巨量資料之Kafka(二)
巨量資料之Kafka(二)
上一節主要介紹了Kafka的概述和基礎的命令列操作,今天來給大家深入瞭解一下!!
3. Kafka架構深入
3.1 Kafka 工作流程及檔案儲存機制
老規矩,我們先來看一下圖中的Kafka的工作流程,簡單的來了解一下…
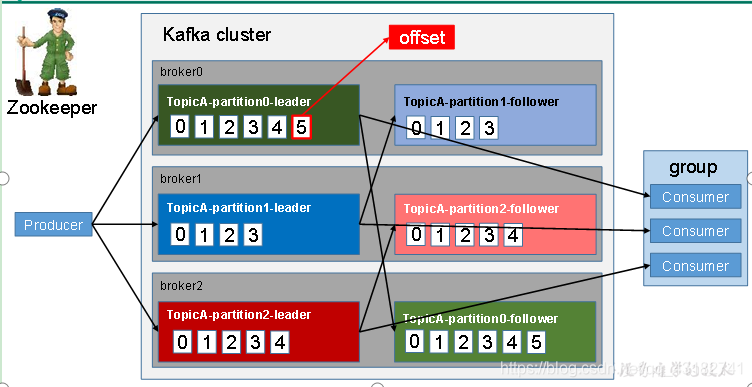
ok,我來給大家闡述一下上圖:
總的來說,大家記住一點,kafka中每個broker可以有多個partition,消費者組中的每個消費者可以消費多個partiton,而一個partition只能由一個消費者消費。
Kafka中訊息是以topic進行分類的,生產者生產訊息,消費者消費訊息,都是面向topic的。
topic是邏輯上的概念,而partiton是物理上的概念,每個partiton對應於一個log檔案,該log檔案中儲存的就是produce生產的資料。Produce生產的資料會被不斷追加到該log檔案末端,且每條資料都有自己的offset。消費者組中的每個消費者,都會實時記錄自己消費到了那個offset,以便出錯恢復時,從上次的位置繼續消費。
我們再來看一下Kafka的檔案儲存機制
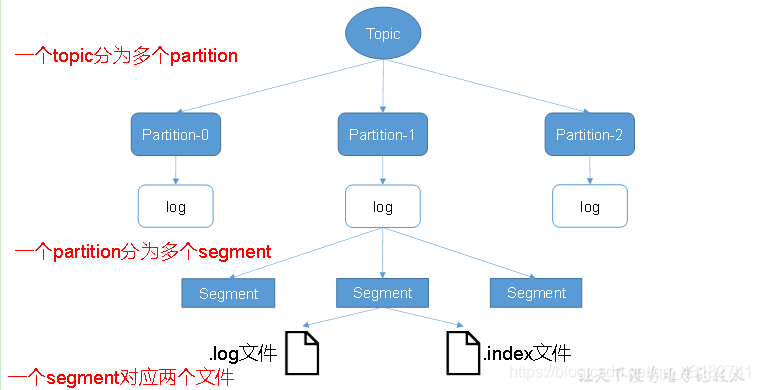
由於生產者生產的訊息會不斷追加到log檔案末尾,為防止log檔案過大導致資料定位效率低下,Kafka採取分片和索引機制,將每個partition分為多個segment。每個segment對應兩個檔案——「.index」檔案和「.log」檔案。這些檔案位於一個資料夾下,該資料夾的命名規則為:topic名稱+分割區序號。例如,first這個topic有三個分割區,則其對應的資料夾為first-0,first-1,first-2。
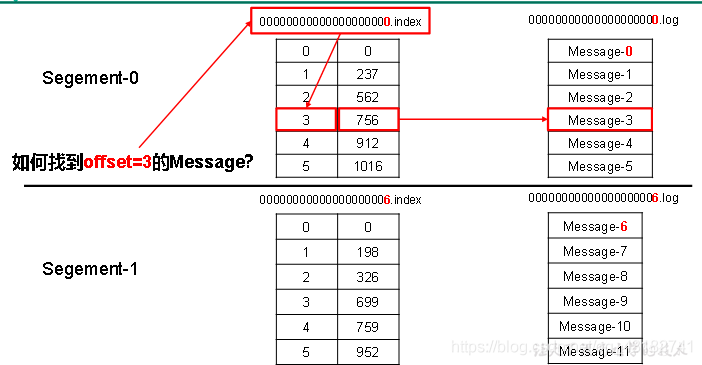
index和log檔案以當前segment的第一條訊息的offset命名。下圖為index檔案和log檔案的結構示意圖。
".index"檔案儲存大量的索引資訊,「.log」檔案儲存大量的資料,索引檔案中的後設資料指向對應資料檔案中,message的物理偏移地址。

3.2 Kafak生產者
3.2.1 分割區策略
1)分割區的原因
(1)方便在叢集中擴充套件,每個Partition可以通過調整以適應它所在的機器,而一個topic又可以有多個Partition組成,因此整個叢集就可以適應任意大小的資料了;
(2)可以提高並行,因為可以以Partition為單位讀寫了。
2)分割區的原則
我們需要將producer傳送的資料封裝成一個ProducerRecord物件。
分割區的原則分為三種情況:
(1) 指明 partition 的情況下,直接將指明的值直接作為 partiton 值;
(2) 沒有指明 partition 值但有** key** 的情況下,將 key 的 hash 值與 topic 的 partition 數進行取餘得到 partition 值;
(3) 既沒有 partition 值又沒有 key 值的情況下, kafka採用Sticky Partition(黏性分割區器),會隨機選擇一個分割區,並儘可能一直使用該分割區,待該分割區的batch已滿或者已完成,kafka再隨機一個分割區進行使用.

3.2.2 資料可靠性保證
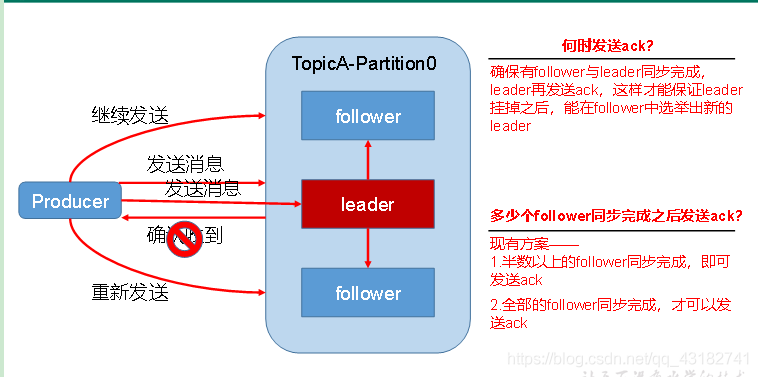
1)生產者傳送資料到topic partition的可靠性保證
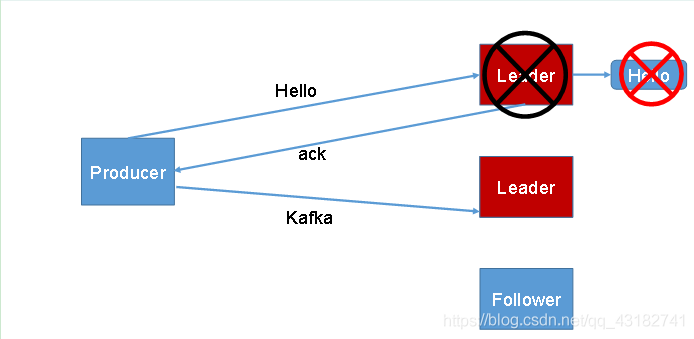
為保證produce傳送的資料,能可靠的傳送到指定的topic,topic的每個partiton收到producer傳送的資料後,都需要向producer傳送ack(acknowledgement 確認收到),如果producer收到ack,就會進行下一輪的傳送,否則重新傳送資料。
我們來看一下下圖,並思考其問題!!
