基於RBF神經網路的信用分類方法
簡要介紹金融資料探勘,RBF神經網路。提出基於RBF神經網路的信用分類的一種方法。此方法可根據客戶提供的煩多而複雜的資料資料來評估客戶信用的好壞。發揮RBF神經網路模擬生物體中神經網路的某些結構和功能,能進行重複學習的特性。將客戶資料與客戶信用之間的非線性關係放進RBF網路這個「黑閘子」裡面。用已有資料對網路進行訓練,讓它學習,調整「黑閘子」裡面的各權值等。再用訓練好的網路來對客戶信用進行評估。
所謂個人信用評估,是指通過使用科學嚴謹的分析方法,綜合考察影響個人信用狀況的主客觀因素,並對其履行債務的意願和能力進行全面的判斷和評估。個人信用評估方法主要分為定性分析和定量分析兩種,前者以信貸人員的主觀判斷法為代表,後者以信用評分卡和信用評分模型為代表。
個人信用評估體系對消費信貸的促進作用主要表現在:
(1)增進授信決策的速度,將客戶繁雜的個人資訊加以具體化,以代號(或等級、分數等)表示客戶信用的品質,使信貸人員一目瞭然,便於快速做出決策。
(2)個人信用評估結果可以作為確定信用額度、信用條件之參考,例如在什麼範圍的評估結果必須提供擔保品或保證人,在什麼評估標準以下不得授予信用等。
(3)有效降低消費信貸風險,一方面,可以約束個人行為,引導個人自動守約,另一方面,則可以精確估計消費信貸風險,最大限度地防止不良貸款的產生。
(4)幫助商業銀行按照風險對客戶進行分類,進行市場細分和有針對性的目標客戶行銷,擴大信貸規模和受信群體。
隨著銀行業務的發展,銀行積累了大量的客戶交易資料,如何利用客戶的特徵資料和行為資料來獲得客戶的行為模式,從而更好地為客戶服務,是銀行需要迫切解決的問題。客戶信用評估對於銀行具有重要意義,它基於對客戶的認知,將客戶劃分為不同的重要等級,並以此制定客戶的差別化服務策略,通過策略的實施從而降低信貸風險。通過對客戶信用的評估根據客戶的信用資訊給出信貸申請者能夠償還的可能性,通過建立評估模型對客戶信用進行評估和預測能夠輔助銀行做出信貸策略。
本文將提出一種基於RBF人工神經網路的信用分類的評估方法。並對這種方法進行分析。
資料探勘(Data Mining,簡稱DM),又稱為資料庫中知識發現(Knowledge Discovery from Database,簡稱KDD),它是一個從大量資料中抽取挖掘出未知的、有價值的模式或規律等知識的複雜過程。金融領域是資料探勘技術研究和應用的重要領域。金融全球化在推動銀行業發展的同時,也帶來了巨大的潛在風險。商業銀行作為經營金融資產的特殊企業,以其特殊的經營物件、廣泛的社會聯絡和強大的影響力,成為風險聚散的焦點。商業銀行在經營過程中所面臨的風險主要包括流動性風險、信貸風險、投資風險、利率風險、匯率風險和資本風險等,隨著業務的演變和發展,流動性風險、投資風險及信貸風險又合稱為信用風險。信用風險指交易一方違約而無法履行合同義務時給另一方帶來的損失,所以又稱為違約風險。對信用風險的有效管理,在現代商業銀行日常執行過程中具有舉足輕重的地位。世界銀行對全球銀行業危機的研究表明,導致銀行破產的最常見原因,就是信用風險。因此,世界上許多大的銀行機構為了對信用風險進行有效的管理與控制,都在積極研究和開發適合自身管理特點的風險預測量化技術和方法。國外對金融領域的資料探勘做了許多相關研究,而近年來國內學者對此領域也開始關注起來。金融業作為現代社會的核心領域,每天都會產生大量資料,目前的資料庫系統可以高效地實現資料的錄入、查詢、統計等功能,但無法發現資料中存在的關係和規則,無法根據現有的資料預測未來的發展趨勢。如何發現資料背後隱藏的知識,成為近年來研究的焦點,因此,金融資料探勘技術應運而生。利用金融資料探勘技術不但可以從大量的資料中發現隱藏其後的規律,而且可以很好地降低金融機構存在的風險。
金融資料探勘主要有以下幾種方法:
(1)決策樹方法:利用樹形結構來表示決策集合,這些決策集合通過對資料集的分類產生規則。國際上最有影響和最早的決策樹方法是ID3方法,後來又發展了其它的決策樹方法。
