乾貨!一文看Doris在作業幫實時數倉中的應用&實踐


資料驅動未來。在巨量資料生態中,資料分析系統在資料創造價值過程中起著非常關鍵的作用,直接影響業務決策效率以及決策品質。Apache Doris作為一款支援對海量巨量資料進行快速分析的MPP資料庫,在資料分析領域有著簡單易用、高效能等優點。
9月20日,Apache Doris組織了一場線上Meetup,作業幫受邀參加,並帶來了一場《Doris在作業幫實時數倉中的應用&實踐》的主題分享。

現場分享精華
大家下午好。下面我來介紹下Doris在作業幫實時數倉中的應用與實踐。
這次的分享主要分三個主題

1、首先是所在團隊的業務與背景介紹
2、其次會介紹下基於Doris,作業幫的查詢系統是如何構建的,以及主要解決的問題
3、未來的規劃
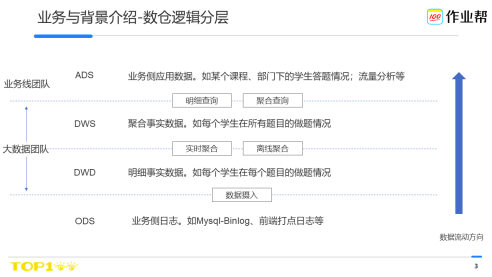
我所在團隊是作業幫巨量資料團隊,主要負責建設公司級數倉,向各個產品線提供面向業務的資料資訊,如到課時長、答題情況等業務資料以及如pv、uv、活躍等流量類資料,服務於拉新、教學、BI等多個重要業務線。
在數倉體系中,巨量資料團隊主要負責到ODS-DWS的建設,從DWS到ADS一般是數倉系統和業務線系統的邊界。
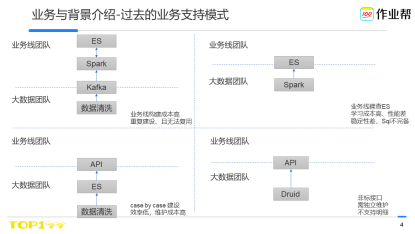
在過去,由於缺失有效、統一的查詢系統,我們探索了很多模式來支援各個業務線發展。
有些業務線對巨量資料相關技術比較瞭解,熟悉spark等計算系統,可以自己處理計算。因此會選用kafka 接收資料後使用spark計算的模式來對接巨量資料團隊;但是其他業務線不一定熟悉這套技術棧,因此這種方案的主要問題無法複製到其他業務線。且Spark叢集跨越多個業務線使用,本身就給業務線帶來了額外的維護成本。
既然Kafka+Spark的模式無法大範圍推廣,我們又探索了基於ES的方案,即巨量資料將資料寫入ES中,然後業務先直接存取ES來獲取資料,但是發現一方面高效能的使用ES,本身就具有很高的成本,對ES得非常熟悉,這對於業務線來說很難有精力去做,其次,由於使用ES的系統品質參差不齊,偶會還發生將ES叢集打垮的問題,穩定性也不可控,最後ES-Sql語法完備性不足,如不支援join、多列group by(6.3版本)等。
因此我們又探索開發API介面,希望在穩定性上可以有更好的解決方案。雖然API可以可控,但是由於API不提供Sql功能,基於需求場景不斷case by case的API開發反而成了影響交付效率的主要瓶頸點。
上述多是支援查詢明細資料,一旦涉及到大規模的流量類查詢,如pv、uv,只好引入druid類系統,但是duird的介面和其他系統的介面不一致,使用者往往又得學習,且Druid不支援明細,一旦需要明細,就需要到ES去查詢,由於涉及兩套系統,有時候還得處理明細資料和聚合資料不一致的問題。
隨著需求越來越多,系統也越來越難以維護,交付效率也特別低,需求排隊非常嚴重。
因此,提供有效而統一的查詢系統,對於實時數倉建設在提高業務支援效率、降低維護成本上都具有非常重大的意義。
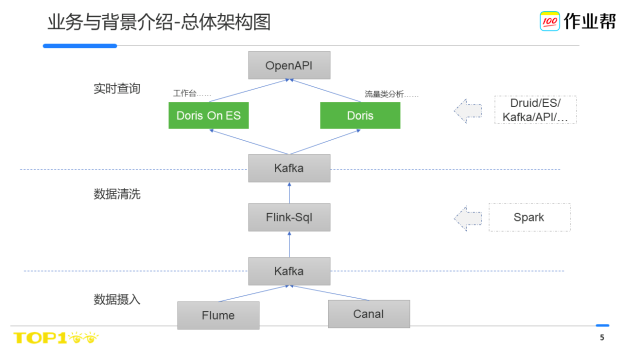
經過過去數月的探索與實踐,我們確立了以Doris為基礎的實時查詢系統。同時也對整個實時數倉的資料計算系統做了一次大的重構,最終整體的架構圖如下:
如圖所示(從下到上),原始業務層紀錄檔經資料攝入系統進入數倉,在資料淨化計算層,我們將原來基Spark系統升級到了Flink,並且基於Flink-Sql提供了統一的資料開發框架,從原有的程式碼開發升級到Sql開發來提升資料的研發效率。
其後查詢系統將Kafka的資料實時同步到查詢引擎內,並通過OpenAPI的統一介面對外提供查詢服務。

