關於Windows10下Linux子系統Ubuntu的JDK環境、Hadoop環境設定以及Scala安裝中出現的問題
Windows10下Linux子系統Ubuntu的JDK環境、Hadoop環境設定以及Scala安裝中出現的問題
安裝前提:
平臺:Windows10電腦,預先下載好的Ubuntu子系統,不會下載的見教學:
Windows10使用Linux子系統
這裡我使用的是Ubuntu18.04.2
我們要開始學習巨量資料的相關內容,老師要求我們自行安裝好Linux系統下的Scala軟體並且設定好它所需要的JDK 環境和Hadoop環境。這裡我主要參考了林子雨老師的安裝教學,不得不說,林老師的安裝教學太太太太太讚了!感謝林老師!
附上林子雨老師的安裝連結:spark2.1.0入門:spark的安裝與使用
Hadoop安裝教學
注:連結的安裝教學中老師已經給出他提供的百度網路硬碟資源,包含這次教學所需要的全部安裝檔案,大家不必費心去找,再次感謝林子雨老師(太感動了)!
選擇Windows下Linux子系統的優點:沒有虛擬機器器+Ubuntu映象檔案設定那麼繁瑣,就Scala的學習還是夠用的;
但是據我下載了VirtualBox並且安裝完Ubuntu系統的室友說,按照林子雨老師的教學安裝這兩者也沒出現多大問題,想要安裝VirtualBox的同學也可一試。
教學中的步驟已經很完備,下面我主要說說我在安裝過程中出現的問題:
- 關於hadoop使用者的建立之後的登陸
由於Windows下的Ubuntu是沒有登陸介面的,所以你可以選擇在命令列中輸入以下命令:
su -l hadoop
接著就會提示讓你輸入密碼,你輸入密碼即可登陸hadoop使用者 - 安裝ssh(重頭戲來了)
Windows下的Ubuntu系統其實已經預設安裝好了老師教學中的openssh-server,因此你在執行完sudo apt-get install openssh-server命令之後,它會出現一段描述,大致意思就是你已經安裝過了;接著你輸入ssh localhost,發現出現了下面這個問題:
 ## 解決方法一:
## 解決方法一:
不用著急,這可能是你的ssh服務沒有開啟,再嘗試輸入命令sudo service ssh start開啟ssh服務,順利的話,可能會出現以下提示:
 再次輸入
再次輸入ssh localhost命令,將出現下面介面:
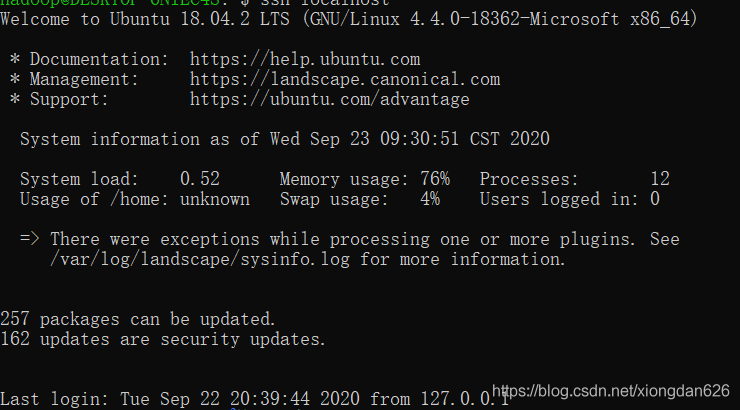 ## 解決方法二:先解除安裝它自己裝的openssh-server,然後按照教學再重新下載一個openssh-server ,接下來都按教學操作;
## 解決方法二:先解除安裝它自己裝的openssh-server,然後按照教學再重新下載一個openssh-server ,接下來都按教學操作;
在這裡小編出現了一個疑問:我安裝的時候並沒有出現ssh首次登陸提示,但我以前從沒有登陸過ssh。並且我用hadoop使用者第一次登陸的時候也沒有出現要輸入密碼的情況,有點奇奇怪怪……
- 安裝Java環境時,不知道怎麼樣把在Windows下下載的jdk解壓到Ubuntu中去:(這裡我選擇的是手動安裝的方式)
解決方法:其實很簡單,輸入命令cd /mnt(cd與/mnt中間有空格)就可以進入Windows下的目錄,然後參考老師給出的命令,即可將jdk解壓到Ubuntu的/usr/lib目錄中
用spark的壓縮包解壓過程來舉個例子:(因為我的jdk已經裝完了找不到截圖了……)
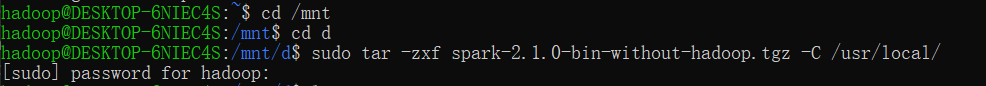 解壓之前,我們先進入你存放jdk檔案的那個目錄,我的放在D槽,因此我進入/mnt/d中,按照老師給的命令:
解壓之前,我們先進入你存放jdk檔案的那個目錄,我的放在D槽,因此我進入/mnt/d中,按照老師給的命令:sudo tar -zxf 要解壓的檔案的名字 -C 解壓後放入的目錄路徑 - 注意:我沒有設定ssh自動登陸,因此每次進入hadoop使用者登陸ssh之前,我們需要先將ssh服務開啟才能進行登陸,如果覺得麻煩可以參考
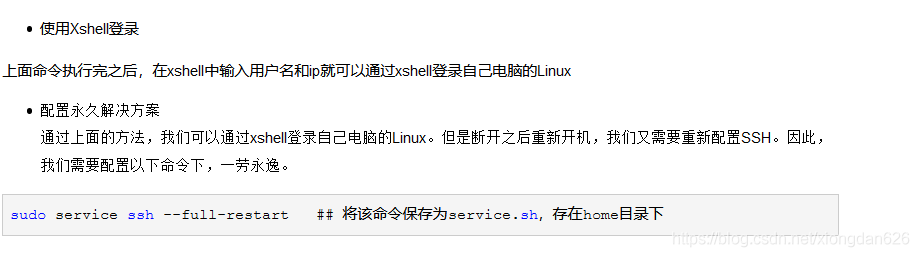 截圖來自部落格Windows10Linux子系統設定ssh
截圖來自部落格Windows10Linux子系統設定ssh
接下來按照教學,我的spark安裝沒有出現什麼問題,附上spark安裝成功之後的執行截圖
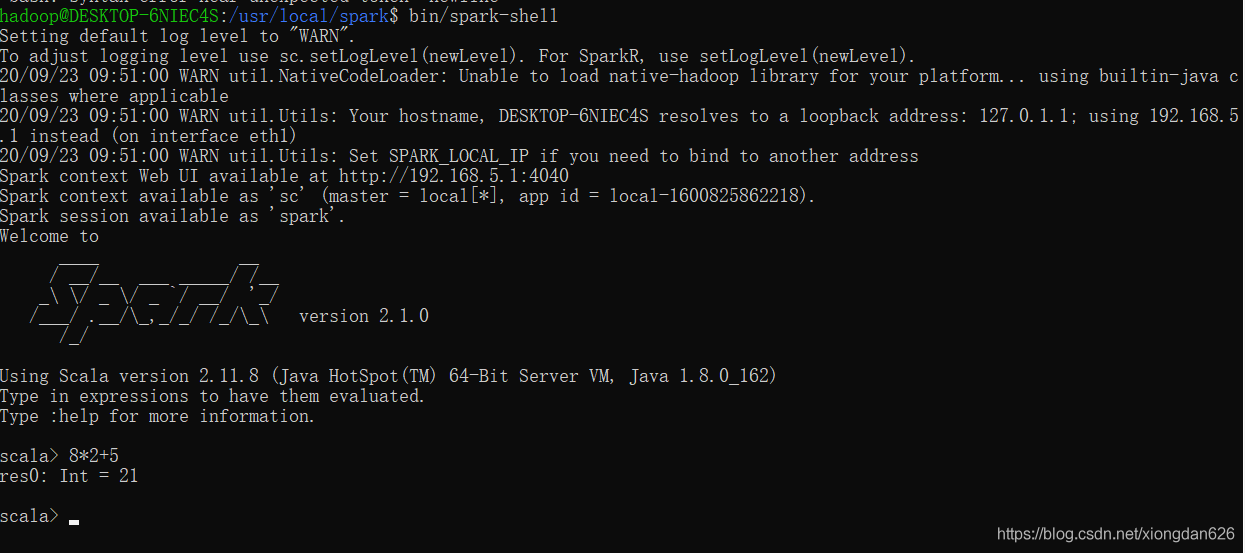
室友說,這個spark的LOGO看起來好酷好高階啊!
嘿嘿嘿,我也這麼覺得。
花了不少時間的這個環境安裝終於安裝好啦,開心!Windows下的Ubuntu在我現在這個階段還是實用的(要是不實用我也感覺不出來)。
有問題請在評論中提出,說不定我們還可以一起討論一下。
最後首尾呼應一下,再次感謝林子雨老師!我們愛您!