【MyBatis系列8】給我五分鐘,帶你徹底掌握MyBatis的快取工作原理
MyBatis中快取原理分析
前言
在計算機的世界中,快取無處不在,作業系統有作業系統的快取,資料庫也會有資料庫的快取,各種中介軟體如Redis也是用來充當快取的作用,程式語言中又可以利用記憶體來作為快取。自然的,作為一款優秀的ORM框架,MyBatis中又豈能少得了快取,那麼本文的目的就是帶領大家一起探究一下MyBatis的快取是如何實現的。給我五分鐘,帶你徹底掌握MyBatis的快取工作原理
為什麼要快取
在計算機的世界中,CPU的處理速度可謂是一馬當先,遠遠甩開了其他操作,尤其是I/O操作,除了那種CPU密集型的系統,其餘大部分的業務系統效能瓶頸最後或多或少都會出現在I/O操作上,所以為了減少磁碟的I/O次數,那麼快取是必不可少的,通過快取的使用我們可以大大減少I/O操作次數,從而在一定程度上彌補了I/O操作和CPU處理速度之間的鴻溝。而在我們ORM框架中引入快取的目的就是為了減少讀取資料庫的次數,從而提升查詢的效率。
MyBatis快取
MyBatis中的快取相關類都在cache包下面,而且定義了一個頂級介面Cache,預設只有一個實現類PerpetualCache,PerpetualCache中是內部維護了一個HashMap來實現快取。
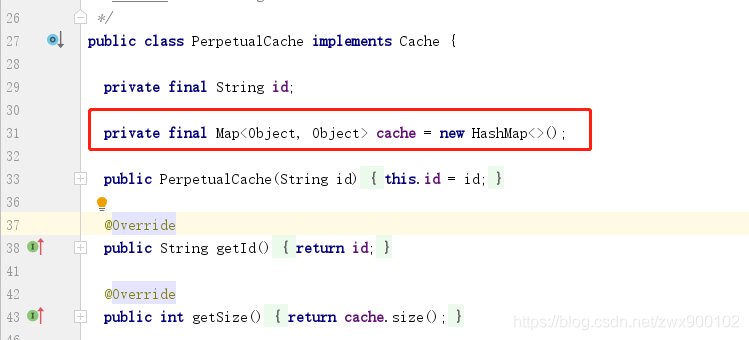
下圖就是MyBatis中快取相關類:
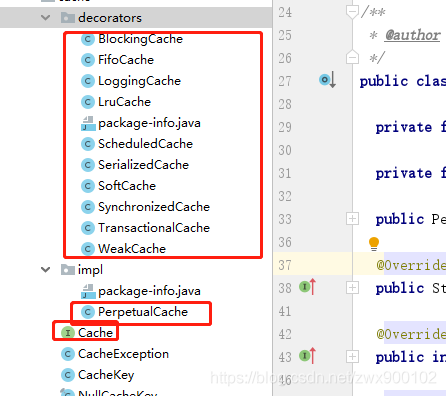
需要注意的是decorators包下面的所有類也實現了Cache介面,那麼為什麼我還是要說Cache只有一個實現類呢?其實看名字就知道了,這個包裡面全部是裝飾器,也就是說這其實是裝飾器模式的一種實現。
我們隨意開啟一個裝飾器:
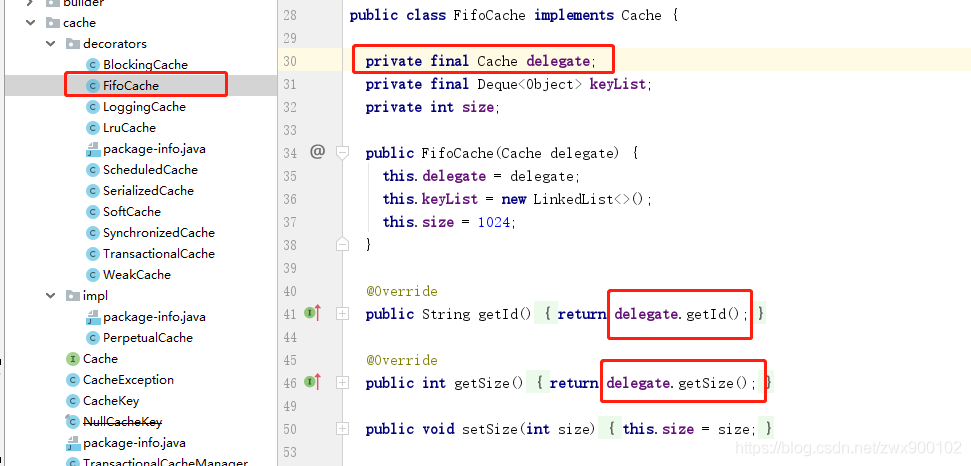
可以看到,最終都是呼叫了delegate來實現,只是將部分功能做了增強,其本身都需要依賴Cache的唯一實現類PerpetualCache(因為裝飾器內需要傳入Cache物件,故而只能傳入PerpetualCache物件,因為介面是無法直接new出來傳進去的)。
在MyBatis中存在兩種快取,即一級快取和二級快取。
一級快取
一級快取也叫本地快取,在MyBatis中,一級快取是在對談(SqlSession)層面實現的,這就說明一級快取作用範圍只能在同一個SqlSession中,跨SqlSession是無效的。
MyBatis中一級快取是預設開啟的,不需要任何設定。
我們先來看一個例子驗證一下一級快取是不是真的存在,作用範圍又是不是真的只是對同一個SqlSession有效。
一級快取真的存在嗎
package com.lonelyWolf.mybatis;
import com.lonelyWolf.mybatis.mapper.UserAddressMapper;
import com.lonelyWolf.mybatis.mapper.UserMapper;
