【案例】python資料分析案例分享
寫在前面的話:切記切記要設定休眠,不能頻繁請求
小白的一點案例記錄,望大神們手下留情。。。
共兩部分原始碼分別見3.1和3.2
一、背景前提
日常辛苦工(mo)作(yu)之後的某時,心血來潮想查下以前離職公司現在怎麼樣了,於是各種企業資訊查詢,某查查登場,註冊–>驗證–>繫結–>登入,還好可以看了,猛然眼前一亮,訴訟異常,悲(竊)傷(喜)著點開,會員,看不到全部內容,咱也理解,畢竟人家是公司不是盈利機構,於是乎,就有了本文的初始念頭:我自己取資料自己查詢自己分析!
二、準備工作
再叨叨一句:小心,爬著爬著就進去了!
用selenium模擬比較真實一些,慢就慢點無所謂
環境:win10、python3.7
工具:anaconda spyder、chrome driver
三方包:selenium、pandas、bs4、requests、random
三、資料採集及清洗
分析了下網站結構,
1、首頁的搜尋按鈕必須輸入關鍵詞才能搜尋,不同關鍵詞的搜尋結果數量不一;
2、搜尋「0」出現的案例條數,與首頁下方的案例點選後相加得到的條數一致;
3、列表頁的標題行固定為class="fd-list-01";
4、標題頁沒有進入詳情頁的連線;且點選標題後,新視窗開啟詳情頁;
5、開啟詳情頁後發現,詳情頁連線較統一,拼接變數為文章型別和文章ID;
6、列表頁標題中的onclick即有此兩個變數;
7、測試驗證上述5和6成功;
8、湊個數吧;
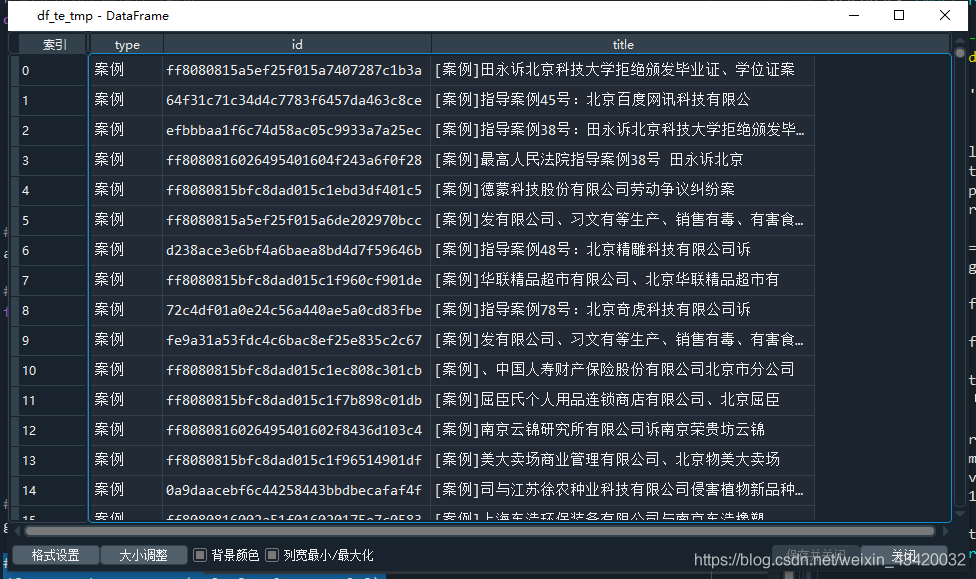
1.目錄採集
先上原始碼: 
# -*- coding: utf-8 -*-
"""
Created on Thu Sep 24 16:52:53 2020
@author: janlyn
"""
from selenium import webdriver
import time
import pandas as pd
import random
driver = webdriver.Chrome()
driver.get(圖片)
driver.find_element_by_id('fd-search').send_keys('0')
driver.find_element_by_class_name('fd-btn').click()
driver.switch_to.window(driver.window_handles[1])
# 獲取列表頁資訊
def get_data():
items = driver.find_elements_by_class_name('fd-list-01')
for ele in items[1:]:
titles = ele.text
a = ele.find_element_by_tag_name('a')
# 獲取onlick中的內容
alls = a.get_attribute('onclick')
if alls:
# 提取onlick中的內容,完整內容為
# οnclick="ckxq('開庭公告','D5EA00BE1700316F2AA7B7C5EEF535F5')"
li = alls.replace("ckxq('","").replace("')","").split("','")
li.append(titles)
al.append(li)
# 點選下一頁
def click_next():
pages = driver.find_element_by_class_name('pageBtnWrap').find_elements_by_tag_name('a')
