【資料結構與演演算法】->演演算法-> A* 搜尋演演算法->如何實現遊戲中的尋路功能?
A* 搜尋演演算法
Ⅰ 前言
你可能玩過魔獸世界,仙劍奇俠和英雄聯盟這類 MMRPG 遊戲,在這些遊戲中,有一個非常重要的功能,就是人物角色自動尋路。當人物處於遊戲地圖中的某個位置的時候,我們用滑鼠點選另外一個相對較遠的位置,人物就會自動地繞過障礙物走過去。那麼這個功能是如何實現的呢?這篇文章我們就來探索一下這個功能。
Ⅱ 演演算法解析
實際上,這是一個非常典型的搜尋問題,人物的起點就是他當下所在的位置,終點就是滑鼠點選的位置。我們需要在地圖中,找一條從起點到終點的路徑,這條路徑要繞過地圖中所有障礙物,並且看起來要是一種非常聰明的走法。所謂聰明,籠統地解釋就是,走的路不能太繞。理論上講,最短路徑顯然是最聰明的走法,是這個問題的最優解。
但是,在前面圖的最短路徑的講解中,我說過,如果圖非常大,那 Dijkstra 最短路徑演演算法的執行耗時會很多。在真實的軟體開發中,我們面對的是超級大的地圖和海量的尋路請求,演演算法的執行效率太低,這顯然是無法接受的。
【資料結構與演演算法】->演演算法->地圖軟體的最優路線是如何計算的?
實際上,像出行路線規劃、遊戲尋路,這些真實軟體開發中的問題,一般情況下,我們都不需要非得求最優解(也就是最短路徑)。在權衡路線規劃品質和執行效率的情況下,我們只需要尋求一個次優解就足夠了。那如何快速找出一條接近於最短路線的次優路線呢?
這個快速的路徑規劃演演算法,就是我們這篇文章要講的 A 演演算法*。實際上,A* 演演算法是對 Dijkstra 演演算法的優化和改造。如何將 Dijkstra 演演算法改造成 A* 演演算法呢?我們逐步來看一下。如果你對 Dijkstra 演演算法 不熟悉,可以先跳轉到我上面連結的文章中看一下。
Dijkstra 演演算法其實是有點類似 BFS 演演算法 ,它每次找到跟起點最近的頂點,往外擴充套件。這種擴充套件的思路,其實有些盲目。為什麼盲目呢?我用下圖的例子來說明。假設下圖對應著一個真實的地圖,每個頂點在圖中的位置,我們用一個二維座標 (x, y) 來表示,其中 x,y 分別表示橫座標和縱座標。
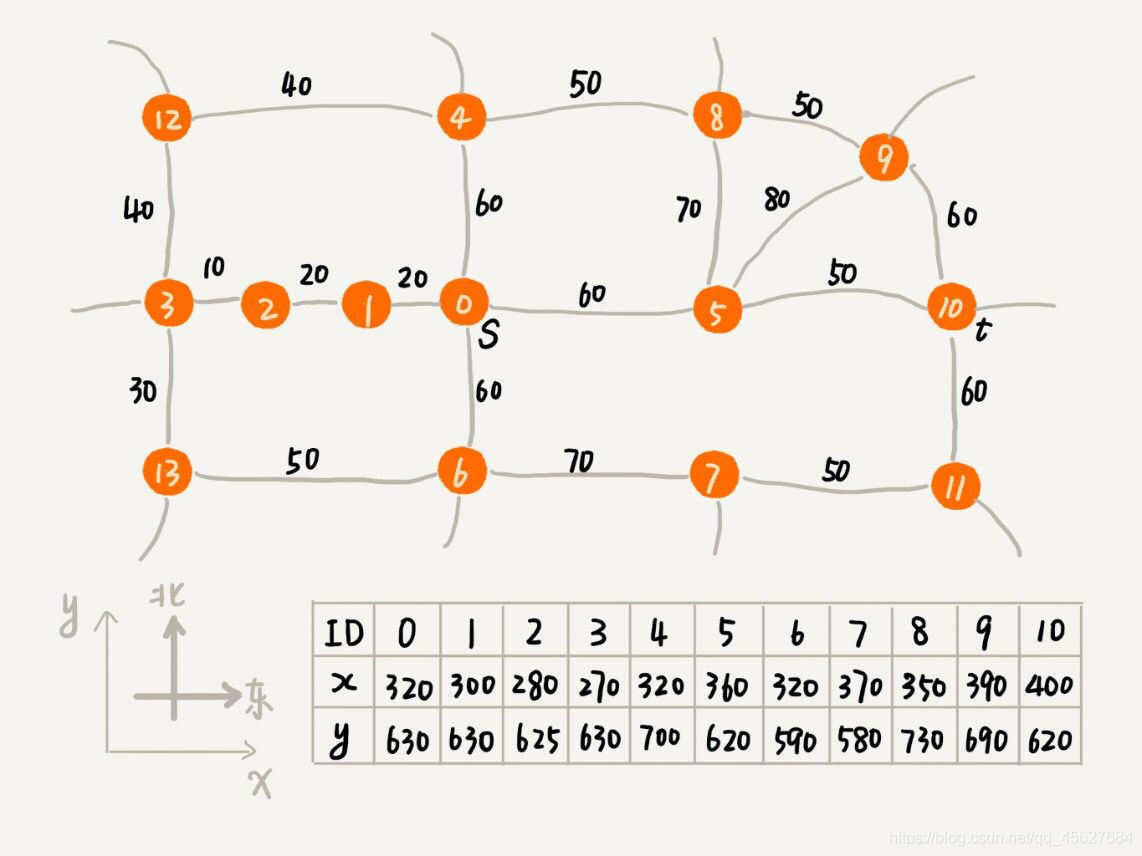
在 Dijkstra 演演算法的實現思路中,我們用一個優先順序佇列,來記錄已經遍歷到的頂點以及這個頂點與起點的路徑長度。頂點與起點路徑長度越小,就越先被從優先順序佇列中取出來擴充套件,從圖中舉的例子可以看出,儘管我們找的是從 s 到 t 的路線,但是最先被搜尋到的頂點依次是 1,2,3。通過肉眼來觀察,這個搜尋方向跟我們期望的路線方向(s 到 t 是自西向東)是反著的,路線搜尋到的方向明顯跑偏了。
之所以會跑偏,是因為我們是按照頂點與起點的路徑長度的大小,來安排出佇列順序的。與起點越近的頂點,就會越早出佇列。我們並沒有考慮到這個頂點到終點的距離,所以,在地圖中,儘管 1,2,3 三個頂點離起始頂點最近,但離終點卻越來越遠。
那麼,如果我們綜合更多的因素,把這個頂點到終點可能還要走多遠,也考慮進去,綜合來判斷哪個頂點該先出佇列,那是不是就可以避免跑偏呢?
當我們遍歷到某個頂點的時候,從起點走到這個頂點的路徑長度是確定的,我們記作 g(i) (i 表示頂點編號)。但是,從這個頂點到終點的路徑長度,我們是未知的。雖然確切的值無法提前知道,但是我們可以用其他估計值來替代。
這裡我們可以通過這個頂點跟終點之間的直線距離,也就是歐幾里得距離,來近似地估計這個頂點跟終點的路徑長度(直線距離和路徑長度不是一個概念)。我們把這個距離記作 h(i)(i 表示頂點編號),專業的叫法叫是啟發函數(heuristic function)。因為歐幾里得距離的計算公式,會涉及到比較耗時的開根號計算,所以我們一般用另外一種更加簡單的計算距離的公式,叫作曼哈頓距離(Manhattan distance)。曼哈頓距離是兩點之間橫縱座標的距離之和,計算的過程只涉及加減法和符號位反轉,所以比歐幾里得距離更加高效。
private int hManhattan(Vertex v1, Vertex v2) {
return Math.abs(v1.x - v2.x) + Math.abs(v1.y - v2.y);
}
