HashMap總結
前言
從名字來看,HashMap 就是使用Hash值來當map的實際儲存key。
需要注意的是,HashMap有兩個版本需要甄別,分別是JDK1.8和JDK1.7。
JDK1.8版本的HashMap
主要是陣列+連結串列,但是當連結串列長度過大時,為了提高效率,會將連結串列轉換為紅黑樹。
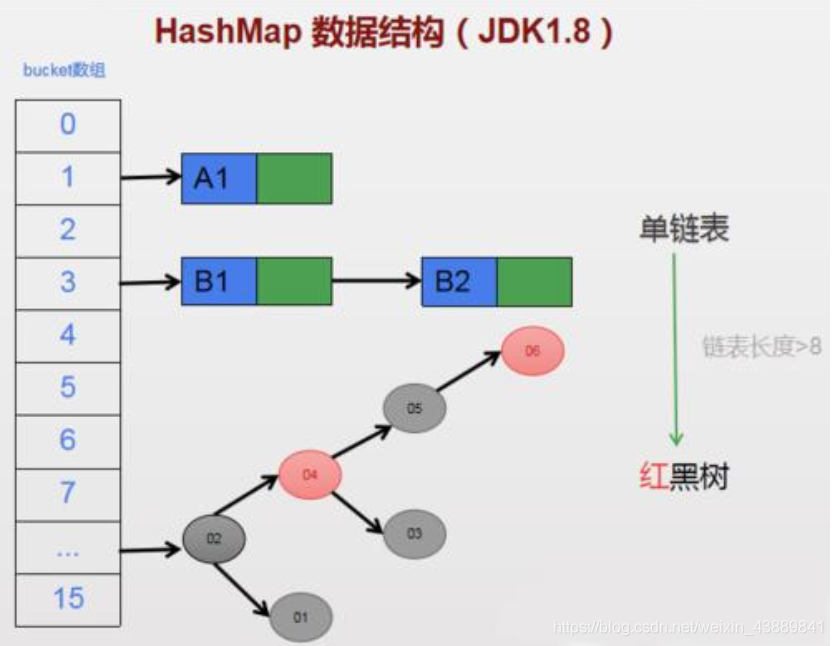
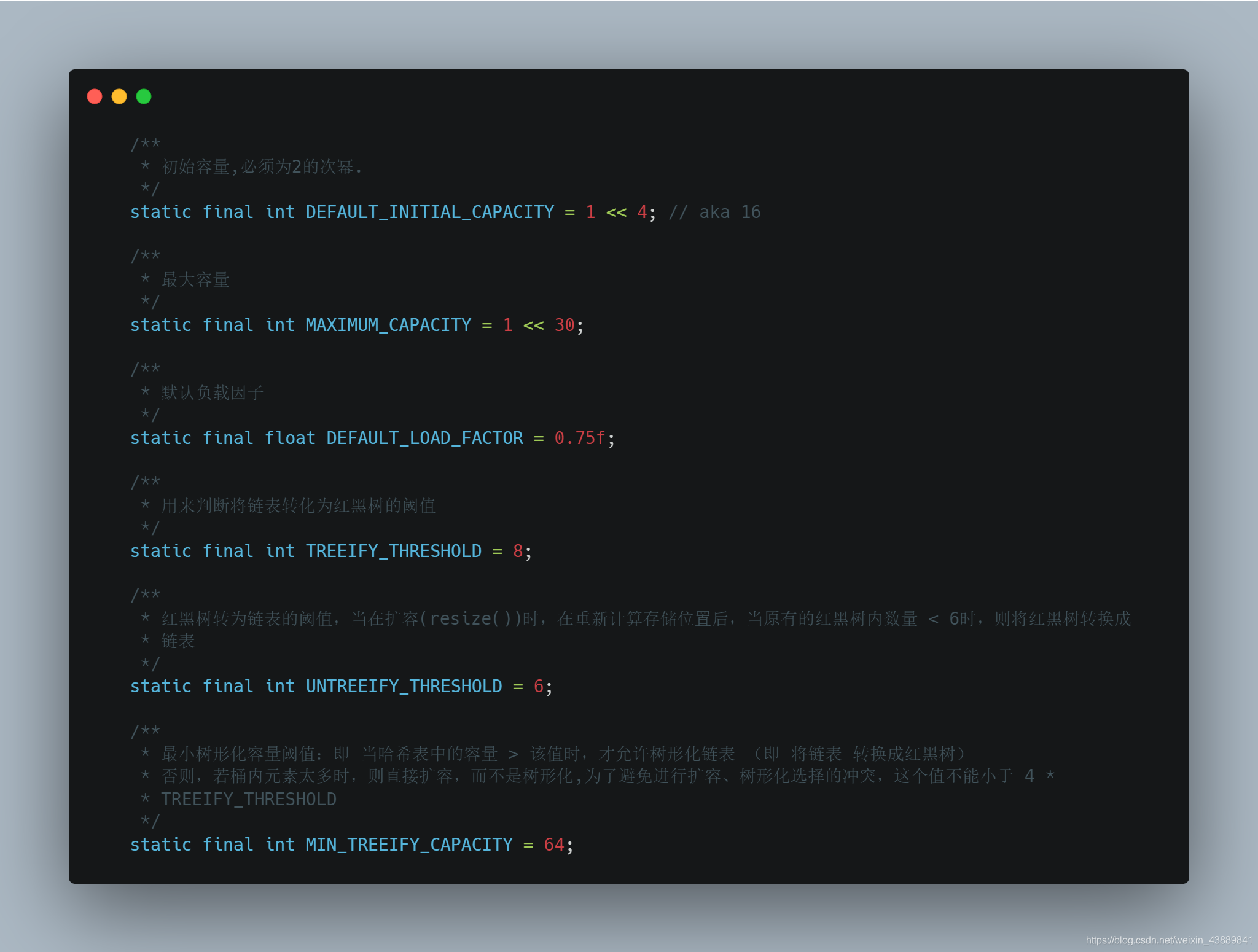
通過下圖配合漢語註釋,我們看看HashMap中的final變數引數。
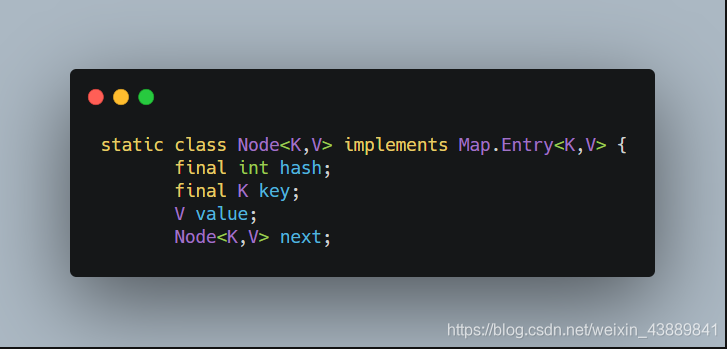
