並行程式設計——概論和背景知識
為什麼要平行計算?
為什麼要關心並行,單處理器已經足夠快了嗎?
為什麼不研製更快的單處理器系統,為什麼要研製並行系統,為什麼研製多處理器系統?
為什麼不能編寫程式,將序列程式自動轉換成可以充分使用多處理器的的並行程式?
1.1 為什麼需要不斷提升的效能
我們現在所需要考慮的問題複雜性增加,例如:氣候模擬,蛋白質摺疊,藥物發現,能源研究,資料分析等問題。需要更加強大的計算能力,普通的序列計算過於緩慢。
1.2 為什麼需要構建並行系統
單處理器效能大幅度提升到主要原因之一是日益增長的積體電路的電晶體密度。隨著尺寸的減小,處理器主頻增加,能夠提供更高的效能,但是卻導致了能耗增加 ,大量能源以熱能形式散失。而處理器等電子元件工作環境的溫度越高,其不可靠性會增加,但是當前空氣冷卻已經達到了極限。
所以如果要構造更快、更加複雜的單處理器,不如防止在一個晶片上放置多個簡單的處理器。這稱作多核處理器。
約定:本文中 核(core) 與 處理器(processer/CPU) 代表同一意思。
1.3 為什麼要編寫並行程式
1.3.1 簡介
為了達到充分利用多核處理器,使得程式更快的執行,渲染的影象更加逼真,需要將序列程式改寫為並行程式,以提高執行速度和處理器的利用率。序列程式同一時間實際上只能使用一個CPU,無法發揮多核處理器對於程式速度的提升效果,所以我們不能簡單地編寫序列程式,我們應該編寫並行程式發掘多核處理器的潛能。
對於一個序列程式:除非事先定義好的高效的全域性演演算法,編譯器很難發現一個高效的方法充分利用多核處理器。所以我們需要編寫程式,對於某一序列結構,將其進行 並行化 。但是當程式複雜性增加,這一改寫的過程會更加的複雜,追求高效的並行化將變得更加困難。
1.3.2 範例
計算n個數的值然後進行累加求和。序列程式程式碼:
sum = 0;
for(int i=0; i<n; i++)
{
x = Compute_value(i)
sum += x;
}
假設我們有p個核,且 p<<n,那麼可以將這n個資料分成p份,每個核只大約需要求n/p個值以及它們的和。
my_sum = 0;
my_first_i = ... ;
my_last_i = ... ;
for(int my_i = my_first_i; my_i < my_last_i; my_i++)
{
my_x = Compute_value(my_i)
my_sum += my_x;
}
其中my_為當前核的私有變數。
所有核完成計算之後,可以由0號核將其結果進行彙總:
if(It is core 0)
{
sum = my_sum;
for(each core other than itself)
{
value = recieve_Value_From_Cores();
sum += value
}
}
else
send_MySum();
或者是採用另一種方式彙總。每兩個核之間,由一個核進行結果相加。然後得到
⌈
p
/
2
⌉
\lceil p/2 \rceil
⌈p/2⌉個結果,反覆這一操作,得到最終結果,如下圖:
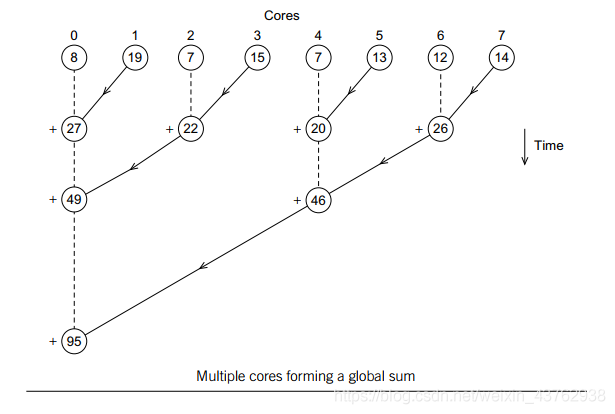
顯然,對於p個核,方法2需要進行p次操作,方法1只需要
log
2
p
\log_2 p
log2p次。
但是除非我們定義好使用方法2,一般來說,編譯器很難採用方法2而不是方法1。這就是為什麼我們需要編寫並行程式,而不能指望編譯器或者其他軟體完成這一項操作。
1.4 怎樣編寫並行程式
1.4.1 簡介