原來只是單純地通過頂點與起點之間的路徑長度 g(i),來判斷誰先出佇列,現在有了頂點到終點的路徑長度估計值,我們通過兩者之和 f(i) = g(i) + h(i),來判斷哪個頂點該最先出佇列。綜合兩部分,我們就能有效避免前面說的跑偏。這裡 f(i) 的專業叫法叫做 估價函數(evaluation function)。
經過上面的描述,我們可以發現,A* 演演算法就是對 Dijkstra 演演算法的簡單改造。實際上,在程式碼實現上,我們也只需要改動幾個地方就可以了。
在 A* 演演算法的程式碼實現中,頂點 Vertex 類的定義,跟 Dijkstra 演演算法中的定義,稍微有點區別,多了 x, y 座標,以及剛剛提到的 f(i) 值。圖 Graph 類的定義跟 Dijkstra 演演算法中的定義一樣。我還是將完整程式碼貼出來,具體的講解大家可以看我的將 Dijkstra 演演算法的文章—— Dijkstra 演演算法 。
首先是 Vertex 頂點類
package com.tyz.astar.core;
/**
* 構造一個頂點
* @author Tong
*/
public class Vertex {
int id; //頂點編號
int distance; //從起始點到這個頂點的距離
int f; //f(i) = g(i) + h(i)
int x; //頂點在地圖中的橫座標
int y; //頂點在地圖中的縱座標
Vertex(int id, int x, int y) {
this.id = id;
this.x = x;
this.y = y;
this.f = Integer.MAX_VALUE;
this.distance = Integer.MAX_VALUE;
}
}
邊的構造
package com.tyz.astar.core;
/**
* 構造邊
* @author Tong
*/
public class Edge {
private int start; //邊的起始頂點編號
private int end; //邊的終止頂點編號
private int weight; //邊的權重
public Edge() {
}
public Edge(int start, int end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
public int getStart() {
return start;
}
public void setStart(int start) {
this.start = start;
}
public int getEnd() {
return end;
}
public void setEnd(int end) {
this.end = end;
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
}
優先順序佇列(小頂堆)
package com.tyz.astar.core;
/**
* 實現一個優先順序佇列(小頂堆)
* @author Tong
*/
class PriorityQueue {
private Vertex[] nodes;
private int count;
public PriorityQueue(int vertex) {
this.nodes = new Vertex[vertex+1];
this.count = 0;
}
/**
* 隊首元素出佇列
* @return 隊首元素
*/
Vertex poll() {
Vertex vertex = this.nodes[1];
this.nodes[1] = this.nodes[this.count--];
heapifyUpToDown(1);
return vertex;
}
/**
* 新增元素並按優先順序堆化
* @param vertex
*/
void add(Vertex vertex) {
this.nodes[++this.count] = vertex;
vertex.id = this.count;
heapifyDownToUp(count);
}
/**
* 更新佇列中元素的distance值
* @param vertex
*/
