爬蟲開始路線
2020-09-24 11:00:09
爬蟲之路
爬蟲的一週學習計劃:
下圖是爬蟲的準備
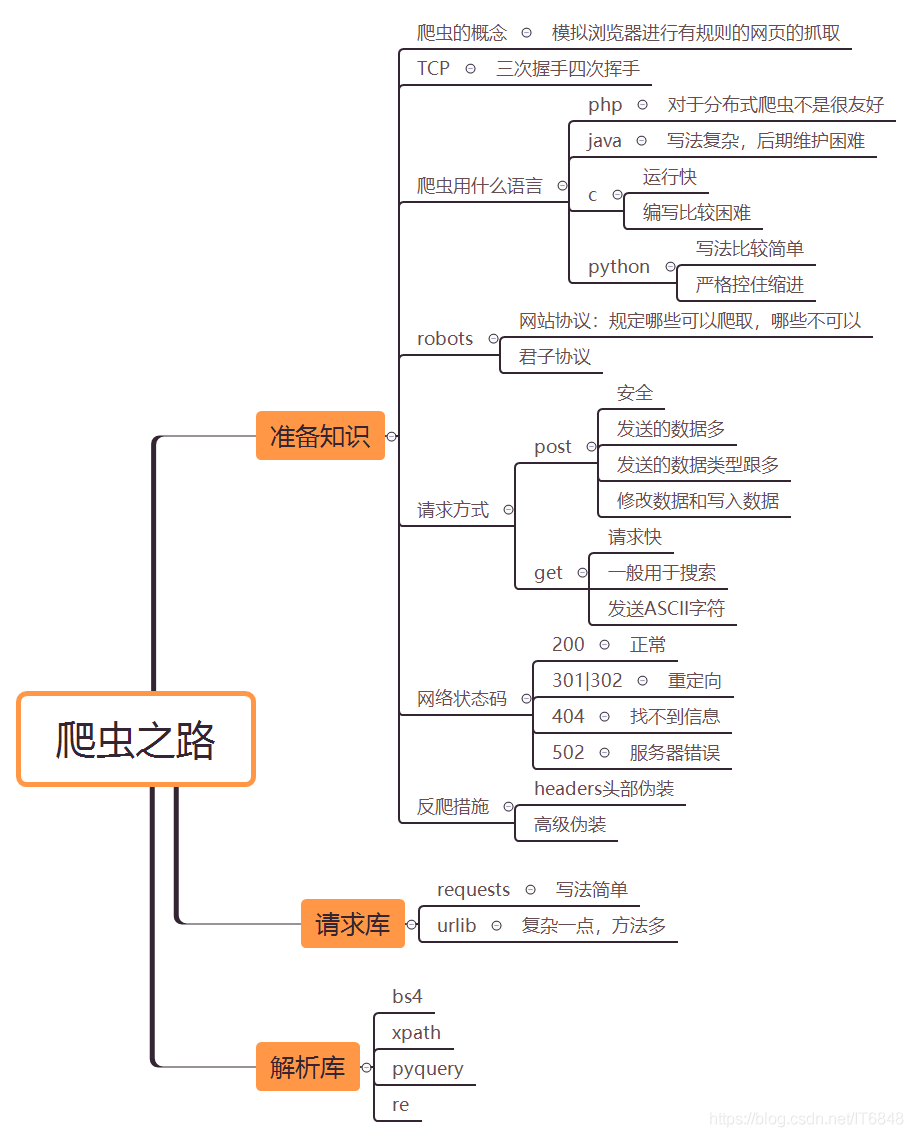
爬蟲爬取快代理案例:
網站的url=「https://www.kuaidaili.com/free/」
這次爬取我們採用的是requests第三方庫
Requests 是一個 Python 的 HTTP 使用者端庫,我們可以用它得到HTML原始碼
import requests
url="https://www.kuaidaili.com/free/"
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36"
}
#這裡進行了頭部的偽裝
res=requests.get(url,headers=headers)
res.encoding="utf-8"
html=res.text
之後我們用xpath實現標籤的遍歷獲取到我們需要的內容
e=etree.HTML(html)
ip_list=e.xpath("//tr/td[1]/text()")
port_list=e.xpath("//tr/td[2]/text()")
#採用zip迭代的方式列印輸出
for ip,port in zip(ip_list,port_list):
str="ip:"+ip+"\t埠號:"+port
print(str)
小結
本文主要講解了網路爬蟲的結構和應用,以及Python實現爬蟲的案例。希望大家對本文中的網路爬蟲工作流程和Requests實現HTTP請求的方式重點吸收消化。