協程實現網路伺服器
對於作業系統而言,程序是最小的資源管理單元,執行緒是最小的執行單元。對於一個執行緒,在使用中,效能可能會受到以下因素的影響:
- 涉及到執行緒阻塞狀態和可執行狀態之間的切換
- 執行緒上下文的切換
- 同步鎖
- ……
所以引入協程——更加輕量級的執行緒。
就像程序和執行緒的關係一樣,一個程序可以擁有多個執行緒,一個執行緒可以擁有多個協程。
協程是在使用者態執行的,所以不會像執行緒切換那樣消耗資源,使效能得到提升。可以說,執行緒是一個特殊的函數,這個函數可以在某個地方掛起,並且可以在掛起處繼續執行。一個執行緒內可以由多個這樣的特殊的函數在執行,但是一個執行緒的多個協程的執行是序列的。如果是多核CPU,多個程序或一個程序內的多個執行緒是可以並行執行的,但是一個執行緒內協程卻絕對是序列的。畢竟協程仍然是一個函數,一個執行緒內可以執行多個函數,但是每個函數都是序列執行的。當一個協程執行時,其他的協程必須被掛起。
C語言上下文切換的庫ucontext:
typedef struct ucontex {
stack_t uc_stack; // 當前上下文要用到的棧
mcontext_t uc_mctx; // 跟硬體相關的資訊
struct ucontext *uc_link; //儲存當前context結束後繼續執行的context記錄
sigset_t uc_sigmask; // 存的上下文的執行期間要遮蔽的訊號集合
}ucontext_t;
// stack_t結構體
typedef struct {
void *ss_sp; // 棧的起始位置
int ss_size; // 棧大小
int ss_flags; // 標誌
}stack_t;
- int getcontext(ucontext_t *ucp); 獲取當前上下文
- int setcontext(const ucontext_t *ucp); 將當前程式上下文置為ucp指向的上下文
- void makecontext(ucontext_t *ucp, void (*func)(), int argc, …);修改ucp指向的上下文, 上下文轉而指向函數func, argc是傳入引數個數, …為傳入引數(直接就是引數, 不用指標),也就是構造上下文。
- int swapcontext(ucontext_t *oucp, const ucontext_t *ucp);儲存當前上下文, 切換到新的上下文, 等於是先執行getcontext(oucp) 再執行setcontext(ucp)
寫個程式感受一波 getcontext() 和 setcontext()
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <ucontext.h>
int main() {
int i;
ucontext_t ctx;
getcontext(&ctx);
printf("i = %d\n",i++);
sleep(1);
setcontext(&ctx);
}
先解釋一波:首先 getcontext() 獲取上下文,然後往下邊執行,執行到 setcontext() 就會去執行getcontext() 獲取到的上下文,也就是說就會回到 getcontext() 所在位置繼續往下執行,從而形成一個迴圈,迴圈的列印 i 的值,結果如下:

再來個程式感受一波 makecontext() :
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <ucontext.h>
void fun() {
printf("fun()\n");
}
int main() {
int i = 1;
char *stack = (char*)malloc(sizeof(char) * 8192);
ucontext_t ctx_main;
ucontext_t ctx_fun;
getcontext(&ctx_main);
getcontext(&ctx_fun);
printf("i = %d\n",i++);
sleep(1);
ctx_fun.uc_stack.ss_sp = stack;
ctx_fun.uc_stack.ss_size = 8192;
ctx_fun.uc_stack.ss_flags = 0;
ctx_fun.uc_link = &ctx_main;
makecontext(&ctx_fun, fun, 0);
setcontext(&ctx_fun);
printf("main exit\n");
return 0;
}
解釋一波:main 函數首先 getcontext(),獲取 main 函數的上下文 ctx_main,ctx_fun 在下邊使用了 makecontext(),使得 ctx_fun 的上下文變成了 fun()函數,所以程式會先列印一個 i = X,接著去 fun 函數列印 fun() 因為 ctx_fun 的連線的 ctx_main 所以又陷入一個迴圈,列印完 i 的值,列印 fun()

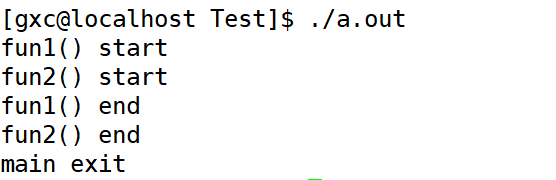
來個程式碼感受 swapcontext();
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <ucontext.h>
ucontext_t ctx_f1;
ucontext_t ctx_f2;
ucontext_t ctx_main;
void fun1() {
printf("fun1() start\n");