void update(Vertex vertex) {
this.nodes[vertex.id].distance = vertex.distance;
heapifyDownToUp(vertex.id);
}
boolean isEmpty() {
return this.count == 0;
}
void clear() {
this.count = 0;
}
/**
* 自上而下堆化
* @param index
*/
private void heapifyUpToDown(int index) {
while (index <= this.count) {
int maxPos = index;
if (index * 2 <= this.count &&
this.nodes[maxPos].distance > this.nodes[index*2].distance) {
maxPos = 2 * index;
} else if ((index * 2 + 1) <= count &&
this.nodes[maxPos].distance > this.nodes[index*2+1].distance) {
maxPos = index * 2 + 1;
} else if (maxPos == index) {
break;
}
swap(index, maxPos);
index = maxPos;
}
}
/**
* 自下而上堆化
* @param index
*/
private void heapifyDownToUp(int index) {
while (index / 2 > 0 &&
this.nodes[index].distance < this.nodes[index / 2].distance) {
swap(index, index / 2);
index /= 2;
}
}
/**
* 交換兩個元素對應的下標的值
* @param index
* @param maxPos
*/
private void swap(int index, int maxPos) {
this.nodes[index].id = maxPos; //下標交換記錄
this.nodes[maxPos].id = index;
Vertex temp = this.nodes[index];
this.nodes[index] = this.nodes[maxPos];
this.nodes[maxPos] = temp;
}
}
A* 演演算法的程式碼實現和 Dijkstra 演演算法的程式碼實現,主要有三點區別:
- 優先順序佇列構建的方式不同。A* 演演算法是根據 f 值(即 f(i) = g(i) + h(i) ),來構建優先順序佇列,而 Dijkstra 演演算法是根據 distance 值(也就是 g(i) )來構建優先順序佇列;
- A* 演演算法在更新頂點 distance 值的時候,會同步更新 f 值;
- 迴圈結束的條件也不一樣, Dijkstra 演演算法是在終點出佇列的時候才結束,A* 演演算法是一旦遍歷到終點就結束。
程式碼實現如下👇
package com.tyz.astar.core;
import java.util.LinkedList;
/**
* A*演演算法實現有向有權圖的兩點間路徑查詢
* @author Tong
*/
public class Graph {
private LinkedList<Edge>[] adj; //鄰接表
private int vertex; //頂點個數
private Vertex[] vertexs;
@SuppressWarnings("unchecked")
public Graph(int vertex) {
this.vertex = vertex;
this.vertexs = new Vertex[this.vertex];
this.adj = new LinkedList[vertex];
for (int i = 0; i < vertex; i++) {
this.adj[i] = new LinkedList<Edge>();
}
}
/**
* 新增頂點
