基於hadoop-2.8.5下的雲環境搭建
基於hadoop-2.8.5下的雲環境搭建
- 一、Hdfs搭建過程(By 儺儺)
- 二、yarn設定(By Ninght)
- 1.基本引數設定
- 1>.yarn.resourcemanager.hostname
- 2>.yarn.resourcemanager.address
- 3>.yarn.resourcemanager.webapp.address
- 4>.yarn.resourcemanager.scheduler.address
- 5>.yarn.resourcemanager.resource-tracker.address
- 6>.yarn.resourcemanager.admin.address
- 7>.yarn.nodemanager.aux-services
- 8>.yarn.log-aggregation-enable
- 9>. yarn.log-aggregation.retain-seconds
- 10>.yarn.application.classpath
- 11>.yarn.nodemanager.pmem-check-enabled
- 12>.yarn.nodemanager,vmem-check-enabled
- 2.遇見問題及解決方法
- 三、spark搭建過程(By 哎呀)
- 四、hdfs、spark、spark搭建過程的改進與整合(By 儺儺)
- 五、可能遇到的問題及解決方法(By 儺儺、Ninght)
一、Hdfs搭建過程(By 儺儺)
1、準備
- 安裝docker,映象站daocloud提供一鍵安裝命令:
curl -sSL https://get.daocloud.io/docker | sh
- 在映象站daocloud拉取centos7映象:
docker pull daocloud.io/library/centos:centos7
- 建立docker的自定義網路,目的是為了固定ip,docker預設使用bridge網路,無法固定ip
docker network create --subnet=172.22.0.0/24 jbhnetwork
- 新建一個資料夾並進入資料夾所在路徑,將jdk安裝包、hadoop安裝包以及待會兒編寫的dockerfile都放入這個資料夾內
下載jdk安裝包:
wget https://repo.huaweicloud.com/java/jdk/8u192-b12/jdk-
8u192-linux-x64.tar.gz
下載hadoop安裝包:
wget
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
2、編寫dockerfile
在剛剛新建的hadoop資料夾下編寫dockerfile:
vim Hadoop-Dockerfile
Hadoop-Dockerfile內容:
(具體註釋參考(這裡))
FROM centos:centos7 MAINTAINER 「jbh1283432219@qq.com」 RUN yum -y
install openssh-server openssh-clients sudo vim net-tools RUN
ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key RUN ssh-keygen -t ecdsa
-f /etc/ssh/ssh_host_ecdsa_key RUN ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key RUN echo 「root:root」 | chpasswd RUN
mkdir /opt/software && mkdir /opt/moudle ADD
jdk-8u192-linux-x64.tar.gz /opt/moudle ADD hadoop-2.8.5.tar.gz
/opt/software ENV CENTOS_DEFAULT_HOME /root ENV JAVA_HOME
/opt/moudle/jdk1.8.0_192 ENV JRE_HOME ${JAVA_HOME}/jre ENV CLASSPATH
J A V A H O M E / l i b : {JAVA_HOME}/lib: JAVAHOME/lib:{JRE_HOME}/lib ENV HADOOP_HOME
/opt/software/hadoop-2.8.5 ENV PATH
J A V A H O M E / b i n : {JAVA_HOME}/bin: JAVAHOME/bin:{HADOOP_HOME}/bin: H A D O O P H O M E / s b i n : {HADOOP_HOME}/sbin: HADOOPHOME/sbin:PATH WORKDIR
$CENTOS_DEFAULT_HOME EXPOSE 22 CMD ["/usr/sbin/sshd", 「-D」]
上面的dockerfile寫得不好,連續的RUN和ENV可以合併,例如上面的
RUN yum -y install openssh-server openssh-clients sudo vim net-tools
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key RUN ssh-keygen -t
ecdsa -f /etc/ssh/ssh_host_ecdsa_key RUN ssh-keygen -t ed25519 -f
/etc/ssh/ssh_host_ed25519_key RUN echo 「root:root」 | chpasswd RUN
mkdir /opt/software && mkdir /opt/moudle
寫成下面這樣會更好
RUN yum -y install openssh-server openssh-clients sudo vim net-tools
&& ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key \ && ssh-keygen -t
ecdsa -f /etc/ssh/ssh_host_ecdsa_key \ && ssh-keygen -t ed25519 -f
/etc/ssh/ssh_host_ed25519_key \ && echo 「root:root」 | chpasswd \ &&
mkdir /opt/software && mkdir /opt/moudle
3、構建映象
dockerfile構建映象時會預設從當前目錄讀取並構建,注意命令最後有個英文句號
docker build -f Hadoop-Dockerfile -t jbh/hadoop:2.8.5 .