2)Topic partition儲存資料的可靠性保證
(1)副本資料同步策略
| 方案 | 優點 | 缺點 |
|---|---|---|
| 半數以上完成同步,就傳送ack | 延遲低 | 選舉新的leader時,容忍n臺節點的故障,需要2n+1個副本 |
| 全部 完成同步,才傳送ack | 選舉新的leader時 ,容忍n臺節點的故障,需要n+1個副本 | 延遲高 |
Kafka選擇的是第二種方案,原因如下:
- 同樣為了容忍n臺節點的故障,第一種方案需要2n+1個副本,而第二種方案只需要n+1個副本,而Kafka的每個分割區都有大量的資料,第一種方案會造成大量資料的冗餘。
- 雖然第二種方案的網路延遲會比較高,但網路延遲對Kafka的影響較小。
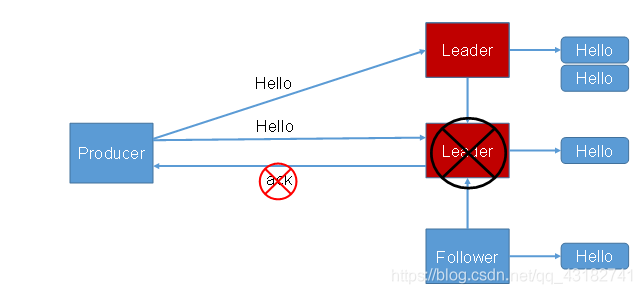
(2)ISR
採用第二種方案之後,設想以下情景:leader收到資料,所有follower都開始同步資料,但有一個follower,因為某種故障,遲遲不能與leader進行同步,那leader就要一直等下去,直到它完成同步,才能傳送ack。這個問題怎麼解決呢?
Leadre維護了一個動態的in-sync replica set(ISR),意為和leader保持同步的follower集合。當ISR中的follower完成資料的同步之後,leader就會給producer傳送給ack。如果follower長時間未向leader同步資料,則該follower將別踢出ISR,該時間闕值由replica.lang.time.ms引數設定。Leader發生故障後,就會從ISR中選舉新的leader。
(3)ack應答級別
對於某些不太重要的資料,對資料的可靠性要求不是很高,能夠容忍資料的少量丟失,所以沒必要等ISR中的follower全部接收成功。
所以Kafka為使用者提供了三種可靠性級別,使用者根據對可靠性和延遲的要求進行權衡,選擇以下的設定。
acks引數設定:
acks:
0:這一操作提供了一個最低的延遲,partiton的leader接收到訊息後還沒有寫入磁碟就已經返回ack,當leader故障時有可能丟失資料**;
1:partition的leader落盤成功後返回ack,如果在follower同步之前leader故障,那麼將會丟失資料;
-1(all):partition的leader和follower全部落盤成功後才返回ack。但是如果在follower同步完成後,broker傳送ack之前,leader發生故障,那麼將會造成資料重複。
3)leader和follower故障處理細節
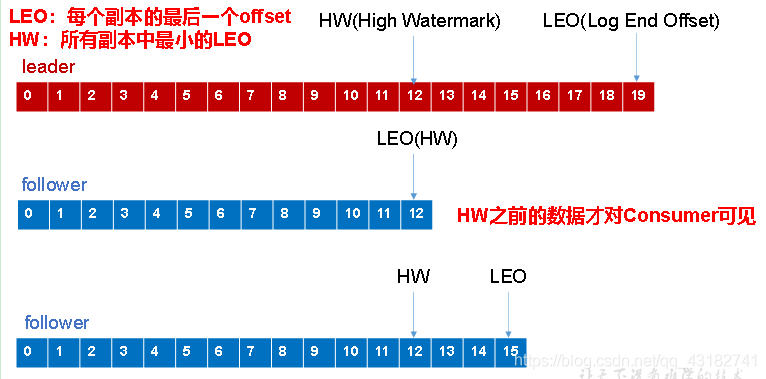
LEO:指的是每個副本最大的offset;
HW:指的是消費者能見到的最大的offset,ISR佇列中最小的LEO。
(1)follower故障
follower發生故障後會被臨時踢出ISR,待該follower恢復後,followerhi讀取本地磁碟記錄的上次的HW,並將log檔案高於HW的部分擷取掉,從HW開始向leader進行同步。等該follower的LEO大於等於該partition的HW,即follower追上leader之後,就可以重新加入ISR了。
(2)leader故障
leader發生故障之後,會從ISR中選出一個新的leader,之後,為保證多個副本之間的資料一致性,其餘的follower會先將各自的log檔案高於HW的部分擷取掉,然後從新的leader同步資料。
注意:這隻能保證副本之間的資料一致性 ,並不能保證資料不丟失或者不重複。
3.2.3 Exactly Once語意
將伺服器的ACK級別設定為-1,可以保證Producer到Server之間不會丟失資料,即At Least Once語意。相對的,將伺服器ACK級別設定為0,可以保證生產者每條訊息只會被傳送一次,即At Most Once語意。
At Least Once可以保證資料不丟失,但是不能保證資料不重複;相對的,At Most Once可以保證資料不重複,但是不能保證資料不丟失。但是,對於一些非常重要的資訊,比如說交易資料,下游資料消費者要求資料既不重複也不丟失,即Exactly Once語意。在0.11版本以前的Kafka,對此是無能為力的,只能保證資料不丟失,再在下游消費者對資料做全域性去重。對於多個下游應用的情況,每個都需要單獨做全域性去重,這就對效能造成了很大影響。
0.11版本的Kafka,引入了一項重大特性:冪等性。**所謂的冪等性就是指Producer不論向Server傳送多少次重複資料,Server端都只會持久化一條。**冪等性結合At Least Once語意,就構成了Kafka的Exactly Once語意。即:At Least Once + 冪等性 = Exactly Once
要啟用冪等性,只需要將Producer的引數中enable.idempotence設定為true即可。Kafka的冪等性實現其實就是將原來下游需要做的去重放在了資料上游。開啟冪等性的Producer在初始化的時候會被分配一個PID,發往同一Partition的訊息會附帶Sequence Number。而Broker端會對<PID, Partition, SeqNumber>做快取,當具有相同主鍵的訊息提交時,Broker只會持久化一條。
但是PID重新啟動就會變化,同時不同的Partition也具有不同主鍵,所以冪等性無法保證跨分割區跨對談的Exactly Once。
3.3 Kafka消費者
3.3.1 消費方式
consumer採用pull(拉)模式從broker中讀取資料。
**push(推)模式很難適應消費速率不同的消費者,因為訊息傳送速率是由broker決定的。**它的目標是儘可能以最快速度傳遞訊息,但是這樣很容易造成consumer來不及處理訊息,典型的表現就是拒絕服務以及網路擁塞。而pull模式則可以根據consumer的消費能力以適當的速率消費資訊。
pull模式不足之處是,如果kafka沒有資料,消費者可能會陷入迴圈中,一直返回空資料。針對這一點,Kafka的消費者在消費資料時會傳入一個時長引數timeout,如果當前沒有資料可供消費,consumer會等待一段時間之後再返回,這段時長即為timeout。
3.3.2 分割區分配策略
一個consumer group中有多個consumer。一個topic有多個partition,所以必然會涉及到partition的分配問題,即確定那個partition由那個consumer來消費。
Kafka有三種分配策略,RoundRobin,Range,Sticky。
1)RoundRobin(輪循)
其結果如下0、1、2按照順序直接分配到三個消費者,3、4、5同上,最後剩下一個6被消費者0消費,如下圖所示:
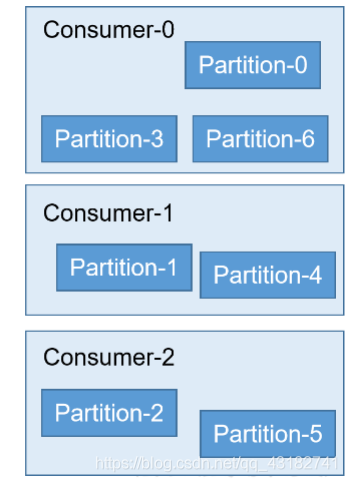
2)Range
0、1、2三個分割區直接被消費者0消費,3、4分割區被消費者1直接消費,5、6分割區被消費者2消費。如下圖所示:



3.3.3 offset的維護
由於consumer在消費過程中可能會出現斷電宕機等故障,consumer恢復後,需要從故障前的位置繼續消費,所以consumer需要實時記錄自己消費到了那個offset,以便故障恢復後繼續消費。
Kafka 0.9 版本之前,consumer預設將offset儲存在Zookeeper中,從0.9 版本之後,consumer預設將offset儲存Kafka一個內建的topic中,該topic為_consumer_offsets。
1)消費offset案例
(0)思想: __consumer_offsets 為kafka中的topic, 那就可以通過消費者進行消費.