import com.lonelyWolf.mybatis.model.LwUser;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
public class TestMyBatisCache {
public static void main(String[] args) throws IOException {
String resource = "mybatis-config.xml";
//讀取mybatis-config組態檔
InputStream inputStream = Resources.getResourceAsStream(resource);
//建立SqlSessionFactory物件
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//建立SqlSession物件
SqlSession session = sqlSessionFactory.openSession();
UserMapper userMapper = session.getMapper(UserMapper.class);
List<LwUser> userList = userMapper.selectUserAndJob();
List<LwUser> userList2 = userMapper.selectUserAndJob();
}
}
執行後,輸出結果如下:
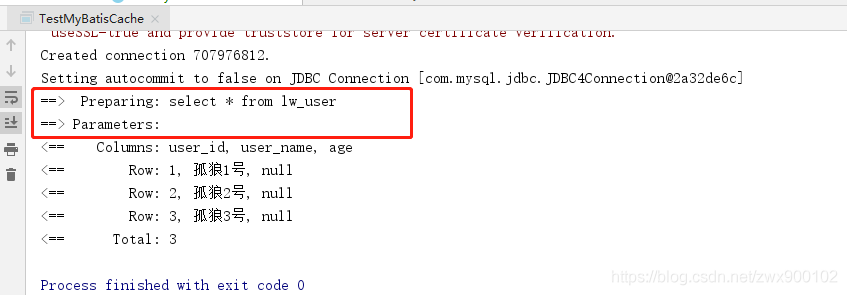
我們可以看到,sql語句只列印了一次,這就說明第2次用到了快取,這也足以證明一級快取確實是存在的而且預設就是是開啟的。
一級快取作用範圍
現在我們再來驗證一下一級快取是否真的只對同一個SqlSession有效,我們對上面的範例程式碼進行如下改變:
SqlSession session1 = sqlSessionFactory.openSession();
SqlSession session2 = sqlSessionFactory.openSession();
UserMapper userMapper1 = session1.getMapper(UserMapper.class);
UserMapper userMapper2 = session2.getMapper(UserMapper.class);
List<LwUser> userList = userMapper1.selectUserAndJob();
List<LwUser> userList2 = userMapper2.selectUserAndJob();
這時候再次執行,輸出結果如下:
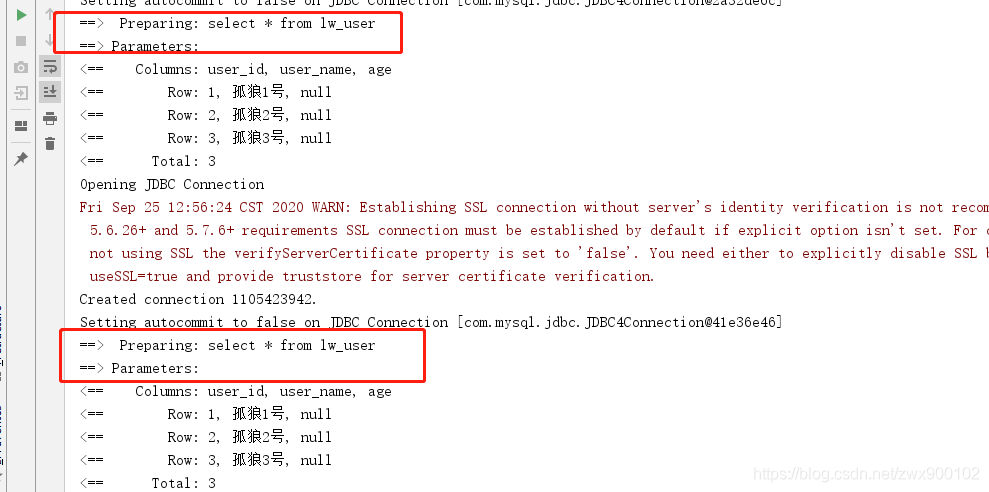
可以看到,列印了2次,沒有用到快取,也就是不同SqlSession中不能共用一級快取。
一級快取原理分析
首先讓我們來想一想,既然一級快取的作用域只對同一個SqlSession有效,那麼一級快取應該儲存在哪裡比較合適是呢?