for page in pages:
title = page.get_attribute('title')
if title == '下一頁':
page.click()
# 若失敗則重新執行當前頁
def loop_temp(func,page):
reg = 1
while reg == 1:
try:
func
reg = 0
print('{}執行成功'.format(page))
except:
print('{}執行失敗,再來一次'.format(page))
reg = 1
# 欄位頭,type和id需要構造詳情頁url,title只是順手取出來,方便驗證
al = [['type','id','title']]
# 迴圈遍歷全部頁數
for i in range(1,28):
loop_temp(get_data(),i)
reg = 1
# 判斷獲取的資料是否為當前遍歷頁資料
while reg == 1:
loop_temp(click_next(),i)
time.sleep(random.randrange(50,150,10)/100)
curr = driver.find_element_by_class_name('curr').text
if curr == str(i+1):
reg = 0
# 最後一頁直接獲取資料
get_data()
# 轉為df資料框,方便操作
df_te = pd.DataFrame(te[1:],columns=te[0])
# 去重資料
df_te_tmp = df_te.drop_duplicates()
# 儲存列表資料
df_te_tmp.to_excel('spyder.xlsx',index=False)
直接儲存執行肯定會出錯滴,你得偵錯吶,這又不是成品原始碼;
思路如下:
1.0範例化瀏覽器
driver = webdriver.Chrome()
1.1開啟網站
.get()方法開啟連結

driver.get(圖片)
1.2輸入關鍵詞
.send_keys()方法輸入內容
driver.find_element_by_id('fd-search').send_keys('0')
1.3點選檢索
.click()方法進行點選
driver.find_element_by_class_name('fd-btn').click()
1.4切換視窗
可以通過driver.title檢視當前tab標題
可以通過driver.refresh()重新整理當前tab
driver.window_handles獲取tab控制程式碼
.switch_to.window()根據控制程式碼進行切換
driver.switch_to.window(driver.window_handles[1])
1.5獲取列表頁資料
.get_attribute()可獲取當前元素中的指定屬性值,前文述的型別和id均可在’onlick’中進行獲取
# 獲取列表頁資訊
def get_data():
items = driver.find_elements_by_class_name('fd-list-01')
for ele in items[1:]:
titles = ele.text
a = ele.find_element_by_tag_name('a')
# 獲取onlick中的內容
alls = a.get_attribute('onclick')
if alls:
# 提取onlick中的內容,完整內容為
# οnclick="ckxq('開庭公告','D5EA00BE1700316F2AA7B7C5EEF535F5')"
li = alls.replace("ckxq('","").replace("')","").split("','")
li.append(titles)
al.append(li)
1.6點選下一頁
迴圈class為pageBtnWrap的a標籤,並判斷title的值是否為下一頁,若是則點選
# 點選下一頁
def click_next():
pages = driver.find_element_by_class_name('pageBtnWrap').find_elements_by_tag_name('a')
for page in pages:
title = page.get_attribute('title')
if title == '下一頁':
page.click()
1.7列表頁結束
點選下一頁或獲取列表頁失敗時,需要重新嘗試
# 若失敗則重新執行當前頁
def loop_temp(func,page):
reg = 1
while reg == 1:
try:
func
reg = 0
print('{}執行成功'.format(page))
except:
print('{}執行失敗,再來一次'.format(page))
reg = 1
已知失敗原因如下:
1)點選下一頁後實際未點選(可能頁面未載入完成導致),導致重複採集;
2)點選下一頁後,頁面未載入完畢,導致頁面屬性缺失,從而獲取不到列表頁相關資訊;
3)點選過快導致頁面載入失敗;
pd可以直接將二維陣列轉化為資料框,故將提取的資料存為列表,先上欄位表頭
# 欄位頭,type和id需要構造詳情頁url,title只是順手取出來,方便驗證
al = [['type','id','title']]
並回圈遍歷每一頁進行採集
最後一頁時多呼叫一次列表資料,而不需要進入迴圈
# 迴圈遍歷全部頁數
for i in range(1,28):
loop_temp(get_data(),i)
reg = 1
# 判斷獲取的資料是否為當前遍歷頁資料
while reg == 1:
loop_temp(click_next(),i)
time.sleep(random.randrange(50,150,10)/100)
curr = driver.find_element_by_class_name('curr').text
if curr == str(i+1):
reg = 0
# 最後一頁直接獲取資料
get_data()
# 轉為df資料框,方便操作
df_te = pd.DataFrame(te[1:],columns=te[0])
# 去重資料
df_te_tmp = df_te.drop_duplicates()
# 儲存列表資料,到當前工作目錄下
df_te_tmp.to_excel('spyder.xlsx',index=False)
2.詳情頁採集
上原始碼
在這裡插入程式碼片
2.1讀取列表頁採集結果
detail = pd.read_excel('spyder.xlsx')
2.2構造url
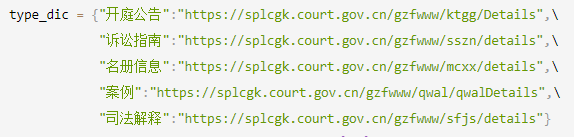
type_dic = {圖片}
url = type_dic[detail_type]
url = '{}?id={}'.format(url,detail_id)
2.3請求連結並清洗資料
2.3.1方法一:requests模擬請求頭獲取(不推薦)
此處有個工具,詳見:curl轉python

def get_detail_spyder(detail_type = '案例',detail_id = 'ff8080815a5ef25f015a7407287c1b3a',title='列表標題'):