(1)修改組態檔consumer.properties不排除內部的topic
exclude.internal.topics=false
(2)建立一個topicbin/kafka-topics.sh --create --topic atguigu --zookeeper hadoop102:2181 --partitions 2 --replication-factor 2(3)啟動生產者和消費者,分別往atguigu生產資料和消費資料
bin/kafka-console-producer.sh --topic atguigu --broker-list hadoop102:9092 bin/kafka-console-consumer.sh --consumer.config config/consumer.properties --topic atguigu --bootstrap-server hadoop102:9092(4)消費offset
bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server hadoop102:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning(5)消費到的資料
[test-consumer-group,atguigu,1]::OffsetAndMetadata(offset=2, leaderEpoch=Optional[0], metadata=, commitTimestamp=1591935656078, expireTimestamp=None) [test-consumer-group,atguigu,0]::OffsetAndMetadata(offset=1, leaderEpoch=Optional[0], metadata=, commitTimestamp=1591935656078, expireTimestamp=None)
3.3.4 消費者組案例
1)需求:測試同一個消費者組中的消費者,同一時刻只能有一個消費者消費。
2)案例實操
(1)在hadoop102、hadoop103上修改/opt/module/kafka/config/consumer.properties組態檔中的group.id屬性為任意組名。[atguigu@hadoop103 config]$ vi consumer.properties group.id=mygroup(2)在hadoop104上啟動生產者
[atguigu@hadoop104 kafka]$ bin/kafka-console-producer.sh \ --broker-list hadoop102:9092 --topic first(3)在hadoop102、hadoop103上分別啟動消費者
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \ bootstrap-server hadoop102:9092 --topic first --consumer.config config/consumer.properties [atguigu@hadoop103 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first --consumer.config config/consumer.properties(4)檢視hadoop102和hadoop103的消費者的消費情況。
3.4 Kafka 高效讀寫資料
1)順序寫磁碟
Kafka的producer生產資料,要寫入到log檔案中,寫的過程是一直追加到檔案末端,為順序寫。官網有資料表明,同樣的磁碟,順序寫能到600M/s,而隨機寫只有100K/s。這與磁碟的機械機構有關,順序寫之所以快,是因為其省去了大量磁頭定址的時間。
2)應用
Kafka資料持久化是直接持久化到Pagecache中,這樣會產生以下幾個好處:
①I/O Scheduler 會將連續的小塊寫組裝成大塊的物理寫從而提高效能
②I/O Scheduler 會嘗試將一些寫操作重新按順序排好,從而減少磁碟頭的移動時間
③充分利用所有空閒記憶體(非 JVM 記憶體)。如果使用應用層 Cache(即 JVM 堆記憶體),會增加 GC 負擔
④讀操作可直接在 Page Cache 內進行。如果消費和生產速度相當,甚至不需要通過物理磁碟(直接通過 Page Cache)交換資料
⑤如果程序重新啟動,JVM 內的 Cache 會失效,但 Page Cache 仍然可用
儘管持久化到Pagecache上可能會造成宕機丟失資料的情況,但這可以被Kafka的Replication機制解決。如果為了保證這種情況下資料不丟失而強制將 Page Cache 中的資料 Flush 到磁碟,反而會降低效能。
3)零複製技術
正常情況下
kafka中:(實現零拷貝)
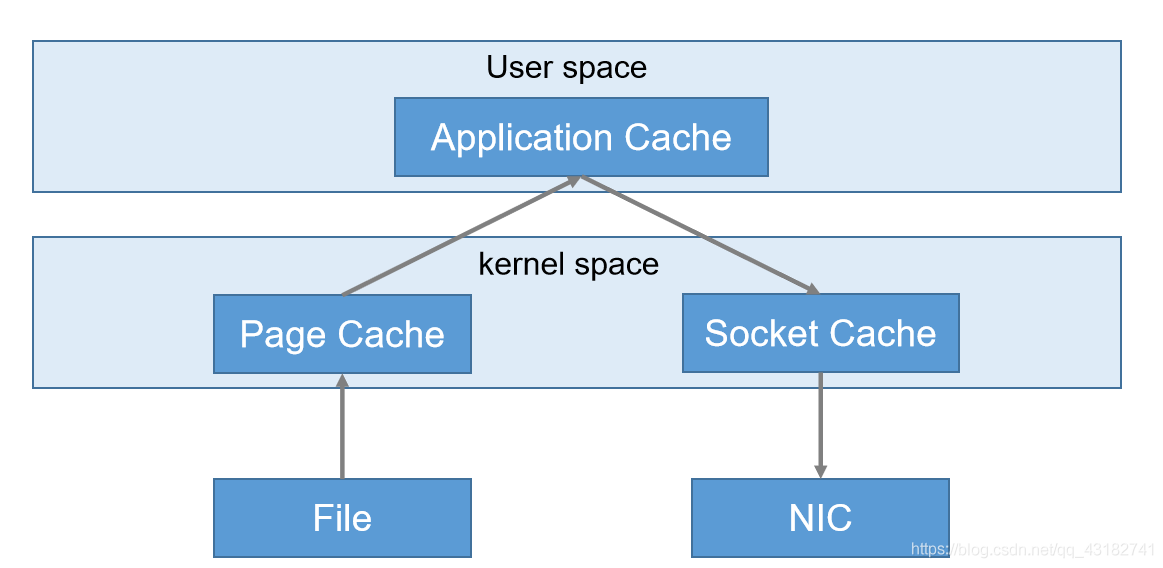
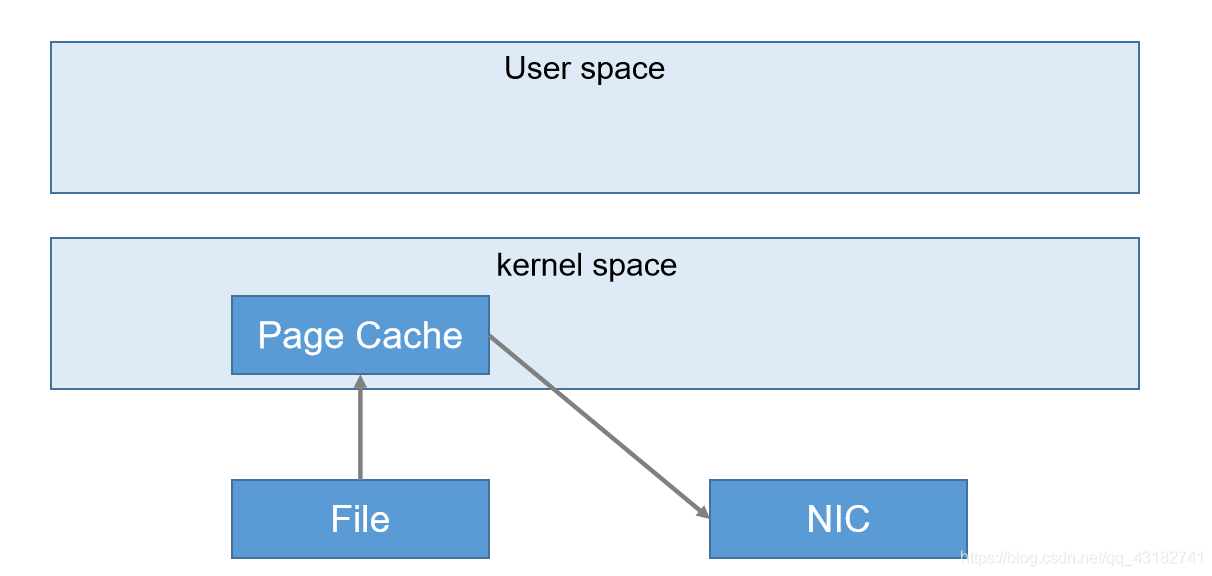
3.5 Zookeeper在Kafka中的作用
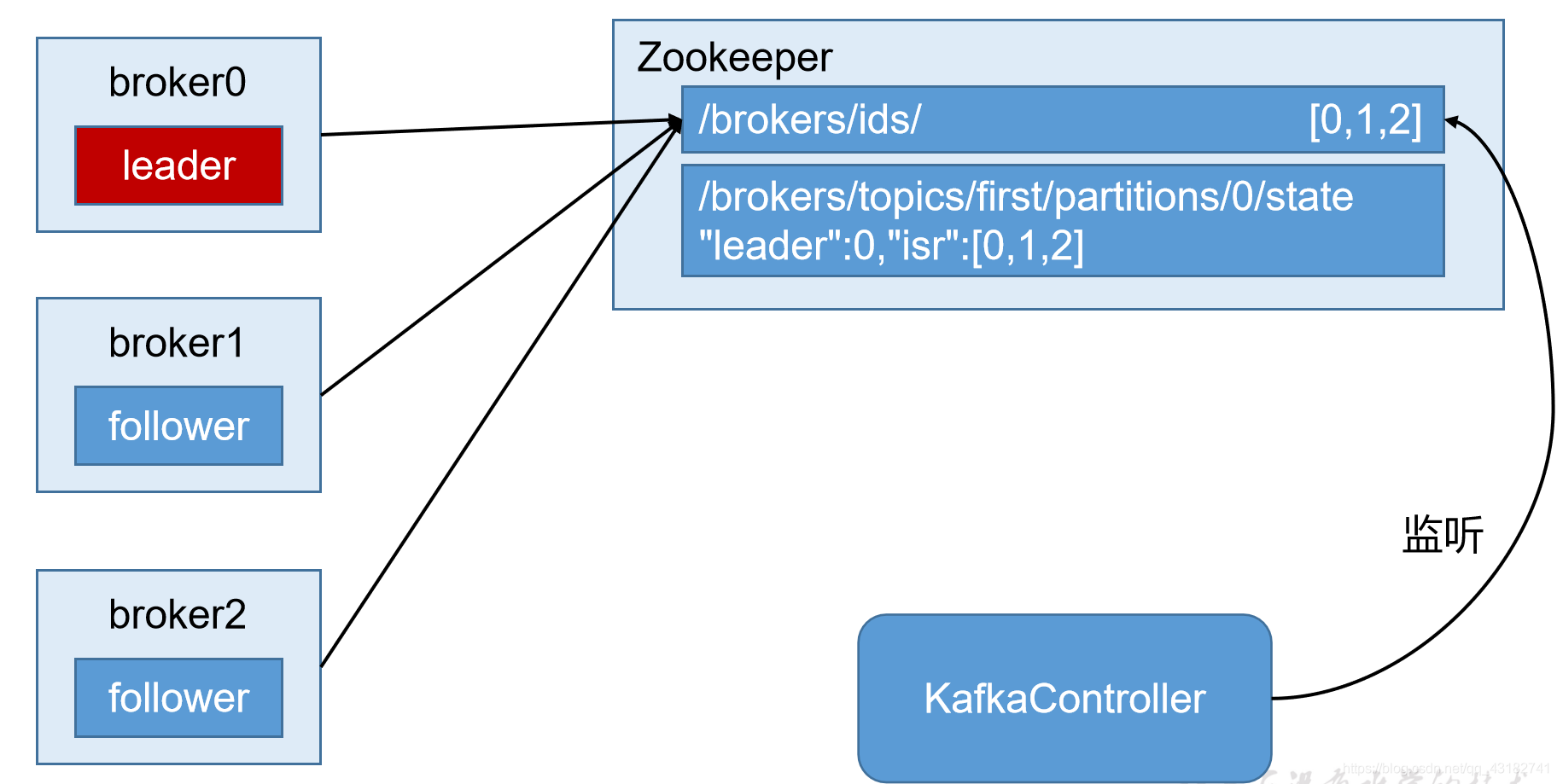
Kafka叢集中有一個broker會被選舉為Controller,負責管理叢集broker的上下線,所有topic的分割區副本分配和leader選舉等工作。
Controller的管理工作都是依賴於Zookeeper的。
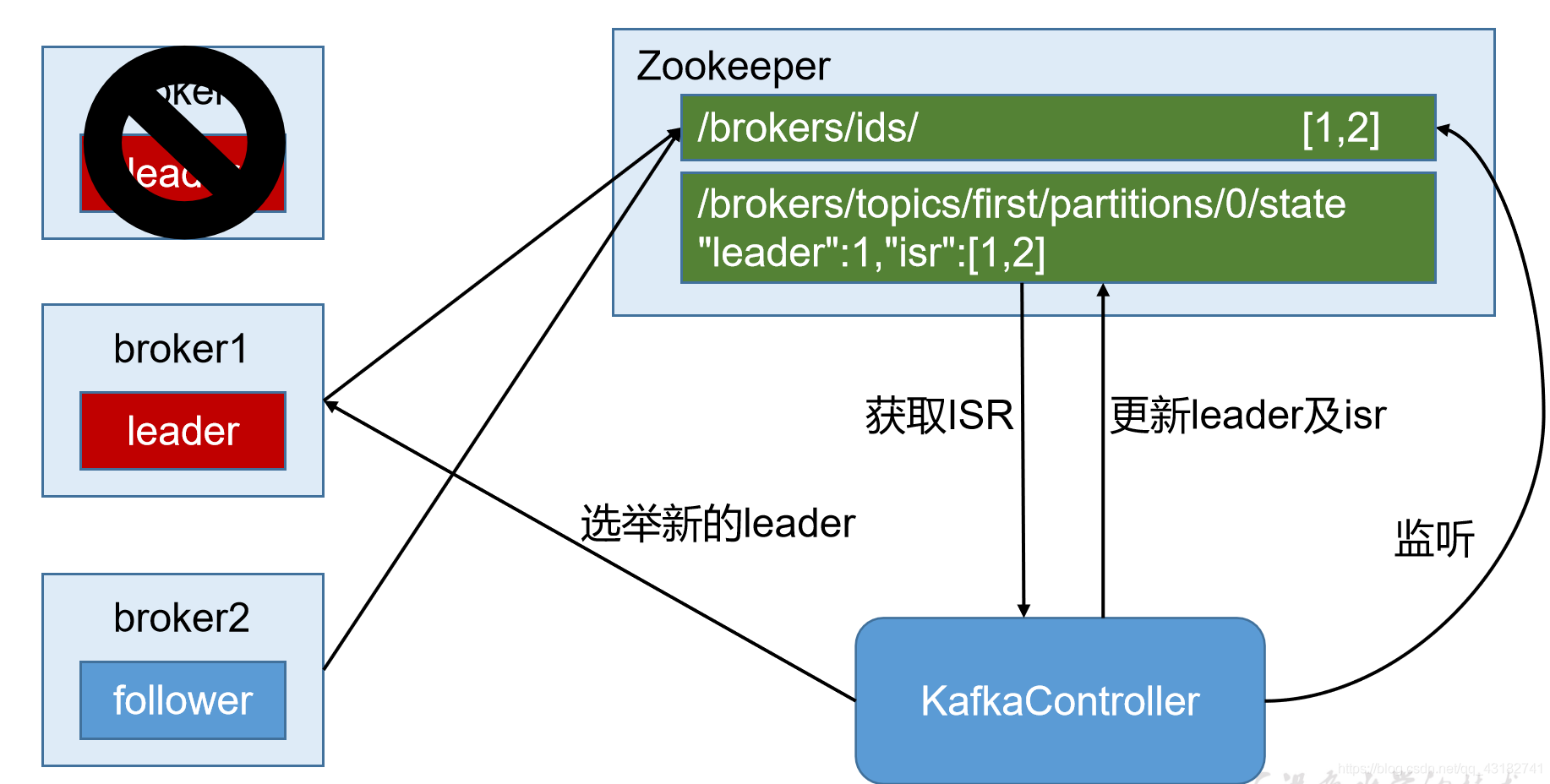
以下為partition的leader選舉過程:
第一步:
第二步:
3.6 Kafka事務
Kafka從0.11版本開始引入了事務支援。事務可以保證Kafka在Exactly Once語意的基礎上,生產和消費可以跨分割區和對談,要麼`全部成功,要麼全部失敗。
3.6.1 Producer 事務
為了實現跨分割區跨對談的事務,需要引入一個全域性唯一的Transation ID,並將Producer獲得PID和Transaction ID繫結。這樣當Producer重新啟動後就可以通過正在進行的Transation ID獲得原來的PID。
為了管理Transaction,Kafka引入了一個新的元件Transaction Coordinator。Producer就是通過和Transaction Coordinator互動獲得Transaction ID對應的任務狀態。Transaction Coordinator還負責將事務所有寫入Kafka的一個內部Topic,這樣即使整個服務重新啟動,由於事務狀態得到儲存,進行中的事務狀態可以得到恢復,從而繼續進行。
3.6.2 Consumer事務(精準一次性消費)
上述事務機制主要是從Producer方面考慮,對於Consumer而言,事務的保證就會相對較弱,尤其時無法保證Commit的資訊被精確消費。這是由於Consumer可以通過offset存取任意資訊,而且不同的Segment File生命週期不同,同一事務的訊息可能會出現重新啟動後被刪除的情況。
如果想完成Consumer端的精準一次性消費,那麼需要kafka消費端將消費過程和提交offset過程做原子繫結。此時我們需要將kafka的offset儲存到支援事務的自定義媒介(比如mysql)。這部分知識會在後續專案部分涉及。
4 . Kafka API
4.1 Producer API
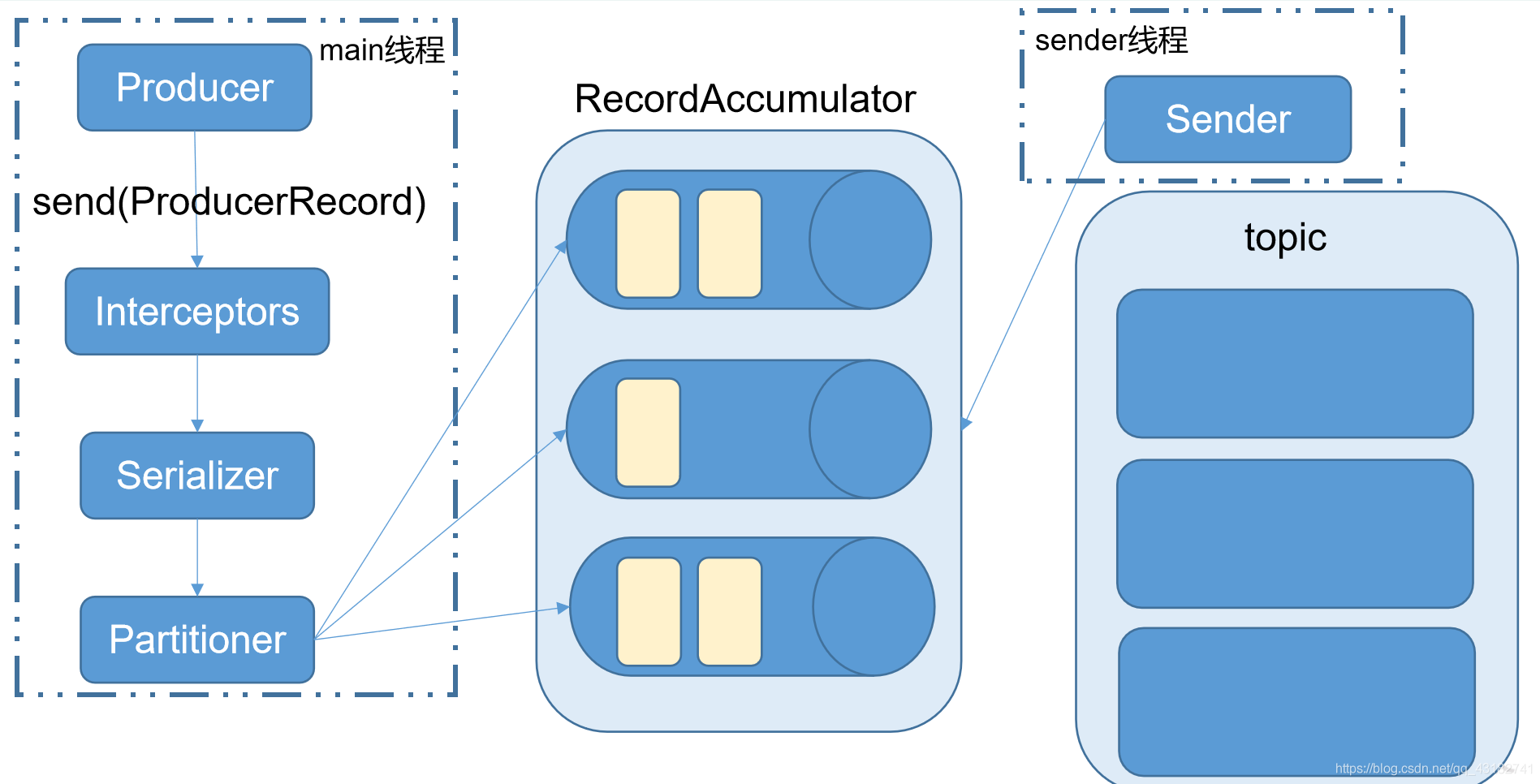
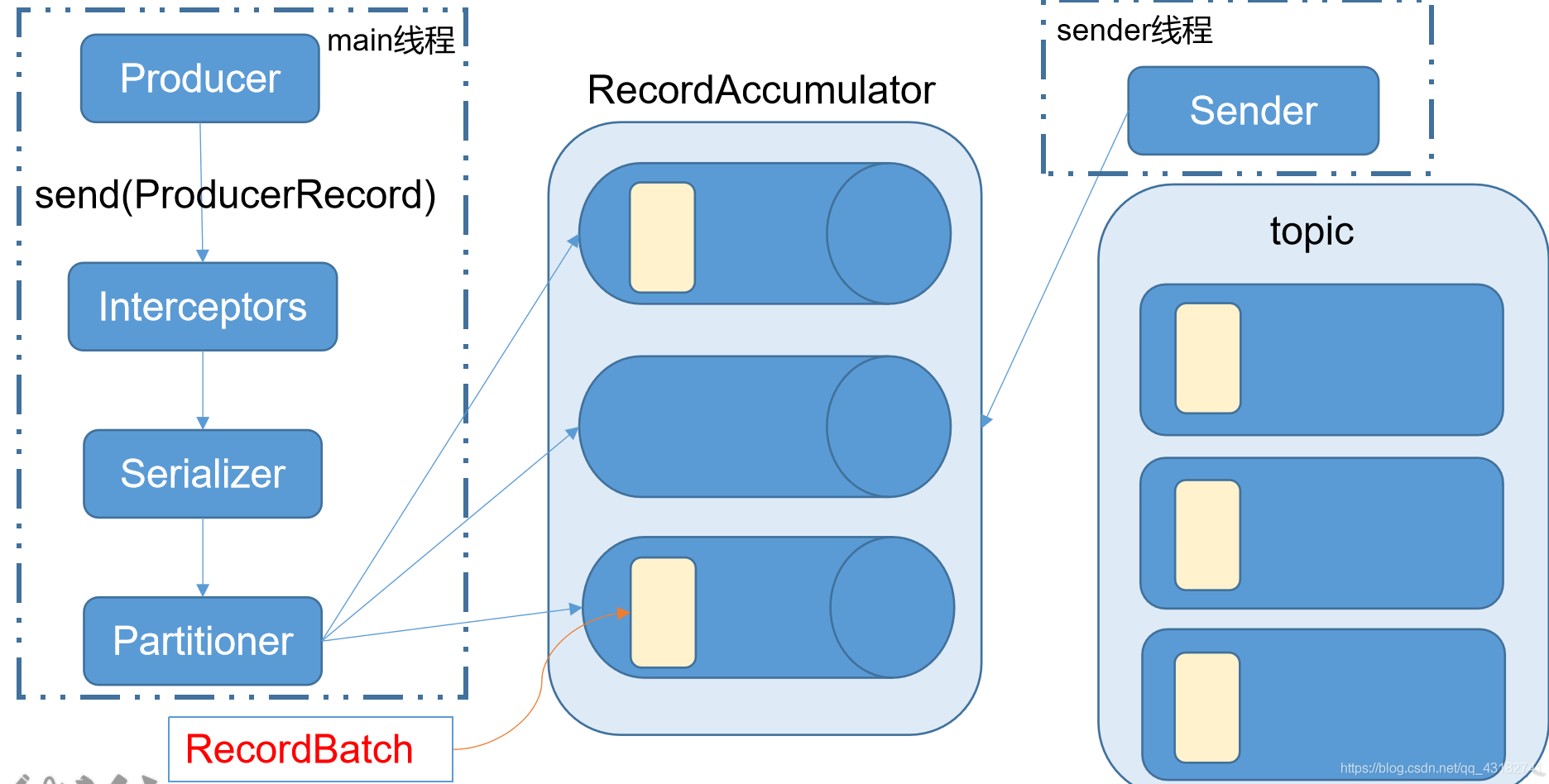
4.1.1 消費傳送流程
Kafka的Producer傳送訊息採用的是非同步傳送的方式。在訊息傳送的過程中,涉及到了兩個執行緒——main執行緒和Sender執行緒,以及一個執行緒共用變數——RecordAccumulator。main執行緒將訊息傳送給RecordAccumulator,Sender執行緒不斷從RecordAccumulator中拉取訊息傳送到Kafka broker。
生產者生產的資料不會直接到topic的分割區中,它會到batch中快取一下,爭取大批次的傳輸資料
相關引數:
batch.size:只有資料積累到batch.size之後,sender才會傳送資料。
linger.ms:如果資料遲遲未達到batch.size,sender等待linger.time之後就會傳送資料。
4.1.2 非同步傳送API
1)匯入依賴
<dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.4.1</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-slf4j-impl</artifactId> <version>2.12.0</version> </dependency> </dependencies>2)新增log4j2組態檔
