python爬取p站排行榜並自動傳送郵件
一、前言
pixiv網站是一個以插圖、漫畫和小說藝術為中心的虛擬社群網站。其初衷是為全球藝術家提供一個平臺,發表他們作品,並透過評級系統反映使用者意見。該網站以使用者投稿的原創圖畫為中心,輔以標籤、書籤、作品迴應、排行榜等功能形成具有其特色的社群網路。
本文以pixiv站作為資料爬取物件,這裡簡稱p站。本文工作內容主要可分為以下內容:
- 爬取p站月排行榜插畫原圖
- 自動打包壓縮插畫檔案
- 實現郵件傳送壓縮檔案
編寫本文是因為我在爬取大量插畫後,希望把它發給手機端更換頭像,以及想分享好看的圖給好友(不得不說,p站的圖確實不少,而且原圖真的超清,之前我還想在哪裡找好看又高清的電腦桌布)。但是每次都需要自己手動壓縮,然後再一個個地傳送壓縮包,難免覺得繁瑣,因此想著用通過python實現自動壓縮插畫檔案然後郵件傳送。
二、爬取網頁
由前文《從0實現python批次爬取p站插畫》可知,首先一個簡單的爬取網頁流程大致地分為三個部分,分別是指定請求url、設定headers、發起存取請求。對p站月排行榜的插畫網頁部分進行資料爬取,首先已知月排行榜插畫部分的網頁地址,然後通過右鍵瀏覽器頁面或者按F12進入網頁inspect,檢視network下面的XHR訊息獲取個人user-agent。程式碼實現如下:
import requests
if __name__ == "__main__":
# 指定url
month_rank_url = 'https://www.pixiv.net/ranking.php?mode=monthly&content=illust'
# 設定headers
rank_url_headers = {
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'User-Agent':'你的user-agent',
}
# 發起請求
rank_res_data = requests.get(month_rank_url, headers=rank_url_headers)
rank_res_code = rank_res_data.status_code
# 如果請求成功,那麼儲存網頁
if rank_res_code == 200:
with open('./rank.html', 'w', encoding='utf-8') as fp:
fp.write(rank_res_data.text)
print('rank.html下載成功!')
# 否則
else:
msg = "請求失敗!狀態碼為:"+str(rank_res_code)
print(msg)
執行成功後,可以看到目錄下生成rank.html檔案,開啟顯示如下內容:
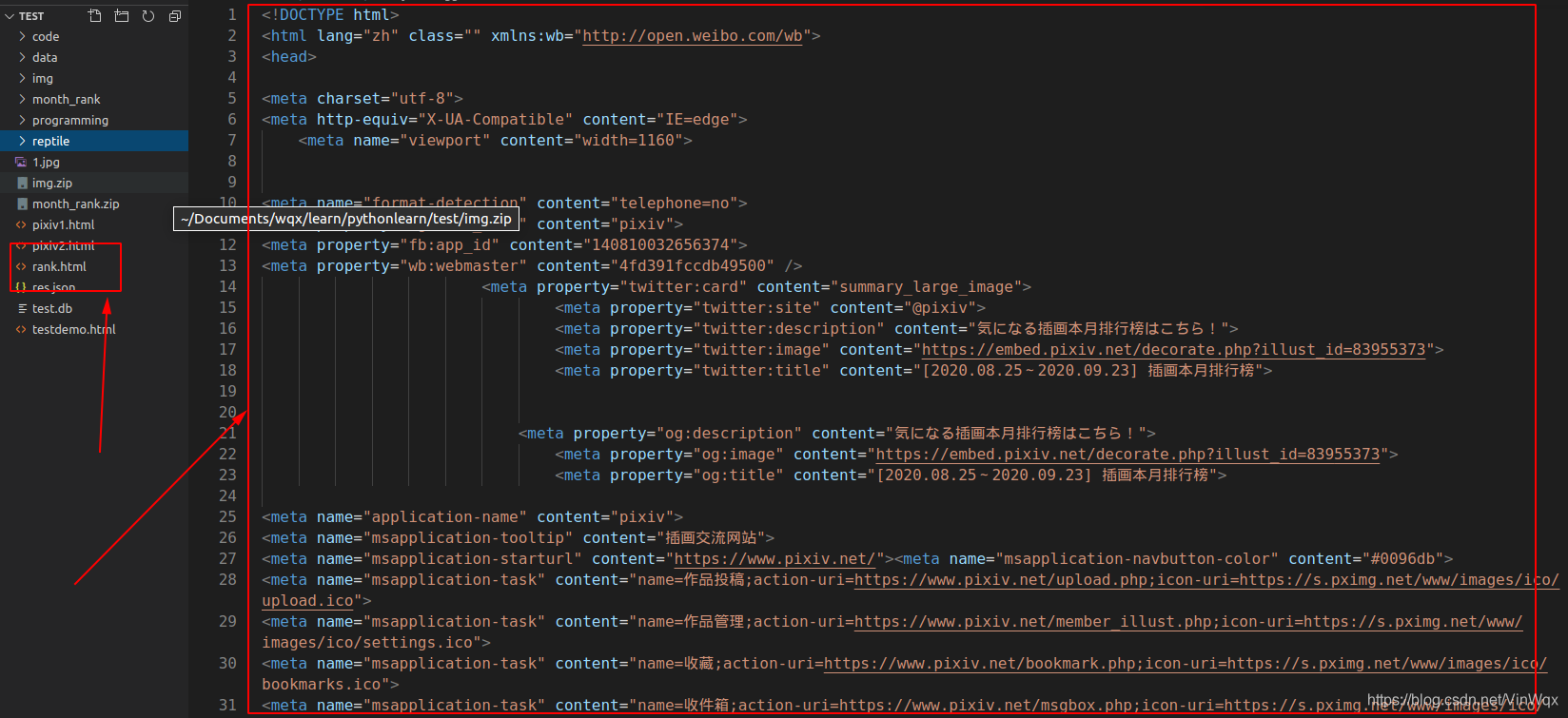
由上圖可知排行榜的資料可以直接進行存取得到。進入到rank.html檔案儲存的資料夾,選擇瀏覽器開啟rank.html檔案,顯示p站的插畫排行榜,可知p站月排行榜插畫部分的網頁內容爬取成功!
二、解析並構造資料
1、網頁解析
