【資料庫原理與安全】0x02 SQL基礎語法
這裡寫自定義目錄標題
SQL語言概述
▪ SQL(Structured Query Language)
結構化查詢語言,是關聯式資料庫的標準語言
▪ SQL是一個通用的、功能極強的關聯式資料庫語言
包括以下幾個方面:
(1)資料定義(Data Definition)
用來定義資料庫的邏輯結構,包括定義表、檢視和資料庫及索引。
(2)資料操縱(Data Manipulation)
包括插入、修改和刪除資料的操作。
(3)資料查詢(Data Query)
(4)資料控制(Data Control)
包括對資料的安全性控制、完整性規則的描述以及對事務的控制語句。、
目前,沒有一個資料庫系統能夠支援SQL標準的所有概念和特性。
SQL特點
1,綜合統一
集資料定義語言(DDL),資料操縱語言(DML),資料控制語言(DCL)功能於一體。
可以獨立完成資料庫生命週期中的全部活動:
⚫ 定義和修改、刪除關係模式,定義和刪除檢視,插入資料,建立資料庫;
⚫ 對資料庫中的資料進行查詢和更新;
⚫ 資料庫重構和維護
⚫ 資料庫安全性、完整性控制,以及事務控制
⚫ 嵌入式SQL和動態SQL定義
▪ 使用者資料庫投入執行後,可根據需要隨時逐步修改模式,不影響資料庫的執行。
▪ 由於關係模型中實體間的聯絡均用關係標識,資料結構單一性帶來的資料操作符統一。
2,高度非過程化
