Hadoop環境設定與測試
Hadoop環境設定與測試
前面的實驗我們做好了Linux環境和Hadoop環境的準備與設定工作,因此這一實驗我們在上一實驗的基礎上進行Hadoop環境的設定和測試。
Hadoop環境搭建前的Linux環境安裝與設定
https://blog.csdn.net/weixin_43640161/article/details/108614907
Linux下JDK軟體的安裝與設定
https://blog.csdn.net/weixin_43640161/article/details/108619802
掌握Linux下Eclipse軟體的安裝與設定
https://blog.csdn.net/weixin_43640161/article/details/108691921
熟悉Hadoop的下載與解壓
https://blog.csdn.net/weixin_43640161/article/details/108697510
Hadoop的安裝方式有三種,分別是單機模式,偽分散式模式,分散式模式。
• 單機模式:Hadoop 預設模式為非分散式模式(本地模式),無需進行其他設定即可執行。非分散式即單 Java 程序,方便進行偵錯。
• 偽分散式模式:Hadoop可以在單節點上以偽分散式的方式執行,Hadoop 程序以分離的 Java 程序來執行,節點既作為NameNode 也作為 DataNode,同時,讀取的是 HDFS 中的檔案。
• 分散式模式:使用多個節點構成叢集環境來執行Hadoop。
• 本實驗採取單機偽分散式模式進行安裝。
重要知識點提示:
- Hadoop 可以在單節點上以偽分散式的方式執行,Hadoop 程序以分離的 Java 程序來執行,節點既作為 NameNode 也作為 DataNode,同時,讀取的是 HDFS 中的檔案
- Hadoop 的組態檔位於 hadoop/etc/hadoop/ 中,偽分散式需要修改5個組態檔hadoop-env.sh、 core-site.xml 、 hdfs-site.xml 、mapred-site.xml和yarn-site.xml
- Hadoop的組態檔是 xml 格式,每個設定以宣告 property 的 name 和 value 的方式來實現
實驗步驟: - 修改組態檔:hadoop-env.sh、core-site.xml,hdfs-site.xml,mapred-site.xml、yarn-site.xml
- 初始化檔案系統hadoop namenode -format
- 啟動所有程序start-all.sh或者start-dfs.sh、start-yarn.sh