<?xml version="1.0" encoding="UTF-8"?> <Configuration status="error" strict="true" name="XMLConfig"> <Appenders> <!-- 型別名為Console,名稱為必須屬性 --> <Appender type="Console" name="STDOUT"> <!-- 佈局為PatternLayout的方式, 輸出樣式為[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here --> <Layout type="PatternLayout" pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" /> </Appender> </Appenders> <Loggers> <!-- 可加性為false --> <Logger name="test" level="info" additivity="false"> <AppenderRef ref="STDOUT" /> </Logger> <!-- root loggerConfig設定 --> <Root level="info"> <AppenderRef ref="STDOUT" /> </Root> </Loggers> </Configuration>編寫程式碼
(1)無回撥無指定分割區以及keypublic class ProducerDemo { public static void main(String[] args) { //獲取設定引數 Properties properties = new Properties(); //kafka叢集 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"); properties.put(ProducerConfig.ACKS_CONFIG,"-1"); //重試次數 properties.put(ProducerConfig.RETRIES_CONFIG,3); //批次大小 properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384); //等待時間 properties.put(ProducerConfig.LINGER_MS_CONFIG,1); //緩衝區大小 properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); //建立生產者物件 KafkaProducer<String, String> produce = new KafkaProducer<String, String>(properties); for (int i = 0; i < 10; i++) { //不帶回撥的方法 //不指定key,分割區使用預設分割區:粘性分割區 produce.send(new ProducerRecord<String, String>("atguigu","value-->" + i)); } //關閉 produce.close(); } }(2)採用回撥方法
public class ProducerDemo1 { public static void main(String[] args) { //獲取設定引數 Properties properties = new Properties(); //kafka叢集 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"); properties.put(ProducerConfig.ACKS_CONFIG,"-1"); //重試次數 properties.put(ProducerConfig.RETRIES_CONFIG,3); //批次大小 properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384); //等待時間 properties.put(ProducerConfig.LINGER_MS_CONFIG,1); //緩衝區大小 properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); //建立生產者物件 KafkaProducer<String, String> produce = new KafkaProducer<String, String>(properties); for (int i = 0; i < 10; i++) { //待回撥的方法 //不指定key,預設使用粘性分割區 produce.send(new ProducerRecord<String, String>("atguigu","value-->" + i), new Callback() { public void onCompletion(RecordMetadata recordMetadata, Exception e) { if(e != null){ //資訊傳送失敗 System.out.println(e.getMessage()); }else { //資訊傳送成功 System.out.println(recordMetadata.topic() + " : " + recordMetadata.partition() + " : " + recordMetadata.offset()); } } }); } //關閉 produce.close(); } }(3) 指定key或分割區
public class ProducerDemo2 { public static void main(String[] args) { //獲取設定引數 Properties properties = new Properties(); //kafka叢集 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"); properties.put(ProducerConfig.ACKS_CONFIG,"-1"); //重試次數 properties.put(ProducerConfig.RETRIES_CONFIG,3); //批次大小 properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384); //等待時間 properties.put(ProducerConfig.LINGER_MS_CONFIG,1); //緩衝區大小 properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); //建立生產者物件 KafkaProducer<String, String> produce = new KafkaProducer<String, String>(properties); for (int i = 0; i < 10; i++) { //不帶回撥的方法 //指定key,使用key對分割區數量取餘確定 //produce.send(new ProducerRecord<String, String>("atguigu","key-->" + i,"message" + i)); produce.send(new ProducerRecord<String, String>("atguigu",0,"key-->" + i,"value-->" + i)); } //關閉 produce.close(); } }(4) 非同步傳送與同步傳送
public class ProducerDemo3 { public static void main(String[] args) throws ExecutionException, InterruptedException { //獲取設定引數 Properties properties = new Properties(); //kafka叢集 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"); properties.put(ProducerConfig.ACKS_CONFIG,"-1"); //重試次數 properties.put(ProducerConfig.RETRIES_CONFIG,3); //批次大小 properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384); //等待時間 properties.put(ProducerConfig.LINGER_MS_CONFIG,1); //緩衝區大小 properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); //建立生產者物件 KafkaProducer<String, String> produce = new