SQL採用集合操作方式
- 操作物件、查詢結果可以是元組的集合
- 一次插入、刪除、更新操作的物件可以是元組的集合
3,面向集合的操作方式
基本概念
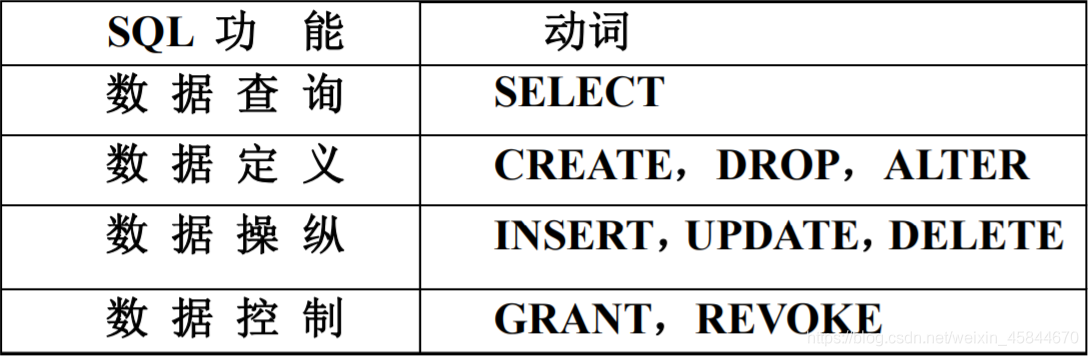
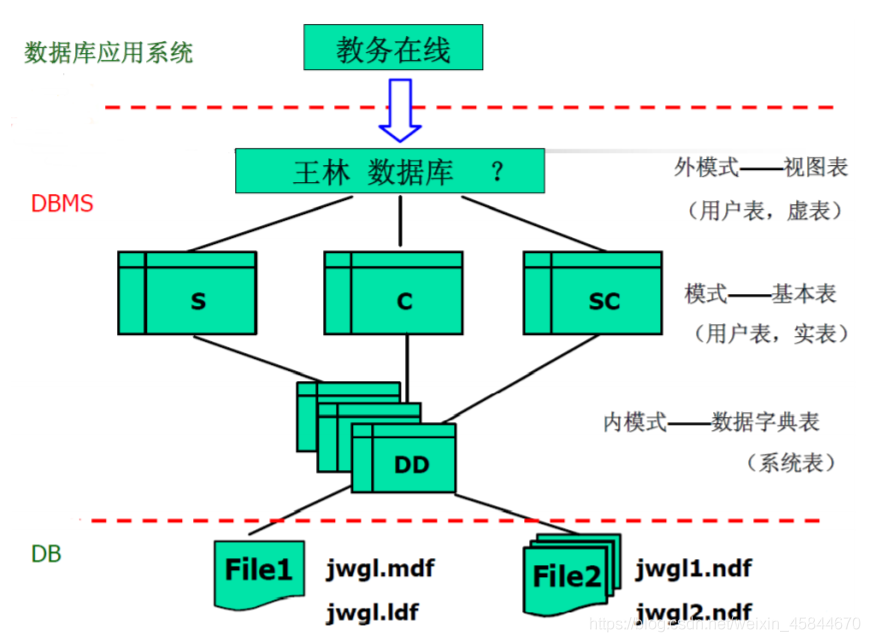
SQL支援的資料庫的三級模式結構,即外模式、模式和內模式。
與之對應的資料庫物件是檢視(view)、基本表(table)和基本表的索引(index)
基本表
- 本身獨立存在的表
- SQL中一個關係就對應一個基本表
- 一個(或多個)基本表對應一個儲存檔案
- 一個表可以帶若干索引
儲存檔案
- 儲存檔案的邏輯結構組成了關聯式資料庫的內模式
- 儲存檔案的物理結構對使用者是隱蔽的
- 索引也是存放在儲存檔案中
檢視
- 從一個或幾個基本表匯出的表
- 資料庫中只存放檢視的定義而不存放檢視對應的資料
- 檢視是一個虛表
- 使用者可以在檢視上再定義檢視
資料定義
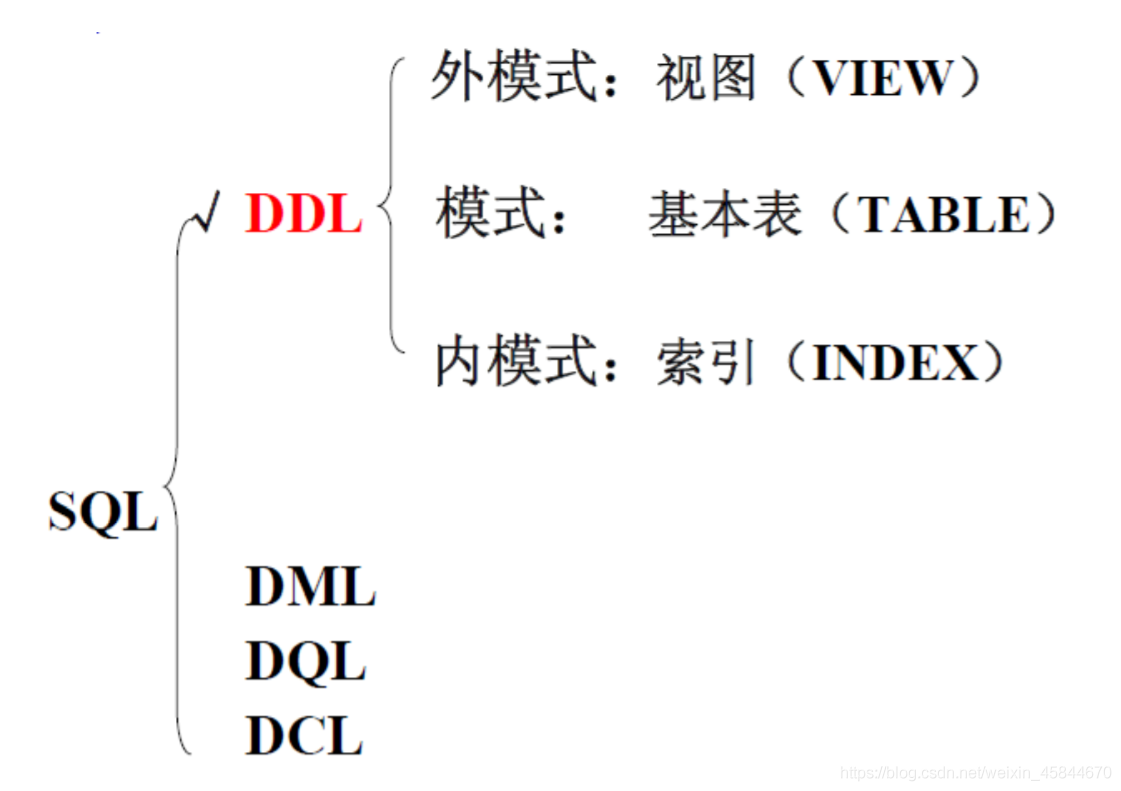
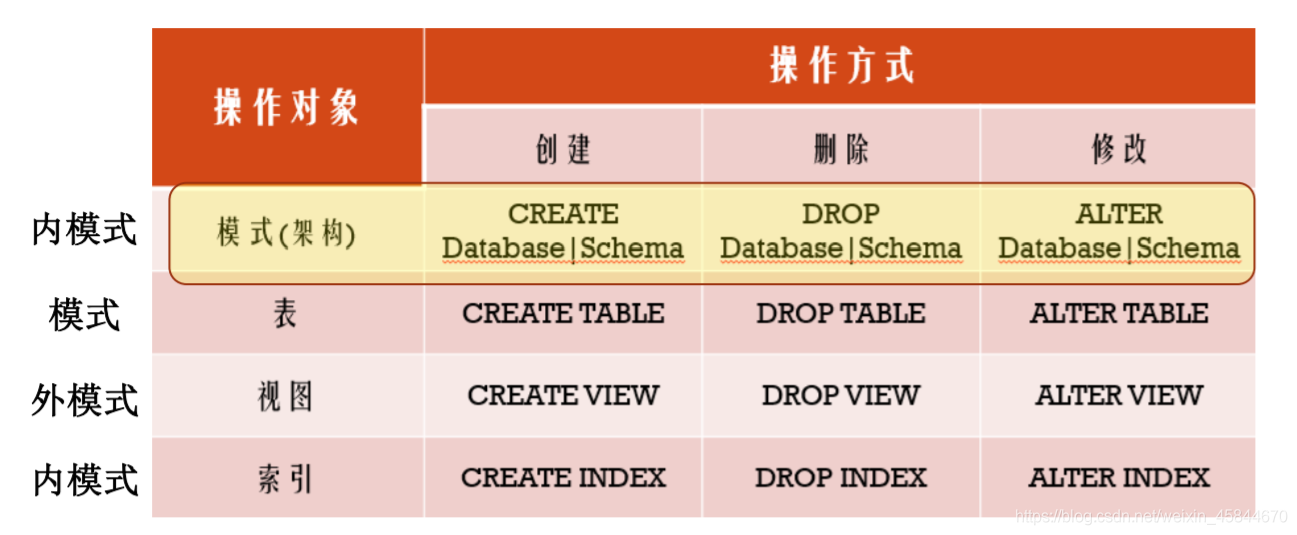
SQL的資料定義功能包括定義表空間(資料庫)、表索引、表和檢視
資料庫的建立與管理
Mysql提供了對資料庫管理的語句,包括建立資料庫、修改資料庫、刪除資料庫等。
建立資料庫
create {database | schema } db_name[create_specification]
mysql在以在建立庫的時候指定庫的預設字元集和排序規則
我們可以在建立資料庫的時候,指定字元集和排序規則,如果不指定,則預設使用mysql伺服器級別指定的字元集和排序規則,除非特殊需求,只要設定其一即可。設定字元集,即設定了預設的排序規則。從Mysql8.0開始,預設值的字元集為utf8,不再是latin1

Unicode(統一碼、萬國碼、單一碼)是一種字元集,Unicode是國際組織制定的可以容納世界上所有文字和符號的字元編碼方案。Unicode用數位0-0x10FFFF來對映這些字元。
• UTF-8、UTF-16、UTF-32都是將數位轉換到程式資料的編碼方案。
例如:在Unicode中:漢字「中」對應的數位是20013。我們可以用UTF-8、UTF-16、UTF-32表示這個數位,將數位20013儲存在計算機中。
UTF-8對應是:E4B8AD;UTF-16對應是:FEFF4E2D;UTF-32對應是:0000FEFF00004E2D
簡單來說,UTF-8、UTF-16、UTF-32是Unicode碼一種實現形式,都是屬於Unicode編碼。
修改資料庫
ALTER {DATABASE | SCHEMA} [db_name]
alter_specification ...