構建成功:
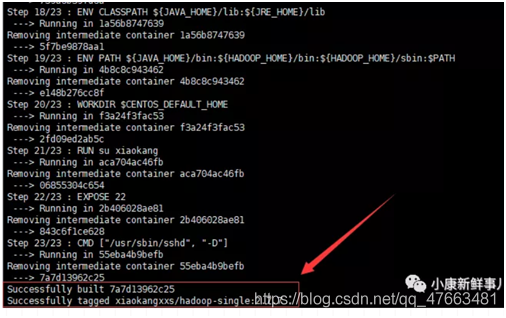 可以檢視映象資訊:
可以檢視映象資訊:
docker images
應該會有jbh/hadoop和centos兩個映象
4、根據構建好的映象建立並進入容器
建立一個namenode和兩個datanode,命令裡的56a73b3d978d是映象id(映象id可以在docker images下檢視,如圖)

docker run -d --name hadoop01 --hostname hadoop01 --net jbhnetwork
–ip 172.22.0.2 -P -p 50070:50070 -p 8088:8088 -p 19888:19888 --privileged 56a73b3d978d /usr/sbin/init docker run -d --name hadoop02 --hostname hadoop02 --net jbhnetwork --ip 172.22.0.3 -P --privileged 56a73b3d978d /usr/sbin/init docker run -d --name hadoop03 --hostname
hadoop03 --net jbhnetwork --ip 172.22.0.4 -P --privileged
56a73b3d978d /usr/sbin/init
檢視正在執行的容器
docker ps
分別進入三個容器(下面命令中的08fa60c9b188是容器id,可在docker ps中檢視)

5、修改設定
1.編輯/etc下的hosts檔案,設定ip和hostname的對映
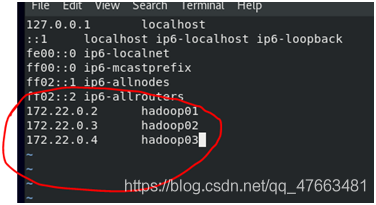 2. 設定ssh免密登陸
2. 設定ssh免密登陸
在三臺容器裡都進行如下操作
ssh-keygen -t rsa -N ‘’ ssh-copy-id-i~/.ssh/id_rsa.pub hadoop01
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop02 ssh-copy-id -i
~/.ssh/id_rsa.pub hadoop03
- 在主節點hadoop01上修改組態檔
先建立所需目錄
[root@hadoop01 ~]$ mkdir /opt/software/hadoop-2.8.5/tmp [root@hadoop01