是的,自然是儲存在SqlSession內是最合適的,那我們來看看SqlSession的唯一實現類DefaultSqlSession:

DefaultSqlSession中只有5個成員屬性,後面3個不用說,肯定不可能用來儲存快取,然後Configuration又是一個全域性的組態檔,也不合適儲存一級快取,這麼看來就只有Executor比較合適了,因為我們知道,SqlSession只提供對外介面,實際執行sql的就是Executor。
既然這樣,那我們就進去看看Executor的實現類BaseExecutor:
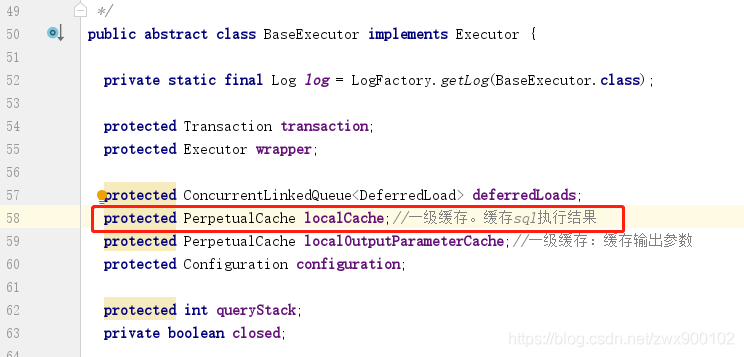
看到果然有一個localCache。而上面我們有提到PerpetualCache內快取是用一個HashMap來儲存快取的,那麼接下來大家肯定就有以下問題:
- 快取是什麼時候建立的?
- 快取的key是怎麼定義的?
- 快取在何時使用
- 快取在什麼時候會失效?
接下來就讓我們逐一分析
一級快取CacheKey的構成
既然快取那麼肯定是針對的查詢語句,一級快取的建立就是在BaseExecutor中的query方法內建立的:

createCacheKey這個方法的程式碼就不貼了,在這裡我總結了一下CacheKey的組成,CacheKey主要是由以下6部分組成
- 1、將Statement中的id新增到CacheKey物件中的updateList屬性
- 2、將offset(分頁偏移量)新增到CacheKey物件中的updateList屬性(如果沒有分頁則預設0)
- 3、將limit(每頁顯示的條數)新增到CacheKey物件中的updateList屬性(如果沒有分頁則預設Integer.MAX_VALUE)
- 4、將sql語句(包括預留位置?)新增到CacheKey物件中的updateList屬性
- 5、迴圈使用者傳入的引數,並將每個引數新增到CacheKey物件中的updateList屬性