- 存取web介面,檢視Hadoop資訊
- 執行範例
- 停止所有範例:stop-all.sh
第一步:設定Hadoop環境(jdk版本不同,修改的內容也不同,我這裡是jdk1.8.0_181和hadoop-3.1.1)
1.設定Hadoop(偽分散式),修改其中的5個組態檔即可
-
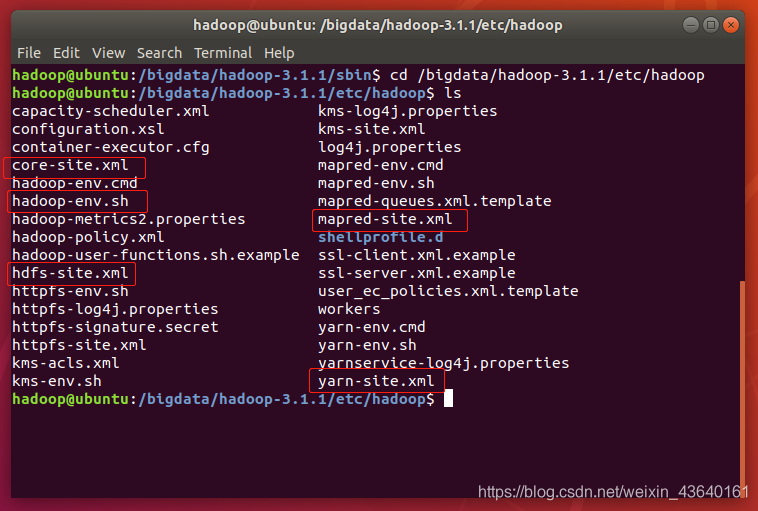
進入到Hadoop的etc目錄下
終端命令:cd /bigdata/hadoop-3.1.1/etc/hadoop
-
修改第1個設定文
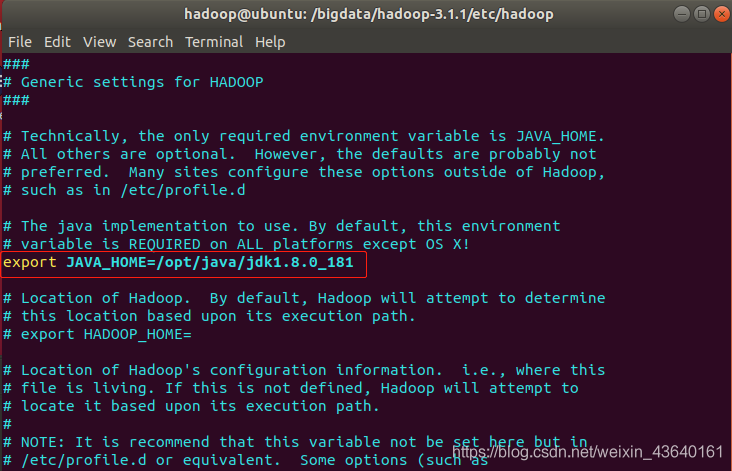
終端命令:sudo vi hadoop-env.sh

找到第54行,修改JAVA_HOME如下(記得去掉前面的 # 號):
export JAVA_HOME=/opt/java/jdk1.8.0_181
- 修改第2個組態檔
終端命令:sudo vi core-site.xml

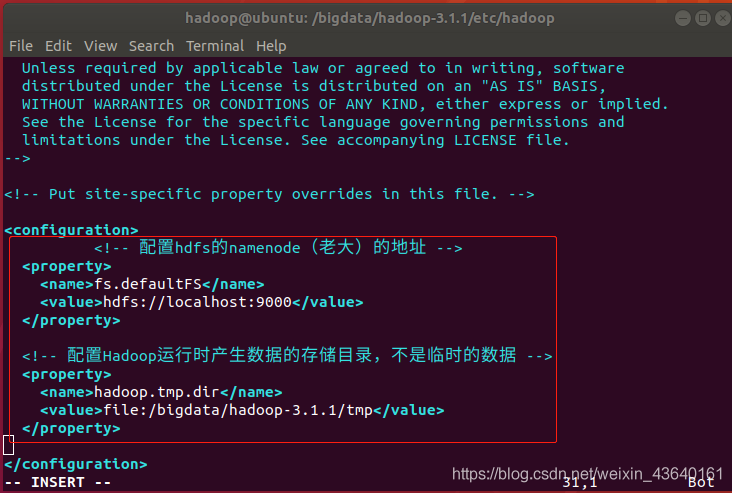
<configuration>
<!-- 設定hdfs的namenode(老大)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 設定Hadoop執行時產生資料的儲存目錄,不是臨時的資料 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/bigdata/hadoop-3.1.1/tmp</value>
</property>
</configuration>
- 修改第3個組態檔
終端命令:sudo vi hdfs-site.xml

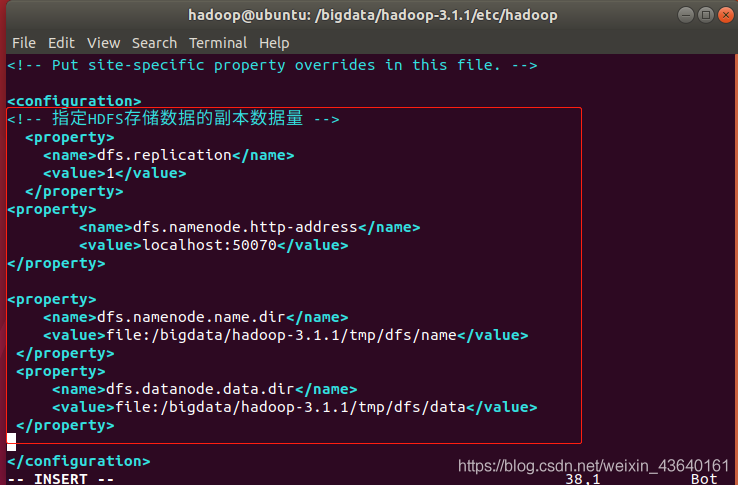
<configuration>
<!-- 指定HDFS儲存資料的副本資料量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>localhost:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/bigdata/hadoop-3.1.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/bigdata/hadoop-3.1.1/tmp/dfs/data</value>
</property>
</configuration>
此外,偽分散式雖然只需要設定 fs.defaultFS 和 dfs.replication 就可以執行(官方教學如此),不過若沒有設定 hadoop.tmp.dir 引數,則預設使用的臨時目錄為 /tmp/hadoo-hadoop,而這個目錄在重新啟動時有可能被系統清理掉,導致必須重新執行 format 才行。所以我們進行了設定,同時也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否則在接下來的步驟中可能會出錯。
- 修改第4個組態檔:
終端命令:sudo vi mapred-site.xml

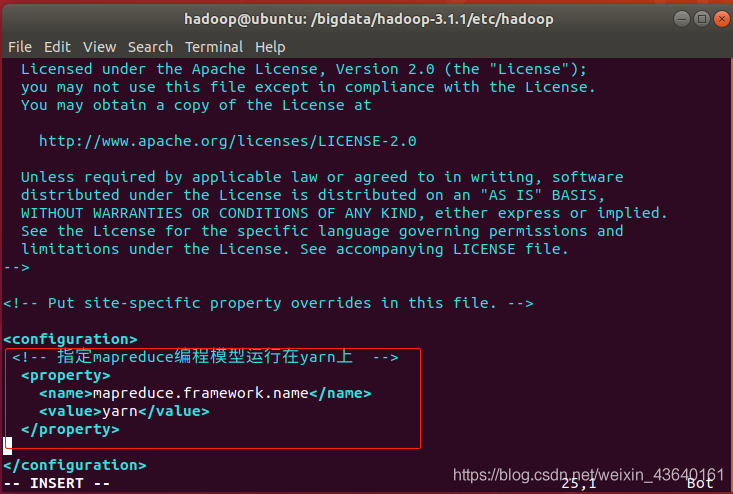
<configuration>
<!-- 指定mapreduce程式設計模型執行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 修改第5個組態檔
sudo vi yarn-site.xml

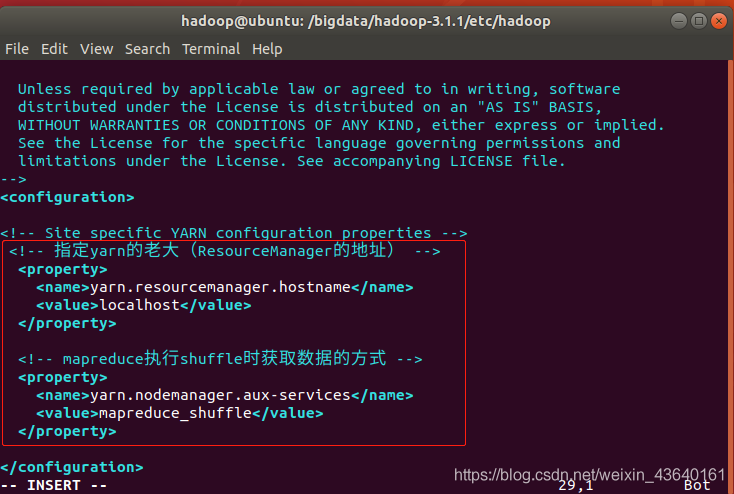
<configuration>
<!-- 指定yarn的老大(ResourceManager的地址) -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<!-- mapreduce執行shuffle時獲取資料的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
-
對hdfs進行初始化(格式化HDFS)
終端命令:
cd /bigdata/hadoop-3.1.1/bin/
sudo ./hdfs namenode -format

-
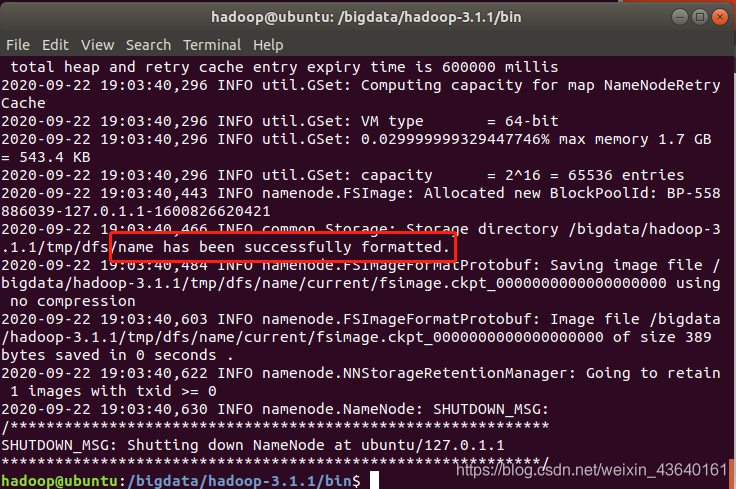
如果提示如下資訊,證明格式化成功:
第二步:啟動並測試Hadoop
終端命令:
cd /bigdata/hadoop-3.1.1/sbin/
ssh localhost
sudo ./start-dfs.sh
sudo ./start-yarn.sh
start-all.sh
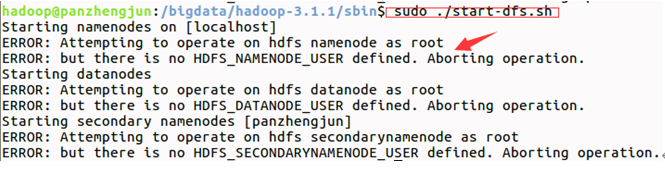
如果報以上錯誤,請修改下面4個檔案如下:
在/hadoop/sbin路徑下:
將start-dfs.sh,stop-dfs.sh兩個檔案頂部新增以下引數
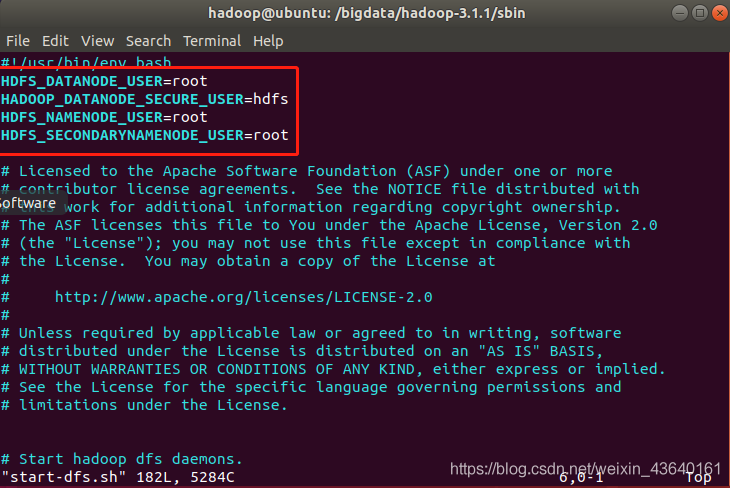
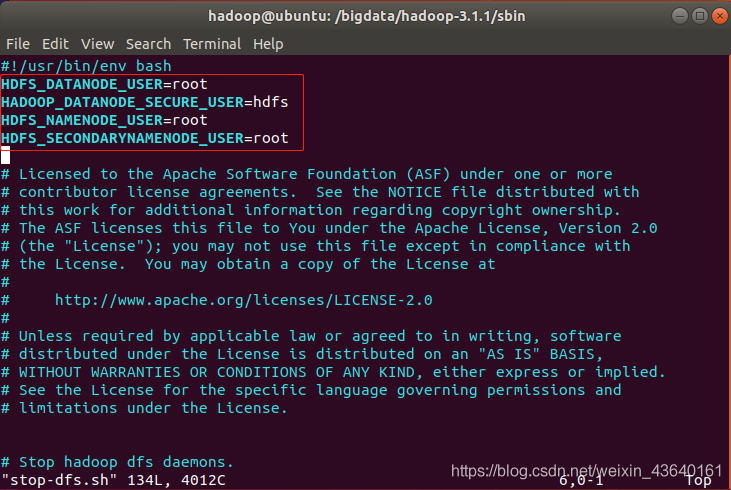
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
終端命令: sudo vi start-dfs.sh
終端命令: sudo vi stop-dfs.sh
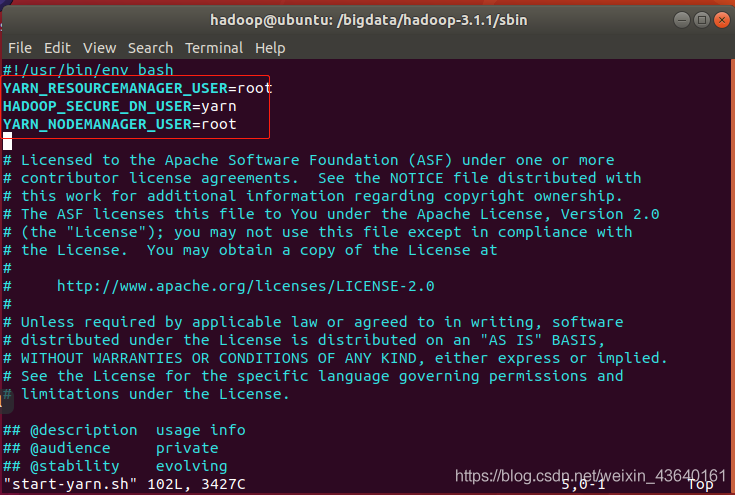
還有,start-yarn.sh,stop-yarn.sh頂部也需新增以下引數:
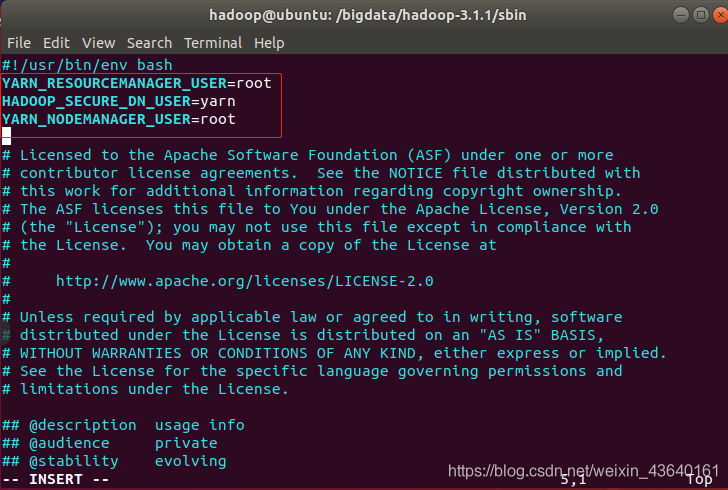
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
終端命令: sudo vi start-yarn.sh
終端命令: sudo vi start-yarn.sh
修改後重新啟動./start-all.sh,成功!
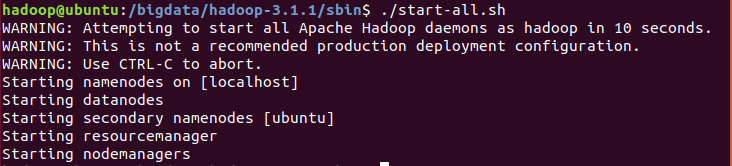
此外,如果出現以下錯誤:
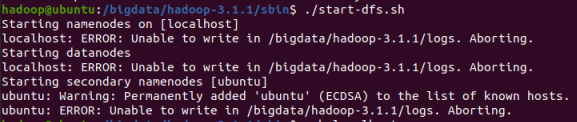
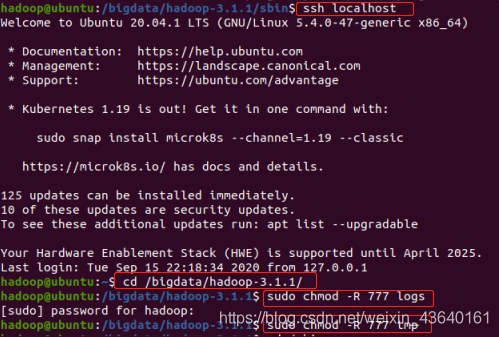
用以下方式解決:
終端命令:
ssh localhost
cd /bigdata/hadoop-3.1.1/
sudo chmod -R 777 logs
sudo chmod -R 777 tmp
-
使用jps命令檢查程序是否存在,總共5個程序(jps除外),每次重新啟動,程序ID號都會不一樣。如果要關閉可以使用 stop-all.sh命令。
4327 DataNode
4920 NodeManager
4218 NameNode
4474 SecondaryNameNode
4651 ResourceManager
5053 Jps

-
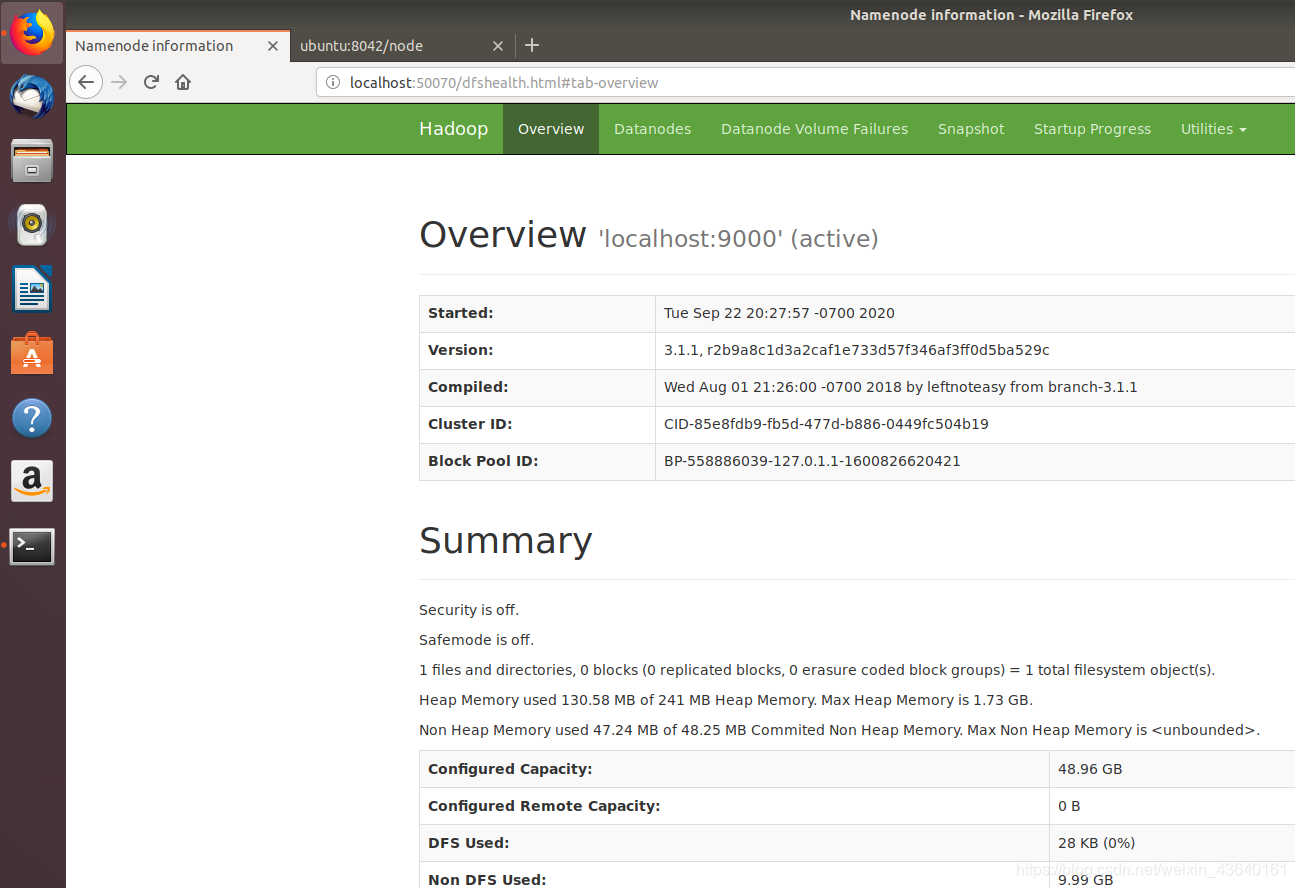
存取hdfs的管理介面
localhost:50070
-
存取yarn的管理介面
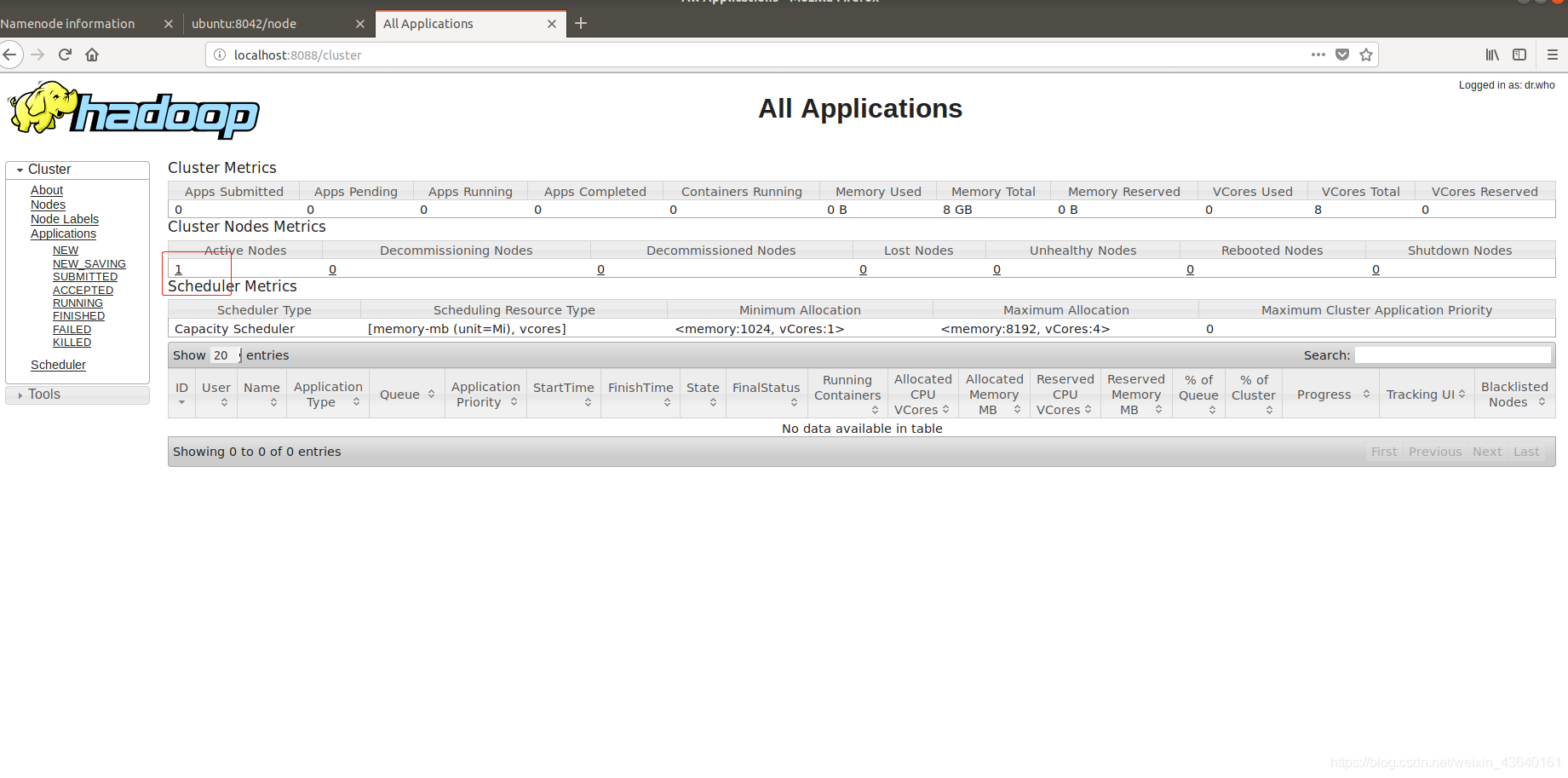
localhost:8088
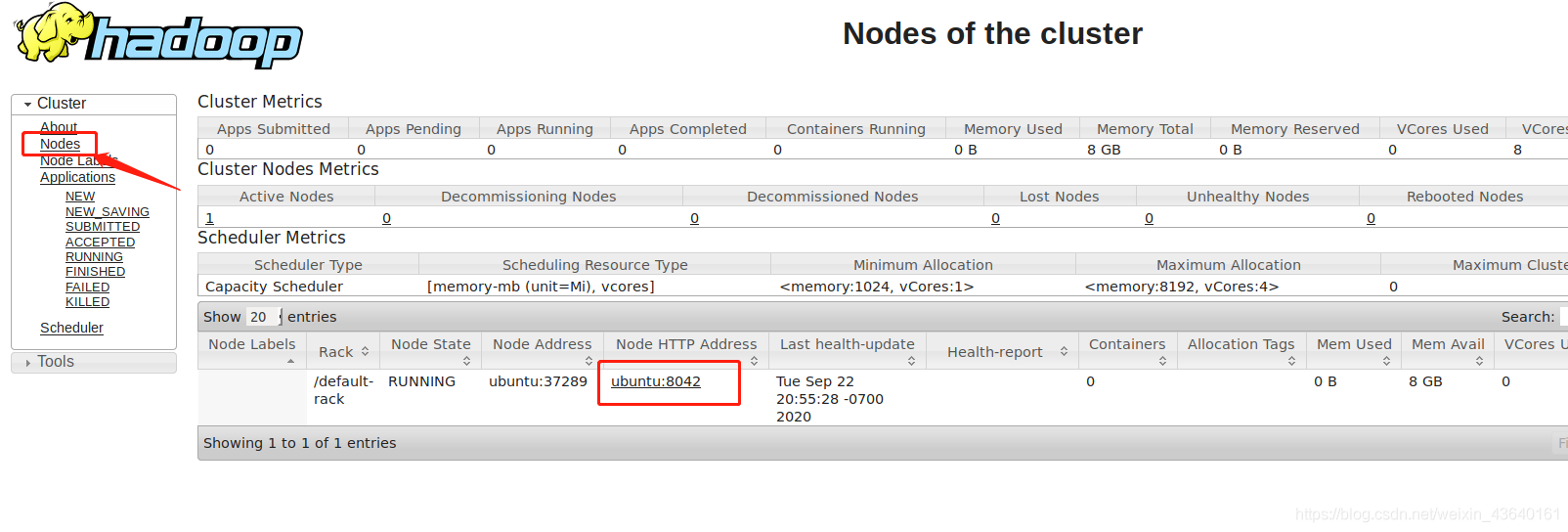
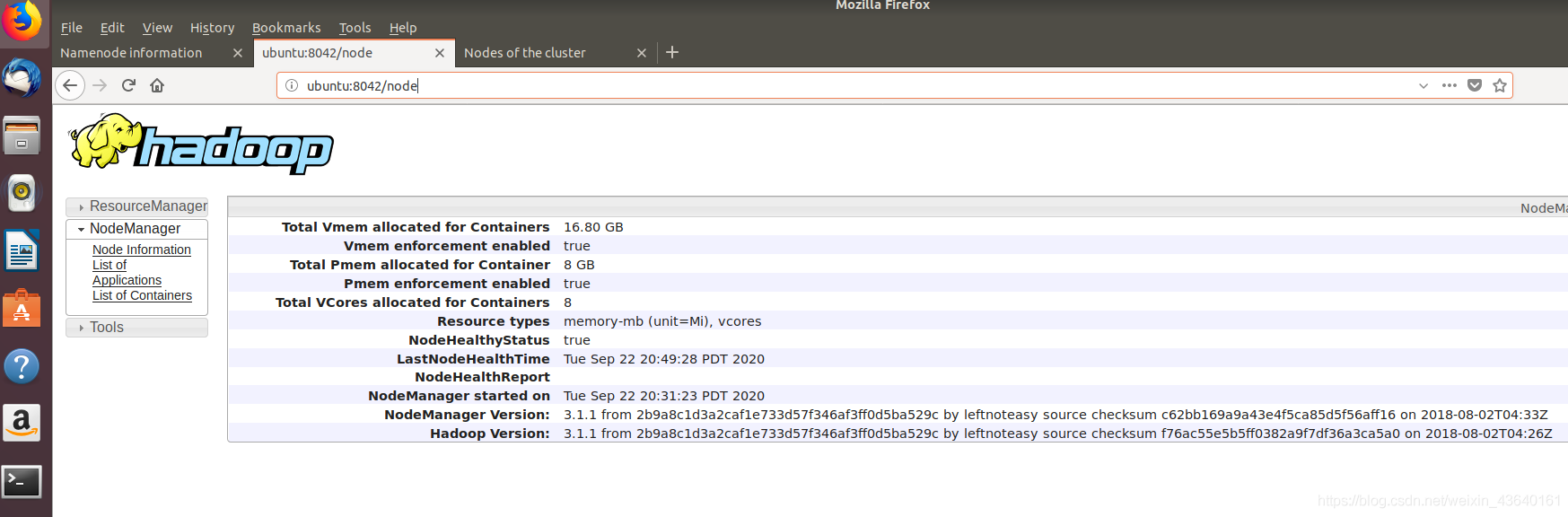
- 如果點選節點Nodes,發現ubuntu:8042也可存取
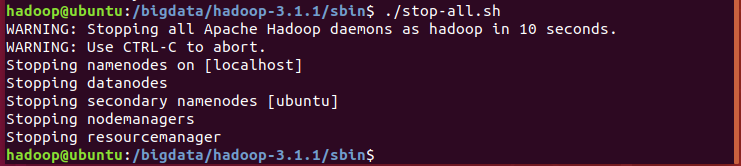
- 如果想停止所有服務,請輸入sbin/stop-all.sh
以上就是Hadoop環境設定與測試的內容,如果遇到一些奇奇怪怪的錯誤,可以在評論區留言。