編寫並行程式,大部分的基本思想都是將任務 分配 給各個核。有兩種廣泛的方法: 任務並行 (task-parallelism) 和 資料並行 (data-parallelism)。任務並行是指將解決問題的各個任務分配到各個核上執行,每個核執行的操作不同;資料並行是將解決問題所需要處理的資料分配給各個核,每個核執行的操作大致一致。
不同的核之間的需要進行的協調包括:
- 通訊:一個或者多個核將自己的部分或全部結果傳送給其他的核。
- 負載平衡:即期望每個核分配的工作資料的數目大致相同。
- 同步:大多數系統中,核不會自動同步,而是在自己的空間內部工作。
目前,功能最強大的並行程式是通過 顯式 並行結構編寫的,即使用擴充套件C/C++ 編寫的。但是這樣的並行程式即便只是在單核處理器上執行,也會遵照並行的要求執行,比較複雜。
1.4.2 根據1.3.2範例講解
通訊: 可以看到,最終某些核需要將計算結果傳送其他核,這就是一種通訊。
負載平衡: 所有核的工作量大致相等,可以避免由於工作分配不平均導致某些核執行較快,會閒置等待其他核完成工作。
同步: 假設所有的資料不需要計算,而是從標準輸入stdin中讀入,使用0號核來初始化陣列x。那麼我們期望其他的核不會立即開始執行,而是等到0號核完成讀入資料、初始化x陣列之後才開始執行。我們期望有一個同步點,在這個點的時候核會在這裡等待,知道所有的核都到達之和才繼續執行。例如:
if(It is core 0)
for(int i=0; i<n; i++)
scanf("%d", &x[i]);
Synchronize_core(); // 同步點
Calculate(); // 計算
1.5 學習目標
學習編寫顯示並行程式。學習目標如下:
- 學會利用C語言及C原因三個擴充套件: 訊息傳遞介面 (Message-Passing Interface, MPI)、POSIX執行緒 (POSIX threads, Pthreads)、OpenMP 來編寫基本的並行程式。
這三種拓展與並行系統相關,我們關注兩種並行系統,詳細可見第二章:
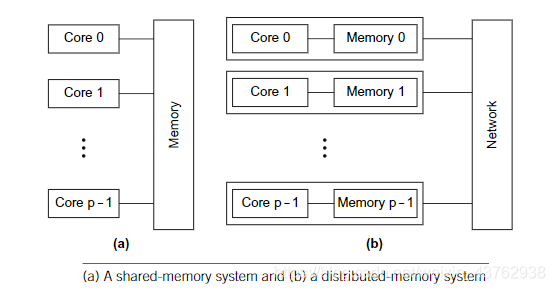
- 共用記憶體系統 (shared-memory system):每個核能夠共用存取計算機記憶體,每一個核都能夠讀寫記憶體所有區域。可以通過檢測更新共用記憶體資料來協調各個核。Pthreads和OpenMP為共用記憶體系統設計。
- 分散式記憶體系統 (distributed-memory system):每個核擁有自己的私有記憶體,核之間的通訊是顯示的,必須使用類似於網路中傳送訊息的機制進行通訊。MPI為分散式記憶體系統設計。
1.6 並行、並行、分散式
平行計算 (concurrent computing)、平行計算 (parallel computing) 和 分散式計算 (distributed computing) 的主要區別如下:
- 平行計算:一個程式的多個任務在同一個時段內可以 同時執行。
- 平行計算:一個程式通過多個任務 緊密共同作業 來解決某個問題。
- 分散式計算:一個程式需要與其他程式共同作業來解決某個問題。
並行程式和分散式程式都是並行的,某些程式例如多工作業系統也是並行的,因為即使在單核計算機上,多個任務也能在同一時間段內 同時執行。並行程式和分散式程式沒有明確的分界線。
並行程式往往在多個核上執行多個任務,這些核在物理空間上更靠近,通過共用記憶體或者是高速網路連線。平行計算核之間的協調比較頻繁,開銷較低,是細粒度的,並且比較可靠。平行計算過程執行時間較短。
分散式程式更加「鬆耦合」(loosely coupled),任務是在多個計算節點上執行的,計算節點相隔較遠且任務是獨立建立的程序完成的。分散式計算核之間的協調不頻繁,粗粒度的,並且不是很可靠。分散式計算過程執行時間較長。