從0實現python批次爬取p站插畫
一、本文編寫緣由
很久沒有寫過爬蟲,已經忘得差不多了。以爬取p站圖片為著手點,進行爬蟲複習與實踐。
二、獲取網頁原始碼
爬取網頁資料的過程主要用到request庫,一個簡單的網頁爬蟲實現過程大致可以分為一下步驟:
- 指定爬取url
- 發起爬取請求
- 儲存爬取資料
下面以爬取pixiv網站為例,獲取pixiv網站首頁原始碼並儲存到pixiv1.html檔案中。
import requests
if __name__ == "__main__":
# step 1: 爬取網頁資料
# 指定url
url = 'https://www.pixiv.net/'
# 發起請求
home_text = requests.get(url).text
# step 2: 解析爬取資料
# step 3: 儲存爬取資料
save_path = './pixiv1.html'
with open(save_path, 'w', encoding='utf-8') as fp:
fp.write(home_text)
print('下載成功!')經過上述操作,將會在當前目錄下生成一個「pixiv1.html」檔案。雙擊檔案開啟,會發現是下圖這樣子,存取該網站首先需要登入,所以會跳入到登入註冊頁面,且頁面都為日文。

針對這個問題,右鍵檢查網頁,進入network,然後重新整理頁面,發現有資料更新,點選檢視Headers。發現request headers裡面帶有cookie,因此需要偽裝UA,設定請求頭header,將request header複製到程式碼塊中。
# 指定url
url = 'https://www.pixiv.net/'
headers = {
'user-agent': '你的user-agent',
'referer':'https://www.pixiv.net/',
'sec-fetch-dest':'document',
'sec-fetch-mode':'navigate',
'sec-fetch-site':'same-origin',
'sec-fetch-user':'1',
'upgrade-insecure-requests':'1',
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'cache-control':'max-age=0',
'cookie': '你的瀏覽器cookie'
}
# 發起請求
home_text = requests.get(url, headers=headers).text再次開啟儲存的網頁檔案「pixiv2.html」,發現頁面並不像我們登入進去的一樣,而是如下圖所示。
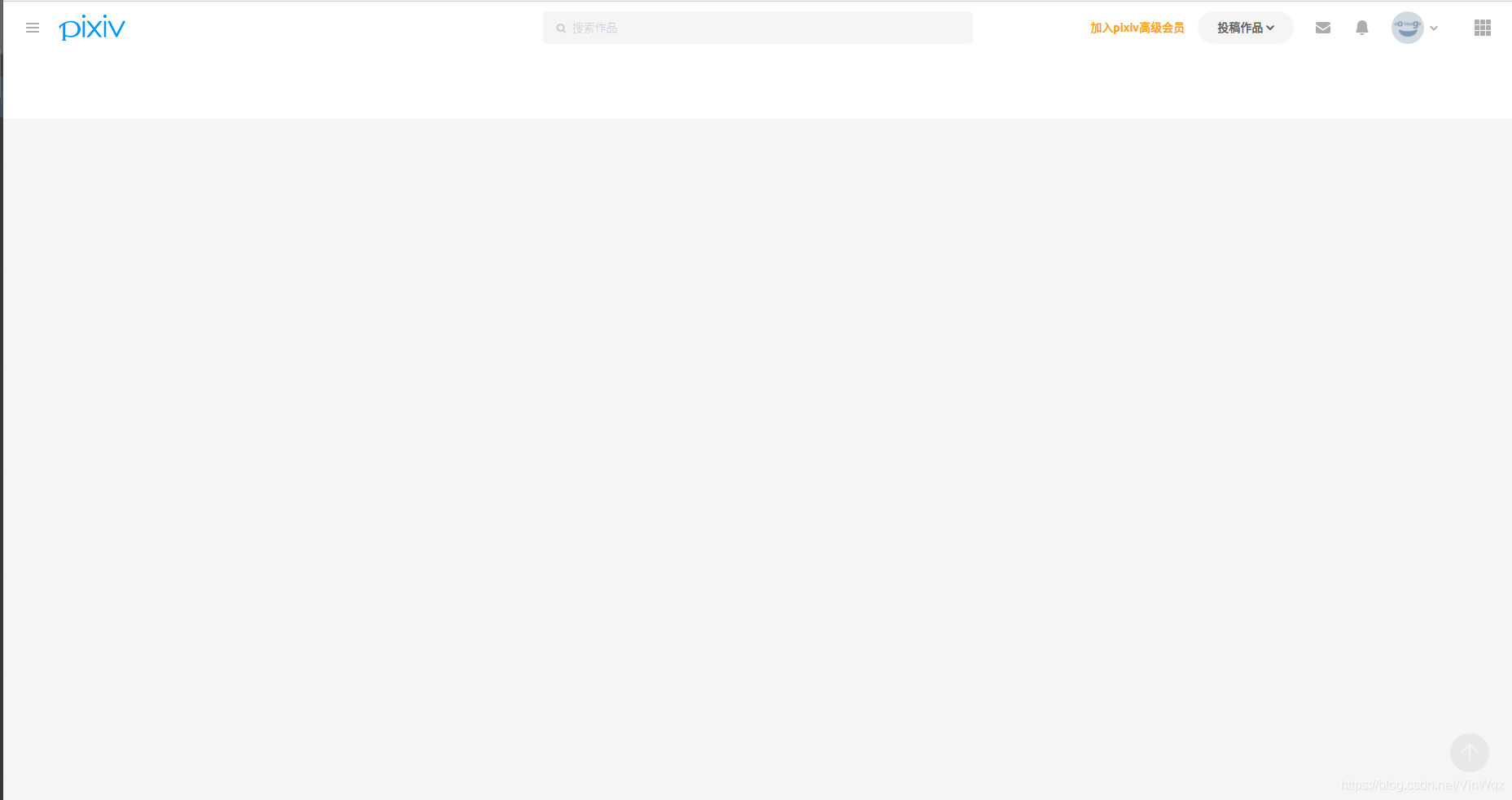
小朋友,你是不是有很多問號......
三、爬取單張縮圖片
由上一個章節可知,首頁的插畫部分並不是首頁的直接原始碼,而是引入了另外的網頁地址和指令碼。這裡,通過進入到網頁並進行分析,右鍵圖片再點選檢查獲取圖片地址,該圖片比較小,為縮圖片。複製圖片地址,並貼上到瀏覽器的位址列,可顯示圖片。

根據獲得的圖片的地址,直接對圖片地址進行存取,獲取圖片資料,並儲存到本地。
import requests
if __name__ == "__main__":
# 指定url
url = 'https://i.pximg.net/c/360x360_70/custom-thumb/img/2020/09/19/02/56/19/84460298_p0_custom1200.jpg'