- 6、如果有設定Environment,則將Environment中的id新增到CacheKey物件中的updateList屬性
一級快取的使用
建立完CacheKey之後,我們繼續進入query方法:
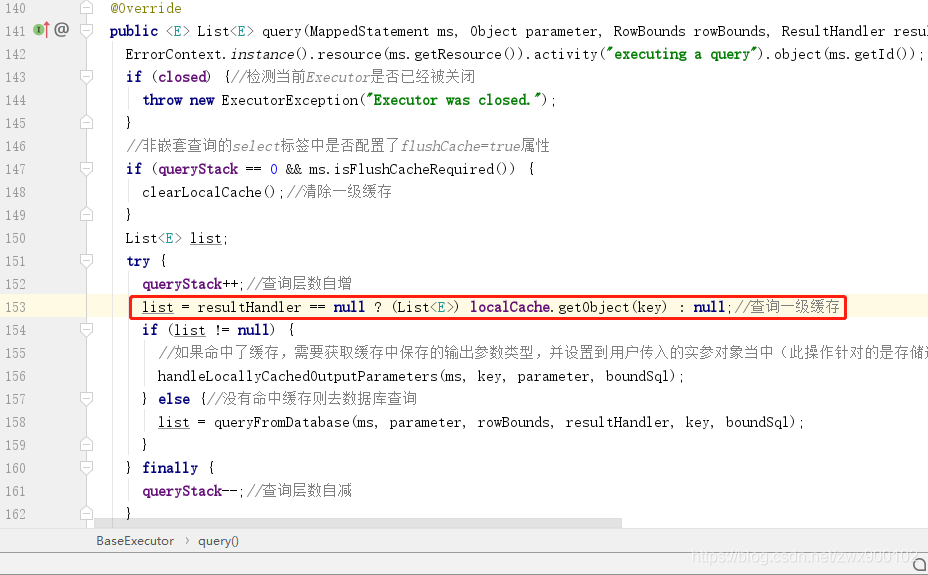
可以看到,在查詢之前就會去localCache中根據CacheKey物件來獲取快取,獲取不到才會呼叫後面的queryFromDatabase方法
一級快取的建立
queryFromDatabase方法中會將查詢得到的結果儲存到localCache中
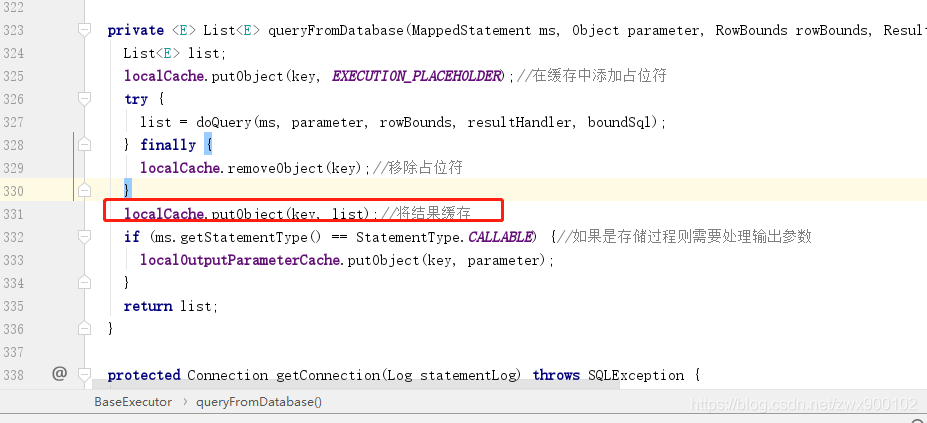
一級快取什麼時候會被清除
一級快取的清除主要有以下兩個地方:
- 1、就是獲取快取之前會先進行判斷使用者是否設定了flushCache=true屬性(參考一級快取的建立程式碼截圖),如果設定了則會清除一級快取。
- 2、MyBatis全域性設定屬性localCacheScope設定為Statement時,那麼完成一次查詢就會清除快取。
- 3、在執行commit,rollback,update方法時會清空一級快取。
PS:利用外掛我們也可以自己去將快取清除,後面我們會介紹外掛相關知識。
二級快取
一級快取因為只能在同一個SqlSession中共用,所以會存在一個問題,在分散式或者多執行緒的環境下,不同對談之間對於相同的資料可能會產生不同的結果,因為跨對談修改了資料是不能互相感知的,所以就有可能存在髒資料的問題,正因為一級快取存在這種不足,所以我們需要一種作用域更大的快取,這就是二級快取。
二級快取的作用範圍
一級快取作用域是SqlSession級別,所以它儲存的SqlSession中的BaseExecutor之中,但是二級快取目的就是要實現作用範圍更廣,那肯定是要實現跨對談共用的,在MyBatis中二級快取的作用域是namespace,也就是作用範圍是同一個名稱空間,所以很顯然二級快取是需要儲存在SqlSession之外的,那麼二級快取應該儲存在哪裡合適呢?