KafkaProducer<String, String>(properties); for (int i = 0; i < 10; i++) { //待回撥的方法 //不指定key,預設使用粘性分割區 //非同步傳送 // produce.send(new ProducerRecord<String, String>("atguigu","value-->" + i), // new Callback() { // public void onCompletion(RecordMetadata recordMetadata, Exception e) { // System.out.println("訊息傳送完成"); // if(e != null){ // //資訊傳送失敗 // System.out.println(e.getMessage()); // }else { // //資訊傳送成功 // System.out.println(recordMetadata.topic() + " : " + recordMetadata.partition() + " : " + recordMetadata.offset()); // } // } // }); // System.out.println("訊息傳送出去"); //同步傳送 produce.send(new ProducerRecord<String, String>("atguigu", "value-->" + i), new Callback() { public void onCompletion(RecordMetadata recordMetadata, Exception e) { System.out.println("訊息傳送完成...."); if(e != null){ //資訊傳送失敗 System.out.println(e.getMessage()); }else { //資訊傳送成功 System.out.println(recordMetadata.topic() + " : " + recordMetadata.partition() + " : " + recordMetadata.offset()); } } }).get(); System.out.println("訊息傳送出去....."); } //關閉 produce.close(); } }
4.1.3 分割區器
1)預設的分割區器 DefaultPartitioner
2)自定義分割區器public class Mypartitioner implements Partitioner { /** * 計算某條訊息要傳送到那個分割區 * @param topic 主題 * @param key 訊息的key * @param keyBytes 訊息key序列化後的位元組陣列 * @param value 訊息的value * @param valueBytes 訊息的value 序列化後的位元組陣列 * @param cluster * @return */ public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { if(value.toString().contains("joe")){ return 0; }else if(value.toString().contains("dog")){ return 1; }else { return 2; } } public void close() { } public void configure(Map<String, ?> map) { } }(3) 指定自定義的分割區器
public class ProducerDemo4 { public static void main(String[] args) { //獲取設定引數 Properties properties = new Properties(); //kafka叢集 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"); properties.put(ProducerConfig.ACKS_CONFIG,"-1"); //重試次數 properties.put(ProducerConfig.RETRIES_CONFIG,3); //批次大小 properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384); //等待時間 properties.put(ProducerConfig.LINGER_MS_CONFIG,1); //緩衝區大小 properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432); //指定分割區器 properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.atguigu.kafka.partitioner.Mypartitioner"); //序列化 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); //建立生產者物件 KafkaProducer<String, String> produce = new KafkaProducer<String, String>(properties); for (int i = 0; i < 10; i++) { if(i % 2 == 0){ produce.send(new ProducerRecord<String, String>("atguigu","joe" + i)); }else { produce.send(new ProducerRecord<String, String>("atguigu","dog" + i)); } } //關閉 produce.close(); } }
4.2 Consumer API
Consumer消費資料時的可靠性是很容易保證的,因為資料在Kafka中是持久化的,故不用擔心資料丟失問題。
由於consumer在消費過程中可能會出現斷電宕機等故障,consumer恢復後,需要從故障前的位置的繼續消費,所以consumer需要實時記錄自己消費到了哪個offset,以便故障恢復後繼續消費。
所以offset的維護是Consumer消費資料是必須考慮的問題。
4.2.1 自動提交offset
1)編寫程式碼
需要用到的類:
KafkaConsumer:需要建立一個消費者物件,用來消費資料
ConsumerConfig:獲取所需的一系列設定引數
ConsuemrRecord:每條資料都要封裝成一個ConsumerRecord物件
為了使我們能夠專注於自己的業務邏輯,Kafka提供了自動提交offset的功能。
自動提交offset的相關引數:
enable.auto.commit:是否開啟自動提交offset功能
auto.commit.interval.ms:自動提交offset的時間間隔
2)消費者自動提交offset且重置offsetpublic class ConsumerDemo { public static void main(String[] args) { //設定設定項 Properties prop = new Properties(); prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"); prop.put(ConsumerConfig.GROUP_ID_CONFIG,"atguigu-group"); //自動提交 prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true"); //自動提交的事件間隔 prop.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000"); //設定key prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); //設定value prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); //offset重置問題 /** * auto。offset.reset: * 滿足兩種情況會重置offset: * 1.當啟動的消費者之前沒有在kafka中有消費記錄(新的組新的人) * 2.當啟動的消費者要消費的offset在kafka中已經不存在(例如超時7天會被刪除) * * 重置到什麼位置: * earliest:目前kafka中topic的分割區中最小的offset * latest: 目前lafla中topic的分割區中最大的offset */ prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest"); //建立消費者物件 KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop); //訂閱主題 List<String> topics = new ArrayList<String>(); topics.add("atguigu"); topics.add("first"); //若不存在的主題,它會自動建立 //topics.add("second"); consumer.subscribe(topics); //消費資料 while(true){ ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1)); for (ConsumerRecord<String, String> record : records) { System.out.println("offset : " + record.offset() + "key : " + record.key() + "value" + record.value()); } } } }
