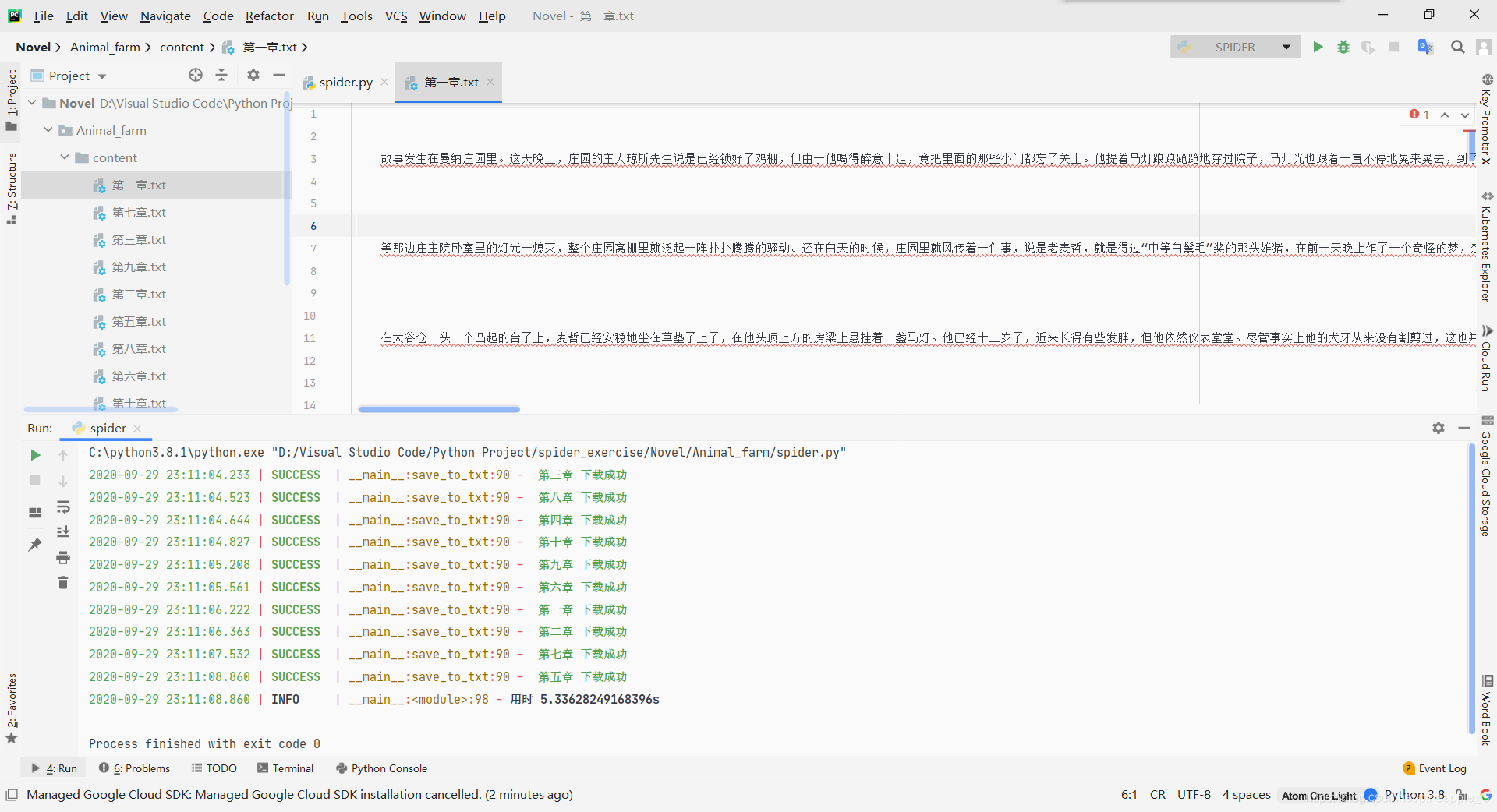
Python 爬小說《動物莊園》
2020-10-01 11:00:22
一、前言
最近都是在解決一些疑難問題,結果把前面最基礎的東西都丟了,協程、xpath、css等等。藉著這次的作業練習,把前面的知識複習一下。
二、爬取目標
爬取小說《動物莊園》全部章節並按章節分類儲存為txt檔案。
目標url:https://www.kanunu8.com/book3/6879/
三、分析過程
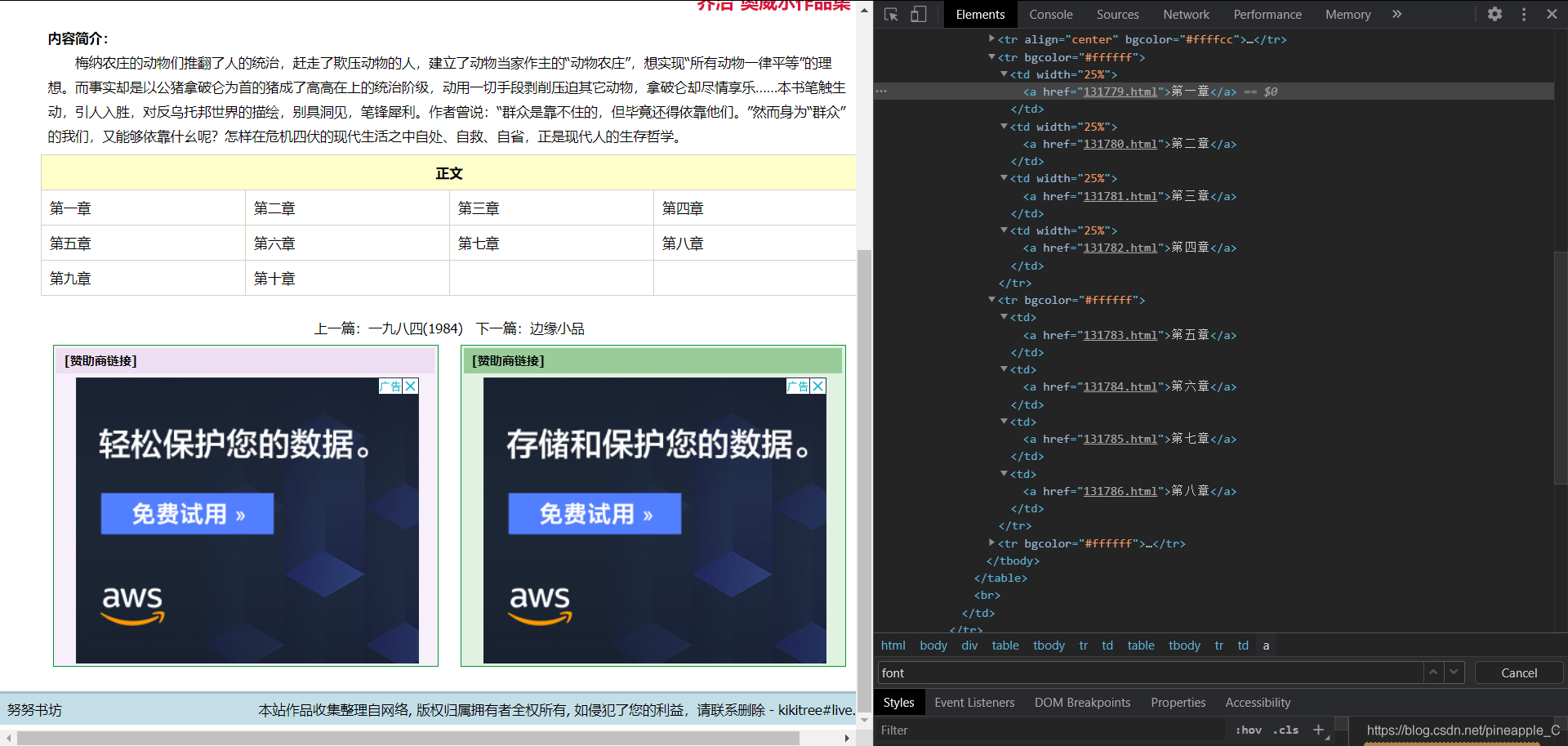
這是目錄頁面,通過結點定位可以獲取每一章節的url,但是這樣會多請求一次,而且還要寫定位的程式碼。觀察這10個url,它們是有規律的,從131779到131788,隨著章節數的增加,這個引數也會跟著加一。所以很容易構造出這10個url。
def get_url():
"""
構造url
:return: None
"""
for page in range(131779, 131789):
yield f'https://www.kanunu8.com/book3/6879/{str(page)}.html'
接著進入文章頁面
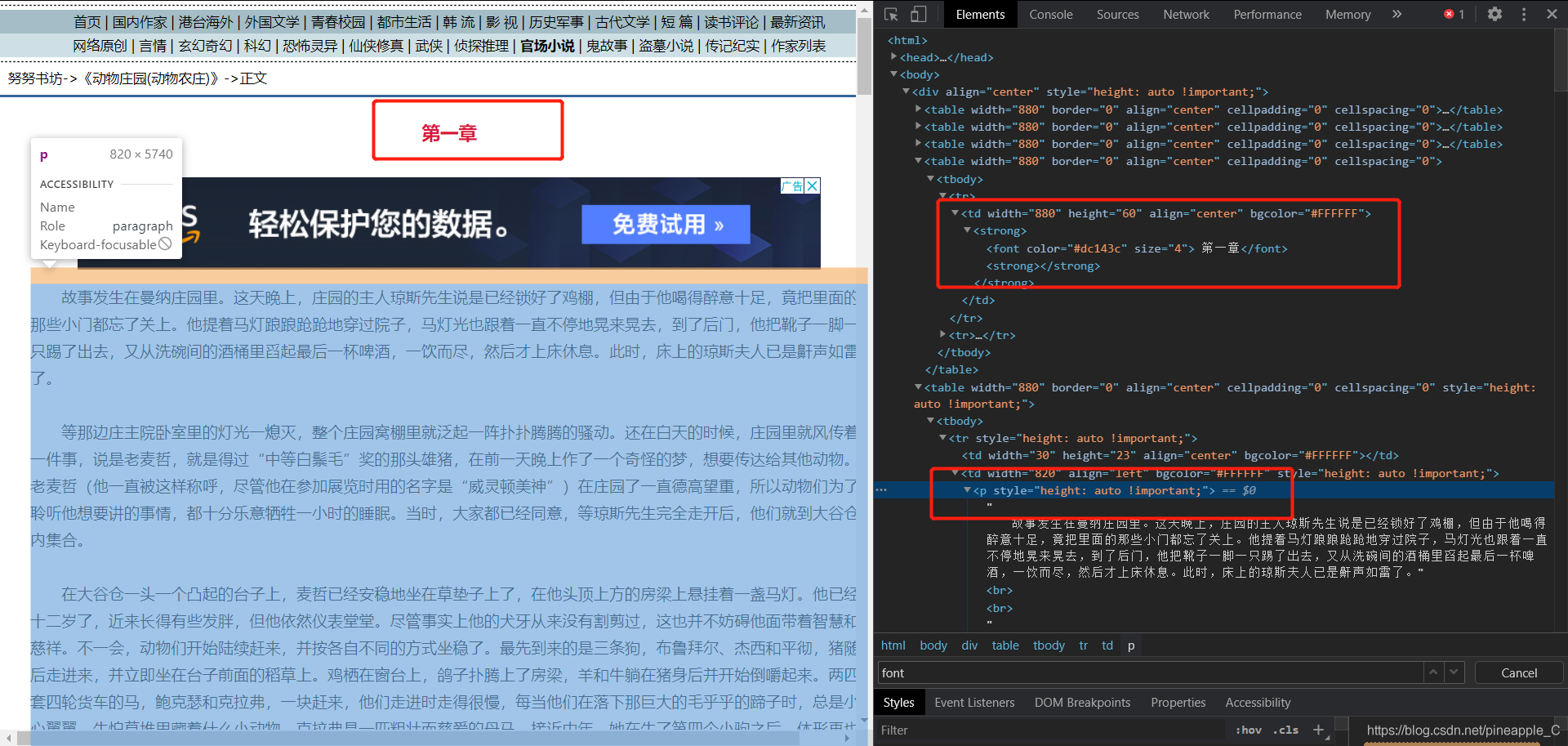
定位一下章節和內容,為了複習,我用了三種不同的匹配方式,還有非同步IO請求。
async def get_content(url):
"""
獲取文章內容
:param url:
:return: None
"""
async with aiohttp.ClientSession() as session:
async with session.get(url, headers=headers) as response:
if response.status == 200:
response = await response.text()
# 正規表示式匹配
section = re.search(r'<font.*?>(.*?)</font>', response).group(1)
