快手爬蟲 解決粉絲數 關注數等字型加密 python快手爬蟲
2020-09-30 18:00:45
想拿一下粉絲數 關注數 描述等
發現字型是加密的 elements是這樣的
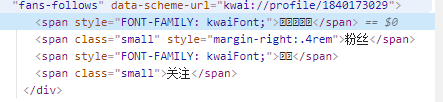
原始碼裡是這樣的

找了找js 原來是用

這些玩意 去

這個ttf裡一一對應 然後用 js + css畫出來的
找到問題所在,就fuck掉它
把js扣出來?用execjs去執行?太LOW了
既然做python 那就用python去重寫
首先用re去拿這個ttf的url (因為每次都變)

先給這玩意下載下來 把這個ttf檔案扔fonteditor裡 然後去
http://fontstore.baidu.com/static/editor/index.html
瞅瞅
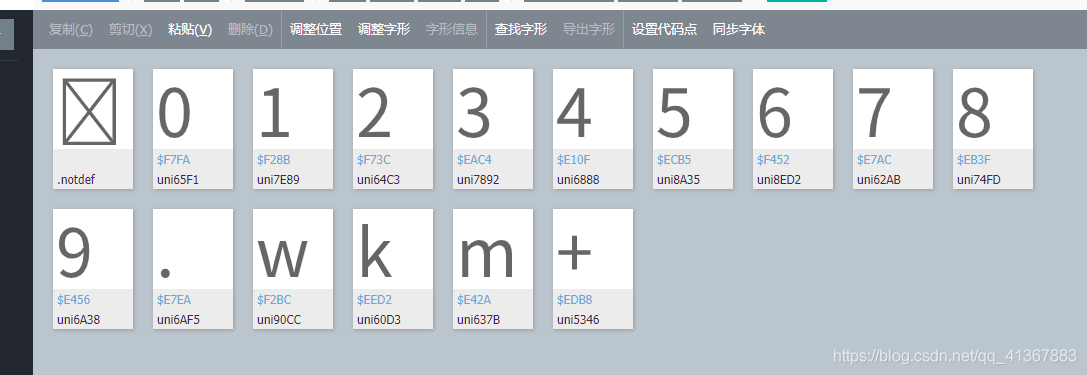
這個時候就發現了東西

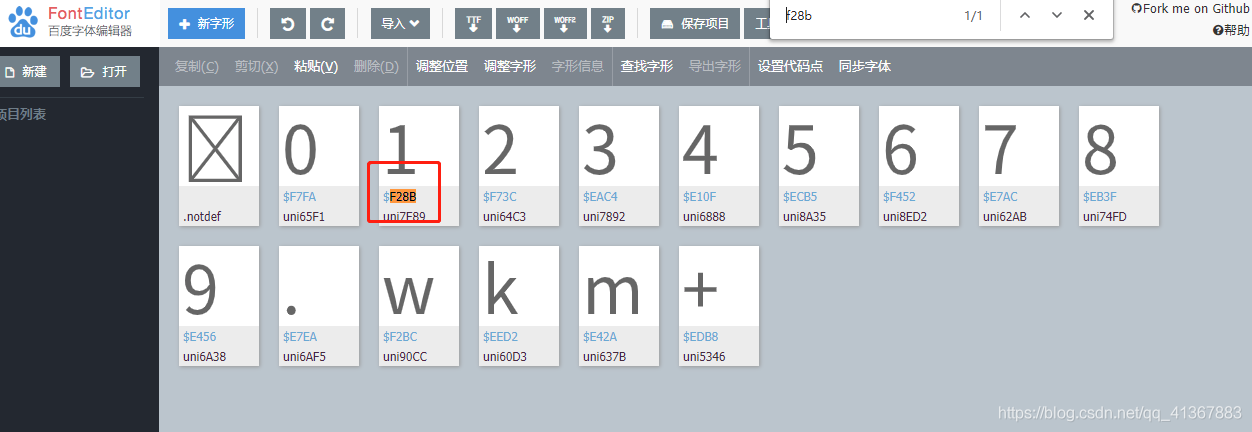
不就是這玩意嗎,找到對應關係了 那就ok了
TTF檔案沒辦法直接搞啊 ?怎麼辦
儲存成xml !
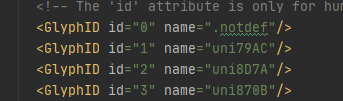 然後就成了這玩意 ok對應關係也有了 python也能搞了
然後就成了這玩意 ok對應關係也有了 python也能搞了
去寫一下 整邏輯就是
先去拿 ttf檔案 url 請求url 儲存 然後轉xml
然後 拿加密前的特殊字元
# 就是這玩意