基於Doris的查詢系統上線後,我們面對一個需求,不用像過去一樣做方案調研、開發介面、聯調測試,現在只要把資料寫入,業務層就可以基於sql自己完成資料查詢、業務開發,交付效率(資料計算好到提供可讀服務)從過去的數人周加快到小時級。
在效能方面,過去基於ES或者mysql來做,當查詢的資料量較大時,我們只能忍受數十個小時到數分鐘的延遲,基於Doris的方案,加快到分鐘級甚至秒級。
Doris的整體架構非常簡單,不依賴任何第三方元件,社群支援度也非常好,從上線到今,我們只需做一些輕量級的運維規範,即可保證高穩定性。
所以說,通過引入Doris,解決了作業幫內實時數倉查詢交付慢、查詢慢的痛點問題,對於後續數倉的系統發展起到了非常關鍵的作用。

接下來,重點講下查詢系統的工作。
分兩部分:查詢系統的架構選型以及原理,以及應用&實踐
在講查詢引擎之前,先講下業務場景。

作業幫內,業務場景主要分兩種
一種是 傳統的流量類,比如算pv、uv、活躍……,作業幫內很多時候還需要看進一步的明細。
比如 作業幫主App 在每天各個小時的活躍使用者數,還要看 作業幫主App每個小時內各個版本的活躍使用者數。

第二種是 面向我們業務線的工作臺,比如教學的老師。
比如我們的老師上完課後,會看下自己班內的同學們的出勤資料、課堂測驗資料等。
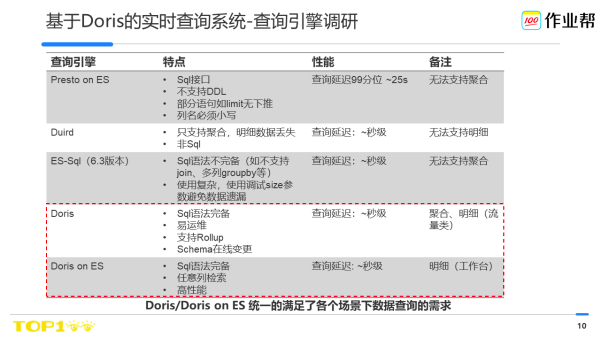
這兩種場景下,這塊考慮到調研成本、團隊技術生態、維護成本等多種因素,我們最後選擇了Doris 作為我們的查詢引擎。主要是Doris可在上述兩種場景下都可以統一的滿足業務的需求。

首先介紹下Doris。
Doris是 mpp架構的查詢引擎。
整體架構非常簡單,只有FE、BE兩個服務,FE負責Sql解析、規劃以及後設資料儲存,BE負責Sql-Plan的執行以及資料的儲存,整體執行不依賴任何第三方系統,功能也非常豐富如支援豐富的資料更新模型、Mysql協定、智慧路由等。對於業務線部署運維到使用都非常友好。
接下來講下用Doris如何解決我們前面提到的業務場景下的問題。
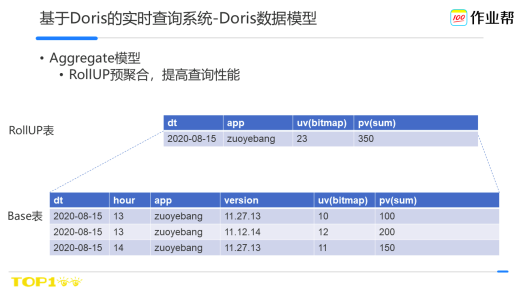
Doris有多種資料模型,流量類場景常用的是聚合模型。比如對於前面提到的場景,我們會吧作業幫主App各個版本的明細資料存到base表中,如果直接從base表中讀取跨天級的聚合資料,由於資料行比較多,可能會出現查詢延遲的問題,因此我們會對常用的天級資料做一次rollup,這樣通過預聚合,來減少查詢的資料量,可以加快查詢的延遲。