以上爬取p站月排行榜插畫網頁內容並下載到本地並不是本文的目的,而是開始批次爬取插畫的第一步。要批次爬取插畫,首先要對網頁本身進行分析並對爬取的網頁進行解析。使用瀏覽器開啟下載的rank.html,然後按F12鍵或者右鍵第一章圖片選擇inspect檢查網頁,可顯示如下圖資訊:

由上圖可知,所有的圖片都存放在一個class類名為`ranking-items-container`的div標籤內。每個圖片通過一個section標籤作為一個獨立的部分存放在div內,section標籤包含了該作品id、排名、標題、作者名等資訊,裡面嵌入的img標籤包含了該作品的縮圖地址(注意了!!!這是構建插畫原圖地址的關鍵部分)、作者id等資訊。這些資訊構成了所要爬取插畫的重要線索,因此需要對爬取的網頁進行解析,獲取到包含插畫資訊的所有section標籤。
網頁的解析主要有三種方式,分別是正規表示式、beautiful soup、xpath,詳細介紹與使用可以參照《python爬蟲入門總結》。xpath具有較強的通用性與高效性,這裡通過該方式對網頁進行解析,關鍵程式碼如下:
# 如果請求成功,那麼對網頁進行解析
if rank_res_code == 200:
# 獲取網頁原始內容
rank_res_text = rank_res_data.text
# 解析網頁
rank_res_etree = etree.HTML(rank_res_text)
# 獲取子標籤
rank_item_section = rank_res_etree.xpath('//div[@class="ranking-items-container"]/div/section')
2、構造資料
通過上述對網頁進行分析,img標籤裡面的data-src屬性的內容為插畫的縮圖地址,該地址包含了原圖地址的唯一的特殊子串「2020/0827/00/00/09/83955373」,通過該子串參與字串的拼接可獲得插畫的原圖地址。
由於插畫原圖作為p站的靜態資源,網站設定了referer引數,只允許存取自己的靜態資源,因此在請求插畫原圖過程中需要設定referer引數。經過分析,插畫的id參與該引數的構成,因此除了縮圖地址,還需要獲取插畫的id,section標籤重重地`data-id`便是該插畫的id。
另外,為方便儲存更多與該圖相關的資訊,獲取該插畫的標題作為圖片檔案儲存的名字,標題資訊位於section標籤中的屬性`data-title`中。下面,通過設定三個列表origin_url_list、origin_title_list、origin_id_list,分別儲存插畫原圖的地址、標題以及id資料。
具體的程式碼實現如下:
# 如果請求成功
origin_url_list = []
origin_title_list = []
origin_id_list = []
if rank_res_code == 200:
# 獲取網頁原始內容
rank_res_text = rank_res_data.text
# 解析網頁
rank_res_etree = etree.HTML(rank_res_text)
# 獲取子標籤
rank_item_section = rank_res_etree.xpath('//div[@class="ranking-items-container"]/div/section')