在MyBatis中為了實現二級快取,專門用了一個裝飾器來維護,這就是我們上一篇文章介紹Executor時還留下的沒有介紹的一個物件:CachingExecutor。
如何開啟二級快取
二級快取相關的設定有三個地方:
1、mybatis-config中有一個全域性設定屬性,這個不設定也行,因為預設就是true。
<setting name="cacheEnabled" value="true"/>
想詳細瞭解mybatis-config的可以點選這裡。
2、在Mapper對映檔案內需要設定快取標籤:
<cache/>
或
<cache-ref namespace="com.lonelyWolf.mybatis.mapper.UserAddressMapper"/>
想詳細瞭解Mapper對映的所有標籤屬性設定可以點選這裡。
3、在select查詢語句標籤上設定useCache屬性,如下:
<select id="selectUserAndJob" resultMap="JobResultMap2" useCache="true">
select * from lw_user
</select>
以上設定第1點是預設開啟的,也就是說我們只要設定第2點就可以開啟二級快取了,而第3點是當我們需要針對某一條語句來設定二級快取時候則可以使用。
不過開啟二級快取的時候有兩點需要注意:
1、需要commit事務之後才會生效
2、如果使用的是預設快取,那麼結果集物件需要實現序列化介面(Serializable)
如果不實現序列化介面則會報如下錯誤:

接下來我們通過一個例子來驗證一下二級快取的存在,還是用上面一級快取的例子進行如下改造:
SqlSession session1 = sqlSessionFactory.openSession();
UserMapper userMapper1 = session1.getMapper(UserMapper.class);
List<LwUser> userList = userMapper1.selectUserAndJob();
session1.commit();//注意這裡需要commit,否則快取不會生效
SqlSession session2 = sqlSessionFactory.openSession();
UserMapper userMapper2 = session2.getMapper(UserMapper.class);
List<LwUser> userList2 = userMapper2.selectUserAndJob();
然後UserMapper.xml對映檔案中,新增如下設定:
<cache/>