# 發起請求
img_data = requests.get(url).content
# 儲存圖片
img_path = './1.jpg'
with open(img_path, 'wb') as fp:
fp.write(img_data)
print('下載成功!')於是名為「1.jpg」的圖片在當前目錄下生成,雙擊開啟發現出錯。如下圖所示。
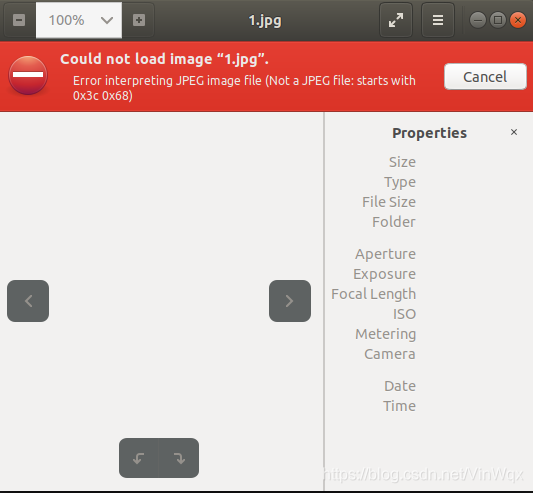
這是因為請求頭資訊缺失,需要新增請求頭,程式碼如下:
# 指定url
url = 'https://i.pximg.net/c/360x360_70/custom-thumb/img/2020/09/19/02/56/19/84460298_p0_custom1200.jpg'
# UA偽裝
headers = {
'user-agent': '你的user-agent',
'cookie': '你的瀏覽器cookie',
'referer':'https://www.pixiv.net/',
'sec-fetch-dest':'document',
'sec-fetch-mode':'navigate',
'sec-fetch-site':'same-origin',
'sec-fetch-user':'1',
'upgrade-insecure-requests':'1',
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'cache-control':'max-age=0',
}
# 發起請求
img_data = requests.get(url, headers=headers).content「1.jpg」檔案生成,雙擊可開啟,爬取單張圖片成功。
三、爬取單張高清原圖
1、獲取原圖地址
要爬取原圖,首先還是得獲取圖片地址。點選插畫的縮圖,進入插畫的詳情頁面,右鍵插畫圖片inspect網頁,如下圖所示。

點選左側圖片進入大圖預覽模式,再右鍵inspect網頁,可知右邊紅色框中a標籤的連結地址就是插畫的原圖地址。但是複製該地址到瀏覽器位址列,顯示403狀態碼。這時點選返回原始網頁中點選圖片,進入大圖模式,然後再在瀏覽器位址列複製地址檢檢視片,發現可以成功顯示圖片。
2、爬取高清原圖
import requests
if __name__ == "__main__":
# step 1: 指定url
url = 'https://i.pximg.net/img-original/img/2020/09/19/02/56/19/84460298_p0.jpg'
headers = {
'referer': 'https://www.pixiv.net/artworks/84460298',
'user-agent':'你的user-agent'
}
# step 2:發起請求
res_data = requests.get(url, headers = headers)
# step 3: 儲存資料
res_code = res_data.status_code
msg = '下載成功!'
if res_code == 200 : # 請求成功
img_data = res_data.content
# 儲存資料
img_path = './img/5.png'
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(msg)
else: # 請求失敗
msg = "下載失敗,返回狀態碼為:"+str(res_code)
print(msg)
