Python爬蟲,30秒爬取500+篇微信文章
2020-09-23 14:00:17
引言
由於工作需要,給公司前端做了一個小工具,使用python語言,爬取搜狗微信的微信文章,附搜狗微信官方網址
搜狗微信:https://weixin.sogou.com/
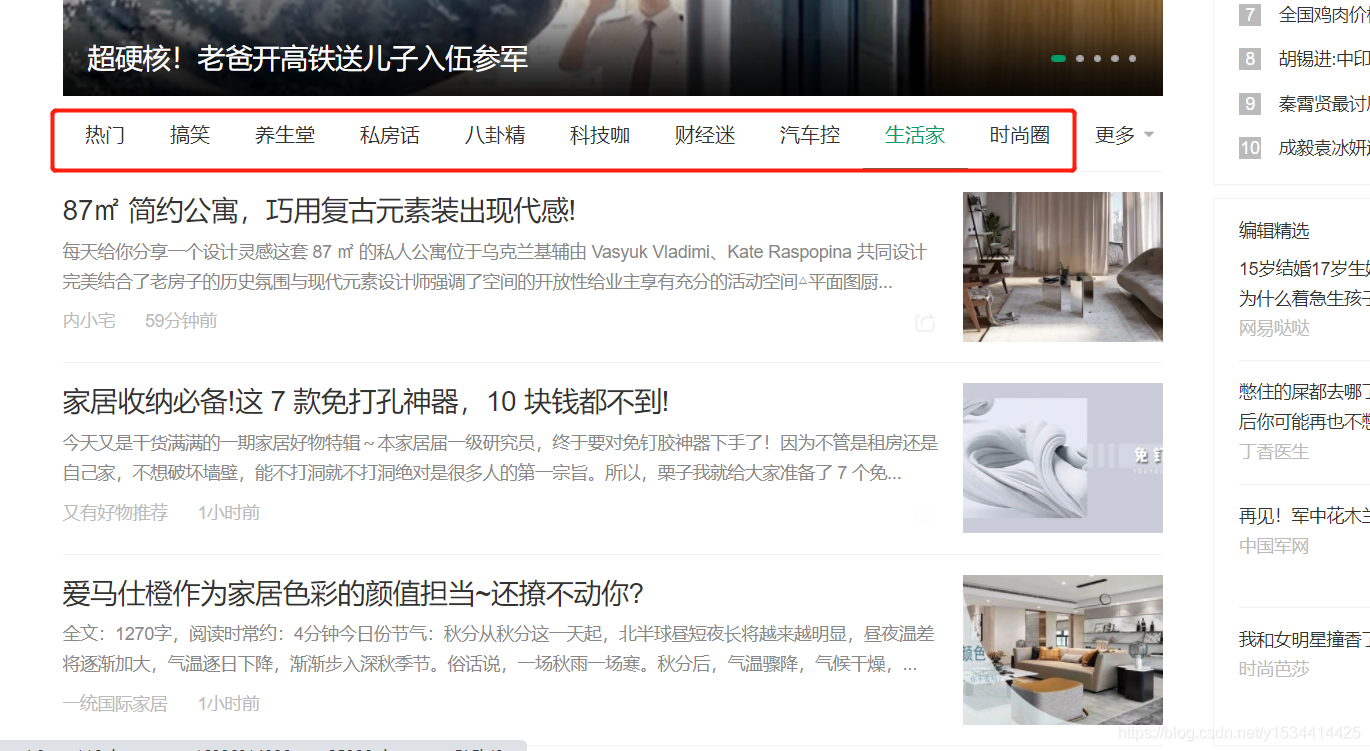
從熱門到時尚圈,並且包括每個欄目下面的額載入更多內容選項
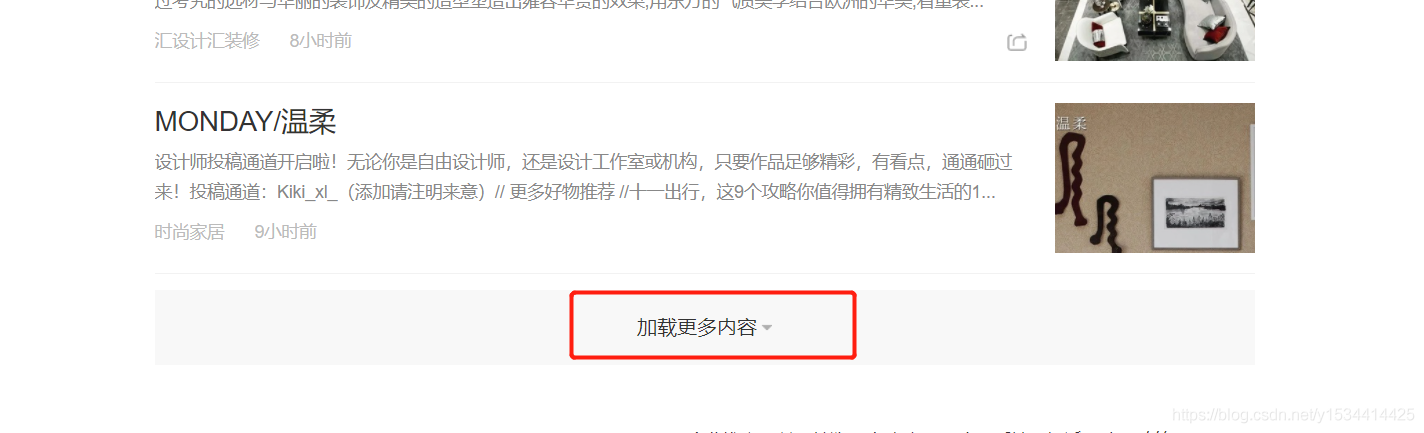
一共加起來500+篇文章
需求
爬取這些文章獲取到每篇文章的標題和右側的圖片,將爬取到的圖片以規定的命名方式輸出到規定資料夾中,並將文章標題和圖片名稱對應輸出到Excel和txt中
效果
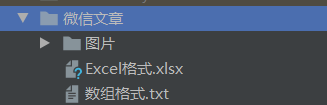
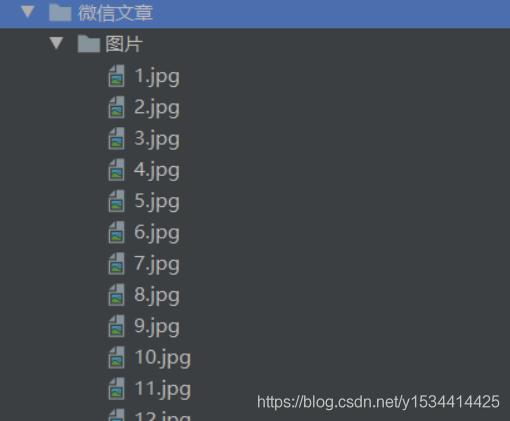
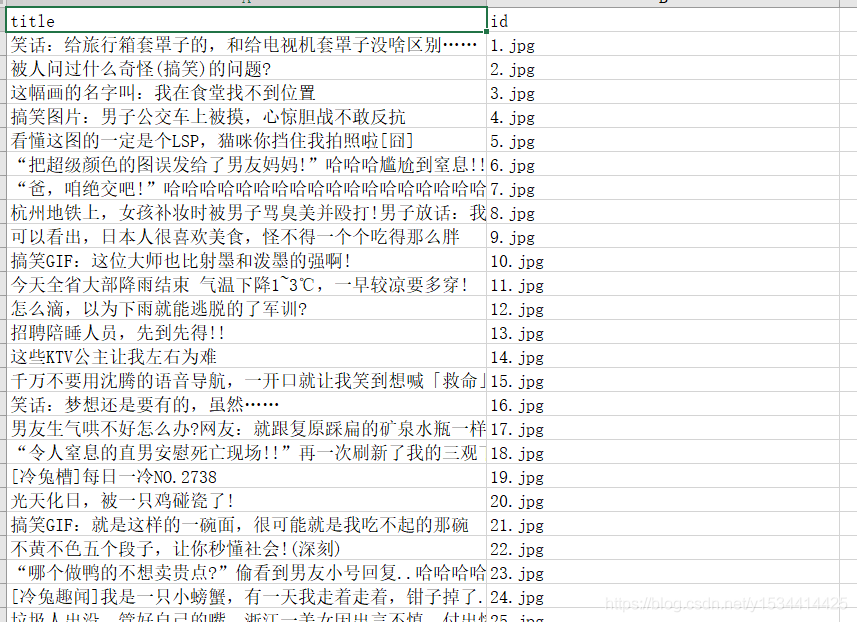

完整程式碼如下
Package Version
------------------------- ---------
altgraph 0.17
certifi 2020.6.20
chardet 3.0.4
future 0.18.2
idna 2.10
lxml 4.5.2
pefile 2019.4.18
pip 19.0.3
pyinstaller 4.0
pyinstaller-hooks-contrib 2020.8
pywin32-ctypes 0.2.0
requests 2.24.0
setuptools 40.8.0
urllib3 1.25.10
XlsxWriter 1.3.3
xlwt 1.3.0
# !/usr/bin/python
# -*- coding: UTF-8 -*-
import os
import requests
import xlsxwriter
from lxml import etree
# 請求微信文章的頭部資訊
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Host': 'weixin.sogou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