執行程式碼,輸出如下結果:
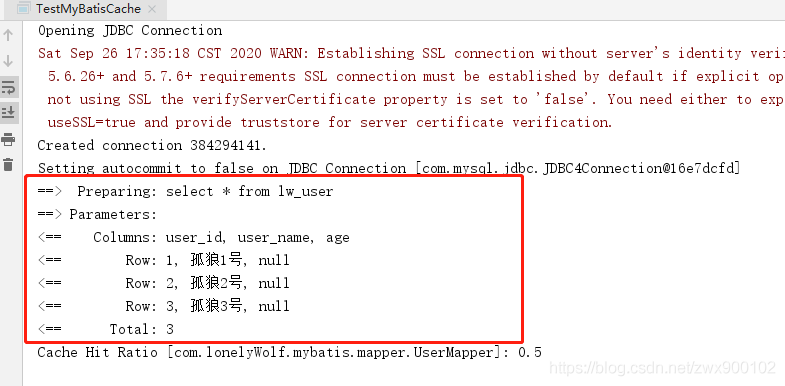
上面輸出結果中只輸出了一次sql,說明用到了快取,而因為我們是跨對談的,所以肯定就是二級快取生效了。
二級快取原理分析
上面我們提到二級快取是通過CachingExecutor物件來實現的,那麼就讓我們先來看看這個物件:
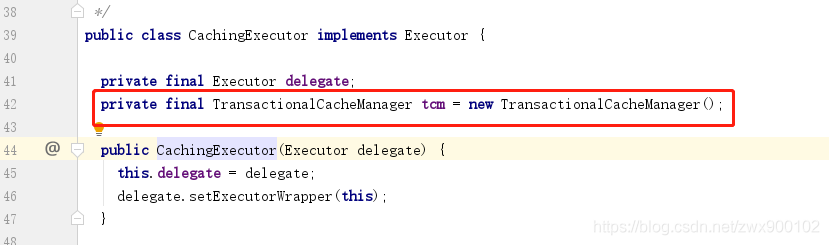
我們看到CachingExecutor中只有2個屬性,第1個屬性不用說了,因為CachingExecutor本身就是Executor的包裝器,所以屬性TransactionalCacheManager肯定就是用來管理二級快取的,我們再進去看看TransactionalCacheManager物件是如何管理快取的:

TransactionalCacheManager內部非常簡單,也是維護了一個HashMap來儲存快取。
HashMap中的value是一個TransactionalCache物件,繼承了Cache。
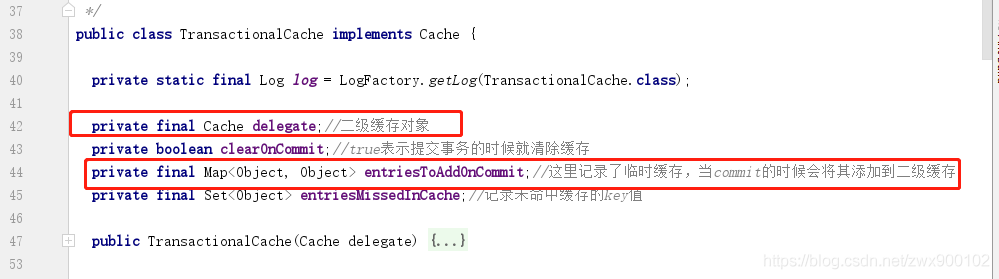
注意上面有一個屬性是臨時儲存二級快取的,為什麼要有這個屬性,我們下面會解釋。
二級快取的建立和使用
我們在讀取mybatis-config全域性組態檔的時候會根據我們設定的Executor型別來建立對應的三種Executor中的一種,然後如果我們開啟了二級快取之後,只要開啟(全域性組態檔中設定為true)就會使用CachingExecutor來對我們的三種基本Executor進行包裝,即使Mapper.xml對映檔案沒有開啟也會進行包裝。
接下來我們看看CachingExecutor中的query方法:
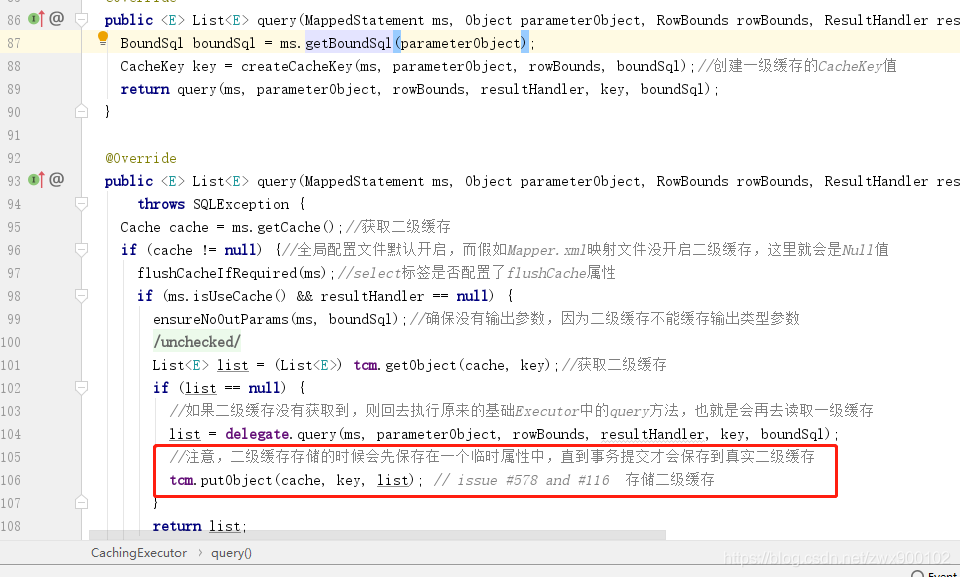
上面方法大致經過如下流程:
- 1、建立一級快取的CacheKey
- 2、獲取二級快取
- 3、如果沒有獲取到二級快取則執行被包裝的Executor物件中的query方法,此時會走一級快取中的流程。
- 4、查詢到結果之後將結果進行快取。
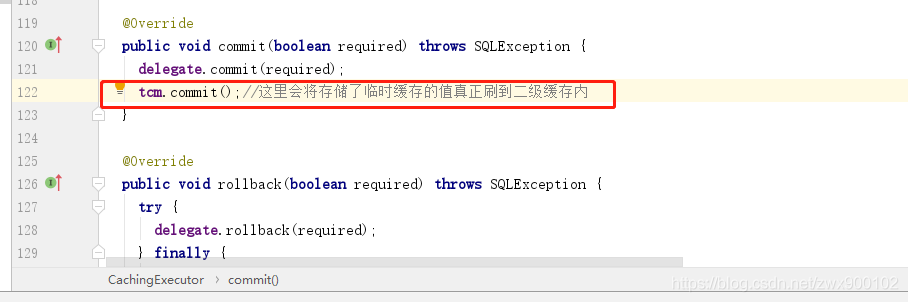
需要注意的是在事務提交之前,並不會真正儲存到二級快取,而是先儲存到一個臨時屬性,等事務提交之後才會真正儲存到二級快取。這麼做的目的就是防止髒讀。因為假如你在一個事務中修改了資料,然後去查詢,這時候直接快取了,那麼假如事務回滾了呢?所以這裡會先臨時儲存一下。
所以我們看一下commit方法:
二級快取如何進行包裝
最開始我們提到了一些快取的包裝類,這些都到底有什麼用呢?
