用Python解決女朋友看電影沒字幕的需求
用Python解決女朋友看電影沒字幕的需求
文章目錄
一、故事情節
是這樣子的,女朋友晚上突然翻到了自己喜歡看的一個電影,但是沒有字幕,這讓她很苦惱。
我急中生智,緊急的解決了我女朋友的需求。
想到了使用Python做一個可以識別語音,然後翻譯出來文字的軟體。

如下圖就是本片文章所要完成的效果,哈哈,是不是還不錯,很棒的樣子。
如果有興趣可以給我點個贊,之後帶來更多好玩、有趣的demo和實現的教學。
《甄嬛傳》第一集的某一小段:
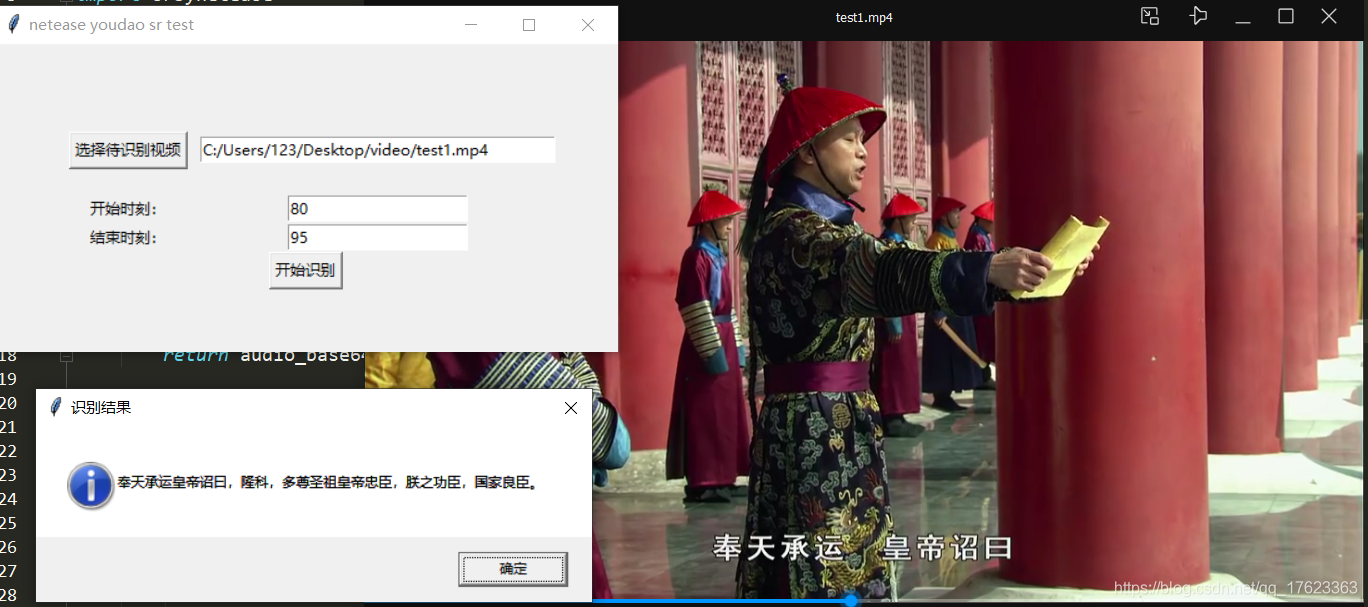
其實,是這樣子的:
最近劇荒,偶然翻出了曾經下載的電視劇回味一番,經典就是經典,不論是劇情還是臺詞,都那麼有魅力,咦?等等,臺詞,臺詞……作為一個IT從業者,我忽然靈光一現——現在語音識別技術這麼發達,能否有什麼辦法能幫我儲存下一些精彩橋段的臺詞呢?或許我也可以是個野生字幕君:p ,似乎也可以在此基礎上順手再翻譯一下個別難懂的臺詞!