4.2.2 手動提交offset
雖然自動提交offset十分簡潔便利,但由於其是基於時間提交的,開發人員難以把握offset提交的時機。因此Kafka還提供了手動提交offset的API。
手動提交offset的方法有兩種:分別是commitSync(同步提交)和commitAsync(非同步提交)。兩者的相同點是,都會將本次poll的一批資料最高的偏移量提交;不同點是,commitSync阻塞當前執行緒,一直到提交成功,並且會自動失敗重試(由不可控因素導致,也會出現提交失敗);而commitAsync則沒有失敗重試機制,故有可能提交失敗。
1)同步提交offset
由於同步提交有失敗重試機制,故更加可靠,以下為同步提交與非同步提交offset的範例。public class ConsumerDemo1 { public static void main(String[] args) { //設定設定項 Properties prop = new Properties(); prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"); prop.put(ConsumerConfig.GROUP_ID_CONFIG,"atguigu-group"); //手動提交 prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); //設定key prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); //設定value prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); //建立消費者物件 KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop); //訂閱主題 List<String> topics = new ArrayList<String>(); topics.add("atguigu"); topics.add("first"); //若不存在的主題,它會自動建立 //topics.add("second"); consumer.subscribe(topics); //消費資料 while(true){ ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1)); for (ConsumerRecord<String, String> record : records) { System.out.println("offset : " + record.offset() + "key : " + record.key() + "value" + record.value()); } //同步提交,當前執行緒會阻塞直到offset提交成功 //consumer.commitSync(); //非同步提交 consumer.commitAsync(new OffsetCommitCallback() { @Override public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) { if(exception != null){ System.out.println(exception.getMessage()); }else { System.out.println(offsets); } } }); } } }手動提交的話主要是在特殊業務中才會使用,我們一般使用自動提交就可以了。
3)資料漏消費和重複消費分析
無論是同步提交還是非同步提交offset,都有可能造成資料的漏消費或者重複消費。**先提交offset後消費,有可能造成漏消費;而先消費後提交offset,有可能會造成資料的重複消費。
4.3 自定義Interceptor
4.3.1 攔截器原理
Produce攔截器(interceptor)是在Kafka 0.10版本被引入的,主要用於實現clients端的客製化化控制化邏輯。
對於produce而言,interceptor使得使用者在訊息傳送前以及producer回撥邏輯前有機會對訊息做一些客製化化需求,比如修改訊息等。同時,producer允許使用者指定多個interceptor按序作用於同一條訊息而形成一個攔截鏈(interceptor)。interceptor的實現介面是org.apache.kafka.clients.producer.ProducerInterceptor,其定義方法包括:
(1)configure(configs)
獲取設定資訊和初始化資料時呼叫。
(2)onSend(ProducerRecord):
該方法封裝進KafkaProducer.send方法中,即它執行在使用者主執行緒中。Producer確保在訊息被序列化以及計算分割區前呼叫該方法。使用者可以在該方法中對訊息做任何操作,但最好保證不要修改訊息所屬的topic和分割區,否則會影響目標分割區的計算。
(3)onAcknowledgement(RecordMetadata, Exception):
該方法會在訊息從RecordAccumulator成功傳送到Kafka Broker之後,或者在傳送過程中失敗時呼叫。並且通常都是在producer回撥邏輯觸發之前。onAcknowledgement執行在producer的IO執行緒中,因此不要在該方法中放入很重的邏輯,否則會拖慢producer的訊息傳送效率。
(4)close:
關閉interceptor,主要用於執行一些資源清理工作
如前所述,interceptor可能被執行在多個執行緒中,因此在具體實現時使用者需要自行確保執行緒安全。另外倘若指定了多個interceptor,則producer將按照指定順序呼叫它們,並僅僅是捕獲每個interceptor可能丟擲的異常記錄到錯誤紀錄檔中而非在向上傳遞。這在使用過程中要特別留意。
4.3.2 攔截器案例
1)需求:
實現一個簡單的雙interceptor組成的攔截鏈。第一個interceptor會在訊息傳送前將時間戳資訊加到訊息value的最前部;第二個interceptor會在訊息傳送後更新成功傳送訊息數或失敗傳送訊息數。
2)案例實操
(1)增加時間戳攔截器public class TimeInterceptor implements ProducerInterceptor<String,String> { /** * 在訊息傳送前將時間戳資訊加到訊息value的最前部 * @param record * @return */ @Override public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) { //獲取訊息的value String value = record.value(); value = System.currentTimeMillis() + " >> " + value; //封裝新的訊息 ProducerRecord<String,String> newRecord = new ProducerRecord<String, String>(record.topic(),record.partition(),record.key(),value); return newRecord; } @Override public void onAcknowledgement(RecordMetadata metadata, Exception exception) { } @Override public void close() { } @Override public void configure(Map<String, ?> configs) { } }(2)統計傳送訊息成功和傳送失敗訊息數,並在producer關閉時列印這兩個計數器