~]$ mkdir -p /opt/software/hadoop-2.8.5/dfs/namenode_data
[root@hadoop01 ~]$ mkdir -p
/opt/software/hadoop-2.8.5/dfs/datanode_data [root@hadoop01 ~]$ mkdir
-p /opt/software/hadoop-2.8.5/checkpoint/dfs/cname
再修改/opt/software/hadoop-2.8.5/etc/hadoop/目錄下的組態檔
(具體的註釋可參考這裡)
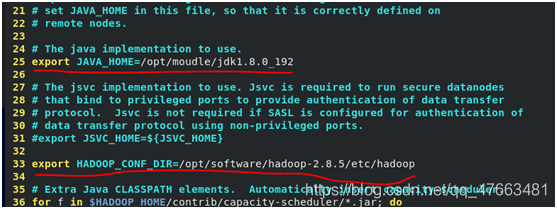
hadoop-env.sh
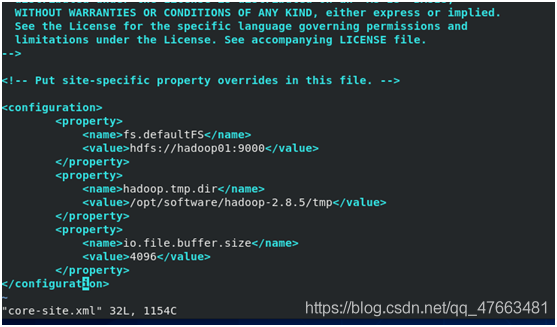
core-site.xml
 hdfs-site.xml
hdfs-site.xml
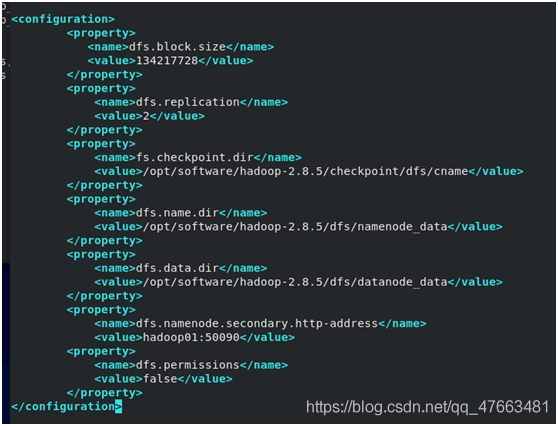 mapred-site.xml
mapred-site.xml
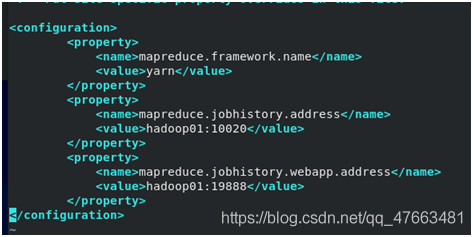 yarn-site.xml
yarn-site.xml
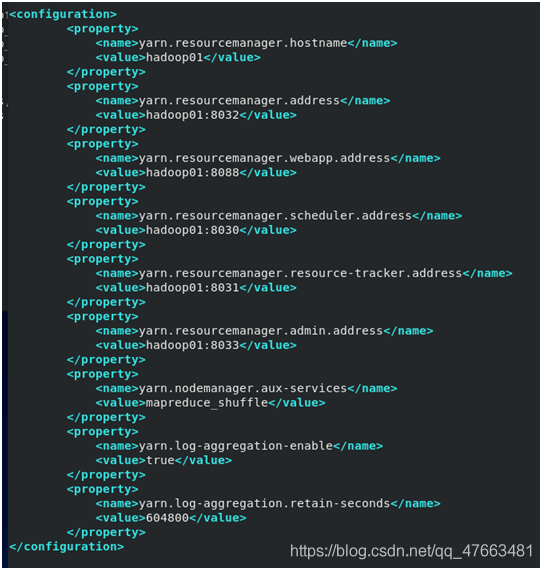 master(在當前組態檔目錄內是不存在master檔案的,用vim寫入內容到master內儲存即可)
master(在當前組態檔目錄內是不存在master檔案的,用vim寫入內容到master內儲存即可)
slaves
再把設定好的檔案分發到另外兩個節點上:
scp -r /opt/software/hadoop-2.8.5/ root@hadoop02:/opt/software/ scp -r
/opt/software/hadoop-2.8.5/ root@hadoop03:/opt/software/
最後再初始化:
hdfs namenode -format
6、啟動叢集
在主節點hadoop01上啟動叢集,hadoop02、hadoop03上的相關服務也會啟動
#啟動dfs服務 start-dfs.sh
#啟動yarn服務 start-yarn.sh
#啟動任務歷史伺服器 mr-jobhistory-daemon.sh start historyserver
 完成!
完成!