要高效的使用Doris的聚合模型,前提都是基於key列做資料行篩選,如果使用value列,Doris需要把相關的行全部聚合計算後方可決策是否屬於結果集,因此效率比較低。
而對於教研工作臺,前面提到的都是基於value的篩選,因此使用了Doris on ES的模型。主要是考慮到 可以發揮ES的任意列檢索的能力,來加快查詢速度。
在我們的實踐中,發現Doris on ES相比直接裸用ES或社群的其他方案如Presto on ES在效能上有很大的提升,接下來介紹下Doris on ES高效能的設計原理。
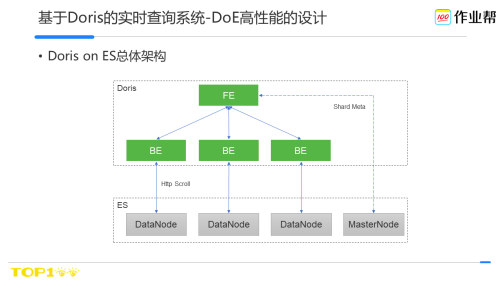
Doris on ES整體的架構如圖,FE負責查詢ES的後設資料資訊如location、shard等,BE負責從ES資料節點掃描資料。

Doris on ES高效能,相比裸用ES,有幾個優化點:
裸用ES時,ES採用的是Query then Fetch的模式,比如請求1000條檔案,ES有10個分片,這時候每個分片都會給協調返回1000個doc id,然後 協調節點其實拿到了10 * 1000個doc id,然後選擇1000個。這樣其實每個分片多返回了900個.
Doris on ES則繞過了協調節點直接去操作datanode。它會在每個datanode上查詢符合預期的docid,這樣不會有過多的docid返回。
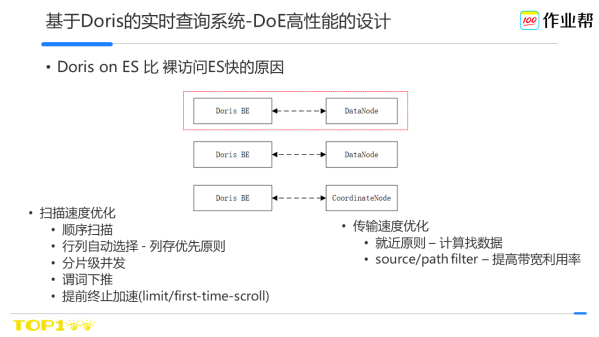
其次,Doris從ES掃描資料時,也做了很多優化。比如在掃描速度上,採用了順序掃描、列存優化、謂詞下推等,在資料從ES傳輸到Doris時,採用就近原則如BE會優先存取本機的datanode、source filter來過濾不用的欄位等來加速傳輸速度。
在我們的調研中,Doris on ES的效能,比Presto on ES快了有數十倍。

在作業幫內,除了上面介紹的基於Doris的資料模型做的基礎應用,要完整的支援業務、保證穩定性、提高效率,還需要其他周邊的系統建設。
接下來介紹下基於Doris,作業幫查詢系統架構的整體設計以及工作模式。
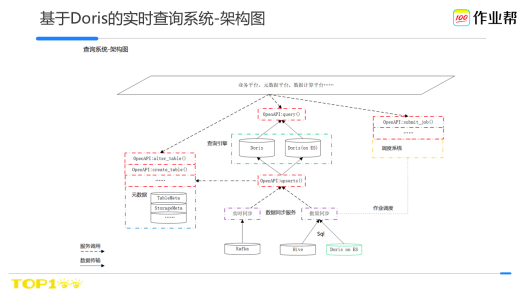
這是作業幫查詢系統的總體架構。
從上往下,首先是我們平臺,包括各個報表平臺、後設資料管理平臺等,主要來提高各個場景的人效。
其下紅色部分為我們統一的api介面層,這裡我們主要是制定了api的規範比如請求響應方式、返回碼等,來減少系統之間對接的成本。
基於api除了提供了主要的讀寫介面外,也包含了周邊的服務建設,比如後設資料管理、排程系統等。