# 下載圖片的頭部資訊
headers_images = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Host': 'img01.sogoucdn.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
a = 0
all = []
# 建立根目錄
save_path = './微信文章'
folder = os.path.exists(save_path)
if not folder:
os.makedirs(save_path)
# 建立圖片資料夾
images_path = '%s/圖片' % save_path
folder = os.path.exists(images_path)
if not folder:
os.makedirs(images_path)
for i in range(1, 9):
for j in range(1, 5):
url = "https://weixin.sogou.com/pcindex/pc/pc_%d/%d.html" % (i, j)
# 請求搜狗文章的url地址
response = requests.get(url=url, headers=headers).text.encode('iso-8859-1').decode('utf-8')
# 構造了一個XPath解析物件並對HTML文字進行自動修正
html = etree.HTML(response)
# XPath使用路徑表示式來選取使用者名稱
xpath = html.xpath('/html/body/li')
for content in xpath:
# 計數
a = a + 1
# 文章標題
title = content.xpath('./div[@class="txt-box"]/h3//text()')[0]
article = {}
article['title'] = title
article['id'] = '%d.jpg' % a
all.append(article)
# 圖片路徑
path = 'http:' + content.xpath('./div[@class="img-box"]//img/@src')[0]
# 下載文章圖片
images = requests.get(url=path, headers=headers_images).content
try:
with open('%s/%d.jpg' % (images_path, a), "wb") as f:
print('正在下載第%d篇文章圖片' % a)
f.write(images)
except Exception as e:
print('下載文章圖片失敗%s' % e)
# 資訊儲存在excel中
# 建立一個workbookx
workbook = xlsxwriter.Workbook('%s/Excel格式.xlsx' % save_path)
# 建立一個worksheet
worksheet = workbook.add_worksheet()
print('正在生成Excel...')
try:
for i in range(0, len(all) + 1):
# 第一行用於寫入表頭
if i == 0:
worksheet.write(i, 0, 'title')
worksheet.write(i, 1, 'id')
continue
worksheet.write(i, 0, all[i - 1]['title'])
worksheet.write(i, 1, all[i - 1]['id'])
workbook.close()
except Exception as e:
print('生成Excel失敗%s' % e)
print("生成Excel成功")
print('正在生成txt...')
try:
with open('%s/陣列格式.txt' % save_path, "w") as f:
f.write(str(all))
except Exception as e:
print('生成txt失敗%s' % e)
print('生成txt成功')
print('共爬取%d篇文章' % a)
最後將程式打包成exe檔案,在windows系統下可以直接執行程式

點贊收藏關注,你的支援是我最大的動力!