content = re.search(r'<p>(.*?)</p>', response, re.S).group(1)
# # xpath匹配
# html=etree.HTML(response)
# section=html.xpath('//font/text()')[0]
# content=''
# for paragrath in html.xpath('//tr/td[2]/p/text()'):
# content+=paragrath
# # css匹配
# doc=pq(response)
# section=doc('font').text()
# content=doc('tr > td:nth-child(2) >p').text()
save_to_txt(section, content)
else:
logger.error(f'{url} 請求失敗')
這樣一來章節和內容就都獲取到了,下面就是儲存到txt檔案,並且去掉一些髒資料,比如多餘的空格,換行, <br>結點等。
def save_to_txt(section, content):
"""
儲存為txt檔案
:param section: 章節
:param content: 內容
:return: None
"""
if not os.path.exists(path):
os.mkdir(path)
# xpath匹配不用替換<br />
content = content.replace('<br />', '').strip('\n')
with open(f'{path}/{section}.txt', 'w', encoding='utf-8') as file:
file.write(content)
logger.success(f'{section} 下載成功')
注意:如果是用xpath,<br>結點會自動轉換成換行,所以要將替換那部分的程式碼註釋掉
四、完整程式碼
# -*- encoding: utf-8 -*-
'''
@File :spider.py
@Author :Pineapple
@Modify Time :2020/9/29 21:11