接下來就基於一個完整的流程來介紹下各部分系統。

首先是後設資料。Doris基於mysql語法建表,已經有後設資料,我們這裡做後設資料,有幾個額外的考慮:
首先是保障查詢效能方面:如果一個表在建表時設定寫錯,那麼查詢效能會非常差,比如ES的index mapping中關閉了docvalue,或者Doris表未啟動列存模式,那麼查詢就會退化成行存模式,效能會比較低,因此為了最大化效能,就需要將建表的過程全部自動化且規範化。這是其一。
Doris自身儲存是有強Schema約束的,比如一個字串的長度。但是ES並沒有明確的長度約束,對於一個keyword型別的欄位,寫入128B或者256B都可以成功,但這會導致一個問題,當把一張es表同步到Doris表時,同步的成功率無法保障。另外,一旦Doris表宣告的型別(如bigint)和ES index的型別不一致(如keyword)時,也會導致Sql執行失敗。因此需要構建統一的資料模型來避免這類問題。
第三:使用效率。我們在使用過程中,建表、刪除表、修改表是一個常見的操作,為了讓各個業務線的同學(不管是否瞭解Doris)都可以快速的建表,這也是要做統一後設資料、統一模型的基礎。
最後,前面也提到了我們整個計算系統也在重構為flink-sql。flink-sql則會強依賴後設資料,比如table on kafka、table on redis……

要統一後設資料,統一資料模型,就得抽象整個資料表的結構,來管理好不同儲存上的表,我們基於env、db、table為基本單位來管理表,database、table大家相對熟悉,env是我們引入的新namespace,主要用於提供不同叢集/業務線的定義,如百度雲的數倉叢集、騰訊雲的數倉叢集,表單元下主要包含field(列型別、值域)、index(如rollup、bitmap索引等)、storage(儲存屬性)。
關於列屬性,主要是規範化型別系統,考慮到json-schema由於其校驗規則豐富、描述能力強,因此對於列值的約束統一使用json-schema來做。
對於資料型別,我們設計了公共資料型別以及私有資料型別。公共類如varchar、int等,這些在不同的儲存系統都有對應的實現,也支援私有型別如Doris::bitmap,方便私有系統的相容和擴充套件。通過這個模式可以將基於各個儲存系統的表做了統一的管理

這是我們線上的真實的一張表。裡面包含了列資訊以及對應的儲存設定。
左圖中的縱向紅框是json-schema的描述,來規範化值域。橫向紅框為ES表的一些meta欄位,比如docid、資料更新時間。這些欄位可以方便追查資料問題、以及用作資料篩選。
因為我們統一了資料模型,因此可以很方便的對所有表統一設定要增加這些meta欄位。

通過後設資料的統一管理,構建的表品質都非常高。所有的表都在最大化效能的提供查詢服務,且由於資料導致的查詢不可用case為0。且對於任何業務線的同學,不管是否瞭解Doris,都可以分鐘級構建出這樣一張高品質的表。

建好表後,就是資料的寫以及讀。統一基於openapi來做。
做api介面其實本質上也是為了在提供系統能力的前提下,進一步保障系統的穩定性和易用性。
比如要控制業務線的誤用(如連線數打滿),提供統一的入口方便寫es、Doris,且控制資料品質……。