根據上面已經獲取了原圖地址,在請求原圖的過程中需設定headers的referer引數,否則請求不成功。
對於請求,可能存在不成功的情況,可以根據返回的狀態碼進行判斷。如果狀態為200,那麼說明ok,請求成功,否則說明請求不成功,列印狀態碼資訊。
四、批次爬取高清原圖
上述爬取單張圖片相比於「」手動右鍵另存為「,實在耗時費力且非但沒有體現任何爬蟲的優勢。但是如果喜歡這個網站的大多數圖片,並希望可以全部儲存到本地,手動就太繁瑣機械了,使用爬蟲可以方便且快速地實現這個操作。
1、分析原圖地址
由上一小節可知,這裡是直接通過檢檢視片地址,然後獲取多張圖片。要獲取多張圖片,那麼一種方法是記錄下所有的圖片地址並儲存到檔案,通過讀取檔案中的圖片地址下載圖片;另一種方式是分析圖片地址的邏輯、構成、關係。顯然後者更為科學與便捷。通過右擊多張圖片,獲取如下圖片地址:
- https://i.pximg.net/img-original/img/2020/09/20/19/00/02/84495797_p0.jpg
- https://i.pximg.net/img-original/img/2020/09/19/18/00/29/84470884_p0.jpg
- https://i.pximg.net/img-original/img/2020/09/20/06/17/10/84484828_p0.png
- https://i.pximg.net/img-original/img/2020/09/19/00/00/44/84457006_p0.jpg
以第一張圖片地址為例,發現該地址前面的」https://i.pximg.net/img-original/img/「以及後面的」_p0.jpg「為公共部分,僅有中間的」2020/09/19/18/00/29/84470884「與其他圖片地址不同。
通過檢視network中XHR的Preview來檢視每條xhr資訊的主題內容,獲知以下圖片內容。
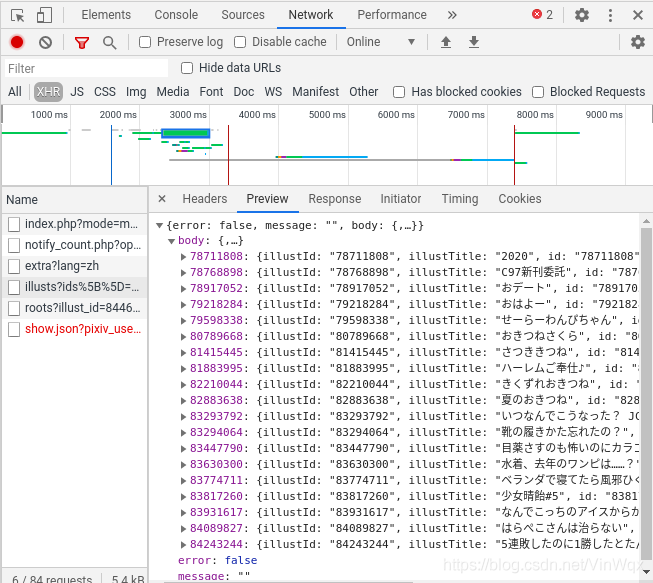
上圖中的json資料中包含了不同的圖片資訊,比如最後一條的key參與構成原圖地址和referer,且裡面url的內容為原圖的縮圖地址,具有原圖特殊部分的資訊。因此,可以通過解析該json資料來構造原圖的url。
2、構造原圖地址
首先找到該preview對應的xhr資訊,然後複製request url,進行請求存取,編碼實現如下:
import requests
import json
import pprint
if __name__ == "__main__":
# step 1: 指定url
url = 'https://www.pixiv.net/ajax/user/10797546/illusts?ids%5B%5D=84243244&ids%5B%5D=84089827&ids%5B%5D=83931617&ids%5B%5D=83817260&ids%5B%5D=83774711&ids%5B%5D=83630300&ids%5B%5D=83447790&ids%5B%5D=83294064&ids%5B%5D=83293792&ids%5B%5D=82883638&ids%5B%5D=82210044&ids%5B%5D=81883995&ids%5B%5D=81415445&ids%5B%5D=80789668&ids%5B%5D=79598338&ids%5B%5D=79218284&ids%5B%5D=78917052&ids%5B%5D=78768898&ids%5B%5D=78711808&lang=zh'