7、檢查
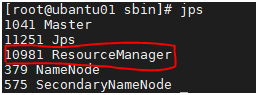
可用jps檢視程序檢驗是否成功啟動
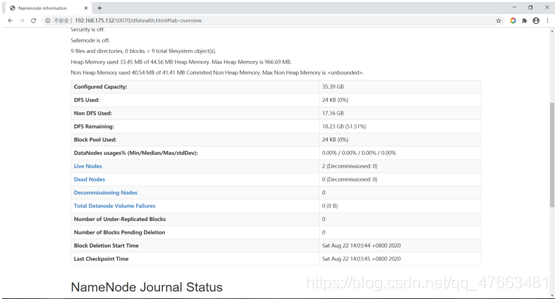
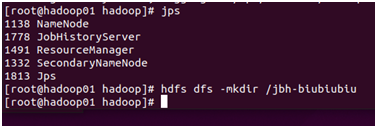 也可以在web介面上檢視:
也可以在web介面上檢視:
Hdfs介面:
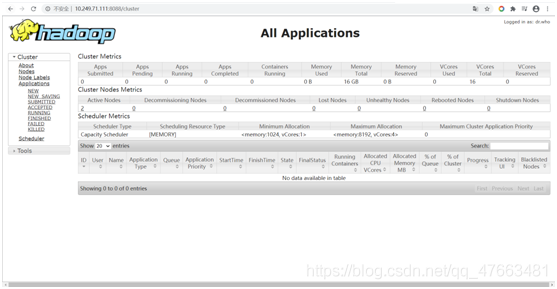
 Yarn介面:
Yarn介面:
 Jobhistory介面:
Jobhistory介面:
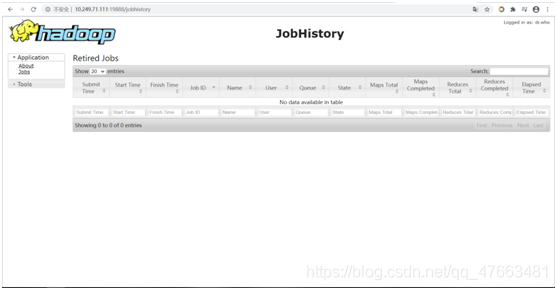 驗證hdfs能否正常使用:
驗證hdfs能否正常使用:
新建資料夾
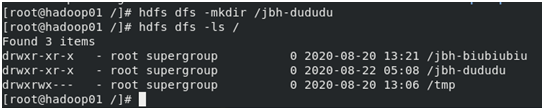 web頁面也能看到新建的資料夾
web頁面也能看到新建的資料夾
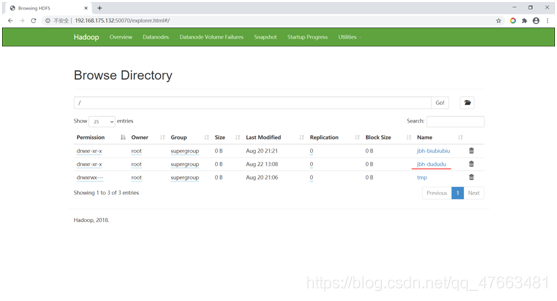 刪除檔案:
刪除檔案:
 上傳/寫入檔案:
上傳/寫入檔案:
 下載/讀取檔案:
下載/讀取檔案:
 檢視檔案:
檢視檔案:
 檢視空間:
檢視空間:

8、打包(可選操作)
可將將搭建好的三個容器儲存為映象並打包成壓縮包:


若想用打包好的壓縮包恢復三個容器,則先把壓縮包恢復成映象:
docker load -i hadoop01.tar.gz docker load -i hadoop01.tar.gz docker
load -i hadoop01.tar.gz
再將映象恢復成容器(和上面建立容器步驟一樣):

二、yarn設定(By Ninght)
在hadoop2.8.5安裝後自帶的yarn中進行yarn設定
在進入容器後的目錄
/opt/software/hadoop-2.8.5/etc/hadoop
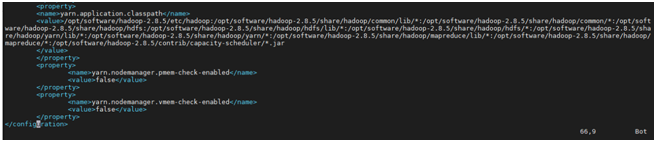
通過vim命令按照下圖編輯yarn-site.xml檔案
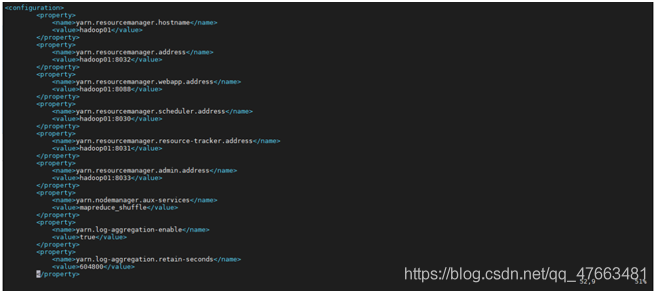
 其中:
其中:
1.基本引數設定
1>.yarn.resourcemanager.hostname
為全域性資源管理器(ResourcManager)的主機名稱
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
2>.yarn.resourcemanager.address
為ResourceManager 對使用者端暴露的地址。使用者端通過該地址向RM提交應用程式,殺死應用程式。預設值為${yarn.resourcemanager.hostname}:8032
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop01:8032</value>
</property>
3>.yarn.resourcemanager.webapp.address
ResourceManager對外web ui地址。使用者可通過該地址在瀏覽器中檢視叢集各類資訊。預設值為${yarn.resourcemanager.hostname}:8088
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:8088</value>
</property>
4>.yarn.resourcemanager.scheduler.address
ResourceManager 對ApplicationMaster暴露的存取地址。ApplicationMaster通過該地址向RM申請資源、釋放資源等。
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop01:8030</value>
</property>
5>.yarn.resourcemanager.resource-tracker.address
ResourceManager 對NodeManager暴露的地址.。NodeManager通過該地址向RM彙報心跳,領取任務等。預設值${yarn.resourcemanager.hostname}:8031
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop01:8031</value>
</property>
6>.yarn.resourcemanager.admin.address