public class CountInterceptor implements ProducerInterceptor<String,String> { private Integer success = 0; private Integer fail = 0; @Override public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) { return record; } /** * 在訊息傳送後更新成功傳送訊息數或失敗傳送訊息數。 * @param metadata * @param exception */ @Override public void onAcknowledgement(RecordMetadata metadata, Exception exception) { if(exception != null){ //傳送失敗 fail++; }else { //傳送成功 success++; } } @Override public void close() { System.out.println("SUCCESS:" + success); System.out.println("FAIL:" + fail); } @Override public void configure(Map<String, ?> configs) { } }(3)producer主程式
public class ProducerDemo { public static void main(String[] args) { //獲取設定引數 Properties properties = new Properties(); //kafka叢集 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"); properties.put(ProducerConfig.ACKS_CONFIG,"-1"); //重試次數 properties.put(ProducerConfig.RETRIES_CONFIG,3); //批次大小 properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384); //等待時間 properties.put(ProducerConfig.LINGER_MS_CONFIG,1); //緩衝區大小 properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432); //指定攔截器 List<String> interceptors = new ArrayList<>(); interceptors.add("com.atguigu.kafka.interceptor.TimeInterceptor"); interceptors.add("com.atguigu.kafka.interceptor.CountInterceptor"); properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,interceptors); //指定key和value的序列化器 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); //建立生產者物件 KafkaProducer<String, String> produce = new KafkaProducer<String, String>(properties); for (int i = 0; i < 10; i++) { //待回撥的方法 //不指定key,預設使用粘性分割區 produce.send(new ProducerRecord<String, String>("atguigu","value-->" + i), new Callback() { public void onCompletion(RecordMetadata recordMetadata, Exception e) { if(e != null){ //資訊傳送失敗 System.out.println(e.getMessage()); }else { //資訊傳送成功 System.out.println(recordMetadata.topic() + " : " + recordMetadata.partition() + " : " + recordMetadata.offset()); } } }); } //關閉 produce.close(); } }3)測試
(1)我們可以在啟動之前寫的消費者,執行測試一下,消費到的資料為:offset : 35,key : null,value1601287826845 >> value-->0 offset : 36,key : null,value1601287827143 >> value-->1 offset : 37,key : null,value1601287827143 >> value-->2 offset : 38,key : null,value1601287827143 >> value-->3 offset : 39,key : null,value1601287827143 >> value-->4 offset : 40,key : null,value1601287827143 >> value-->5 offset : 41,key : null,value1601287827143 >> value-->6 offset : 42,key : null,value1601287827143 >> value-->7 offset : 43,key : null,value1601287827143 >> value-->8 offset : 44,key : null,value1601287827143 >> value-->9

5. Kafka監控
1)修改kafka啟動命令
修改kafka-server-start.sh命令中if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" fi為
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70" export JMX_PORT="9999" #export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" fi注意:修改之後在啟動kafka之前要分發給其他節點
2)上傳壓縮包kafka-eagle-bin-1.4.5.tar.gz到叢集/opt/software目錄
3)解壓到本地[atguigu@hadoop102 software]$ tar -zxvf kafka-eagle-bin-1.4.5.tar.gz4)進入剛才解壓的目錄
[atguigu@hadoop102 kafka-eagle-bin-1.4.5]$ ll 總用量 82932 -rw-rw-r--. 1 atguigu atguigu 84920710 8月 13 23:00 kafka-eagle-web-1.4.5-bin.tar.gz5)將kafka-eagle-web-1.3.7-bin.tar.gz解壓至/opt/module
[atguigu@hadoop102 kafka-eagle-bin-1.4.5]$ tar -zxvf kafka-eagle-web-1.4.5-bin.tar.gz -C /opt/module/6)修改名稱
[atguigu@hadoop102 module]$ mv kafka-eagle-web-1.4.5/ eagle7)給啟動檔案執行許可權
[atguigu@hadoop102 eagle]$ cd bin/ [atguigu@hadoop102 bin]$ ll 總用量 12 -rw-r--r--. 1 atguigu atguigu 1848 8月 22 2017 ke.bat -rw-r--r--. 1 atguigu atguigu 7190 7月 30 20:12 ke.sh [atguigu@hadoop102 bin]$ chmod 777 ke.sh8)修改組態檔 conf/system-config.properties