for section in rank_item_section:
# 獲取標題
origin_title = section.xpath('./@data-title')[0]
origin_title_list.append(origin_title)
# 獲取id
origin_id = section.xpath('./@data-id')[0]
origin_id_list.append(origin_id)
# 獲取縮圖
thumbnail_url = section.xpath('.//div[@class="_layout-thumbnail"]/img/@data-src')[0]
# 通過正規表示式擷取特殊部分
origin_url_special = re.findall('img/(.*?)_p0',thumbnail_url)[0]
# 拼接原圖url並新增到列表中
origin_url = "https://i.pximg.net/img-original/img/"+origin_url_special+"_p0.jpg"
origin_url_list.append(origin_url)
# 檢查資料構造是否正確
i = -1
for url in origin_url_list:
i = i+1
print(url)
print(origin_title_list[i])
print(origin_id_list[i])
print()
# 否則
else:
msg = "請求失敗!狀態碼為:"+str(rank_res_code)
print(msg)
結果如下圖所示,說明資料已準備好!

三、批次爬取原圖
批次爬取的核心還是資料爬取,參照上述提到的模板即可。已經獲得所有的插畫原圖資料,那麼在爬取一條資料的基礎上增加一個迴圈操作便可以實現批次爬取所有的圖片資料。程式碼實現如下:
# 如果資料夾「month_rank」不存在,那麼建立
month_rank_dir = './month_rank'
if not os.path.exists(month_rank_dir):
os.mkdir(month_rank_dir)
i = -1
for url in origin_url_list:
i = i+1
origin_url_headers = {
'referer': 'https://www.pixiv.net/artworks/%s' % origin_id_list[i],
'User-Agent':'你的user-agent',
}
origin_res = requests.get(url, headers=origin_url_headers)
# 如果請求成功,那麼儲存圖片
origin_res_code = origin_res.status_code
if origin_res_code == 200:
origin_img_name = origin_title_list[i]+".png"
with open(month_rank_dir+"/"+origin_img_name, 'wb') as fp:
fp.write(origin_res.content)
msg = origin_img_name+"下載成功!"