在JDK1.8版本的HashMap中,連結串列元素叫做Node
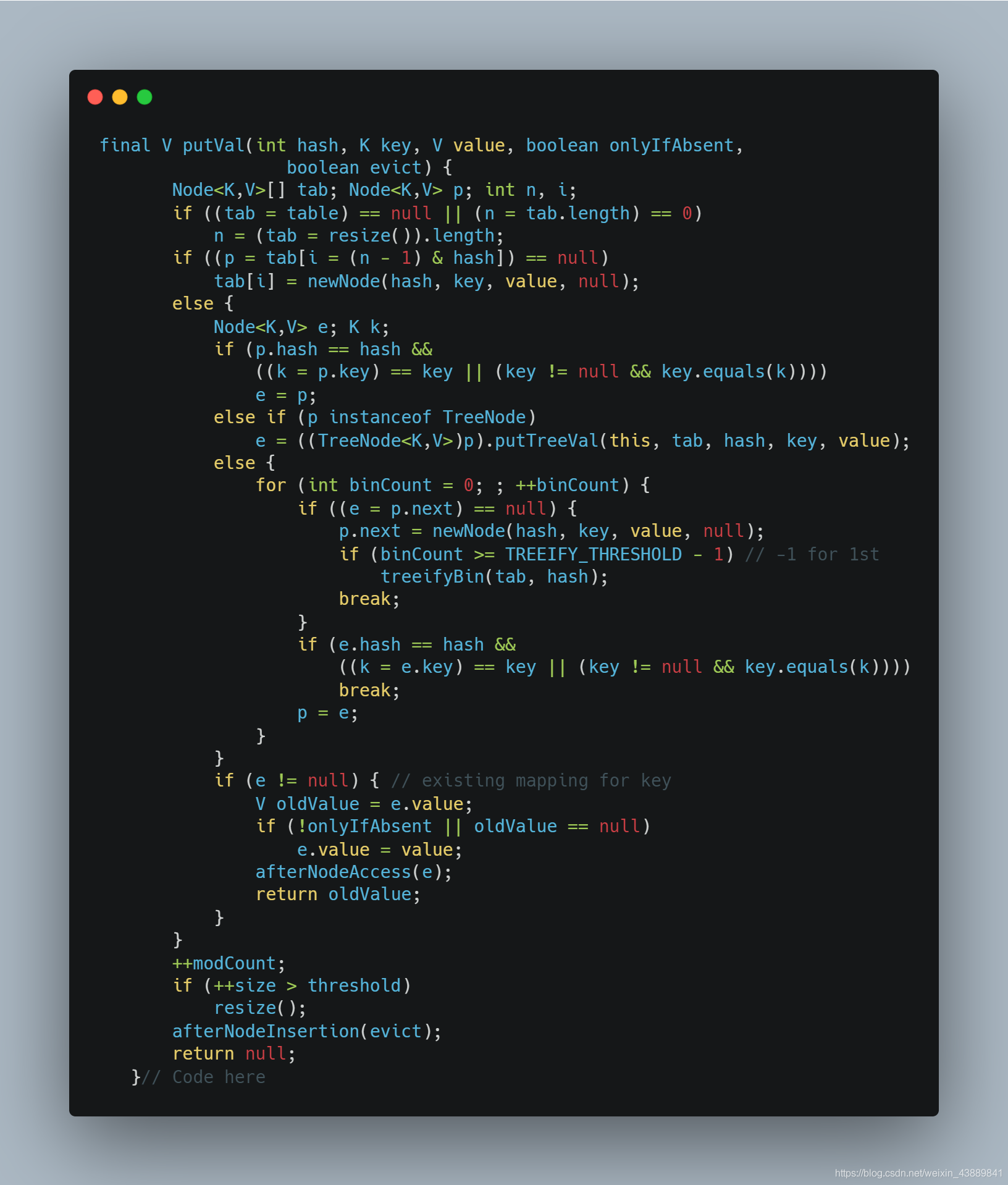
Put方法如下
為便於闡述,我們這裡預先協定陣列的一個元素叫做桶,也就是連結串列。
那麼put方法的流程如下:
- 判斷當前桶是否為空,空的就需要初始化(resize 中會判斷是否進行初始化)。
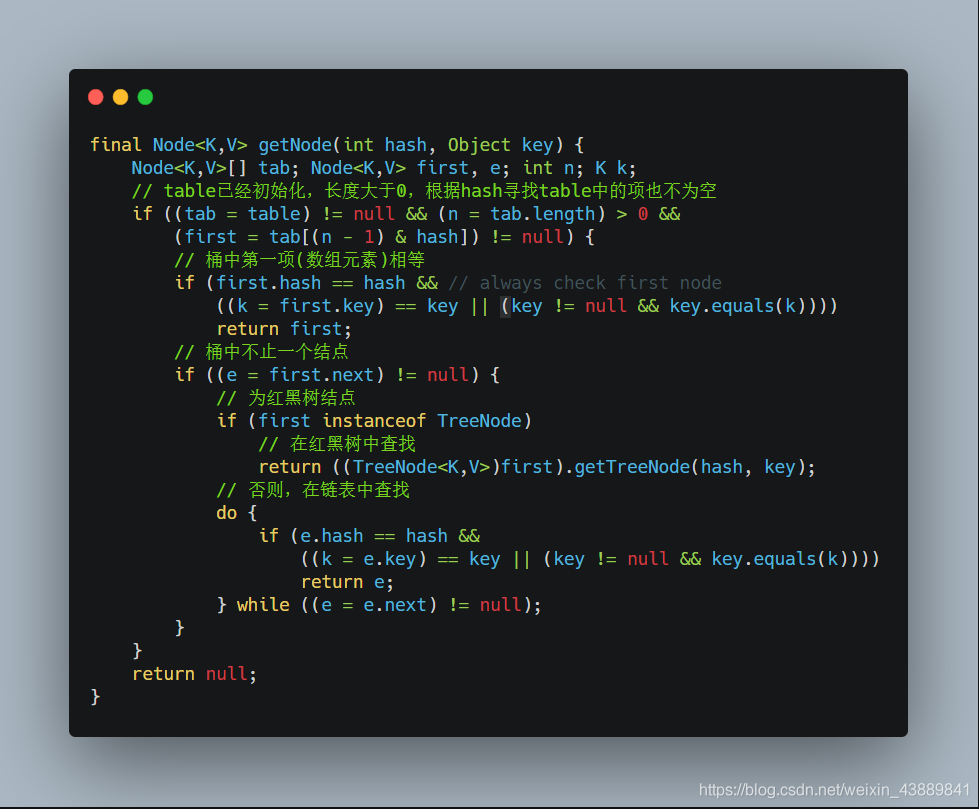
- 根據當前 key 的 hashcode定位到具體的桶中並判斷是否為空,為空表明沒有 Hash 衝突就直接在當前位置建立一個新桶即可。 