【概念解析】簡單理解Embedding技術在推薦系統中的應用
簡單理解Embedding技術在推薦系統中的應用
在之前的學習階段做過一些基於Tensorflow的NLP實驗,很多時候在構建模型的model時候不管三七二十一上來就先來上一層Embedding,只知道加上Embedding層後會得到更好的結果卻未曾深究其作用,經過閱讀《深度學習推薦系統》一書,才明白了個大概,拿來分享給大家也方便日後自己理解。本文結合推薦系統來闡述Embedding的作用和原理。但這裡沒有涉及具體程式碼實現,只做簡單的概念的闡述。
Embedding概述
Embedding操作經常出現在我們設計的模型裡,我們稱其為'嵌入',或者翻譯成'向量對映'。簡單來說它通常幫助我們實現的是一種用低維稠密向量表示高維稀疏向量的作用,便於上層深度神經網路處理。在深度學習框架中,特別是:推薦、廣告、搜尋為核心的網際網路領域,Embedding使用的非常廣泛,Embedding幾乎可以說是Deep Learning的基礎核心操作了。
其實,Embedding並不是單純的去轉化稀疏的one-hot向量這麼簡單,它的應用場景非常多元。它既可以處理序列樣本,也可以處理圖樣本,同時也可以處理異構的多特徵樣本。同時在工業界,Embedding由於其綜合資訊能力強、易於上線部署的特點,應用非常廣泛。
如何理解Embedding
Embedding可以定義為用一個低維的稠密向量去表示一個物件。物件可以為一個詞、一個商品,也可以是一部電影等等。換言之,Embedding向量可以表示相應物件的某些特徵,同時Embedding向量之間的距離反映了物件之間的相似性。
舉個例子會更加直觀(這裡直接用樹上的案例吧):
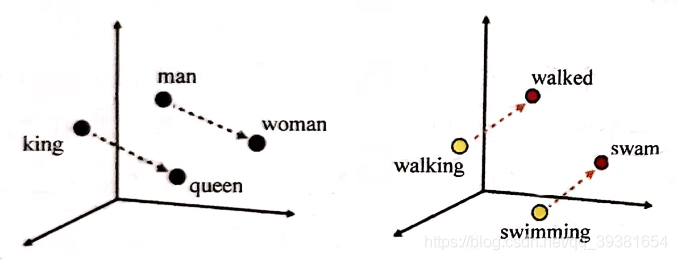
如上圖(左)所示,這是當我們使用Embedding向量表示幾個單詞在Embedding空間的表示。可以看出Embedding(King)到Embedding(Queen)與Embedding(Man)到Embedding(Woman)的距離幾乎完全一樣,這表示Embedding想兩件的距離甚至包含著詞與之間的語意關係資訊(因為我們知道剛才這兩組單詞之間的語意對照是相似的)。
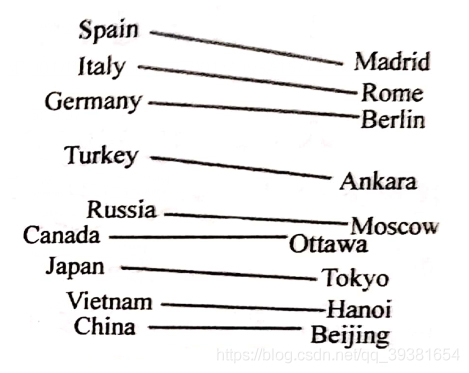
而同樣的圖(右),我們去對比Embedding(Walking)和Embedding(Walked)與Embedding(Swimming)和Embedding(Swam)時也發現它們有著相似的距離表示,這就意味著Embedding同時也能夠挖掘出詞與詞之間詞性關係。(即Walking-Walked ∽ Swimming-Swam)其實,這也只是代表著Embedding很小一部分的作用,假如資料集足夠大,有大量的語料輸入的前提下,Embedding甚至可以挖掘出一些通用知識,比如國家和首都的關係(表示為每個國家與其首都的Embedding空間向量距離相似):
Embedding在推薦領域的泛化
我們剛剛舉的例子是在NLP過程中最簡單的例子,當我們面對推薦問題的時候,我們同樣也可以使用Embedding來對應用領域內的物品進項向量化的表示。與文書處理不同的是,之前詞向量使用大量的語料庫作為基礎進行訓練,那麼當問題被泛化,顯然不同領域的訓練樣本是不同的,比如視訊推薦往往使用使用者的觀看序列進行電影的Embedding化,而電商平臺則會通過使用者的購買歷史作為訓練樣本,而教育類推薦往往以學生選課的順序序列作為樣本參與Embedding。
Embedding的重要性
剛剛我們說Embedding是Deep Learning的基礎核心操作,或者說推薦系統的核心,主要原因有三個方面:
- 推薦場景中大量使用one-hot編碼對類別、id等特徵進行編碼,導致樣本的特徵維度很高但卻非常稀疏。深度學習的結構特點卻不擅長處理稀疏的特徵向量,所以幾乎所有的DL模型都需要Embedding層作為第一層來將高維稀疏的特徵對映到一個相對低維的且稠密的向量上來。
- Embedding本身就是極其重要的特徵向量。相比於MF等傳統方法產生的特徵向量,Embedding幾乎可以引入任何資訊進行編碼(尤其是Graph Embedding技術出現後),Embedding向量往往會與其他推薦系統特徵連線後進入深層神經網路繼續訓練。
- Embedding對物品、使用者相似度的計算常用於推薦系統的召回部分設計,我們都知道推薦系統的核心分為兩部,顯示召回物品,然後是排序返回TopN序列。那麼對於第一部分的召回過程中,當區域性敏感雜湊等快速最近鄰搜尋技術應用於推薦系統後Embedding更適用於對海量資料進行快速篩選,過濾出幾百個相似度高的產品交付給上層進行精準排序,以便生成最終的推薦序列。
對於Embedding相關技術的總結
這裡給出一些Embedding相關技術的總結,事實上在《深度學習推薦系統》這本書裡有詳細的講解每種技術的起源和原理,本文在此處等於給出了索引,想要更好的使用Embedding相關技術的同學可以就表中的目錄區自行深入瞭解:
