《面試心經》MySQL基礎
一葉障目,不見Offer
前言
MySQL 是當今後端技術的世界必不可少的一部分。幾乎所有的後端技術面試官都會圍繞 MySQL 的原理和使用對面試者進行全方位、無死角的盤問。來自 MySQL 的盤問或許會遲到,但它絕不會缺席。看著一個個自信的小眼神被面試官折磨的黯淡無光,老衲實屬不忍。在一個月黑風高的夜晚,終於下定決心,收集整理Redis面試資料,著《面試心經》系列,望能普渡眾生。
注:本篇問答基於 MySQL 8.0
面試開始
一個穿著邋里邋遢的禿頂中年人抱著一個滿是劃痕的Mac向你走來。看你著那稀疏的頭髮,心想我艹,這至少也是個高階架構師了吧。但是看過《面試心經》的我們,依然可以氣定神閒、穩如泰山

小夥子你好,看你簡歷上寫了專案中有使用MySQL,請用一句話總結一下MySQL是什麼?
這時的你心裡忍不住暗罵,頭都禿成這樣了,問的問題如此平常,就這?但是你不能表現出來。
認真回答道:MySQL是一個關係型的資料庫管理系統,由Oracle Corporation開發和維護
面試官頭也不擡,接著提問:
MySQL 索引是什麼?有什麼用?
索引(Index)是一種資料結構,可以幫助MySQL高效獲取資料
這個很好理解,假如 MySQL 是一本書,裡面的一篇篇文章就好比一條條資料,索引就是書的目錄,你若想閱讀書中的某一篇文章,你可以先翻開目錄,找到文章的頁碼,然後直接翻到相應的頁碼進行閱讀。但是,如果沒有目錄,你就得從第一頁開始,一頁一頁的往後找,一直找到你想要的那篇文章才終止查詢,進行閱讀。(如果你想閱讀的文章恰好在書的最後一頁,那你就得查詢整本書,效率可想而知)
小夥子,那你知道 MySQL 索引有哪幾種嗎 ?
一氣呵成的回答道:常見的索引有四種,分別是:PRIMARY KEY(主鍵索引),UNIQUE(唯一索引),INDEX(普通索引)和 FULLTEXT(全文索引),這幾種都是使用 B樹 實現的
最好還能簡單介紹一下這幾種索引的區別
注:B+樹是B樹的一種
如果你想要突出自己,你還可以說:另外,還有使用 R樹 實現的 空間資料型別的索引 ,MEMORY 表還支援 雜湊索引
如果你還想讓人覺得你骨骼精奇,你可以說:除此之外,MySQL還支援 多列索引、 Invisible Indexes(不可見索引)、 Descending Indexes(降序索引)
面試官緩緩擡起頭,只見他雙眼微眯,繼續發問:
你剛才提到 B樹,那你說說 B樹 平衡二元樹 有什麼區別?為什麼不用 平衡二元樹 實現索引呢
答:平衡二元樹是一種左右樹高度 ≤ 1 的二元樹,B樹是多叉樹。由於B樹每個節點可以存多個元素,所以相同資料量情況下,B樹的樹高往往要 小於 二元樹的樹高,資料檢索的速度更快
注:資料檢索總是從根節點開始,樹的高度 = 磁碟I/O的次數
使用和建立 多列索引(又稱:複合索引)時需要注意什麼?
風輕雲淡道:最左原則
最左原則:舉例來說,如果你有一個三列的索引(col1, col2, col3),則在搜尋條件是(col1),(col1, col2) 或 (col1, col2, col3)的時候,都可以走索引查詢
MySQL 事務瞭解嗎?說說它有哪些特徵
注:InnoDB支援事務,MyISAM不支援
不假思索,道:ACID,分別是 原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)、永續性(Durability)
面試官繼續追問:MySQL 事務有幾種隔離級別呢?
四種,級別從低到高分別是:讀未提交(Read uncommitted)、讀已提交(read committed)、可重複讀(repeatable read)、序列化(Serializable)
注:MySQL的預設隔離級別是 可重複讀(repeatable read)
分別解釋一下髒讀、不可重複讀、幻讀
這時你肯定暗自竊喜:「小樣兒,不怕你問,就怕你不問。老夫早就準備好了」
髒讀 是指一個事務讀取到另一個事務修改後還沒有 COMMIT 的資料;不可重複讀 是指一個事務多次讀取同一資料,在多次讀取之間有另外的事務對這一資料進行修改並 COMMIT,導致多次讀取同一資料的結果不一致;幻讀 和不可重複讀類似,區別在於不可重複讀的重點是修改,幻讀的重點在於新增或者刪除
MySQL 的儲存引擎有哪些?
答:常用的有 InnoDB、MyISAM。另外還有 MEMORY、CSV、ARCHIVE等
那你說說 InnoDB 和 MyISAM 的區別
InnoDB支援事務,MyISAM不支援
InnoDB支援外來鍵,MyISAM不支援
InnoDB是聚簇索引 ,MyISAM是非聚簇索引。(聚簇索引 ≠ 主鍵)
MyISAM儲存表總行數,InnoDB 不儲存
InnoDB最小的鎖粒度是行鎖,MyISAM 最小的鎖粒度是表鎖
面試官微微頷首,繼續道:
你剛提到聚簇索引,它是怎麼回事兒
每個InnoDB表都有一個特殊的索引,稱為 聚簇索引 ,用於儲存行資料。通常,聚簇索引 就是 主鍵索引;如果沒有為表定義主鍵,則會選擇一個 NOT NULL 的 唯一索引(UNIQUE ) 作為聚簇索引;如果符合條件的 UNIQUE 也沒有,則在InnoDB 內部生成一個隱藏的聚集索引 GEN_CLUST_INDEX
注:通常我們會為每個InnoDB表建立或選擇一個 連續自增的列 作為主鍵(如自增 id),但是嚴格來講,主鍵並不是必須的**
VARCHAR(10) 和 CHAR(10) 有什麼區別
答:VARCHAR(10) 和 CHAR(10) 都代表欄位最多可儲存10個 字元(注:這裡不是位元組),但它們被儲存和檢索的方式不同。它們的最大長度以及是否保留尾隨空格也不同。
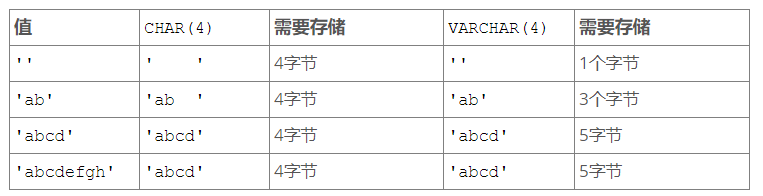
CHAR 列的長度可以是 0 到 255 之間的任何值。CHAR 儲存值時,MySQL會用空格右填充到指定的長度。當檢索CHAR列的值時,尾部填充的空格會被丟棄(如果你的資料本身尾部有空格,也會一併丟棄)。VARCHAR 列儲存可變長度的字串,最多可以儲存 65535 bytes(字元集不同,一個字元所佔的bytes可能不同),如果儲存的資料沒有達到指定的長度,並不會用空格填充。另外,VARCHAR列儲存資料時,還會額外花費1個或2個位元組,用於儲存該資料長度
如果我往 CHAR(2)列上設定值 ‘abcde’ 會怎樣?
可故作思考,答:分兩種情況,如果SQL模式設定為嚴格,不會儲存值,並丟擲錯誤。如果SQL模式設定不為嚴格,則會將值截斷儲存,並丟擲警告,例如這裡會儲存 ‘ab’
MySQL主從有了解嗎?簡要說明一下主從同步過程
主從同步的原理其實就是 基於二進位制檔案的複製,分為 同源複製 (一主多從或一主一從) 和 多源複製(多主多從),這裡以常用的一主多從為例
略微組織一下語言,娓娓道來:Master 將所有對資料的操作命令(增、刪、改)寫入binlog檔案,Slave 去讀取 Master 的 binlog檔案,然後執行。
如果有需要,你還可以稍微說詳細一點,主從複製具體步驟如下:
前置:Master 和每個 Slave 都已設定唯一的伺服器 ID(使用server_id系統變數),Master 開啟 binlog
- Master:binlog執行緒——將所有對資料的操作命令(增、刪、改)寫入 binlog 檔案
- Slave:io執行緒——在使用start slave 之後,負責從master上拉取 binlog 內容,放進 自己的 relay log 中;(每個Slave都會記錄上一次讀取的位置,所以下一次可以接著讀。這也意味著可以將多個Slave連線到Master並執行同一二進位制紀錄檔的不同部分)
- Slave:sql執行執行緒——執行 relay log 中的語句(可以將Slave設定為僅處理操作特定資料庫或表的事件)
面試官兩眼放光,嗯,這盤是撿到寶了
面試結束
小夥子挺不錯啊,這快到飯點兒了,要不咱們先去樓下餐廳邊吃邊聊吧。對了,你喜歡吃什麼?
微笑著說:榮幸之至
這可是不可多得的好機會,如果有幸遇到這種情況,大概率能夠說明面試官非常認可你了,可以趁吃飯的功夫瞭解一下公司的情況,也可以聊聊公司的技術棧以及興趣愛好,拉近彼此的距離。再不濟,也可以填飽肚子…
寫在最後
不知你會不會有那樣一種感覺,很多事情看起來很簡單,覺得自己也能做,只是懶得去做而已;很多知識點看起來自己都知道,但當面試官問的時候,你卻不能邏輯清晰且完整的做出回答,事後還覺得:這些自己都會,只是發揮不好而已…
我以前也是這樣。但我現在才明白,其實不是懶,只是不願意承認自己是個廢物而已。
Stay hungry, stay foolish
努力提升自己技術的看度和廣度,是通過面試的必要條件
平時多思考、多總結,才能在面試時侃侃而談
另外保持自信和從容,會讓你看起來更加靠譜,提升面試通過率
本文是根據平時面試的經歷,總結完善而成。由於篇幅原因,有一些回答或許不夠完美,我會在之後的文章中將面試時的常考點更加細緻的剖析。
用最樸素的語言,裝最高階的B
最後,祝大家早日上岸。咱們的口號是: 必拿下!!!
你的 點贊 和 關注 對我非常有用