print(msg)
elif origin_res_code == 404:
# 重新構建圖片url
# 擷取.png之前的部分
prefix_origin_url = re.findall('(.*?).png', url)[0]
# 拼接新的url
new_origin_url = prefix_origin_url+".jpg"
# 重新新增url、title、id
origin_url_list.append(new_origin_url)
origin_title_list.append(origin_title_list[i])
origin_id_list.append(origin_id_list[i])
# 否則列印狀態碼
else:
msg = "請求 圖片"+origin_title_list[i+1]+" 失敗!狀態碼為:"+str(origin_res_code)
print(msg)執行成功後,生成month_rank資料夾,並儲存爬取的所有圖片資料,如下圖所示。至此,排行榜的插畫作品原圖爬取成功!(超高清~可以用來作電腦桌面、頭像什麼的~)

四、壓縮插畫目錄
有時候,對於下載的這些插畫可能想分享給其他人,或者傳送到其他裝置。比如使用電腦儲存了這些圖片檔案,可以換作電腦桌布等等,如果想把下載的這些插畫換作手機桌布或者微信頭像等等,那麼可以通過微信的方式傳送到手機端。但是過程中不可以傳送整個資料夾,所以要麼選擇一張一張地傳送,要麼就是將資料夾打包壓縮,這樣可以簡單方便地整體遷移到另一個裝置。總之,通過檔案壓縮的方式可以很方便地進行資料遷移與分享等等。
該部分主要涉及到檔案壓縮功能。首先需要匯入提供壓縮功能的模組zipfile,然後指定壓縮的路徑,進行壓縮操作。這裡主要用到zipfile模組的ZipFile方法。具體程式碼實現如下:
if os.path.exists(month_rank_dir):
print('正在為您壓縮...')
# 壓縮後的名字
zip_file_new = month_rank_dir+'.zip'
zip = zipfile.ZipFile(zip_file_new, 'w', zipfile.ZIP_DEFLATED)
for dir_path, dir_names, file_names in os.walk(month_rank_dir):
# 去掉目標跟路徑,只對目標資料夾下面的檔案及資料夾進行壓縮
fpath = dir_path.replace(month_rank_dir, '')
for filename in file_names:
zip.write(os.path.join(dir_path, filename), os.path.join(fpath, filename))
zip.close()
print('該目錄壓縮成功!')
else:
print('您要壓縮的目錄不存在...')執行成功在,如下圖所示在指定目錄下生成.zip壓縮檔案。打包壓縮資料夾可以對檔案很便捷地統一傳送管理,但是這裡爬取的圖片都是比較高清的原圖,一個圖片檔案就可能達到2M的大小,這樣以來,整個壓縮檔案就比較大,在傳輸的過程中需要耗費更長的時間。另外,在後文中使用郵件進行附件傳送,一般來說郵件伺服器會對郵件大小作一定的要求,如果附件超過一定的大小,那麼將會傳送失敗。因此,一個較好的方式是,將一個資料夾壓縮成多個壓縮檔案,一次傳送或者上傳多個檔案,以確保傳送的檔案尺寸在規定範圍內,該方法將在後續進行整理。

五、傳送插畫郵件
經過以上的批次爬取以及壓縮的工作,在本地可以得到一個包含所有爬取插畫原圖的壓縮包檔案。這時,通過郵箱的方式,可以在手極端開啟郵箱下載插畫壓縮檔案,也可以通過郵件方式傳送給多個好友,從而可以實現多裝置、多使用者之間共用。
該部分qq郵箱伺服器進行郵件傳送服務。要想使用該服務,需要獲取本人郵箱的授權碼,獲取方式為:qq郵箱首頁-->設定-->賬戶-->POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服務-->開啟POP3/SMTP服務-->獲取授權碼,然後儲存該授權碼,在傳送郵件時需要用到。重點關注如下圖:

在傳送插畫郵件部分,主要用到smtplib以及email兩個第三方庫。首先需要導包。
import smtplib # smtplib 用於郵件的發信動作
from email.mime.text import MIMEText # email 用於構建郵件內容
from email.header import Header # 用於構建郵件頭
from email.mime.multipart import MIMEMultipart
from email.mime.application import MIMEApplication然後需要指定傳送者的郵箱以及授權碼,接收者的郵箱列表(如果列表只有一個那麼就傳送給一個人,如果有多個就實現了同時給多人傳送郵件),附件的絕對路徑以及要使用的郵件伺服器,這裡用到的是qq郵箱伺服器。
print('開始傳送郵件...')