@Contact :cppjavapython@foxmail.com
@GitHub :https://github.com/Pineapple666
@Blog :https://blog.csdn.net/pineapple_C
@Desciption :None
'''
# import lib
from pyquery.pyquery import PyQuery as pq
from os.path import dirname, abspath
from loguru import logger
from lxml import etree
import aiohttp
import asyncio
import time
import re
import os
start = time.time()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
loop = asyncio.get_event_loop()
tasks = []
path = dirname(abspath(__file__)) + '/content'
def get_url():
"""
構造url
:return: None
"""
for page in range(131779, 131789):
yield f'https://www.kanunu8.com/book3/6879/{str(page)}.html'
async def get_content(url):
"""
獲取文章內容
:param url:
:return: None
"""
async with aiohttp.ClientSession() as session:
async with session.get(url, headers=headers) as response:
if response.status == 200:
response = await response.text()
# 正規表示式匹配
section = re.search(r'<font.*?>(.*?)</font>', response).group(1)
content = re.search(r'<p>(.*?)</p>', response, re.S).group(1)
# # xpath匹配
# html=etree.HTML(response)
# section=html.xpath('//font/text()')[0]
# content=''
# for paragrath in html.xpath('//tr/td[2]/p/text()'):
# content+=paragrath
# # css匹配
# doc=pq(response)
# section=doc('font').text()
# content=doc('tr > td:nth-child(2) >p').text()
save_to_txt(section, content)
else:
logger.error(f'{url} 請求失敗')
def save_to_txt(section, content):
"""
儲存為txt檔案
:param section: 章節
:param content: 內容
:return: None
"""
if not os.path.exists(path):
os.mkdir(path)
# xpath匹配不用替換<br />
content = content.replace('<br />', '').strip('\n')
with open(f'{path}/{section}.txt', 'w', encoding='utf-8') as file:
file.write(content)
logger.success(f'{section} 下載成功')
if __name__ == '__main__':
for url in get_url():
tasks.append(get_content(url))
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
logger.info(f'用時 {end - start}s')
如有錯誤,歡迎私信糾正!
技術永無止境,謝謝支援!