【論文】《Blockchained On-Device Federated Learning》精讀筆記
目錄
2.1 one-Epoch BlockFL Operation
3. END-TO-END LATENCY ANALYSIS
3.1 One-Epoch BlockFL Latency Model
3.2 Latency Optimal Block Generation Rate
4.NUMERICAL RESULTS AND DISCUSSION
1.INTRODUCTION
傳統的聯邦學習主要有以下侷限性:
(1)依賴單一的中央伺服器,容易受到伺服器故障的影響;
(2)沒有合適的獎勵機制來刺激使用者提供資料訓練和上傳模型引數。
對此,作者提出了【基於區塊鏈的區塊鏈聯邦學習(BlockFL)】:
(1)用區塊鏈網路來代替中央伺服器,區塊鏈網路允許交換裝置的本地模型更新;
(2)加入驗證和提供相應的獎勵機制。
加入區塊鏈之後,還要考慮延遲問題,因為越高的延遲會導致越多的forking現象。造成延遲的原因主要有以下幾個:
compution delays:訓練本地模型、在本地計算全域性模型;
communication delays:上傳本地模型、下載本地模型、塊傳播延遲、塊驗證延遲(可忽略);
block Generation:塊生成延遲。
對此,作者又對BlockFL由區塊鏈網路引起的延遲進行了分析,研究了BlockFL端到端學習完成延遲,考慮通過調整塊的生成速率即POW難度來使延遲最小化,以此增加系統的實用性。
2. ARCHITECTURE AND OPERATION
2.1 one-Epoch BlockFL Operation

Fig.1.a是傳統FL的架構,不再進行贅述。
Fig.1.b是BlockFL的架構。BlockFL的邏輯結構由礦工和裝置組成。礦工在物理上是隨機選擇的裝置或者單獨節點。
BlockFL每一輪訓練可以分為7個步驟:
1)本地模型更新:裝置
用local sample訓練local model。[計算公式(1)]
2)本地模型上傳:裝置
3)交叉驗證:礦工廣播傳遞local model並進行驗證。若驗證通過,則把它記錄在礦工的候選塊中(直到達到block size,或者達到maxinum waiting time)。
4)塊生成:每個礦工執行POW,直到找到nonce或收到生成塊。
5)塊傳播:首次找到nonce的礦工的候選塊被作為新塊並傳播給其他礦工,礦工從區塊鏈網路上獲得挖礦獎勵(mining reward)。為了避免鏈分叉,一旦每個礦工接收到新的塊,就傳送一個ACK,包括是否發生forking。如果發生forking,操作將從第1)步重新開始,生成新塊的礦工等待一個預定義的而最大block ACK waiting time。
6)全域性模型下載:裝置
從相鄰礦工那裡下載新塊。
7)全域性模型更新:裝置
這個迴圈過程結束的條件: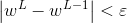 .
.
2.2 FL operation in BlockFL
(1)裝置集: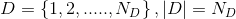 . 的資料樣本為
. 的資料樣本為 .
.
(2)FL模型:本文解決的是平行迴歸問題。
所有裝置的資料樣本: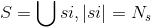
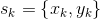 ,其中,
,其中,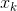 是d維列向量,
是d維列向量,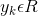 。
。
目標:minimize loss function 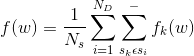 。
。
和傳統FL一樣,使用隨機方差消減梯度演演算法。所有的裝置的本地模型更新採用分散式擬牛頓法進行聚合。
3. END-TO-END LATENCY ANALYSIS
3.1 One-Epoch BlockFL Latency Model
延遲分析在instruction中已有敘述,此處略。
3.2 Latency Optimal Block Generation Rate
使用公式(3)推匯出最優的「塊生成率」。
過程略。
結論:過大的塊生成率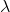 ,forking的發生率變大,進而導致學習完成延遲變大。
,forking的發生率變大,進而導致學習完成延遲變大。
相反,過小的塊生成率,生成塊的代價變大,延遲也會變高。
4.NUMERICAL RESULTS AND DISCUSSION
數值評估了BlockFL的平均完成學習延遲。

Fig.3.a 表示塊生成率對BlockFL的平均學習完成延遲的影響
延遲影象是凸形的,並且隨著SNR(訊雜比)的增大而減小。
Fig.3.b 說明
在裝置數量相同的情況下,BlockFL與傳統FL的準確率幾乎相等。

Fig.4.a 說明BlockFL的學習完成延遲比傳統FL更低( )。
)。
的時候,通過以0.05的概率向每個礦工的本地模型更新加入高斯噪聲
。
- 無故障時,延遲的原因主要有:交叉驗證、塊傳播。
- 在BlockFL中,每個礦工的故障僅僅影響它相聯的裝置,而這些裝置可以從其他互聯的正常礦工那裡獲得模型,從而消除這個影響。
- 較多的礦工可以獲得更低的延遲。(
,有故障時)
- 存在一個使延遲最低的裝置數目。過多的裝置可以有更多可以利用的資料集,但會增大每個塊的大小和塊交換的時間,導致如圖的「凸形延遲」。
Fig.4.b 設定一個裝置成為礦工的門檻![\theta _{e}\epsilon \left [ 0,1 \right ]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202009/gifpdzwgk4hrcq.gif) .
.
無故障時,學習完成延遲變大(因為低門檻時,礦工多,交叉驗證和塊傳播延遲高)
有故障時,延遲反而低(因為礦工少了,耗時減少)
Fig.4.c 表示惡意礦工的鏈比誠實礦工的鏈長的概率。
說明只要有幾個塊被誠實礦工「鎖」住,被惡意礦工篡改的概率就幾乎為0.