# 傳送者的郵箱和授權碼
from_addr = '你的郵箱'
password = '你的郵箱授權碼'
# 接收者的郵箱及名稱
to_addr = ['對方郵箱1', '對方郵箱2', ...]
# 附件
to_attachment = '插畫壓縮包的絕對路徑'
# 發信伺服器
smtp_server = 'smtp.qq.com'接下來的工作便是郵件的主體部分:正文和附件。在這一部分,需要建立一個帶附件的範例,可以對郵件的的資訊頭進行設定,比如傳送者名字、接收者名字以及郵件主題。其次新增郵件正文,比如你有什麼想對接收者說的或者有什麼需要註明的。最後建立一個MIMEApplication範例讀取要傳送的附件並新增到郵件主體中。程式碼如下:
# 建立一個帶附件的範例
msg = MIMEMultipart()
msg['From'] = Header('你的郵箱頭(可自行設定)', 'utf-8')
msg['To'] = Header(";".join(to_addr), 'utf-8')
msg['Subject'] = Header('您要的P站排行榜來咯', 'utf-8')
# 郵件正文內容
text = MIMEText('hello!附件是p站的9月排行榜,請注意查收~', 'plain', 'utf-8')
msg.attach(text)
# 郵件附件
att = MIMEApplication(open(to_attachment, 'rb').read())
# 修改附件名稱
att.add_header('Content-Disposition', 'attachment', filename="p站排行榜插畫.zip")
msg.attach(att)最後,開始傳送郵件。大致分為以下步驟:
- 連線伺服器
- 登入郵箱
- 傳送郵件
- 關閉伺服器
程式碼如下:
# 開啟發信服務,這裡使用的是加密傳輸
server = smtplib.SMTP_SSL(smtp_server)
server.connect(smtp_server,465)
# 登入發信郵箱
server.login(from_addr, password)
# 傳送郵件
server.sendmail(from_addr, to_addr, msg.as_string())
# 關閉伺服器
server.quit()
print('郵件傳送成功...')
六、完整python實現
在理解上面這些之後,在下面程式碼的基礎上,可以把其中涉及到的檔案操作以及郵件操作等部分都可以進行封裝,然後通過函數呼叫,這樣的方式應該更為通用。另外對於郵件的接收者、正文、附件等等,可以通過列表物件儲存,然後通過引數傳遞的方式進行郵件傳送。自行解決hhh~~
import requests
import pprint
from lxml import etree
import re
import os
import time
import zipfile
import smtplib # smtplib 用於郵件的發信動作
from email.mime.text import MIMEText # email 用於構建郵件內容
from email.header import Header # 用於構建郵件頭
from email.mime.multipart import MIMEMultipart
from email.mime.application import MIMEApplication
if __name__ == "__main__":
# step 1 : 獲取網頁
month_rank_url = 'https://www.pixiv.net/ranking.php?mode=monthly&content=illust'
rank_url_headers = {
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'User-Agent':'你的user-agent',
}
rank_res_data = requests.get(month_rank_url, headers=rank_url_headers)
rank_res_code = rank_res_data.status_code
origin_url_list = []
origin_title_list = []
origin_id_list = []
if rank_res_code == 200:
# step 2 : 解析網頁
# 獲取網頁原始內容
rank_res_text = rank_res_data.text
rank_res_etree = etree.HTML(rank_res_text)
# 網頁解析
rank_item_section = rank_res_etree.xpath('//div[@class="ranking-items-container"]/div/section')
for section in rank_item_section:
origin_title = section.xpath('./@data-title')[0]
origin_title_list.append(origin_title)
origin_id = section.xpath('./@data-id')[0]
origin_id_list.append(origin_id)
thumbnail_url = section.xpath('.//div[@class="_layout-thumbnail"]/img/@data-src')[0]
origin_url_special = re.findall('img/(.*?)_p0',thumbnail_url)[0]
origin_url = "https://i.pximg.net/img-original/img/"+origin_url_special+"_p0.jpg"
origin_url_list.append(origin_url)
# step 3 : 下載圖片
# 如果資料夾「month_rank」不存在,那麼建立
month_rank_dir_name = 'month_rank_new'
month_rank_dir = './'+month_rank_dir_name
if not os.path.exists(month_rank_dir):
os.mkdir(month_rank_dir)
i = -1
for url in origin_url_list:
i = i+1
origin_url_headers = {
'referer': 'https://www.pixiv.net/artworks/%s' % origin_id_list[i],
'User-Agent':'你的user-agent',
}
origin_res = requests.get(url, headers=origin_url_headers)
# 如果請求成功,那麼儲存圖片
origin_res_code = origin_res.status_code
if origin_res_code == 200:
origin_img_name = origin_title_list[i]+".png"
with open(month_rank_dir+"/"+origin_img_name, 'wb') as fp:
fp.write(origin_res.content)
msg = origin_img_name+"下載成功!"