headers = {
'accept':'application/json',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'cookie':'你的cookie',
'referer': 'https://www.pixiv.net/artworks/84460298',
'sec-fetch-dest':'empty',
'sec-fetch-mode':'cors',
'sec-fetch-site':'same-origin',
'user-agent':'你的user-agent',
}
# step 2:發起請求
res_data = requests.get(url, headers = headers)
# step 3: 檢視請求結果
res_json = res_data.json()
pprint.pprint(res_json)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
由此可知,該request url就是json資料對應的介面地址,通過存取該地址,返回所需要的包含圖片資訊的json資料。
根據顯示的json資料,可知其中包含了不止一個的圖片資訊,通過解析請求結果可以構造多個圖片地址。請求結果返回的資料為字典型別的資料,真正有用到的是body中的內容。首先或許結果資料的body部分,然後通過list方法可以獲取字典所有的key,即圖片的id。通過定義兩個陣列分別為origin_url_list和origin_title_list,分別儲存所有的原圖地址和原圖名稱。通過直接取值的方式獲取圖片的title並新增到列表中,通過正規表示式解析縮圖的地址來獲取原圖中的特殊部分,然後進行字串拼接獲得原圖地址。最後可以通過列印的方式,檢查構造的資料是否正確。
# step 3: 解析json資料
res_json = json_res_data.json()
res_json_body = res_json['body'] # 獲取json中的body內容
id_list = list(res_json_body) # 獲取body中的所有的key,即圖片id
origin_url_list = [] # 儲存所有的原圖地址
origin_title_list = []
# step 4: 構造原圖地址
for item in id_list:
# 獲取title
origin_title_list.append(res_json_body[item]['title'])
# 通過獲取縮圖地址構造原圖地址
thumbnail_url = res_json_body[item]['url']
origin_specail_part = re.findall('img/(.*?)_p0',thumbnail_url)[0]
origin_url_list.append("https://i.pximg.net/img-original/img/%s_p0.jpg" % origin_specail_part)
# step 4: 列印檢視結果是否正確
i = -1
for item in origin_url_list:
# 更新索引
print(origin_title_list[i])
print(id_list)
print(item)
print()
3、批次爬取原圖
經過上述步驟,可以獲得圖片的網址、標題、referer引數涉及到的圖片id等資訊,然後根據這些資訊,發起請求存取,然後儲存圖片至本地即可。至此,批次爬取圖片成功!