ResourceManager 對管理員暴露的存取地址。管理員通過該地址向RM傳送管理命令等。預設值為${yarn.resourcemanager.hostname}:8033
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop01:8033</value>
</property>
7>.yarn.nodemanager.aux-services
NodeManager上執行的附屬服務。需設定成mapreduce_shuffle,才可執行MapReduce程式
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
8>.yarn.log-aggregation-enable
是否啟用紀錄檔聚集功能,預設值為false
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
9>. yarn.log-aggregation.retain-seconds
在HDFS上聚集的紀錄檔最多儲存的時間,預設值為-1
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>648000</value>
</property>
10>.yarn.application.classpath
用於引入hadoop路徑
在終端中通過
hadoop classpath
命令可以檢視

<property>
<name>yarn.application.classpath</name>
<value>/opt/software/hadoop-2.8.5/etc/hadoop:/opt/software/hadoop-2.8.5/share/hadoop/common/lib/*:/opt/software/hadoop-2.8.5/share/hadoop/common/*:/opt/software/hadoop-2.8.5/share/hadoop/hdfs:/opt/software/hadoop-2.8.5/share/hadoop/hdfs/lib/*:/opt/software/hadoop-2.8.5/share/hadoop/hdfs/*:/opt/software/hadoop-2.8.5/share/hadoop/yarn/lib/*:/opt/software/hadoop-2.8.5/share/hadoop/yarn/*:/opt/software/hadoop-2.8.5/share/hadoop/mapreduce/lib/*:/opt/software/hadoop-2.8.5/share/hadoop/mapreduce/*:/opt/software/hadoop-2.8.5/contrib/capacity-scheduler/*.jar
</value>
</property>
11>.yarn.nodemanager.pmem-check-enabled
是否啟動一個執行緒檢查每個任務正使用的實體記憶體量,如果任務超出分配值,則直接將其殺掉,預設是true。
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
12>.yarn.nodemanager,vmem-check-enabled
是否啟動一個執行緒檢查每個任務正使用的虛擬記憶體量,如果任務超出分配值,則直接將其殺掉,預設是true。
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2.遇見問題及解決方法
這裡設定完成後,在啟動yarn時出現了只有nodemanager而沒有啟動resourcemanager的情況,通過修改容器中
/opt/software/hadoop-2.8.5/sbin
路徑下的指令碼可以解決
vim yarn-daemon.sh
找到下面的語句
nohup nice -n Y A R N N I C E N E S S " YARN_NICENESS " YARNNICENESS"HADOOP_YARN_HOME"/bin/yarn --config $YARN_CONF_DIR c o m m a n d " command " command"@" > 「$log」 2>&1 < /dev/null &
將語句前的
nohup
刪去即可

這時再次啟動yarn可以發現能夠正常拉起resourcemanager程序