如果當前桶有值( Hash衝突),那麼就要比較當前桶中的 key、key 的 hashcode 與寫入的 key 是否相等,相等就賦值給 e,在第 8步的時候會統一進行賦值及返回。 如果當前桶為紅黑樹,那就要按照紅黑樹的方式寫入資料。 如果是個連結串列,就需要將當前的 key、value封裝成一個新節點寫入到當前桶的後面(形成連結串列)。
- 接著判斷當前連結串列的大小是否大於預設的閾值,大於時就要轉換為紅黑樹。
- 如果在遍歷過程中找到 key 相同時直接退出遍歷。 如果 e != null 就相當於存在相同的 key,那就需要將值覆蓋。
- 最後判斷是否需要進行擴容。
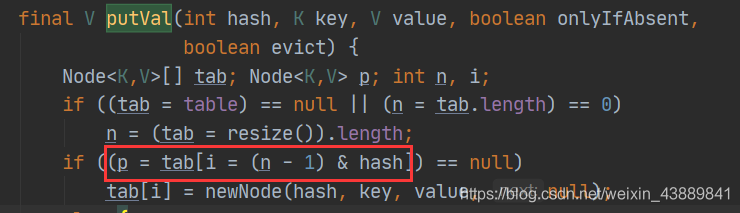