(2)規則歸納方法:通過統計方法歸納,提取有價值的if- then規則。規則歸納技術在資料探勘中被廣泛使用,其中以關聯規則挖掘的研究開展得較為積極和深入。
(3)神經網路方法:從結構上模擬生物神經網路,以模型和學習規則為基礎,建立3種神經網路模型:前饋式網路、反饋式網路和自組織網路。這種方法通過訓練來學習的非線性預測模型,可以完成分類、聚類和特徵挖掘等多種資料探勘任務。
(4)遺傳演演算法:模擬生物進化過程的演演算法,由繁殖(選擇)、交叉(重組)、變異(突變)三個基本運算元組成。為了應用遺傳演演算法,需要將資料探勘任務表達為一種搜尋問題,從而發揮遺傳演演算法的優化搜尋能力。
(5)粗糙集(Rough Set)方法:Rough集理論是由波蘭數學家Pawlak在八十年代初提出的一種處理模糊和不精確性問題的新型數學工具。它特別適合於資料簡化,資料相關性的發現,發現資料意義,發現資料的相似或差別,發現資料模式和資料的近似分類等,近年來已被成功地應用在資料探勘和知識發現研究領域中。
(6)K2 最鄰近技術:這種技術通過K個最相近的歷史記錄的組合來辨別新的記錄。這種技術可以作為聚類和偏差分析等挖掘任務。
(7)視覺化技術:將資訊模式、資料的關聯或趨勢等以直觀的圖形方式表示,決策者可以通過視覺化技術互動地分析資料關係。視覺化資料分析技術拓寬了傳統的圖表功能,使使用者對資料的剖析更清楚。
神經網路方法是金融資料探勘中一種很重要的技術。
1.2 神經網路簡介
神經網路的全稱是人工神經網路(Artificial Neural Network,簡稱ANN),它採用物理上可實現的器件或採用計算機來模擬生物體中神經網路的某些結構和功能,並用於工程領域。神經網路是資料探勘中的一種非常重要的方法。它類似於人類大腦重複學習的方法,先給出一系列的樣本,進行學習和訓練,從而產生區別各種樣品之間的不同特徵和模式。樣本集應該儘量體現代表性,為了精確地擬合各種樣本資料,通過上百次,甚至上千次的訓練和學習,系統最後得出潛在的模式。當它遇到新的樣品資料時,系統就會根據訓練結果自動進行預測和分類。
人工神經網路是對生物神經網路系統的模擬,其資訊處理功能是由網路單元的輸入輸出特性及網路的拓撲結構所決定的。人工神經網路對問題的求解方式與傳統方法不同,它是經過訓練來解答問題的。其主要特點表現為:
(1)高度的並行性。人工神經網路是由許多相同的簡單處理單元並聯組合而成,雖然每個單元的功能簡單,但作為一個整體其對資訊的處理能力與效果驚人。
(2)高度的非線性全域性作用。網路通過神經元之間相互影響、相互作用,實現從輸入狀態到輸出狀態空間的非線性對映,從全域性觀點來看,這不是網路區域性效能的迭加,而表現出某種集體性的行為。
(3)良好的容錯性與聯想記憶功能。網路通過自身的權值改變及網路方程的執行能實現對資訊的記憶與聯想。
(4)較強的自適應、自學習能力。人工神經網路通過訓練和學習來獲得網路的權值與結構,呈現出很強的自學習能力和對環境的自適應能力。
人工神經網路的上述特點,正好適應信用風險控制的要求。由於信用風險系統高度的非線性,使得傳統的方法難以構建合適的控制模型。而神經網路帶有高度並行處理資訊的機制且具有較強的自學習、自適應能力,內部有大量的可調引數,因而使系統具有很強的靈活性。同時在信用評估時,有些因素帶有模糊性,而神經網路的後天學習能力使之能隨環境的變化而不斷學習,與傳統的評價方法相比,表現出更強的功能。同時,神經網路可以再現評價專家的經驗、知識和直覺思維,較好地保證了評價與控制結果的客觀性。
然而常用的多層前饋網路,由於變換函數的限制,其功能受到限制。RBF神經網路是一種區域性逼近網路。相對於典型的全域性逼近的BP網路,兩者構造的本質不同。比較而言,RBF神經網路雖然規模通常較大,但學習速度較快,並且網路的函數逼近能力、圖形識別與分類能力都優於BP網路。RBF神經網路將在下一節再做介紹。
1.3 RBF神經網路簡介
1985年,Powell提出了多變數插值的徑向基函數(Radial Basis Function,簡稱RBF)方法。RBF神經網路是由J.Moody和C.Darken於20世紀80年代末提出的一種神經網路結構。目前已經證明,徑向基網路能夠以任意精度逼近連續函數。