三、spark搭建過程(By 哎呀)
1、安裝Spark3.0.0
1.首先下載Spark安裝檔案:
存取Spark官方下載地址(以下操作均在主節點上進行)
2.下載如下名稱檔案:
spark-3.0.0-bin-without-hadoop.taz
3.以下裝配操作需要環境如下:
JAVA JDK 1.8
Hadoop 2.8.5及以上的叢集環境
4.下載完畢後,用以下命令解壓安裝包並修改目錄許可權:
sudo tar –zxf ~/downloads/spark-3.0.0-bin-without-hadoop.taz -C/usr/local
~/downloads………taz 為壓縮檔案的路徑及檔名,/usr/local為壓縮到的路徑
cd /usr/local
sudo mv ./spark-3.0.0-bin-without-hadoop/ ./spark
賦予許可權,其中hadoop為使用者名稱
sudo chown –R hadoop ./spark
2、修改組態檔
1.修改bashrc
在節點主機終端執行如下命令:
vim ~/.bashrc
在.bashrc中新增如下設定
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export JAVA_HOME=/opt/moudle/jdk1.8.0_192
export JRE_HOME=${JAVA_HOME}/jre
儲存並退出後執行source命令,使修改生效
source ~/.bashrc
2.修改slaves組態檔
cd /usr/local/spark/
cp ./conf/slaves.template ./conf/slaves
把預設內容localhost換成以下內容
hadoop01
hadoop02
以上分別為兩個從節點的主機名
3.設定spark-env.sh檔案
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
編輯spark-env.sh,新增以下內容
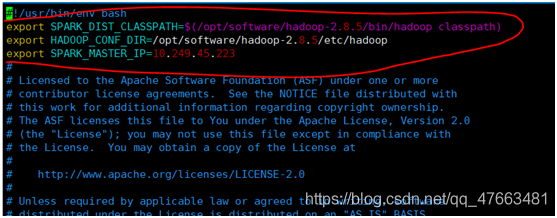
export SPARK_DIST_CLASSPATH=$(/opt/software/hadoop-2.8.5/bin/hadoop classpath)
括號內為hadoop路徑
export HADOOP_CONF_DIR=/opt/software/hadoop-2.8.5/etc/hadoop
export SPARK_MASTER_IP=10.249.45.223
等號後為主節點IP
4.傳送資料夾到從節點
在主節點上執行如下命令:
cd /usr/local
tar –zcf ~/spark.master.tar.gz ./spark
cd ~
scp ./spark.master.tar.gz hadoop02:/home/usr/local
scp ./spark.master.tar.gz hadoop03:/home/usr/local
以下操作分別在兩個從節點上執行:
sudo rm –rf /usr/local/spark/
sudo tar-zxf ~/spark.master.tar.gz –C /usr/local
sudo chown –R hadoop /usr/local/spark
3、啟動spark叢集
- 首先啟動hadoop叢集
- 啟動master節點
在Master節點上執行如下命令
cd /usr/local/spark/
sbin/start-master.sh
- 啟動從節點
在Master節點上執行如下命令
cd /usr/local/spark/
sbin/start-slaves.sh
-
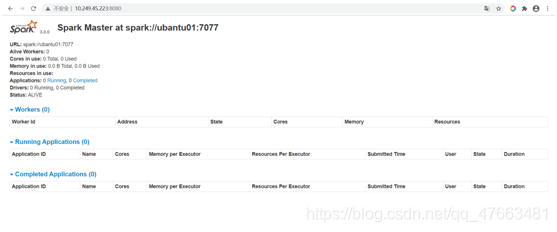
檢視spark啟動後的叢集資訊
在Master主機上開啟瀏覽器,存取http://master:8080 -
節點的關閉
sbin/stop-master.sh
sbin/stop-slaves.sh
再關閉hadoop叢集
Spark的webui介面:
4、提供一個測試程式碼
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("yarn").setAppName("My App")
sc = SparkContext(conf = conf)
logFile = "hdfs://hadoop01:9000/a1/a1"