* @param id
* @param x
* @param y
*/
public void addVetex(int id, int x, int y) {
this.vertexs[id] = new Vertex(id, x, y);
}
public void addEdge(int start, int end, int weight) {
this.adj[start].add(new Edge(start, end, weight));
}
/**
* 用A*演演算法求strat頂點到end頂點之間的最短距離
* @param start 起始頂點
* @param end 終止頂點
*/
public void astar(int start, int end) {
int[] predecessor = new int[this.vertex]; //用來還原最短路徑
//按照頂點的f值來構建小頂堆
PriorityQueue queue = new PriorityQueue(this.vertex); //小頂堆
boolean[] inqueue = new boolean[this.vertex];
inqueue[start] = true;
this.vertexs[start].distance = 0;
this.vertexs[start].f = 0;
queue.add(this.vertexs[start]);
inqueue[start] = true;
while (!queue.isEmpty()) {
Vertex minVertex = queue.poll(); //取堆頂元素並從佇列中將其從佇列中刪除
for (int i = 0; i < this.adj[minVertex.id].size(); i++) {
Edge edge = this.adj[minVertex.id].get(i);
Vertex nextVertex = this.vertexs[edge.getEnd()];
if (nextVertex.distance > minVertex.distance + edge.getWeight()) {
nextVertex.distance = minVertex.distance + edge.getWeight();
nextVertex.f = nextVertex.distance +
hManhattan(nextVertex, this.vertexs[end]);
predecessor[nextVertex.id] = minVertex.id;
if (inqueue[nextVertex.id] == true) {
queue.update(nextVertex);
} else {
queue.add(nextVertex);
inqueue[nextVertex.id] = true;
}
}
if (nextVertex.id == end) { //只要到達終點就可以停下了
queue.clear(); //將queue狀態變成empty才能跳出迴圈
break;
}
}
}
//輸出路徑
System.out.print(start);
print(start, end, predecessor);
}
private int hManhattan(Vertex v1, Vertex v2) {
return Math.abs(v1.x - v2.x) + Math.abs(v1.y - v2.y);
}
/**
* 遞迴列印路徑
* @param start
* @param end
* @param predecessor
*/
private void print(int start, int end, int[] predecessor) {
if (start == end) {
return;
}
print(start, predecessor[end], predecessor);
System.out.println("->" + end);
}
}
儘管 A* 演演算法可以更加快速地找到從起點到終點的路線,但是它並不是像 Dijkstra 演演算法那樣,找到最短路線,這是為什麼呢?