首先介紹下資料寫介面。
由於統一了表模型,因此可以很方便的提供統一的寫入介面協定。使用者也無須關注實際表的儲存是es還是Doris以及處理異構系統的系統。
第二,統一了寫介面,就可以統一的對寫入的資料會做校驗檢查,如資料的大小、型別等,這樣可以保證資料寫入的品質與準確性。這樣對於資料的二次加工非常重要。
第三,接入協定中還增加了關鍵詞,如資料的版本。可以解決資料的亂序問題,以及建立統一的寫入監控。如下圖是我們整個寫入資料流的qps以及端到端(資料寫入儲存時間以及資料生產時間)的延遲分位值,這樣可以讓系統提高可觀測性、白盒化。
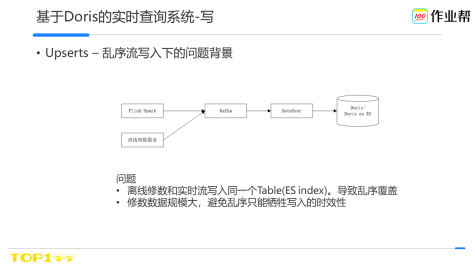
接下來講一個具體的場景,寫入端是如何解決亂序問題的。
常態下我們的實時資料流是經過flink或spark計算後寫入kafka,然後由查詢系統同步到Doris/es中。
當需要修數時,如果直接寫入,會導致同一個key的資料被互相覆蓋,因此為了避免資料被亂序覆蓋,就得必須停掉實時流,這個會導致資料時效性式受損。
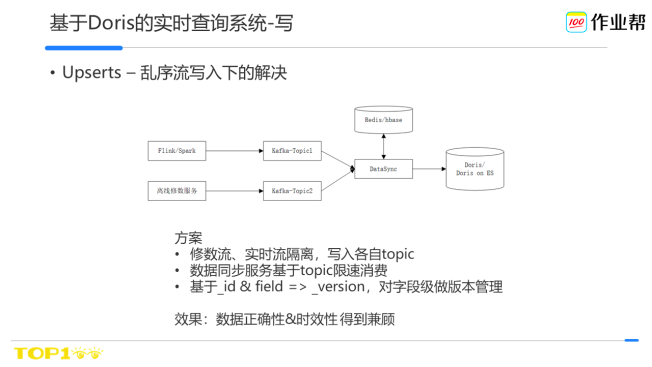
因此我們基於寫入端做了改進,實時資料流、離線修復資料流各自寫入不同的topic,同步服務對每個topic做限速消費,如實時流時效性要求高,可以配額調的大些,保證配額,離線時效性則允許配額小點,或者在業務低峰期將配額調大,並基於資料key&列版本儲存做了過濾。這樣可以保證時效性的前提下,修數也可以按照預期進行。
最後是讀的部分。
在提供sql能力的前提下,我們也做了一些額外的方案,比如快取、統一的系統設定。對於系統延遲、穩定性提升都有很大的改進。並且由於統一了讀介面,上述的這些改造,對於業務線來說都是透明的。

除了常規下面向低延遲的讀,還有一類場景面向吞吐的讀。
介紹下場景,比如 要統計統計某個學部下(各個老師)的學生上課情況:上課人數、上課時長等。
在過去,我們是基於spark/flink來處理這類問題,如spark消費kafka中的課中資料,對於每一條資料,會去redis中查詢教師資訊來補全維度。
常態下,當課中資料到達的時候,教師資訊是就緒的,因此沒有什麼問題。可是在異常下,如維度流遲到、儲存查詢失敗等,會導致課中流到達時,無法獲取對應的教師資訊,也就無法計算相關維度如學部的統計。
過去面臨這種情況時,只能遇到這種異常,如重試如果無法解決,只能丟棄或者緊急人工干預,比如在尾標就緒後再重新回刷課中表,一旦遇到上游kafka資料過期就只能從ods層或者離線修復,效率特別低,使用者體驗也非常差。

基於Doris模式下,我們使用微批排程的模式。
排程系統會定期(分鐘級)執行一個排程任務,基於sql join完成資料的選取。這樣哪怕在異常下,課中流查不到教師資料,這樣join的結果只是包含了可以查到教師資料的資訊,
待教師資料就緒後,即可自動補全這部分課中資料的維度。整個過程全部自動化來容錯。效率非常高。
因此這個模式的主要好處
業務端延遲可控、穩定性好。整個過程主要取決於排程的週期和Sql執行時長。排程週期可控,且由於Doris on ES的高效能,Sql執行時長几乎都可以在分鐘內完成。
資料修復成本低、維護方便。一旦資料有異常,可以自動觸發對應的資料視窗進行重新計算。