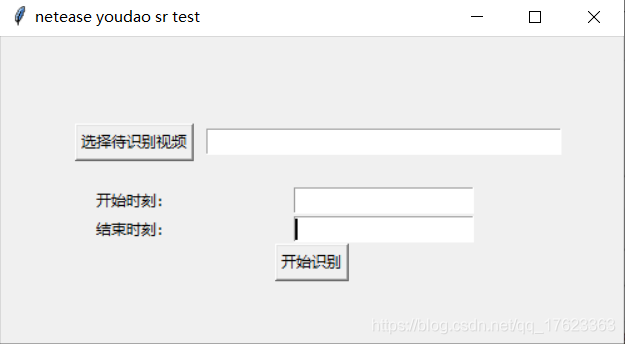
略加思索,我大概有了個想法——做個視訊中提取音訊的程式,而後去請求一個開放的語音識別API來幫我把語音轉為文字。鑑於之前呼叫有道智雲的愉快經驗,我決定再次拿來為我所用,很快做出了這個demo(請忽略這醜醜的介面佈局,能用就行……)。
歡迎關注我,一塊來履行我之前的承諾,連更一個月之內,把幾篇寫完。
| 序號 | 預計完成時間 | 開發dome名字以及功能&釋出文章內容 | 是否已寫完 | 文章連結 |
|---|---|---|---|---|
| 1 | 9月3 | 文字翻譯,單文字翻譯,批次翻譯demo。 | 已完成 | CSDN:點我直達 微信公眾號:點我直達 |
| 2 | 9月11 | OCR-demo,完成批次上傳識別;在一個demo中可選擇不同型別的OCR識別《包含手寫體/印刷體/身份證/表格/整題/名片),然後呼叫平臺能力,具體實現步驟等。 | 已完成 | CSDN:點我直達 微信公眾號: |
| 3 | 10月27 | 語音識別demo,demo中上傳—段視訊,並擷取視訊中短語音識別-demo的一段音訊進行短語音識別 | CSDN: 微信公眾號: | |
| 4 | 9月17 | 智慧語音評測-demo | CSDN: 微信公眾號: | |
| 5 | 9月24 | 作文批改-demo | CSDN: 微信公眾號: | |
| 6 | 9月30 | 語音合成-demo | CSDN: 微信公眾號: | |
| 7 | 10月15 | 單題拍搜-demo | CSDN: 微信公眾號: | |
| 8 | 10月20 | 圖片翻譯-demo | CSDN: 微信公眾號: | |
二、開發前的準備工作
首先,是需要在有道智雲的個人頁面上建立範例、建立應用、繫結應用和範例,獲取呼叫介面用到的應用的id和金鑰。具體個人註冊的過程和應用建立過程詳見文章不到100行程式碼搞定Python做OCR識別身份證,文字等各種字型
三、開發過程詳細介紹
下面介紹具體的程式碼開發過程。
(一)介面規範說明
首先分析有道智雲的API輸入輸出規範。根據檔案來看,呼叫介面格式如下:
有道語音識別API HTTPS地址:
https://openapi.youdao.com/asrapi
介面呼叫引數:
| 欄位名 | 型別 | 含義 | 必填 | 備註 |
|---|---|---|---|---|
| q | text | 要翻譯的音訊檔的Base64編碼字串 | True | 必須是Base64編碼 |
| langType | text | 源語言 | True | 支援語言 |
| appKey | text | 應用 ID | True | 可在 應用管理 檢視 |
| salt | text | UUID | True | UUID |
| curtime | text | 時間戳(秒) | true | 秒數 |
| sign | text | 簽名,通過md5(應用ID+q+salt+curTime+金鑰)生成 | True | 應用ID+q+salt+curTime+金鑰的MD5值 |
| signType | text | 簽名版本 | True | v2 |
| format | text | 語音檔案的格式,wav | true | wav |
| rate | text | 取樣率, 推薦 16000 採用率 | true | 16000 |
| channel | text | 聲道數, 僅支援單聲道,請填寫固定值1 | true | 1 |
| type | text | 上傳型別, 僅支援base64上傳,請填寫固定值1 | true | 1 |
其中q為base64編碼的待識別音訊檔,「上傳的檔案時長不能超過120s,檔案大小不能超過10M」,這點需要注意一下。
API的返回內容較為簡單:
| 欄位 | 含義 |
|---|---|
| errorCode | 識別結果錯誤碼,一定存在。 詳細資訊參加 錯誤程式碼列表 |
| result | 識別結果,識別成功一定存在 |
(二)專案開發
這個專案使用python3開發,包括maindow.py,videoprocess.py,srbynetease.py三個檔案。
介面部分,使用python自帶的tkinter庫,提供視訊檔選擇、時間輸入框和確認按鈕;
videoprocess.py:來實現在視訊的指定時間區間提取音訊和處理API返回資訊的功能;
srbynetease.py:將處理好的音訊傳送到短語音識別API並返回結果。
1、介面部分的實現
介面部分程式碼如下,比較簡單。
root=tk.Tk()
root.title("netease youdao sr test")
frm = tk.Frame(root)
frm.grid(padx='50', pady='50')
btn_get_file = tk.Button(frm, text='選擇待識別視訊', command=get_file)
btn_get_file.grid(row=0, column=0, padx='10', pady='20')
path_text = tk.Entry(frm, width='40')