alter_specification:
|[DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
| DEFAULT ENCRYPTION [=] {'Y' | 'N'}
例如:
alter database jwgl character set utf8
刪除資料庫
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name
表的建立和管理
資料表是資料庫中非常重要的物件,對資料表的操作也使用。DDL語句,包括對錶的建立、修改和刪除以及新增表的約束等。
建立表
一般格式:
CREATE TABLE [IF NOT EXISTS] tablename(
col_name type [NOT NULL | NULL] [DEFAULT default_value]
[AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY]
)
CREATE TABLE t1 (
c1 INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
c2 VARCHAR(100),
c3 VARCHAR(100)
);
< tablename >:所要定義的基本表的名字
< col_name >:組成該表的各個屬性(列)
< type >:主要有字元型、數值型和日期型
< table_options >:表級約束條件(外來鍵、主鍵)
修改表
格式:
◼ ALTER TABLE <表名>
◼ [ADD <新列名> <資料型別> [完整性約束名] ]
◼ [DROP <完整性約束名> | COLUMN <列名> ]
◼ [MODIFY COLUMN <列名> <新資料型別> ]
◼ [NULL|NOT NULL]
說明:
➢ ADD子句增加新列和新的完整性約束條件
➢ DROP子句刪除指定的完整性約束條件或列,有約束的列應先刪除約束。
➢ MODIFY子句用於修改原有的列定義(列名、資料型別)和空值約束。
ALTER Table table_name
ADD col_name type;
Drop col_name;
Modify col_name type;
向 Student 表增加 「 入學時間 」 列Scome,其資料型別為日期型。
ALTER TABLE Student ADD Scome DATETIME;
刪除表
NULL值不是一種資料型別,也與0、空字串或空格不同,不能參
與大小或相等比較,但排序優先於其他資料
SQL的資料定義命令
表索引的建立和使用
索引的分類
按資料儲存結構分
聚集索引(Clustered Index)
是指索引項的順序與表中記錄的物理順序一致的索引組織。
一個表只能有一個聚集索引(一般是主鍵)
非聚集索引(Nonclustered Index)
非聚集索引並不改變資料表的儲存順序,而是建立一個由指標構成的索引檔案,這些指標邏輯上按照索引關鍵字的值進行排序。索引檔案和表檔案分別儲存。
可為一個資料表建立多個非聚集索引,每個索引決定了該資料表記錄的一種邏輯順序
Mysql中提到:一個表最多16個索引,最大索引長度256位元組
二者區別在於, 通過聚集索引可以查到需要查詢的資料, 而通過非聚集索引可以查到記錄對應的主鍵值 , 再使用主鍵的值通過聚集索引查詢到需要的資料,故非聚集索引也稱二級索引。因此,宏觀上聚集索引的效能要遠好於非聚集索引
按資料唯一性分
唯一索引:唯一索引表示表中每一個索引值只對應唯一的資料記錄,這與表的
PRIMARY KEY的特性類似,但又有區別:
▪ 當表中有被設定為UNIQUE的欄位時,Mysql會自動建立一個非聚集的唯一性索引。
▪ 而當表中有PRIMARY KEY的欄位時,Mysql會在PRIMARY KEY欄位建立一個聚集索引。
▪ 此外,唯一索引在1個表中可建多個,且值可為NULL。