# BeautifulSoup 解析
headers = {
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Referer': 圖片,
'Accept-Language': 'zh-CN,zh;q=0.9',
}
# params = (('id', detail_id),)
url = type_dic[detail_type]
url = '{}?id={}'.format(url,detail_id)
try:
# 隨機休眠0.5-1.5秒
time.sleep(random.randrange(50,150,10)/100)
# response = requests.get(url, headers=headers, params=params)
response = requests.get(url, headers=headers)
bsobj = BeautifulSoup(response.text,'lxml')
# 標題正文等合體
bs_all = bsobj.find(attrs={"class":"fd-fix"})
# 文章標題
title_name = bs_all.findChild().text
# 文章標題下方的文章資訊,待解析
title_info = bs_all.findChild().findNext().text
fabudanwei,suoshushengfen,fabushijian,liulanliang=('','','','')
# 有的文章無該4個欄位中的某個,故迴圈遍歷匹配提取
for i in title_info.split('\u3000\u3000'):
if '釋出單位' in i:
fabudanwei = i.split(':')[1]
elif '所屬省份' in i:
suoshushengfen = i.split(':')[1]
elif '釋出時間' in i:
fabushijian = i.split(':')[1]
elif '瀏覽量' in i:
liulanliang = i.split(':')[1]
zhengwen_html = str(bs_all.find(attrs={"class":"fd-alt-all"}))
# 清除style標籤
[s.extract() for s in bs_all("style")]
zhengwen = bs_all.find(attrs={"class":"fd-alt-all"}).text
# 構造並返回字典
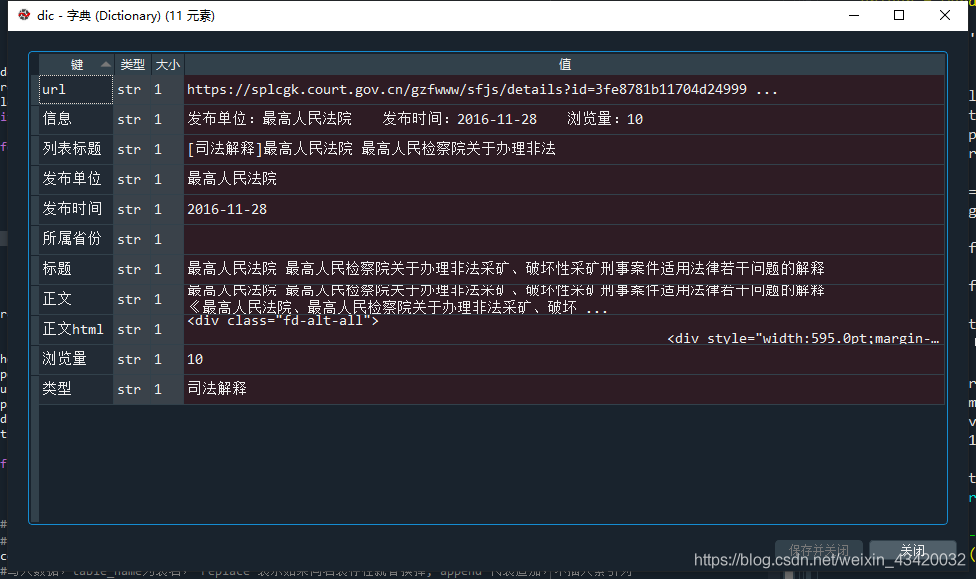
dic = {'型別':detail_type,'標題':title_name,'列表標題':title,'資訊':title_info,\
'釋出單位':fabudanwei,'所屬省份':suoshushengfen,'釋出時間':fabushijian,\
'瀏覽量':liulanliang,'正文html':zhengwen_html,'正文':zhengwen,'url':url}
return dic
except Exception as e:
print(url,e)
return 0
2.3.2方法二:selenium模擬瀏覽器(推薦)
def get_detail(driver,detail_type = '案例',detail_id = 'ff8080815a5ef25f015a7407287c1b3a',title='列表標題'):