print(msg)
elif origin_res_code == 404:
# 重新構建圖片url
prefix_origin_url = re.findall('(.*?).png', url)[0]
new_origin_url = prefix_origin_url+".jpg"
# 重新新增url、title、id
origin_url_list.append(new_origin_url)
origin_title_list.append(origin_title_list[i])
origin_id_list.append(origin_id_list[i])
else:
msg = "請求 圖片"+origin_title_list[i]+" 失敗!狀態碼為:"+str(origin_res_code)
print(msg)
# 否則
else:
msg = "請求失敗!狀態碼為:"+str(rank_res_code)
print(msg)
# step 4 : 壓縮資料夾
zip_file_new = month_rank_dir+'.zip'
if os.path.exists(month_rank_dir):
print('正在為您壓縮...')
# 壓縮後的名字
zip = zipfile.ZipFile(zip_file_new, 'w', zipfile.ZIP_DEFLATED)
for dir_path, dir_names, file_names in os.walk(month_rank_dir):
fpath = dir_path.replace(month_rank_dir, '')
for filename in file_names:
zip.write(os.path.join(dir_path, filename), os.path.join(fpath, filename))
zip.close()
print('該目錄壓縮成功!')
else:
print('您要壓縮的目錄不存在...')
# step 5 : 傳送郵件
print('開始傳送郵件...')
# 傳送者的郵箱和授權碼
from_addr = '你的郵箱'