複合索引(多重索引)
▪ 複合索引是將兩個欄位或多個欄位組合起來建立的索引,而單獨的欄位允許有重複的值。
▪ 對於複合索引,Mysql從左到右的使用索引中的欄位,一個查詢可以只使用索引中的一部份,但只能是最左側部分。例如索引是key index (a,b,c). 可以支援a | a,b | a,b,c 3種組合進行查詢,但不支援 b或b,c進行查詢 。
索引的建立
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name (index_col_name 次序,…)
▪ 索引可以建立在表的一列或多列上,各列名之間用逗號分隔,最多16列。
▪ <次序>為ASC(升)/DESC(降),預設值為ASC。
▪ UNIQUE:此索引每一個值只對應唯一的資料記錄
▪ FULLTEXT:全文索引
▪ SPATIAL:空間索引(支援OpenGIS幾何資料模型)
▪ index_type:BTREE、HASH

在Student表的Sname列上建立一個非聚集索引,且Student表中的記錄將按Sname值的升序存放。
CREATE INDEX Stusname ON Student (Sname)
注意,在有聚集索引的資料庫:
▪ 更新聚集索引列資料時,往往導致表中記錄的物理順序的變更,代價較大,因此對於經常更新的列不宜建立聚集索引。
▪非聚集索引對記錄物理順序不影響
為學生課程資料庫中的Student ,Couse,SC三個表建立索引。
其中Student表按學號升序建唯一索引,Course表按課程號升序建唯一索引,SC表按學號升序和課程號降序建唯一索引。
CREATE UNIQUE
INDEX Stusno ON Student(Sno)
CREATE UNIQUE
INDEX Coucno ON Course(Cno)
CREATE UNIQUE
INDEX Scno ON SC(Sno ASC, Cno DESC)
索引的修改
(mysql5.7, mysql5.7+)
ALTER TABLE tbl_name RENAME INDEX old_index_name
TO new_index_name
(mysql5.7-)
ALTER TABLE tbl_name DROP INDEX old_index_name
ALTER TABLE tbl_name ADD INDEX new_index_name(column_name)
索引的刪除
DROP INDEX 索引名 on 表名
資料更新
資料插入
INSERT [INTO] <表名> [(<屬性列1>[, <屬性列2 >…])]
VALUES (<常數1> [, <常數2>]…)
功能:向表中新增一行資料(元組)。其中新元組在屬
性列1的值為常數1、屬性列2的值為常數2…
INTO子句
▪ 指定要插入資料的表名及屬性列
▪ 屬性列的順序可與表定義中的順序不一致
▪ 沒有指定屬性列:表示要插入的是一條完整的元組,且屬性列屬性
與表定義中的順序一致、必須在每個屬性列上均有值。
▪ 指定部分屬性列:插入的元組在其餘屬性列上取空值
▪ 在表定義時說明了NOT NULL的屬性列不能取空值,否則出錯。
VALUES子句
▪ 提供的值必須與INTO子句匹配
▪ 值的個數
▪ 值的型別

資料修改
格式:
UPDATE <表名>
SET <列名>=<表示式>[, <列名>=<表示式>]…
[ WHERE <條件>]
▪ 功能:修改指定表中滿足WHERE子句條件的元組。SET子
句指出元組中要修改的列。
▪省略WHERE,表示要修改表中的所有元組。
▪表示式中可出現常數、列名、系統支援的函數以及
運運算元。最簡單的條件是:<列名>=常數。

資料刪除
格式:
DELETE
[FROM] <表名>
[ WHERE <條件> ]
▪ 功能:從指定表中刪除滿足WHERE子句條件的所有元組。
▪ 如果省略WHERE子句,表示刪除表中全部元組,但表的定義仍在資料字
典中。