RBF網路的結構與多層前向網路類似,它是一種三層前向網路(如圖1)。輸入層由訊號源結點組成。第二層為隱含層,單元數視所描述問題的需要而定。第三層為輸出層,它對輸入模式的作用做出響應。從輸入空間到隱含空間的變換是非線性的,而從隱含層空間到輸出層空間的變換是線性的。隱單元的變換函數是RBF,它是一種區域性分佈的中心點徑向對稱衰減的非負非線性函數。
2.1.1 德國信用資料庫
採用Hans Hofmann教授整理提供的德國信用資料庫german.data。德國信用資料庫包含1000份客戶信用資料。該資料庫包含的20個條件屬性分別為:
屬性1:經常帳戶狀況。1: 賬戶餘額<0馬克; 2:0馬克≤賬戶餘額<200馬克; 3:≥200馬克; 4:無經常帳戶記錄。
屬性2:帳戶持續時間(月) 。
屬性3:貸款歷史狀況。1:無貸款記錄或所有貸款均按時返還; 2:在本銀行的所有貸款均按時返還; 3:迄今為止現存貸款按時返還; 4:過去曾延遲還款; 5:存在危帳或仍存在貸款(非本銀行) 。
屬性4:貸款用途。1:購買新車; 2:購買二手車; 3:購買傢俱裝置; 4:購買收音機或電視機; 5:購買家庭用品; 6:維修; 7:教育; 8:度假; 9:接受再培訓; 10:經商; 11:其他用途。
屬性5:貸款數額。
屬性6:儲蓄存款帳戶狀況。1:賬戶餘額<100馬克; 2: 100馬克≤賬戶餘額< 500馬克; 3:500馬克≤賬戶餘額< 1000馬克; 4:賬戶餘額≥1000馬克; 5:未知或無儲蓄存款。
屬性7:現工作就業時間。1:失業; 2:就業時間<1年; 3: 1年≤就業時間< 4 年; 4: 4年≤就業時間<7年; 5:就業時間≥7年。
屬性8:分期付款佔月收入的百分比。
屬性9:個人狀況及性別。1:男性離互斥或分居; 2:女性離異、分居或結婚; 3:男性單身; 4:男性結婚或鰥居; 5:女性單身。
屬性10:其他債務或保證金。1:無; 2:聯合申請人; 3:保證人。
屬性11:現居住狀況。
屬性12:財產狀況。1:擁有房產不動產; 2:不擁有房產不動產,但有社保儲蓄協定或養老保險; 3:不擁有房產不動產,無社保儲蓄協定或養老保險,但擁有汽車或其他(不在屬性6範圍內) ;4:未知或無財產。
屬性13:年齡。
屬性14:其他分期付款計劃。1:銀行; 2:商店; 3:無。
屬性15:房屋狀況。1:租住; 2:自有; 3:免費使用。
屬性16:在本銀行已有存款數目。
屬性17:工作狀況。1:失業、無技能或非本地居民; 2:無技能的本地居民; 3:技術工人或公務員; 4:經理、自由職業者、高階僱員或官員。
屬性18:應撫養人數。
屬性19:電話。1:無; 2:有或已註冊。
屬性20:是否外籍勞工。1:是; 2:否。
決策屬性:信用狀況評價。1:好; 2:壞。
2.1.1 澳大利亞信用資料庫
澳大利亞信用資料庫共有690份資料。每份資料有14個屬性加一個決策屬性。14個屬性中有8個數量屬性和6個分類屬性。
該演演算法具體過程如下:
(1)選擇一個適當的高斯函數寬度r,定義一個向量A(t)用於存放屬於各類的輸出向量之和,定義一個計數器B(t)用於統計屬於各類的樣本個數,其中t為類別數。
(2)從第一個資料對(x1,y1)開始,在x1上建立一個聚類中心,令c1 = x1,A(1)= y1,B(1)= 1。這樣建立的RBF網路,只有一個隱單元,該隱單元的中心為c1,該隱單元到輸出層的權向量為w1 = A(1)/B(1)。
(3)考慮第2個樣本資料對(x2,y2),求出x2 到c1 這個聚類中心的距離|x2-c1|。如果|x2-c1|<=r,則c1為x2 的最近鄰聚類,且令A(1) = y1+y2,B(1) = 2,w1 = A(1)/B(1);如果|x2-c1|>r,則將x2 作為一個新聚類中心,並令c2 = x2,A(2) = y2,B(2) = 1。在上述建立的RBF網路中再新增一個隱單元,該隱單元到輸出層的權向量為w2 = A(2)/B(2)。