password = '你的授權碼'
# 接收者的郵箱及名稱
to_addr = ['aaa@qq.com', 'bbb@qq.com', 'ccc@qq.com', ...]
to_attachment = '剛剛生成壓縮檔案的絕對路徑'
smtp_server = 'smtp.qq.com'
# 建立一個帶附件的範例
msg = MIMEMultipart()
msg['From'] = Header('星河Cynthia <星河Cynthia@qq.com>', 'utf-8')
msg['To'] = ";".join(to_addr)
msg['Subject'] = Header('您要的P站高清插畫來咯', 'utf-8')
# 郵件正文內容
text = MIMEText('hello!附件是爬取的p站插畫,請注意查收~', 'plain', 'utf-8')
msg.attach(text)
# 郵件附件
att = MIMEApplication(open(to_attachment, 'rb').read())\
att.add_header('Content-Disposition', 'attachment', filename="p站插畫.zip")
msg.attach(att)
# 開啟發信服務,這裡使用的是加密傳輸
server = smtplib.SMTP_SSL(smtp_server)
server.connect(smtp_server,465)
server.login(from_addr, password)
server.sendmail(from_addr, to_addr, msg.as_string())
server.quit()
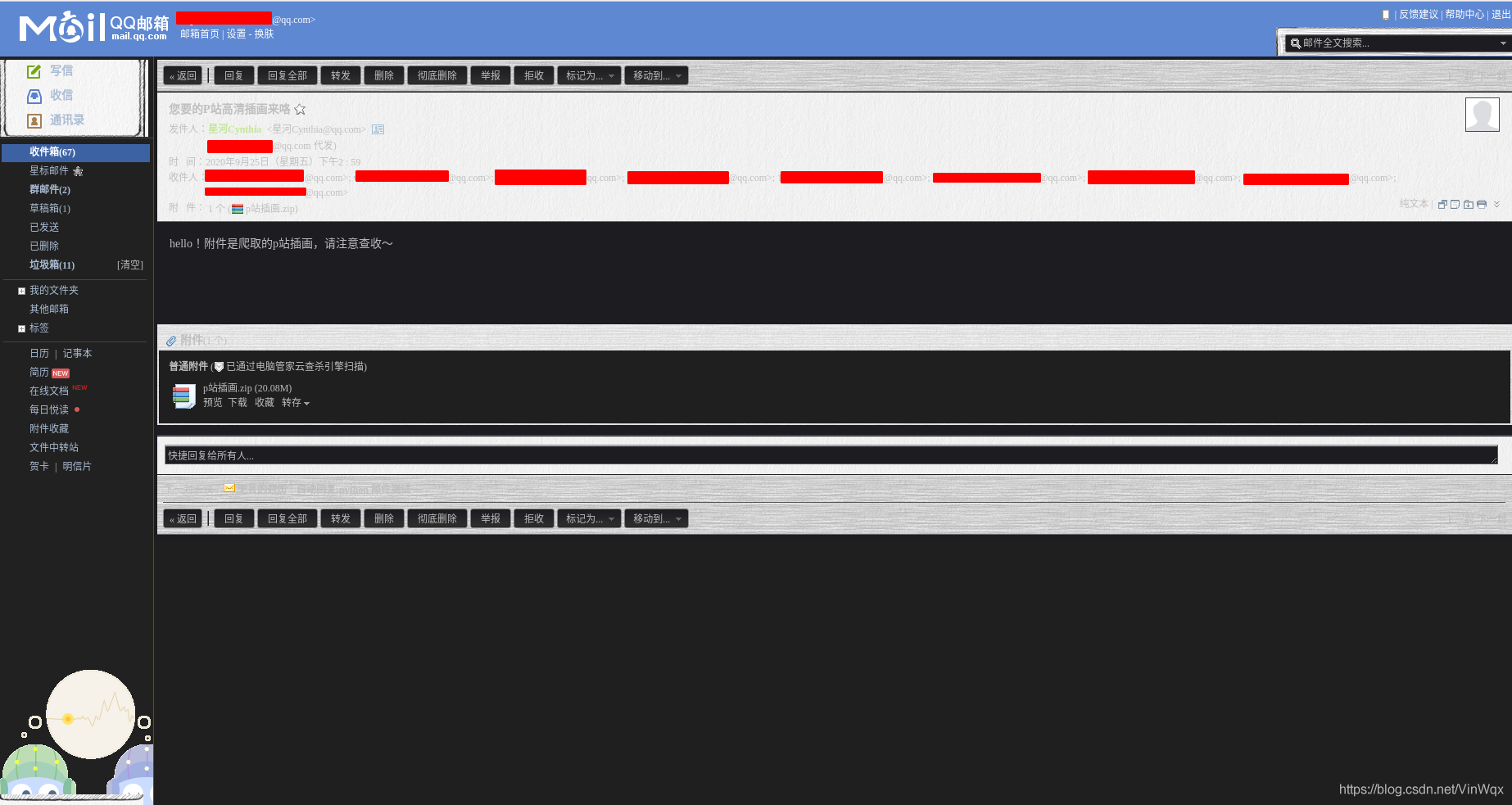
print('郵件傳送成功...')然後接收者將收到下圖這樣的郵件:
寫在最後:
1、本文的部分操作學習參考以下資料:
- 郵件部分1:菜鳥教學
- 郵件部分2:python實現自動傳送郵件
- 壓縮部分1:python壓縮資料夾
2、如果有錯誤歡迎指正~
3、幫我康康左下角的小拇指亮了沒~