哪個詞嵌入呢??
其實我覺得應該是這樣理解:當用於下游任務,一個單詞的嵌入表示是和你當前輸入的句子是有關的,句子的不同,會影響句法和語意的不同。這就會造成同一個單詞的嵌入表示不同。比如‘i want to eat an apple’和‘apple is reall delicious’這兩句話,語意和語法都不同,那麼生成的apple的詞嵌入也是不一樣的,底層的LSTM會捕捉句法資訊,高層的LSTM會捕捉語意資訊。
五、參考文獻
https://arxiv.org/pdf/1802.05365.pdf
https://github.com/horizonheart/ELMO Elmo的註釋版本
https://arxiv.org/abs/1509.01626
https://github.com/horizonheart/ELMO
https://blog.csdn.net/liuchonge/article/details/70947995
https://www.zhihu.com/question/279426970/answer/614880515
https://zhuanlan.zhihu.com/p/51679783
https://blog.csdn.net/linchuhai/article/details/97170541
https://blog.csdn.net/jeryjeryjery/article/details/80839291
https://blog.csdn.net/jeryjeryjery/article/details/81183433
https://blog.csdn.net/weixin_44081621/article/details/86649821
https://jozeelin.github.io/2019/07/25/ELMo/
https://www.cnblogs.com/jiangxinyang/p/10235054.html
最後祝大家中秋節和國慶節快樂,也祝福天津大學125週年啦,有幸成為天大人,希望越來越好。大家也加油!!!!
完整程式碼:連結:https://pan.baidu.com/s/1ZvSGtACrogyUtcRMCfXrig
提取碼:udif
複製這段內容後開啟百度網路硬碟手機App,操作更方便哦