(4)假設我們考慮第k個樣本資料對(xk,yk)時,k = 3,4,…,N 存在M個聚類中心,其中心點分別為c1,c2,…,cM,在上述建立的RBF網路中已有M隱單元。再分別求出到這M個聚類中心的距離|xk - ci|,i = 1,2,…,M,設|xk – cj|為這些距離中的最小距離,即cj為xk 的最近鄰聚類,則:
如果|xk – cj|>r,則將xk作為一個新聚類中心,並令cM+1 = xk ,M =M+1,A(M) = yk ,B(M) = 1。且保持A(i),B(i)的值不變,i = 1,2,…,M - 1。在上述建立的RBF網路中再新增第M個隱單元。
如果|xk – cj|<=r,作如下計算:A(j) = A(j)+ yk ,B(j) = B(j)+1。當i不等於j時,i = 1,2,…,M,且保持A(i),B(i)的值不變。隱單元到輸出層的權向量為wi = A(i)/B(i) , i = 1,2,…,M。
(5)根據上述規則建立的RBF網路其輸出應為
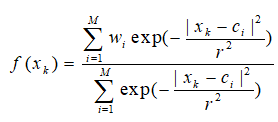
2.2.2 動態調整引數R演演算法
(1)將訓練集分成兩個集合,分別命名為A和B。用A來訓練網路,用B來計算網路分類準確率。
(2)取R初值為1。
(4)訓練網路,並求出該網路分類準確率。記錄當前最高準確率對應的R值為optR。
(5)若R<=0,轉步驟(6);若R>0,以0.01的步長,減小R值,返回步驟(4)。
(6)令R等於optR,訓練網路。
應用德國信用資料庫german.data前700份作為訓練集,後300份作為測試集。訓練集分為A和B兩集合,A集合含600份資料,B集合含100份資料。將1000份資料隨機打亂100次,分別做訓練和測試。可得出表1中的實驗結果:
表1 德國信用資料庫實驗結果彙總
|
| 20個輸入屬性 | 屬性約簡為11個輸入屬性 (刪除屬性 7 8 9 11 15 13 18 19 20) | |||
| 均值 | 方差 | 均值 | 方差 | ||
| 沒有處理噪聲資料 | 動態選定關鍵屬性 | 0.731200 | 0.000642 | 0.734833 | 0.000664 |
| 不選關鍵屬性 | 0.737600 | 0.000561 | 0.739367 | 0.000637 | |
| 處理噪聲資料 | 動態選定關鍵屬性 | 0.728133 | 0.000795 | 0.775133 | 0.002235 |
| 不選關鍵屬性 | 0.734867 | 0.000608 | 0.778967 | 0.002554 | |
(注:噪聲處理工作由同組的諸強同學用MATLAB工具完成。)
應用澳大利亞信用資料庫前483份作為訓練集,後207份作為測試集。訓練集分為A和B兩集合。不選關鍵屬性。將690份資料隨機打亂100次,分別做訓練和測試。可得出表2中的實驗結果:
表2 澳大利亞信用資料庫實驗結果彙總
|
| 14個輸入屬性 | 屬性約簡為11個輸入屬性 (刪除屬性 1,13,14) | |||
| 均值 | 方差 | 均值 | 方差 | ||
| 沒有處理噪聲資料 | A集合283份資料 B集合200份資料 | 0.854058 | 0.014590 | 0.855314 | 0.014838 |
| A集合333份資料 B集合150份資料 | 0.855121 | 0.014919 | 0.856811 | 0.015228 | |
| 處理噪聲資料 | A集合283份資料 B集合200份資料 | 0.874444 | 0.020065 | 0.878164 | 0.021053 |
| A集合333份資料 B集合150份資料 | 0.876425 | 0.020540 | 0.879710 | 0.021473 | |
由上實驗結果可知,對網路分類準確率影響較大的因素為:噪聲資料,屬性約簡,A,B集合元素個數比等。其中影響最大的為噪聲資料。說明這種方法抵抗噪聲干擾的能力較差。