import requests
import pprint
import json
import re
if __name__ == "__main__":
# step 1: 指定url
json_url = 'https://www.pixiv.net/ajax/user/10797546/illusts?ids%5B%5D=84243244&ids%5B%5D=84089827&ids%5B%5D=83931617&ids%5B%5D=83817260&ids%5B%5D=83774711&ids%5B%5D=83630300&ids%5B%5D=83447790&ids%5B%5D=83294064&ids%5B%5D=83293792&ids%5B%5D=82883638&ids%5B%5D=82210044&ids%5B%5D=81883995&ids%5B%5D=81415445&ids%5B%5D=80789668&ids%5B%5D=79598338&ids%5B%5D=79218284&ids%5B%5D=78917052&ids%5B%5D=78768898&ids%5B%5D=78711808&lang=zh'
json_url_headers = {
'accept':'application/json',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'cookie':'你的cookie',
'referer': 'https://www.pixiv.net/artworks/84460298',
'sec-fetch-dest':'empty',
'sec-fetch-mode':'cors',
'sec-fetch-site':'same-origin',
'user-agent':'你的user-agent',
'x-user-id':'你的user-id',
}
# step 2:發起請求
json_res_data = requests.get(json_url, headers = json_url_headers)
# step 3: 解析json資料
res_json = json_res_data.json()
res_json_body = res_json['body'] # 獲取json中的body內容
id_list = list(res_json_body) # 獲取body中的所有的key,即圖片id
origin_url_list = [] # 儲存所有的原圖地址
origin_title_list = []
# step 4: 構造原圖地址
for item in id_list:
# 獲取title
origin_title_list.append(res_json_body[item]['title'])
# 通過獲取縮圖地址構造原圖地址
thumbnail_url = res_json_body[item]['url']
origin_specail_part = re.findall('img/(.*?)_p0',thumbnail_url)[0]
origin_url_list.append("https://i.pximg.net/img-original/img/%s_p0.jpg" % origin_specail_part)
# step 4: 遍歷origin_url_list爬取圖片
i = -1
for item in origin_url_list:
# 更新id列表索引
i = i+1
# 獲取地址
origin_url = item
# 設定headers
origin_url_headers = {
'referer': 'https://www.pixiv.net/artworks/%s' % str(id_list[i]),
'user-agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
}
# 發起請求
img_res = requests.get(origin_url, headers=origin_url_headers)
img_res_data = img_res.content
img_res_code = img_res.status_code
if img_res_code == 200: # 如果請求成功
# 儲存圖片
img_save_name = str(origin_title_list[i])+".png"
with open("./img/"+img_save_name, 'wb') as fp:
fp.write(img_res_data)
msg = img_save_name+"儲存成功!"
print(msg)
else: # 否則輸出狀態碼
msg = "下載失敗!狀態碼為:"+ img_res_code
print(msg) 儲存結果如下圖:

寫在最後:
1、本文的圖片爬取在博主so long引導下完成,並參考了其部落格P站爬蟲,分析過程批次爬取原圖png。
2、如果讀者你覺得有幫助,可以點亮下方的小拇指,因為博主會很開心你喜歡。