logData = sc.textFile(logFile,2).cache()
numAs = logData.filter(lambda line:'a' in line).count()
print('Lines with a:%s'%(numAs))
四、hdfs、spark、spark搭建過程的改進與整合(By 儺儺)
1、改進思路:
1、將等的安裝都寫入dockerfile內,再根據dockerfile構建一個包含hdfs、yarn、spark、java,但沒有組態檔的映象。
2、將寫好的組態檔存在宿主機內,然後在根據映象建立容器時,通過docker run的-v命令將宿主機內的組態檔掛載到容器內,這樣就免去了每次建立容器時都要重新組態檔的麻煩。
3、將容器內的一些重要檔案如後設資料、datanode儲存的檔案等也通過docker run的-v命令對映到宿主機內,防止容器丟失或刪除時裡面這些檔案也隨之丟失。
2、編寫含hdfs、yarn、spark、java在內的dockerfile:FROM centos:centos7
FROM centos:centos7
MAINTAINER 「jbh1283432219@qq.com」
RUN yum -y install openssh-server openssh-clients sudo vim net-tools \
&& ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key \
&& ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key \
&& ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key \
RUN echo 「root:root」 | chpasswd
RUN mkdir /opt/software && mkdir /opt/moudle
ADD jdk-8u192-linux-x64.tar.gz /opt/moudle
ADD hadoop-2.8.5.tar.gz /opt/software
ADD spark-3.0.0-bin-without-hadoop.tgz /opt/software
ENV HADOOP_HOME /opt/software/hadoop-2.8.5
SPARK_HOME/opt/software/spark-3.0.0-bin-without-hadoop
JAVA_HOME /opt/moudle/jdk1.8.0_192
JRE_HOME ${JAVA_HOME}/jre
CLASSPATH J A V A H O M E / l i b : {JAVA_HOME}/lib: JAVAHOME/lib:{JRE_HOME}/lib
PATH J A V A H O M E / b i n : {JAVA_HOME}/bin: JAVAHOME/bin:{HADOOP_HOME}/bin: H A D O O P H O M E / s b i n : {HADOOP_HOME}/sbin: HADOOPHOME/sbin:{SPARK_HOME}/bin: S P A R K H O M E / s b i n : {SPARK_HOME}/sbin: SPARKHOME/sbin:PATH
WORKDIR /root
EXPOSE 22
CMD ["/usr/sbin/sshd", 「-D」]
3、根據dockerfile建立映象
建立映象前要確認hadoop、spark、java的安裝包與dockerfile在同一目錄下
hadoop、spark、java的安裝命令:
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
wget http://archive.apache.org/dist/spark/spark-3.0.0/spark-3.0.0-bin-without-hadoop.tgz
wget https://repo.huaweicloud.com/java/jdk/8u192-b12/jdk-8u192-linux-x64.tar.gz
建立映象(這裡網路模式使用的是host,與宿主機共用ip):
docker build --network=host -f dockerfile -t hadooop-spark:2.8.5
.
4、建立容器
1.