另外假如來了一個元素,該把該元素放到陣列的哪個位置呢?這個位置除了與計算後的hash值有關,還與陣列的長度有關,下圖的n就是陣列的長度。
上圖的hash通過下面方法算出
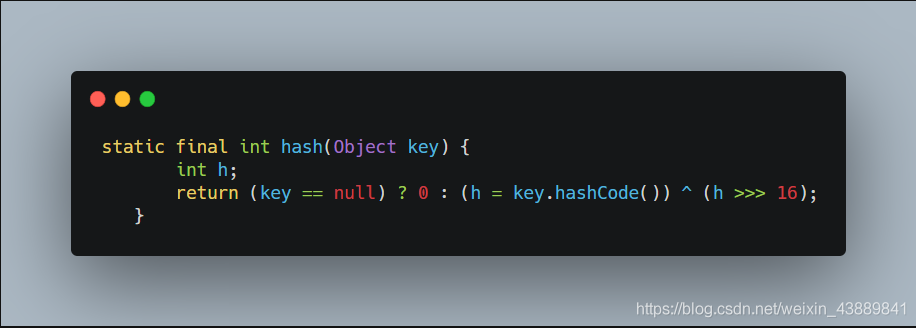
(1)首先獲取物件的hashCode()值,然後將hashCode值右移16位元,然後將右移後的值與原來的hashCode做互斥或運算,返回結果。(其中h>>>16,在JDK1.8中,優化了高位運算的演演算法,使用了零擴充套件,無論正數還是負數,都在高位插入0)。