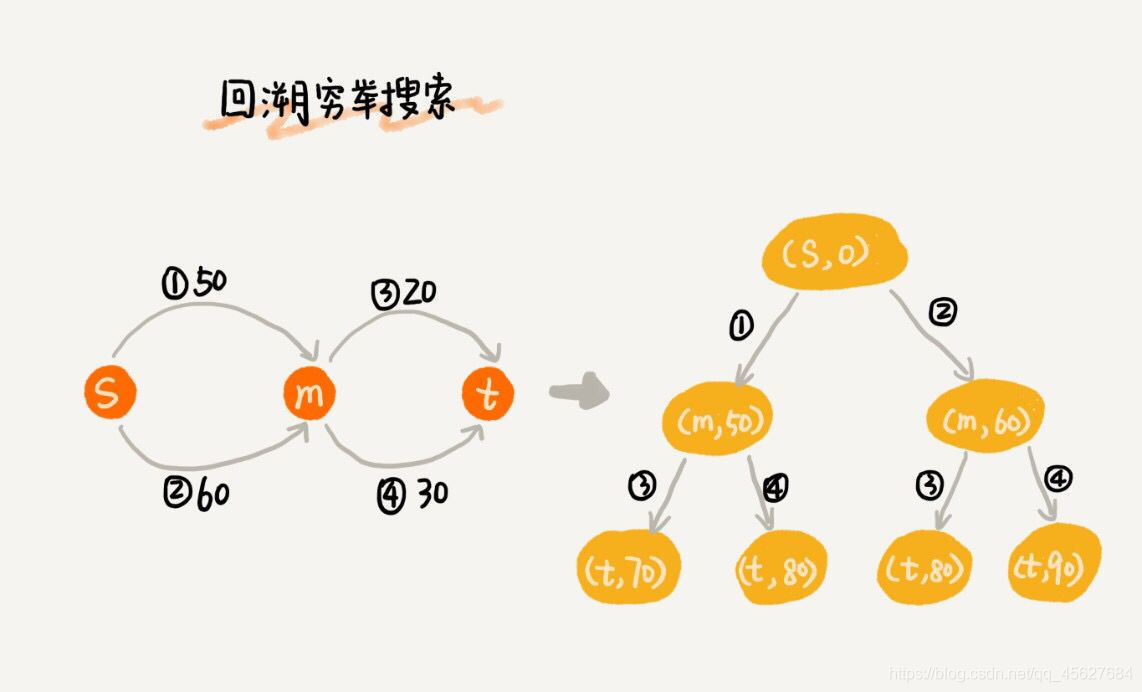
要找出起點 s 到終點 t 的最短路徑,最簡單的方法是,通過回溯窮舉所有從 s 到 t 的不同路徑,然後對比找出最短的那個。不過很顯然,回溯演演算法的執行效率非常低,是指數級的。
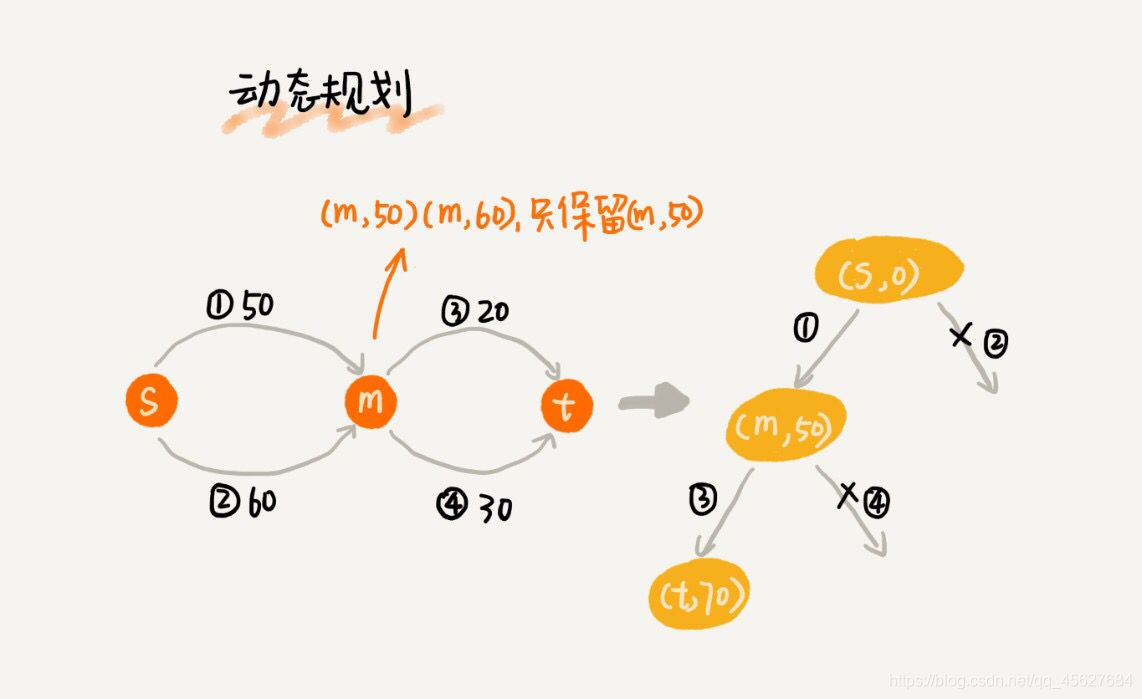
 Dijkstra 演演算法在此基礎上,利用動態規劃的思想,對回溯搜尋進行了剪枝,只保留起點到某個頂點的最短路徑,繼續往外擴充套件搜尋。動態規劃相較於回溯搜尋,只是換了一個實現思路,但它實際上也考察到了所有從起點到終點的路線,所以才能得到最優解。
Dijkstra 演演算法在此基礎上,利用動態規劃的思想,對回溯搜尋進行了剪枝,只保留起點到某個頂點的最短路徑,繼續往外擴充套件搜尋。動態規劃相較於回溯搜尋,只是換了一個實現思路,但它實際上也考察到了所有從起點到終點的路線,所以才能得到最優解。
A* 演演算法之所以不能像 Dijkstra 演演算法那樣,找到最短路徑,主要原因是兩者的 while 迴圈結束條件不一樣,前面我們說過,Dijkstra 演演算法是在終點出佇列的時候才結束,A* 演演算法是一旦遍歷到終點就結束。對於 Dijkstra 演演算法來說,當終點出佇列的時候,終點的 distance 值是優先順序佇列中所有頂點的最小值,即便再執行下去,終點的 distance 值也不會再被更新了。對於 A* 演演算法來說,一旦遍歷到終點,我們就結束 while 迴圈,這個時候,終點的 dist 值未必是最小值。