存放在宿主機的組態檔有如下幾個
 其中
其中
bashrc檔案設定:
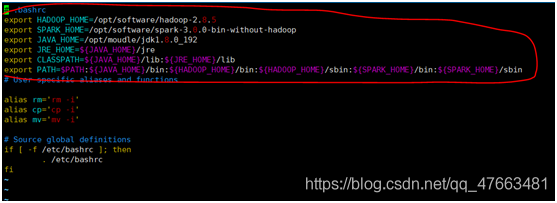
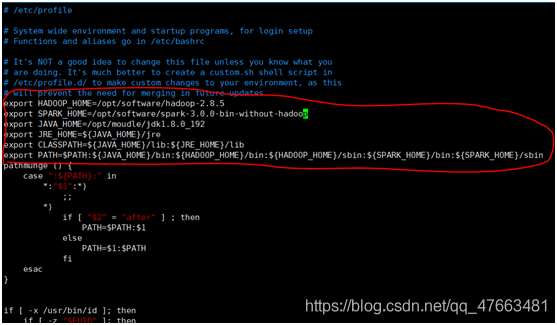
Profile檔案設定:
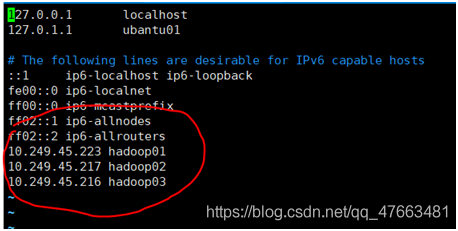
hosts檔案設定:
 hadoop資料夾內的組態檔與上面設定hdfs時的
hadoop資料夾內的組態檔與上面設定hdfs時的
/opt/software/hadoop-2.8.5/etc/hadoop/
目錄下的組態檔一致
spark資料夾(相對於上面設定spark時的設定有改動,主要是改變了spark的路徑):
Spark-env.sh檔案:
slaves檔案:

dfs、checkpoint、tmp這三個資料夾不是組態檔,是對映到宿主機、存放容器內重要資料的檔案。
dfs資料夾內有namenode_data和datanode_data兩個資料夾,分別存放主節點後設資料和從節點儲存的檔案塊。
checkpoint存放有與checkpoint相關的資料檔案。
tmp存放有臨時資料檔案。
2.
根據映象建立容器,並用-v命令把存在宿主機裡的組態檔掛載到容器內:
docker run -d --name hadoop1 --net host -P --privileged -v
/root/configurationfile/hadoop:/opt/software/hadoop-2.8.5/etc/hadoop
-v /root/configurationfile/hosts:/etc/hosts -v /root/configurationfile/dfs:/opt/software/hadoop-2.8.5/dfs -v
/root/configurationfile/tmp:/opt/software/hadoop-2.8.5/tmp -v
/root/configurationfile/checkpoint/dfs/cname:/opt/software/hadoop-2.8.5/checkpoint/dfs/cname
-v /root/configurationfile/spark/conf:/opt/software/spark-3.0.0-bin-without-hadoop/conf
-v /root/configurationfile/profile:/etc/profile -v /root/configurationfile/bashrc:/root/.bashrc a7621d9796e1
/usr/sbin/init
進入容器後設定ssh後便可使用
五、可能遇到的問題及解決方法(By 儺儺、Ninght)
一、執行Dockerfile構建映象過程中RUN yum出錯
解決方法:
1.可能是網路問題,檢查網路是否正常
2.若宿主機網路沒問題,可以嘗試在docker build命令時新增–net=host
3.可能是防火牆未關閉,關閉防火牆
二、ssh連線失敗
解決方法:
檢視hosts檔案有沒有設定好主機名和ip的對映,有時候重新啟動容器後hosts檔案會自動復原
三、成功拉起hdfs、yarn、spark等服務後卻無法開啟web ui介面
解決方法:
可能是防火牆未關閉,嘗試關閉防火牆
四、用start-dfs.sh啟動hdfs的時候沒有報錯,但檢視從節點的jps卻沒有datanode
在執行檔案系統格式化時,會在namenode資料資料夾(即組態檔中dfs.name.dir在本地系統的路徑)中儲存一個current/VERSION檔案,記錄namespaceID,標識了所格式化的 namenode的版本。如果頻繁的格式化namenode,那麼datanode中儲存(即組態檔中dfs.data.dir在本地系統的路徑)的current/VERSION檔案只是儲存著第一次格式化時的namenode ID,因此造成datanode與namenode之間的id不一致,導致datanode無法啟動
解決方法是刪除current資料夾,然後重新hdfs namenode -format進行初始化。
五、啟動yarn時只能拉起nodemanager而不能拉起resourcemanager
解決方法:
通過修改容器中
/opt/software/hadoop-2.8.5/sbin
路徑下的指令碼可以解決
vim yarn-daemon.sh
找到下面的語句
nohup nice -n Y A R N N I C E N E S S " YARN_NICENESS " YARNNICENESS"HADOOP_YARN_HOME"/bin/yarn --config $YARN_CONF_DIR c o m m a n d " command " command"@" > 「$log」 2>&1 < /dev/null &
將語句前的
nohup
刪去即可
這時再次啟動yarn可以發現能夠正常拉起resourcemanager程序