(2)在putVal原始碼中,我們通過(n-1)&hash獲取該物件的鍵在hashmap中的位置。(其中hash的值就是(1)中獲得的值)其中n表示的是hash桶陣列的長度,並且該長度為2的n次方,這樣(n-1)&hash就等價於hash%n。因為&運算的效率高於%運算。
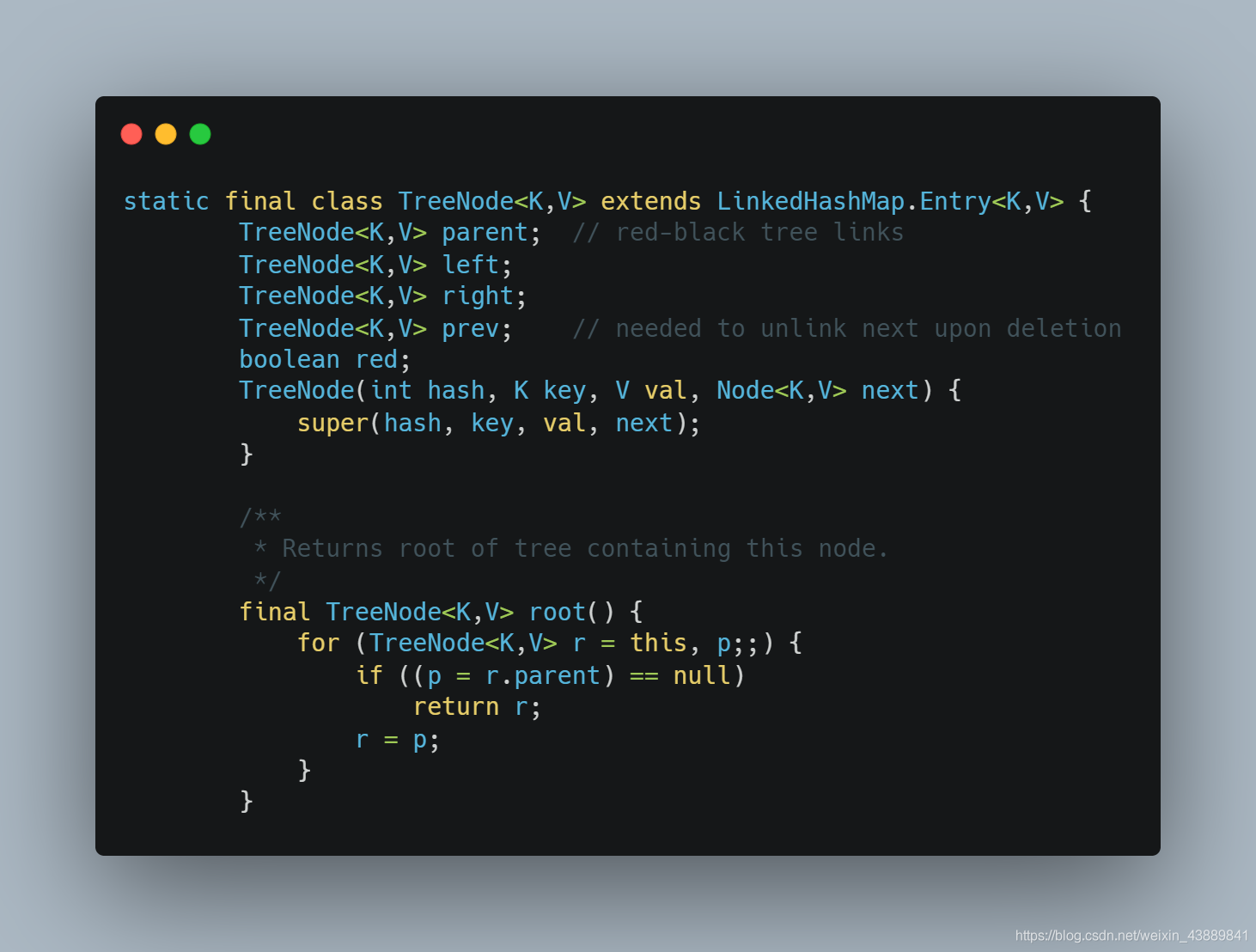
我們上面提到了,當連結串列元素過多時,連結串列會轉化為紅黑樹,下面就是紅黑樹的定義
作為一個Map,有put方法,也有get方法
JDK1.7版本的HashMap
HashMap是陣列+連結串列,通俗點講就是陣列裡放連結串列,連結串列中放的是Key-Value,連結串列元素叫做Entry.