# selenium解析
url = type_dic[detail_type]
url = '{}?id={}'.format(url,detail_id)
driver.get(url)
# 隨機休眠0.5-1.5秒
time.sleep(random.randrange(50,150,10)/100)
try:
# 標題正文等合體
bs_all = driver.find_element_by_class_name('fd-fix')
# 文章標題
title_name = bs_all.find_element_by_tag_name('h2').text
# 文章標題下方的文章資訊,待解析
title_info = bs_all.find_element_by_tag_name('h5').text
fabudanwei,suoshushengfen,fabushijian,liulanliang=('','','','')
# 有的文章無該4個欄位中的某個,故迴圈遍歷匹配提取
for i in title_info.split('\u3000\u3000'):
if '釋出單位' in i:
fabudanwei = i.split(':')[1]
elif '所屬省份' in i:
suoshushengfen = i.split(':')[1]
elif '釋出時間' in i:
fabushijian = i.split(':')[1]
elif '瀏覽量' in i:
liulanliang = i.split(':')[1]
zhengwen_html = bs_all.find_element_by_class_name('fd-alt-all').get_attribute('outerHTML')
zhengwen = bs_all.find_element_by_class_name('fd-alt-all').text
# 構造並返回字典
dic = {'型別':detail_type,'標題':title_name,'列表標題':title,'資訊':title_info,\
'釋出單位':fabudanwei,'所屬省份':suoshushengfen,'釋出時間':fabushijian,\
'瀏覽量':liulanliang,'正文html':zhengwen_html,'正文':zhengwen,'url':url}
return dic
except Exception as e:
print(url,e)
return 0
2.4自主選擇方法一或方法二
leixing = 2
if leixing == 2:
driver = webdriver.Chrome()
for index,detail_type,detail_id,title,url in detail.itertuples():
print('正在獲取第{}條資料...,連線:{}'.format(index+1,url))
while True:
if leixing == 1:
dic = get_detail_spyder(detail_type,detail_id,title)
elif leixing == 2:
dic = get_detail(driver,detail_type,detail_id,title)
if dic:
result_list.append(dic)
break
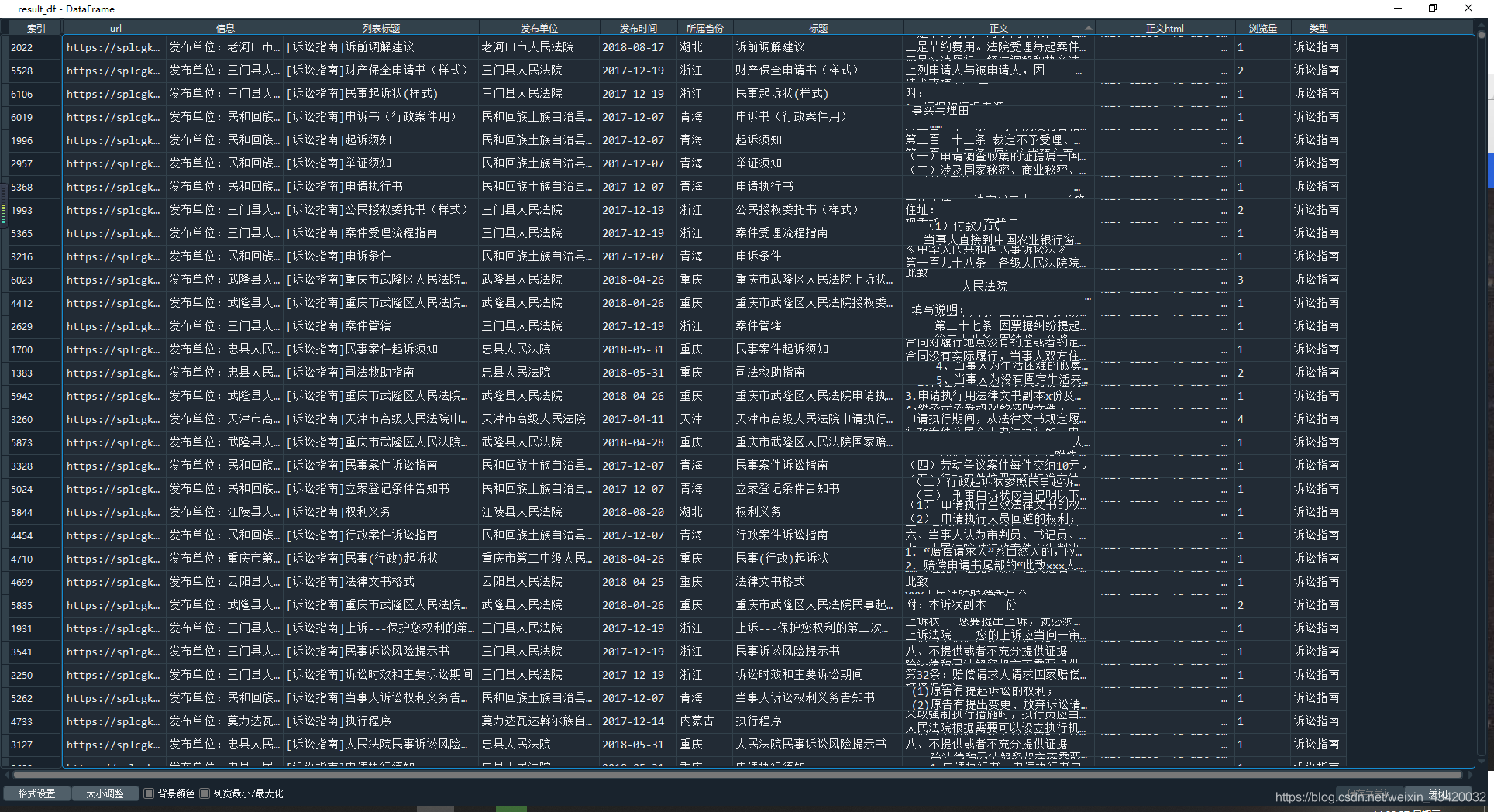
result_df = pd.DataFrame(result_list)
四、資料分析
見下篇