最後,講下其他方面的建議實踐,這些相對簡單,但是在實際的應用中非常容易忽視。
ADS層表,尤其是面向平臺側的應用,慎用join。Doris的join策略比較多,如broadcast、shuffer等,如果使用需要了解原理,屬於高階使用者的使用範疇。對於強調快速迭代的場景下,可以使用微批模式來略降低資料更新的延遲,提高資料查詢的效率。
使用Doris on ES時,尤其是在ES叢集負載很高的情況下,在延遲允許的情況下建議將es的掃描超時時間設定大一點,如30s甚至更久。
Batch size,不是越大越好。我們實踐中發現4096下最好,可以最高達到每秒30w的掃描速度。
Doris使用bitmap做精確去重時,有時候會發現Sql延遲比較高,但是系統cpu利用率低,可以通過調大fragment_instance_num的值。
運維Doris時,建議使用supervisor,可以幫助避免很多服務異常掛掉的問題;機器全部開啟ulimit –c,避免出core時無法高效定位
當前我們在使用master版本,主要是考慮到bugfix很及時,但是也要避免新程式碼、feature的bug引入,因此我們會關注社群的issue、並做好case迴歸、固化使用模式等一系列手段來保障master在實際生產中的穩定性。

最後,講下規劃。
Doris 在作業幫實時數倉的建設中發揮了很關鍵的作用。
在實際的應用中,我們也發現了一些當前的一些不足。

如Doris on ES在面對大表的join查詢時,目前延遲還比較大,因此需要進一步的優化解決;
Doris自身的olap表可以做動態分割區,對於ES表目前可控性還不足;
其次,當ES修改表後,如增加欄位,只能刪除Doris表重建,可能會有短暫的表不可用,需要自動化同步或者支援線上熱修改;
最後Doris on ES可以支援更多的謂詞下推,如count等。
我們也希望可以和社群一起,把Doris建設的越來越好。
好的。我的分享到此結束。謝謝大家。

精彩問答Q&A
問題1:Doris on ES V.S. sparksql on ES,在功能上和效能上咱們調研過嗎?對於使用哪個您這邊有什麼建議嗎?
答:SparkSql on ES和Doris on ES 雖然都是Sql,但是在實際的生產環境中使用差異還是比較大的。
功能上來說,SparkSql和Doris-Sql需要考慮語法的相容性問題,畢竟是兩個系統,語法相容其實很難。一旦不一致就需要使用者端面向不同的系統做適配。
效能上,SparkSql或者Doris on ES,雖然存取ES的原理都差不多,但是實現上可能會有diff,這些diff會導致效能上差異比較大,如SparkSql的connector是不支援列存模式的。
場景上,如果使用SparkSql建議可以使用在流計算場景,更多的是解決吞吐的問題,類似的系統應該是Flink-Sql。可以吧資料按照行掃出來後,基於Spark的分散式計算能力、yarn的資源管理走流計算的模式。Doris on ES更適合走低延遲的場景。
問題2:Doris 支援Hive Metastore,和Flink SQL是什麼關係?剛才講的太快,有點沒聽懂
答:Doris其實是不支援Hive MetaStore的。只是可以從HDFS上load檔案,然後在Doris的load語法中指定對應的列。
FlinkSql和這塊關係不大。不過我理解你說的應該是我們的後設資料,這部分背景是因為Flink-Sql執行時需要設定ddl語句,比如一張基於redis的表都有哪些列,型別是什麼,這些需要統一的管理起來,目前是儲存到了我們的後設資料系統中。通過介面和Flink系統完成對接。
問題3:_version欄位是一個內部欄位?需要使用者端寫入的時候指定,還是系統自動建立?和HBase的version的應用場景有區別嗎?
答:_version是我們資料流的一個內建協定欄位。在數流轉過程中,使用者只要設定值即可,不需要顯示建立。具體的值可以根據資料欄位的寫入服務來設定,比如在ods層,應該是採集側服務來寫入,如果在中間的flink清洗環節,應該是flink系統來設定,儘量讓架構服務統一設定,保證穩定性。
_version欄位最終會對映到儲存系統中的UpdateTime欄位,這個也是架構負責寫入的。不需要業務側關注。
HBase的version更多是用於多版本的管理,比如資料的回滾等。這裡查詢系統的_version更多是為了保證資料的時鮮性,即使用者從查詢系統讀到的資料始終是最新的。這麼做的前提主要是因為查詢系統比如ES對於資料列多版本支援不太好,對於資料流更新時如果沒有版本管理,容易導致亂序覆蓋。和HBase的version場景還不同。
ES內部也有一個_version,但是這個_version一般是ES內部使用,用於高並行下樂觀鎖的實現。和當前的場景都不一樣。


更多閱讀推薦