swapcontext(&ctx_f1, &ctx_f2);
printf("fun1() end\n");
}
void fun2() {
printf("fun2() start\n");
swapcontext(&ctx_f2, &ctx_f1);
printf("fun2() end\n");
}
int main() {
char stack1[1024 * 8];
char stack2[1024 * 8];
getcontext(&ctx_main);
getcontext(&ctx_f1);
getcontext(&ctx_f2);
ctx_f1.uc_stack.ss_sp = stack1;
ctx_f1.uc_stack.ss_size = 8192;
ctx_f1.uc_stack.ss_flags = 0;
ctx_f1.uc_link = &ctx_f2;
makecontext(&ctx_f1, fun1, 0);
ctx_f2.uc_stack.ss_sp = stack2;
ctx_f2.uc_stack.ss_size = 8192;
ctx_f2.uc_stack.ss_flags = 0;
ctx_f2.uc_link = &ctx_main;
makecontext(&ctx_f2, fun2, 0);
swapcontext(&ctx_main, &ctx_f1);
printf("main exit\n");
}
解釋:
首先初始化 ctx_f1 ,它的後繼是 ctx_f2,接著 makecontext() 構造上下文,ctx_f1 的上下文是 fun1() 函數;
初始化 ctx_f2,它的後繼是 ctx_main ,接著 makecontext() 構造上下文, ctx_f2 的上下文是 fun2() 函數。
執行流程:首先主函數遇到 swapcontext(&ctx_main, &ctx_f1),切換到 fun1() 函數,進入 fun1() 函數遇到 swapcontext(&ctx_f1, &ctx_f2) ,切換到 fun2() 函數,進入fun2() 函數遇到 swapcontext(&ctx_f2, &ctx_f1) ,返回 fun1()函數,fun1() 函數執行完,去執行 fun1() 函數的後繼 fun2() ,fun2() 函數執行完,去執行 fun2() 函數的後繼主函數,效果如下:
----------------------------------------------------分割線----------------------------------------------------
所以現在要實現協程,協程的結構體中應該有:回撥函數、協程上下文、協程棧、協程狀態。還得有一個協程排程器來控制所有的協程,具體程式碼如下:
enum State {
DEAD,
READY,
RUNNING,
SUSPEND
};
struct schedule;
// 協程結構體
typedef struct {
// 回撥函數
void *(*call_back)(struct schedule *s, void* args);
// 回撥函數引數
void *args;
// 協程上下文
ucontext_t ctx;
// 協程棧
char stack[STACKSZ];
// 協程狀態
enum State state;
}coroutine_t;
// 協程排程器
typedef struct schedule {
// 所有協程
coroutine_t **coroutines;
// 當前正在執行的協程,如果沒有正在執行的協程為 -1
int current_id;
// 最大下標
int max_id;
// 主流程上下文
ucontext_t ctx_main;
}schedule_t;
協程還得有以下功能的函數,具體的實現,參照最開始的連結
// 建立協程排程器
schedule_t *schedule_creat();
// 協程執行函數
static void* main_fun(schedule_t *s);
// 建立協程,返回當前協程在排程器的下標
int coroutine_creat(schedule_t *s, void *(*call_back)(schedule_t *,void *args),void *args);
// 讓出 CPU
void coroutine_yield(schedule_t *s);
// 恢復 CPU
void coroutine_resume(schedule_t *s, int id);
// 刪除協程
static void delete_coroutine(schedule_t *s, int id);
// 釋放排程器
void schedule_destroy(schedule_t *s);
// 判斷所有協程都執行完了
int schedule_finish(schedule_t *s);
// 啟動協程
void coroutine_running(schedule_t *s, int id);
有了以上函數的功能,使用協程實現網路伺服器的具體思路如下:
做到一請求一協程,而不是一請求一執行緒。因為協程排程器裡邊是用陣列儲存的所有的協程,所以可以用一個迴圈一直去遍歷這個陣列,當哪個協程需要執行的時候,就執行,如果讓出CPU了,就回圈往後遍歷看下一個。在同步的情況下實現了非同步。用一個 current_id 來判斷當前協程是否執行(如果不執行 current_id 置為 -1)。