然後去切割 對應 OK完事
對應關係的程式碼
根據看到的 id : 0啥也不說
從1~15 就是這些東西
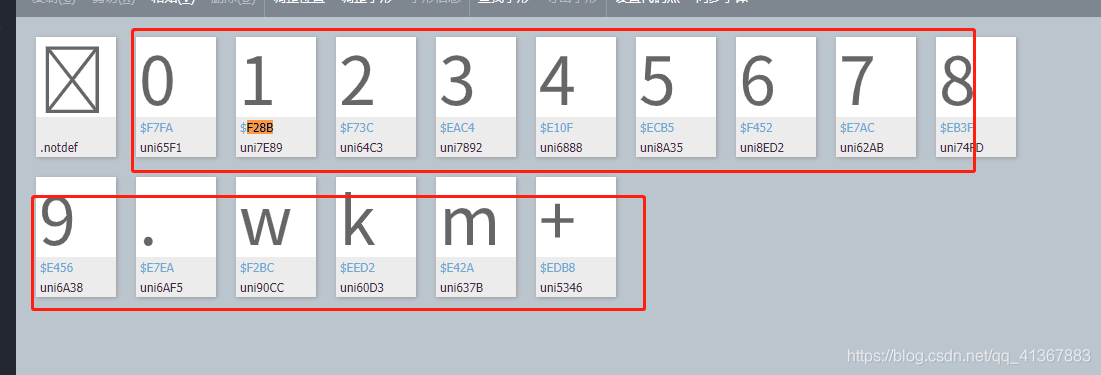
上程式碼
# 對應關係
def kuaishou_un_font(soup, font_size):
# soup 就是傳的 ttf轉碼成xml的
font_dict = {}
for font_m in soup.glyphorder.children:
if font_m != '\n' and 'humans' not in font_m:
id = font_m.get('id')
name = font_m.get('name')
if id != '0' and int(id) < 11:
font_dict[name] = str(int(id)-1)
elif id == '11':
font_dict[name] = '.'
elif id == '12':
font_dict[name] = 'w'
elif id == '13':
font_dict[name] = 'k'
elif id == '14':
font_dict[name] = 'm'
elif id == '15':
font_dict[name] = '+'
size_dict = {}
for font_k in soup.cmap_format_4.children:
if 'map' in str(font_k):
code = font_k.get('code')[-4:]
name = font_k.get('name')
size_dict[code] = name
return font_dict[size_dict[font_size]]
然後是拿TTF 檔案然後轉成xml
# TTF轉XML
font = TTFont('font_size.ttf')
font.saveXML('font_size.xml')
和split後list去一一解密
# font_url 自己去動態拿 每次都變動
font_url = ''
font_res = requests.get(font_url)
with open('font_size.ttf', 'wb+') as f:
f.write(font_res.content)
font = TTFont('font_size.ttf')
font.saveXML('font_size.xml')
soup = BeautifulSoup(open('font_size.xml'), 'lxml')
try:
fan = user_data_json['obfuseData']['fan'][40:-8].split(';&#x')
fans = ''
for f in fan:
fans += kuaishou_un_font(soup, f)
except:
fans = ''
最後
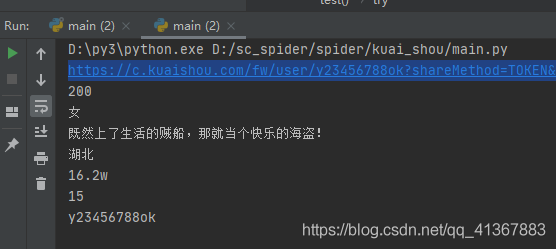
OK~ 解碼完成 全部程式碼沒放 因為是根據需求寫的 懶得改成大家都能用的了 主要是給個思路 思路有了就很簡單 需要的找我