在回答這個問題之前,我們先斷點一下看看獲取到的二級快取長啥樣:
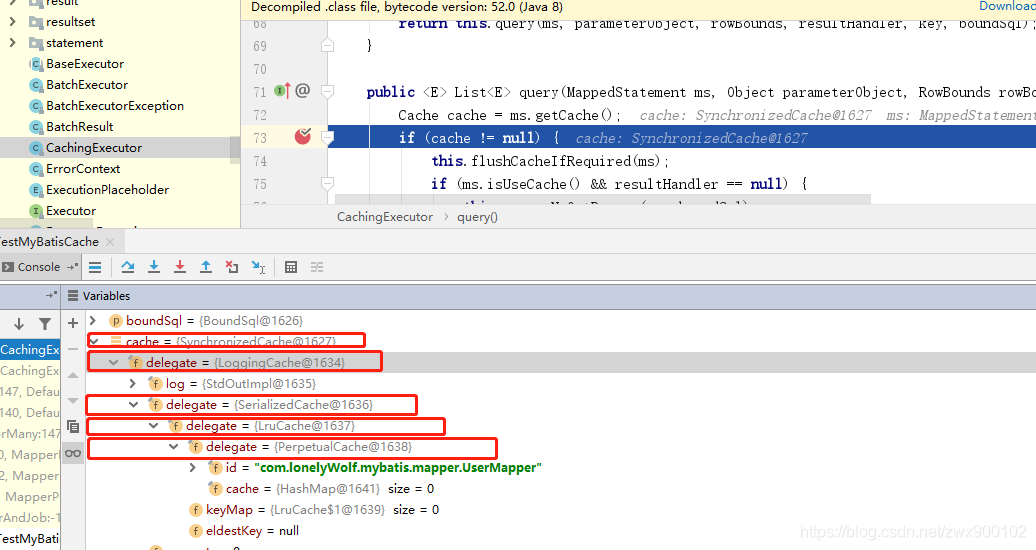
從上面可以看到,經過了層層包裝,從內到外一次經過如下包裝:
- 1、PerpetualCache:第一層快取,這個是快取的唯一實現類,肯定需要。
- 2、LruCache:二級快取淘汰機制之一。因為我們設定的預設機制,而預設就是LRU演演算法淘汰機制。淘汰機制總共有4中,我們可以自己進行手動設定。
- 3、SerializedCache:序列化快取。這就是為什麼開啟了預設二級快取我們的結果集物件需要實現序列化介面。
- 4、LoggingCache:紀錄檔快取。
- 5、SynchronizedCache:同步快取機制。這個是為了保證多執行緒機制下的執行緒安全性。
下面就是MyBatis中所有快取的包裝彙總:
| 快取包裝器 | 描述 | 作用 | 裝飾條件 |
|---|---|---|---|
| PerpetualCache | 快取預設實現類 | - | 基本功能,預設攜帶 |
| LruCache | LRU淘汰策略快取(預設淘汰策略) | 當快取達到上限,刪除最近最少使用快取 | eviction=「LRU」 |
| FifoCache | FIFO淘汰策略快取 | 當快取達到上限,刪除最先入隊的快取 | eviction=「FIFO」 |
| SoftCache | JVM軟參照淘汰策略快取 | 基於JVM的SoftReference物件 | eviction=「SOFT」 |
| WeakCache | JVM弱參照淘汰策略快取 | 基於JVM的WeakReference物件 | eviction=「WEAK」 |
| LoggingCache | 帶紀錄檔功能快取 | 輸出快取相關紀錄檔資訊 | 基本功能,預設包裝 |
| SynchronizedCache | 同步快取 | 基於synchronized關鍵字實現,用來解決並行問題 | 基本功能,預設包裝 |
| BlockingCache | 阻塞快取 | get/put操作時會加鎖,防止並行,基於Java重入鎖實現 | blocking=true |
| SerializedCache | 支援序列化的快取 | 通過序列化和反序列化來儲存和讀取快取 | readOnly=false(預設) |
| ScheduledCache | 定時排程快取 | 操作快取時如果快取已經達到了設定的最長快取時間時會移除快取 | flushInterval屬性不為空 |
| TransactionalCache | 事務快取 | 在TransactionalCacheManager中用於維護快取map的value值 | - |
二級快取應該開啟嗎
既然一級快取預設是開啟的,而二級快取是需要我們手動開啟的,那麼我們什麼時候應該開啟二級快取呢?