###################################### # multi zookeeper&kafka cluster list ###################################### kafka.eagle.zk.cluster.alias=cluster1 cluster1.zk.list=hadoop102:2181,hadoop103:2181,hadoop104:2181 ###################################### # kafka offset storage ###################################### cluster1.kafka.eagle.offset.storage=kafka ###################################### # enable kafka metrics ###################################### kafka.eagle.metrics.charts=true kafka.eagle.sql.fix.error=false ###################################### # kafka jdbc driver address ###################################### kafka.eagle.driver=com.mysql.jdbc.Driver kafka.eagle.url=jdbc:mysql://hadoop102:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull kafka.eagle.username=root kafka.eagle.password=1234569)新增環境變數
export KE_HOME=/opt/module/eagle export PATH=$PATH:$KE_HOME/bin注意:source /etc/profile
10)啟動[atguigu@hadoop102 eagle]$ bin/ke.sh start ... ... ... ... ******************************************************************* * Kafka Eagle Service has started success. * Welcome, Now you can visit 'http://192.168.202.102:8048/ke' * Account:admin ,Password:123456 ******************************************************************* * <Usage> ke.sh [start|status|stop|restart|stats] </Usage> * <Usage> https://www.kafka-eagle.org/ </Usage> ******************************************************************* [atguigu@hadoop102 eagle]$注意:啟動之前需要先啟動ZK以及KAFKA
11)登入頁面檢視監控資料
http://192.168.202.102:8048/ke
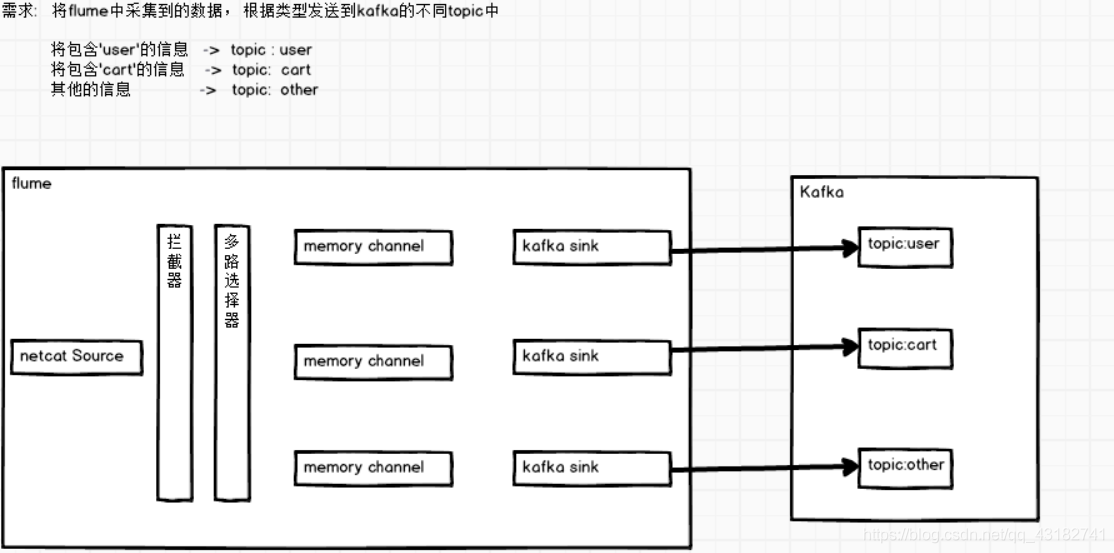
6. Flume對接Kafka
我們先來看一下拓撲圖
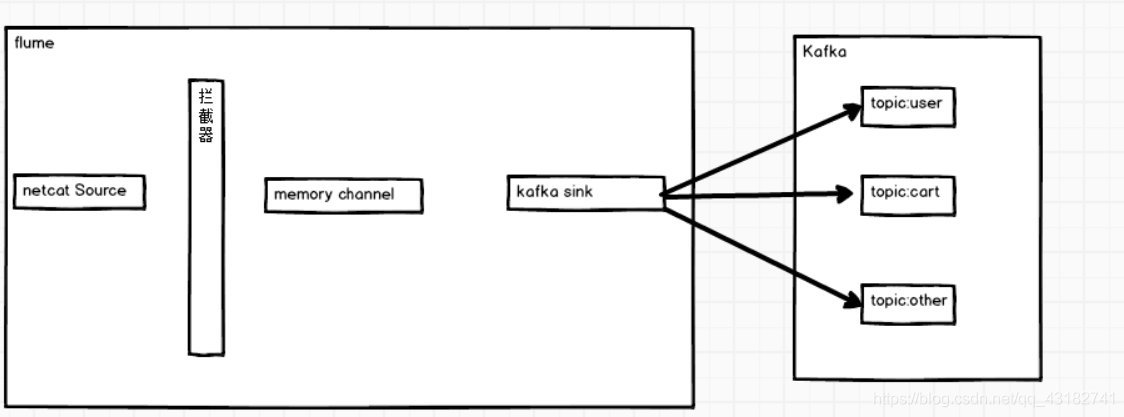
上圖中清晰的展示了Flume和Kafka的對接是如何實現的,但是我們不需要如此複雜,Kafka中的sink給我們提供了相應的方法,我們只需要如下圖所示就可以了:
6.1 設定flume
這些設定flume的官網都會有…
# define a1.sources = r1 a1.sinks = k1 a1.channels = c1 # source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/data/flume.log # sink a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sinks.k1.kafka.topic = first a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.kafka.producer.linger.ms = 1 # channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # bind a1.sources.r1.channels = c1 a1.sinks.k1.channel = c12) 啟動kafka消費者
3) 進入flume根目錄下,啟動flume$ bin/flume-ng agent -c conf/ -n a1 -f jobs/flume-kafka.conf4) 向 /opt/module/data/flume.log裡追加資料,檢視kafka消費者消費情況
$ echo hello >> /opt/module/data/flume.log
6.2 資料分離
0)需求: 將flume採集的資料按照不同的型別輸入到不同的topic中
將紀錄檔資料中帶有atguigu的,輸入到Kafka的first主題中,
將紀錄檔資料中帶有shangguigu的,輸入到Kafka的second主題中,
其他的資料輸入到Kafka的third主題中
1)編寫Flume的Interceptor
0)需求: 將flume採集的資料按照不同的型別輸入到不同的topic中
將紀錄檔資料中帶有joe的,輸入到Kafka的first主題中,
將紀錄檔資料中帶有dog的,輸入到Kafka的atguigu主題中,
其他的資料輸入到Kafka的third主題中
1)編寫Flume的Interceptorpublic class FlumeKafkaInterceptor implements Interceptor { @Override public void initialize() { } /** * 如果包含「joe」就傳送到first主題 * 如果包含「dog」就傳送到atguigu主題 * 其他的資料傳送到third主題 * @param event * @return */ @Override public Event intercept(Event event) { //獲取event的header Map<String, String> headers = event.getHeaders(); //獲取event的body String body = new String(event.getBody()); if(body.contains("joe")){ headers.put("topic","first"); }else if(body.contains("dog")) { headers.put("topic","atguigu"); } return event; } @Override public List<Event> intercept(List<Event> events) { for (Event event : events) { intercept(event); } return events; } @Override public void close() { } //獲取FlumeKafkaIntercceptor的物件 public static class MyBuilder implements Builder{ @Override public Interceptor build() { return new FlumeKafkaInterceptor(); } @Override public void configure(Context context) { } } }2)將寫好的interceptor打包上傳到Flume安裝目錄的lib目錄下
3)設定flume# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = hadoop102 a1.sources.r1.port = 6666 # Describe the sink a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = third a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.kafka.producer.linger.ms = 1 #Interceptor a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.atguigu.kafka.flumeInterceptor.FlumeKafkaInterceptor$MyBuilder # # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c14) 啟動kafka消費者
5) 進入flume根目錄下,啟動flume$ bin/flume-ng agent -c conf/ -n a1 -f jobs/flume-kafka.conf6) 向6666埠寫資料,檢視kafka消費者消費情況
其實Kafka主要是在我們在收集資料時與Flume一起使用,從而起到一個快取從而可以收集大量資料,Kafka的主要特點就是吞吐量大。。哈哈,學到這裡Kafka結束,想學其他的巨量資料框架,大家接著跟我學哈😄😄😄😄😄😄😄😄