實現爬取csdn個人部落格並匯出資料
2020-09-27 09:00:27
因為最近也在學習python,爬蟲和一點pandas的內容
剛好看到一篇部落格,部落格地址:https://blog.csdn.net/xiaoma_2018/article/details/108231658也是實現一樣的內容的,只是使用的方式被我改了一下,我也是借鑑學習大佬的方法
我所使用到的庫有lxml, urllib.request
程式碼如下
'''
匯入所需要的庫
'''
import urllib.request as ur
import lxml.etree as le
import pandas as pd
from config import EachSource,OUTPUT
url = 'https://blog.csdn.net/shine_a/article/list/2'
#得到部落格所有內容
def get_blog(url):
req = ur.Request(
url=url,
headers={
'cookie':'c_session_id%3D10_1600923150109.901257%3Bc_sid%3D40c3e11ae0d6021f6f8323db1cc321a1%3Bc_segment%3D9%3Bc_first_ref%3Dwww.google.com.hk%3Bc_first_page%3Dhttps%253A%2F%2Fwww.csdn.net%2F%3Bc_ref%3Dhttps%253A%2F%2Fblog.csdn.net%2F%3Bc_page_id%3Ddefault%3B',
'User_Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
)
response = ur.urlopen(req).read()
return response
# 得到每一個部落格的連結, 進入二級頁面並提取資料
def get_href_list():
href_s = le.HTML(response).xpath('//div[@class="articleMeList-integration"]/div[2]/div/h4/a/@href')
for data in href_s:
rp = ur.urlopen(data).read()
html = rp.decode()
title = le.HTML(html).xpath('//div[contains(@class,"main_father")]/div/main/div[1]/div/div/div/h1/text()')