1、因為所有的update操作(insert,delete,uptede)都會觸發快取的重新整理,從而導致二級快取失效,所以二級快取適合在讀多寫少的場景中開啟。
2、因為二級快取針對的是同一個namespace,所以建議是在單表操作的Mapper中使用,或者是在相關表的Mapper檔案中共用同一個快取。
自定義快取
一級快取可能存在髒讀情況,那麼二級快取是否也可能存在呢?
是的,預設的二級快取畢竟也是儲存在本地快取,所以對於微服務下是可能出現髒讀的情況的,所以這時候我們可能會需要自定義快取,比如利用redis來儲存快取,而不是儲存在本地記憶體當中。
MyBatis官方提供的第三方快取
MyBatis官方也提供了一些第三方快取的支援,如:encache和redis。下面我們以redis為例來演示一下:
引入pom檔案:
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-redis</artifactId>
<version>1.0.0-beta2</version>
</dependency>
然後快取設定如下:
<cache type="org.mybatis.caches.redis.RedisCache"></cache>
然後在預設的resource路徑下新建一個redis.properties檔案:
host=localhost
port=6379
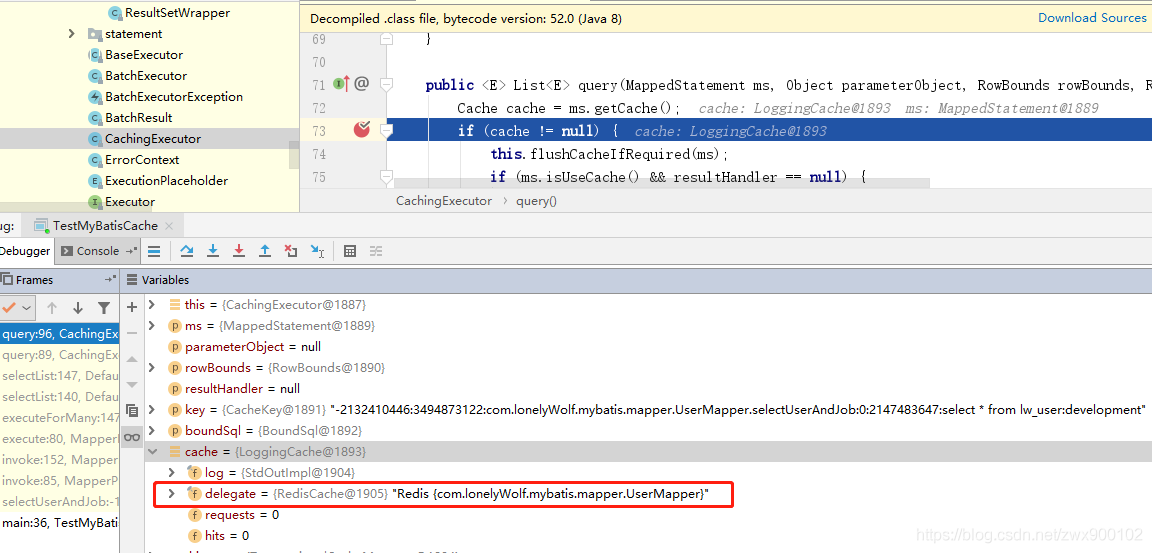
然後執行上面的範例,檢視Cache,已經被Redis包裝:
自己實現二級快取
如果要實現一個自己的快取的話,那麼我們只需要新建一個類實現Cache介面就好了,然後重寫其中的方法,如下:
package com.lonelyWolf.mybatis.cache;
import org.apache.ibatis.cache.Cache;
public class MyCache implements Cache {
@Override
public String getId() {
return null;
}
@Override
public void putObject(Object o, Object o1) {
}
@Override
public Object getObject(Object o) {
return null;
}
@Override
public Object removeObject(Object o) {
return null;
}
@Override
public void clear() {
}
@Override
public int getSize() {
return 0;
}
}
上面自定義的快取中,我們只需要在對應方法,如putObject方法,我們把快取存到我們想存的地方就行了,方法全部重寫之後,然後設定的時候type配上我們自己的類就可以實現了,在這裡我們就不做演示了
總結
本文主要分析了MyBatis的快取是如何實現的,並且分別演示了一級快取和二級快取,並分析了一級快取和二級快取所存在的問題,最後也介紹瞭如何使用第三方快取和如何自定義我們自己的快取,通過本文,我想大家應該可以徹底掌握MyBatis的快取工作原理了。
下一篇,將會介紹MyBatis外掛的實現原理
請關注我,和孤狼一起學習進步。