path_text.grid(row=0, column=1)
start_label=tk.Label(frm,text='開始時刻:')
start_label.grid(row=1,column=0)
start_input=tk.Entry(frm)
start_input.grid(row=1,column=1)
end_label=tk.Label(frm,text='結束時刻:')
end_label.grid(row=2,column=0)
end_input=tk.Entry(frm)
end_input.grid(row=2,column=1)
sure_btn=tk.Button(frm, text='開始識別', command=start_sr)
sure_btn.grid(row=3,column=0,columnspan=3)
root.mainloop()
其中sure_btn的繫結事件start_sr()做了簡單的例外處理,並通過彈窗列印最終的識別結果:
def start_sr():
print(video.video_full_path)
if len(path_text.get())==0:
sr_result = '未選擇檔案'
else:
video.start_time = int(start_input.get())
video.end_time = int(end_input.get())
sr_result=video.do_sr()
tk.messagebox.showinfo("識別結果", sr_result)
2、處理音視訊功能開發
(1)在videoprocess.py中,我用到了python的moviepy庫來處理視訊,按指定起止時間擷取視訊,提取音訊,並按API要求轉為base64編碼形式:
def get_audio_base64(self):
video_clip=VideoFileClip(self.video_full_path).subclip(self.start_time,self.end_time)
audio=video_clip.audio
result_path=self.video_full_path.split('.')[0]+'_clip.mp3'
audio.write_audiofile(result_path)
audio_base64 = base64.b64encode(open(result_path,'rb').read()).decode('utf-8')
return audio_base64
(2)處理好的音訊檔編碼傳到封裝好的有道智雲API呼叫方法中:
def do_sr(self):
audio_base64=self.get_audio_base64()
sr_result=srbynetease.connect(audio_base64)
print(sr_result)
if sr_result['errorCode']=='0':
return sr_result['result']
else:
return "Something wrong , errorCode:"+sr_result['errorCode']
3、傳送資料翻譯功能的開發
srbynetease.py中封裝的呼叫方法比較簡單,按API檔案「組裝」好data{}傳送即可:
def connect(audio_base64):
data = {}
curtime = str(int(time.time()))
data['curtime'] = curtime
salt = str(uuid.uuid1())
signStr = APP_KEY + truncate(audio_base64) + salt + curtime + APP_SECRET
sign = encrypt(signStr)
data['appKey'] = APP_KEY
data['q'] = audio_base64
data['salt'] = salt
data['sign'] = sign
data['signType'] = "v2"
data['langType'] = 'zh-CHS'
data['rate'] = 16000
data['format'] = 'mp3'
data['channel'] = 1
data['type'] = 1
response = do_request(data)
return json.loads(str(response.content,'utf-8'))
四、效果展示
隨手開啟《甄嬛傳》第一集的某一小段試試:
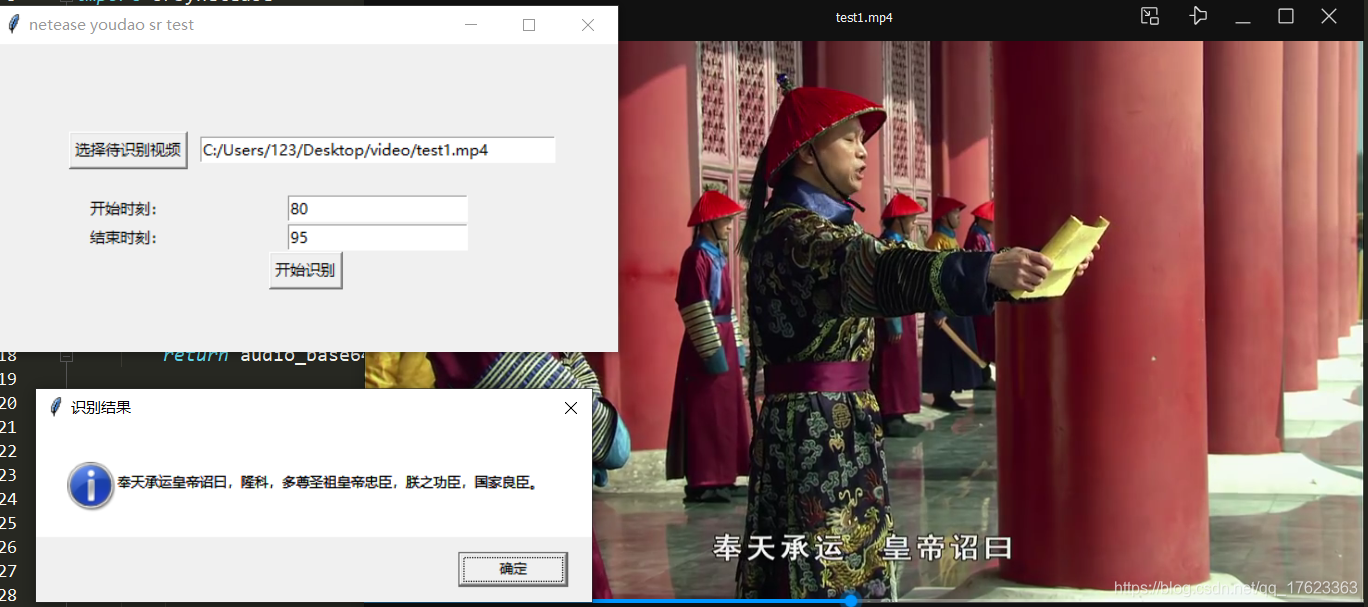
效果可以,斷句的一點小瑕疵可以忽略。沒想到這短語音識別API博古通今,古文語音識別也這麼溜,厲害厲害!
五、總結
一番嘗試帶我開啟了新世界的大門,從今天開始我可以是一個不打字卻能搬運字幕的野生字幕君了,後面再有時間可以試試識別完翻譯成其他語言的操作,嗯,是技術的力量!
專案地址:https://github.com/LemonQH/SRFromVideo
關注我微信公眾號第一時間推播給你哦:
回覆選單,更有好禮,驚喜在等著你。

快來我粉絲群:每天歡快的玩耍