readCount = le.HTML(html).xpath('//div[@class="bar-content"]/span[@class="read-count"]/text()')
time = le.HTML(html).xpath('//div[@class="article-info-box"]/div[3]/span[2]/text()')
url_href = data
content = [title[0],readCount[0],time[0],url_href]
info = ",".join(content)
# print(info)
with open(EachSource,'a',encoding='utf-8') as f:
f.writelines(info+'\n')
# 處理資料
def parseData():
f = pd.read_table('./info.txt',sep=',',header=None, names=['文章標題', '瀏覽量', '釋出時間','文章連結'])
f.to_csv(OUTPUT)
if __name__ == '__main__':
blogID = input('Enter blogID:')
pages = input('Enter page:')
response = get_blog(
url= 'https://blog.csdn.net/{blogID}/article/list/{pages}'.format(blogID=blogID, pages=pages)
)
# data = response.decode('utf-8')
# with open('a.txt','w',encoding='utf-8') as f:
# f.write(data)
print('獲取部落格連結...')
get_href_list()
print("開始獲取資料...")
parseData()
print("結束獲取資料...")
說一下我在實現的過程中所遇到的一些問題:
1.在用xpath得到的每個部落格的url的時候,我通過data遍歷進入href_s但是遍歷出來的是url並不是直接進入部落格(二級頁面了)返回的是一些xml格式的物件,所以rp = ur.urlopen(data).read(),html = rp.decode()的方式需要進入到url物件然後進行decode才能進行下面的xpath
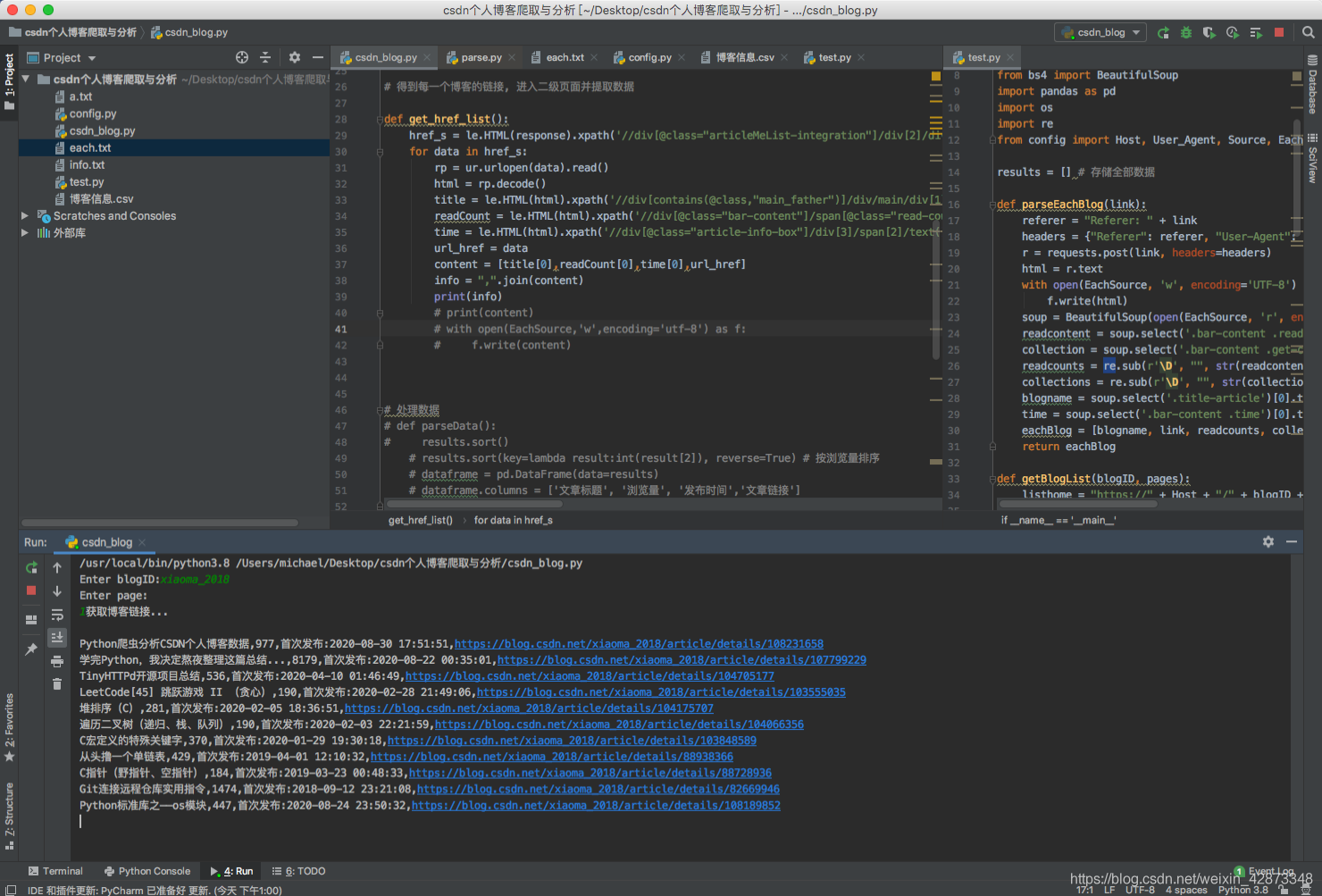
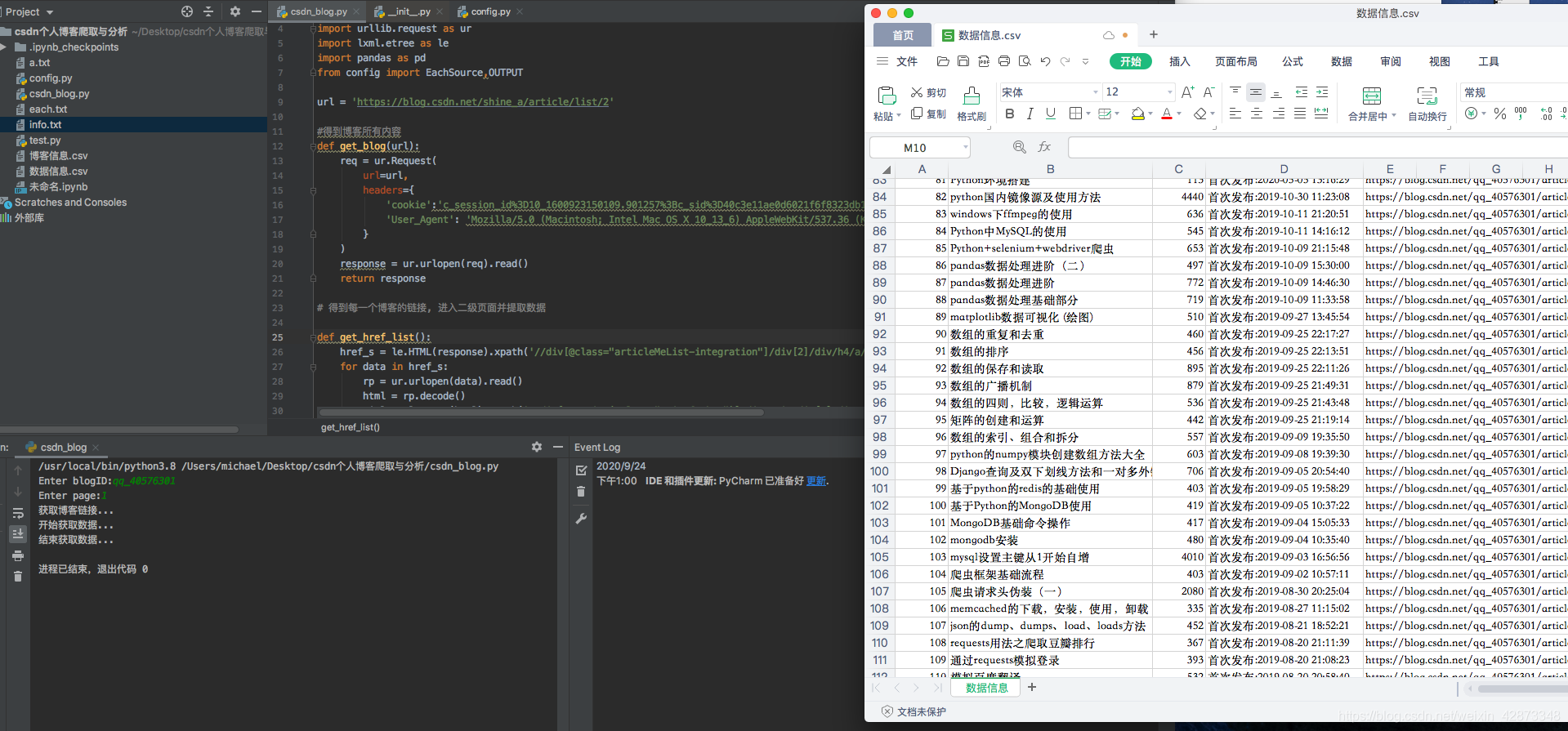
以下是實現的情況:
過程:
最後感謝Caso_卡索博主所提供的內容提供學習與參考!