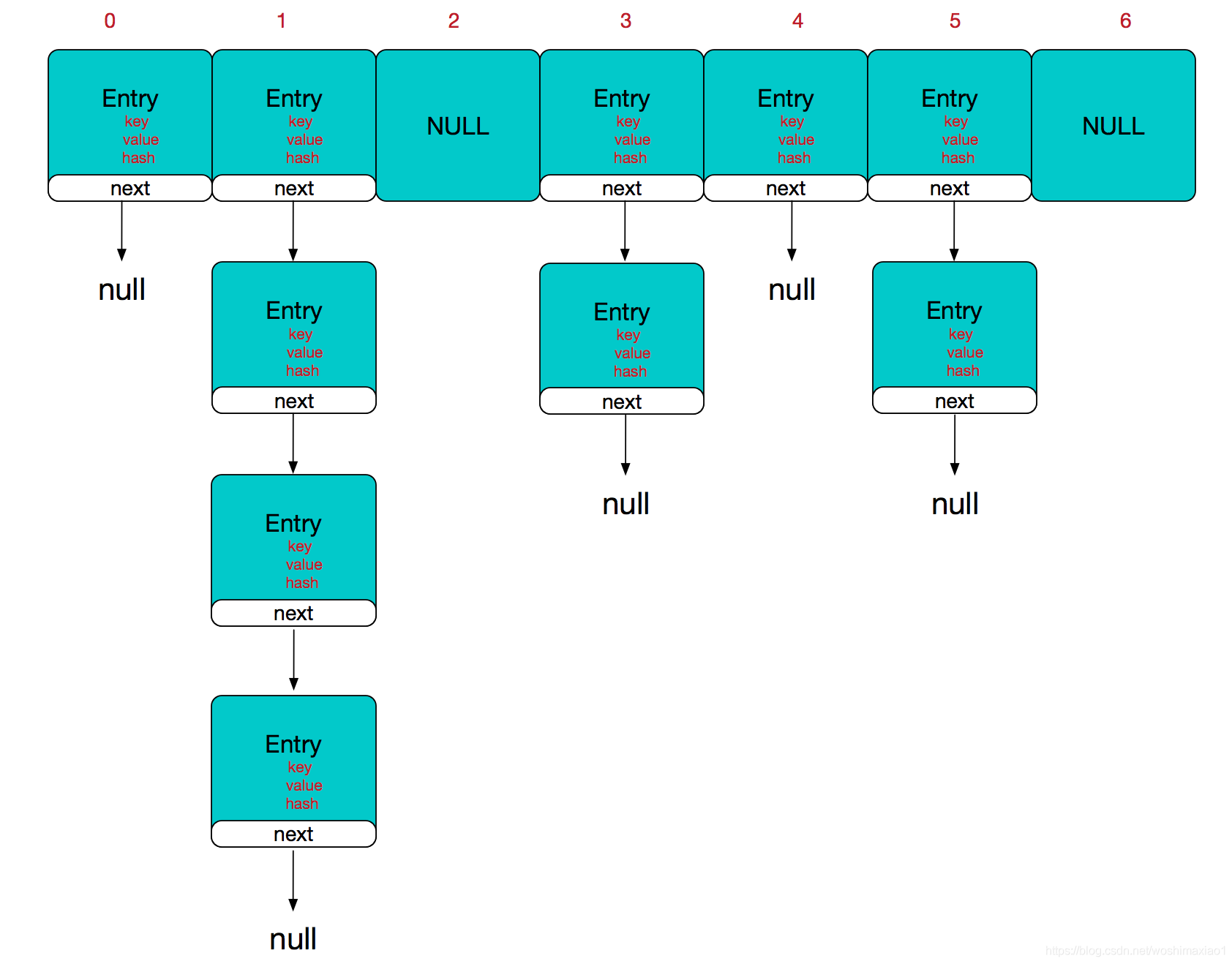
HashMap有負載因子0.75和初始容量16,同時有對應的閾值16*0.75=12。
在put元素時,按照雜湊碼&(陣列元素-1),計算應該放到哪個連結串列裡。
當size大於閾值時會將陣列擴容,擴容到原來的兩倍,將舊陣列裡的元素全部重新計算下標放到新陣列中。
總結
總體來說,JDK1.8版本相對於前面版本的HashMap進行了優化。
在JDK1.7中,插入結點使用頭插法,在1.8後,將頭插法改成了尾插法。
這麼做的原因在於頭插法會導致死迴圈。