A* 演演算法利用貪婪演演算法的思路,每次都找 f 值最小的頂點出佇列,一旦搜尋到終點就不再繼續考察其他頂點和路線了。所以,它並沒有考察所有的路線,也就不可能找到最短路徑了。
Ⅲ 如何實現遊戲尋路問題
要利用 A* 演演算法解決遊戲尋路的問題,我們只需要將地圖抽象成圖就可以了。不過,遊戲中的地圖和一般的地圖是不一樣的,因為遊戲中的地圖並不像我們現實生活中那樣,存在規劃非常清晰的道路,更多的是寬闊的荒野、草坪等。所以,我們沒辦法用普通的抽象方法,把岔路口抽象成頂點,把道路抽象成邊。
實際上,我們可以換一種抽象的思路,把整個地圖分割成一個一個的小方塊。在某一個方塊上的人物,只能往上下左右四個方向的方塊上移動。我們可以把每個方塊看作一個頂點。兩個方塊相鄰,我們就在它們之間,連兩條有向邊,並且邊的權值都是 1。所以,這個問題就轉化成了,在一個有向有權圖中,找某一個頂點到另一個頂點的路徑問題。將地圖抽象成邊權值為 1 的有向圖之後,我們就可以套用 A* 演演算法,來實現遊戲中人物的自動尋路功能了。
Ⅳ 總結
這篇文章我們說的 A* 演演算法屬於一種啟發式搜尋演演算法(Heuristically Search Algorithm)。實際上,啟發式搜尋演演算法並不僅僅只有 A* 演演算法,還有很多其他演演算法,比如 IDA* 演演算法,蟻群演演算法,遺傳演演算法,模擬退火演演算法等等,大家有興趣可以再去看看。
啟發式搜尋演演算法利用估價函數,避免跑偏,貪心地朝著最有可能到達終點的方向前進。這種演演算法找出的路線,並不是最短路線,但是,實際的軟體開發中的路線規劃問題,我們往往並不需要非得找出最短路線。所以,鑑於啟發式搜尋演演算法能很好地平衡路線品質和執行效率,它在實際的軟體開發中的應用更加廣泛。