邏輯迴歸預測癌症分類
2020-09-28 12:01:38
下面是用邏輯迴歸對癌症分類預測過程:
#1獲取資料 讀取的時候加上names #2資料處理 處理缺失值 #3資料集劃分 #4特徵工程 標準化 #5邏輯迴歸預估器 #6模型評估
import pandas as pd
import numpy as np
#1讀取資料
column_name=['Sample code number','Clump Thickness','Uniformity of Cell Size','Uniformity of Cell Shape',
'Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli',
'Mitoses','Class']
data=pd.read_csv("breast-cancer-wisconsin.data",names=column_name)
data.head()
#class是標籤 2代表良性 4代表惡性

#2處理缺失值
#將裡面的問號替換成nan
data=data.replace(to_replace="?",value=np.nan)
#將裡面的缺失樣本刪除
data.dropna(inplace=True)
data.isnull().any()#檢視是否還有缺失值

#3劃分資料集
from sklearn.model_selection import train_test_split
#先篩選特徵值和目標值
x=data.iloc[:,1:-1]#data裡面所有的行,第一列到倒數第二列
y=data["Class"]#data裡面class那一列
x_train,x_test,y_train,y_test=train_test_split(x,y)#這樣就劃分好了資料集
#4資料集標準化
from sklearn.preprocessing import StandardScaler
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
#5模型訓練
from sklearn.linear_model import LogisticRegression
estimator=LogisticRegression()
estimator.fit(x_train,y_train)
#邏輯迴歸的模型引數:迴歸係數和偏置
print("模型的迴歸係數:{}".format(estimator.coef_))
print("模型的迴歸偏置:{}".format(estimator.intercept_))

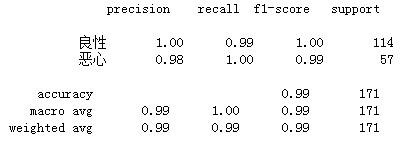
#檢視精確率、召回率、F1-score
from sklearn.metrics import classification_report
print(classification_report(y_test,estimator.predict(x_test),labels=[2,4],target_names=["良性","噁心"]))
#計算AUC指標
from sklearn.metrics import roc_auc_score
y_true=np.where(y_test>3,1,0)
print("AUC的值:{}".format(roc_auc_score(y_true,estimator.predict(x_test))))
AUC的值:0.9956140350877193