幾種新詞發現思路
下面的方法都是用於構建新的詞庫,將新的詞庫跟常用詞庫進行對比,刪掉常見詞,就可以得到新詞了。
一、基於頻次、凝聚度、自由度的分詞。
頻次:就是字或詞在整個語料中出現的次數。在整個 2400 萬字的資料中,「電影」一共出現了 2774 次,2774就是頻次。
凝聚度:就是兩個詞單獨出現的概率乘積和它們一起出現的概率的大小對比。在整個 2400 萬字的資料中,「電影」一共出現了 2774 次,出現的概率約為 0.000113 。「院」字則出現了 4797 次,出現的概率約為 0.0001969 。如果兩者之間真的毫無關係,它們恰好拼在了一起的概率就應該是 0.000113 × 0.0001969 ,約為 2.223 × 10-8 次方。但事實上,「電影院」在語料中一共出現了 175 次,出現概率約為 7.183 × 10-6 次方,是預測值的 300 多倍。類似地,統計可得「的」字的出現概率約為 0.0166 ,因而「的」和「電影」隨機組合到了一起的理論概率值為 0.0166 × 0.000113 ,約為 1.875 × 10-6 ,這與「的電影」出現的真實概率很接近——真實概率約為 1.6 × 10-5 次方,是預測值的 8.5 倍。計算結果表明,「電影院」更可能是一個有意義的搭配,而「的電影」則更像是「的」和「電影」這兩個成分偶然拼到一起的。
自由度:我們用資訊熵來衡量一個文字片段的左鄰字集合和右鄰字集合有多隨機。考慮這麼一句話「吃葡萄不吐葡萄皮不吃葡萄倒吐葡萄皮」,「葡萄」一詞出現了四次,其中左鄰字分別為 {吃, 吐, 吃, 吐} ,右鄰字分別為 {不, 皮, 倒, 皮} 。根據公式,「葡萄」一詞的左鄰字的資訊熵為 – (1/2) · log(1/2) – (1/2) · log(1/2) ≈ 0.693 ,它的右鄰字的資訊熵則為 – (1/2) · log(1/2) – (1/4) · log(1/4) – (1/4) · log(1/4) ≈ 1.04 。可見,在這個句子中,「葡萄」一詞的右鄰字更加豐富一些。 在人人網使用者狀態中,「被子」一詞一共出現了 956 次,「輩子」一詞一共出現了 2330 次,兩者的右鄰字集合的資訊熵分別為 3.87404 和 4.11644 ,數值上非常接近。但「被子」的左鄰字用例非常豐富:用得最多的是「曬被子」,它一共出現了 162 次;其次是「的被子」,出現了 85 次;接下來分別是「條被子」、「在被子」、「床被子」,分別出現了 69 次、 64 次和 52 次;當然,還有「疊被子」、「蓋被子」、「加被子」、「新被子」、「掀被子」、「收被子」、「薄被子」、「踢被子」、「搶被子」等 100 多種不同的用法構成的長尾⋯⋯所有左鄰字的資訊熵為 3.67453 。但「輩子」的左鄰字就很可憐了, 2330 個「輩子」中有 1276 個是「一輩子」,有 596 個「這輩子」,有 235 個「下輩子」,有 149 個「上輩子」,有 32 個「半輩子」,有 10 個「八輩子」,有 7 個「幾輩子」,有 6 個「哪輩子」,以及「n 輩子」、「兩輩子」等 13 種更罕見的用法。所有左鄰字的資訊熵僅為 1.25963 。因而,「輩子」能否成詞,明顯就有爭議了。「下子」則是更典型的例子, 310 個「下子」的用例中有 294 個出自「一下子」, 5 個出自「兩下子」, 5 個出自「這下子」,其餘的都是隻出現過一次的罕見用法。事實上,「下子」的左鄰字資訊熵僅為 0.294421 ,我們不應該把它看作一個能靈活運用的詞。當然,一些文字片段的左鄰字沒啥問題,右鄰字用例卻非常貧乏,例如「交響」、「後遺」、「鵝卵」等,把它們看作單獨的詞似乎也不太合適。我們不妨就把一個文字片段的自由運用程度定義為它的左鄰字資訊熵和右鄰字資訊熵中的較小值。
二、基於遺忘演演算法的分詞。
分詞原理:詞語具備以相對穩定週期重複再現的特徵,所以可以考慮使用遺忘的方法。這意味著,我們只需要找一種適當的方法,將句子劃分成若干子串,這些子串即為「候選詞」。在遺忘的作用下,如果「候選詞」會週期性重現,那麼它就會被保留在詞庫中,相反如果只是偶爾或隨機出現,則會逐漸被遺忘掉。
子串劃分規則:如果兩個字共現的概率大於它們隨機排列在一起的概率,那麼我們認為這兩個字有關,反之則無關。如果相鄰兩字無關,就可以將兩字中間斷開。逐字掃描句子,如果相鄰兩字滿足下面的公式,則將兩字斷開,如此可將句子切成若干子串,從而獲得「候選詞」集,判斷公式如下圖所示:

計算遺忘剩餘量:使用牛頓冷卻公式,各引數在遺忘演演算法中的含義,如下圖所示:

其中遺忘係數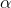 ,可以參考艾賓浩斯曲線中的實驗值,如下圖:
,可以參考艾賓浩斯曲線中的實驗值,如下圖:
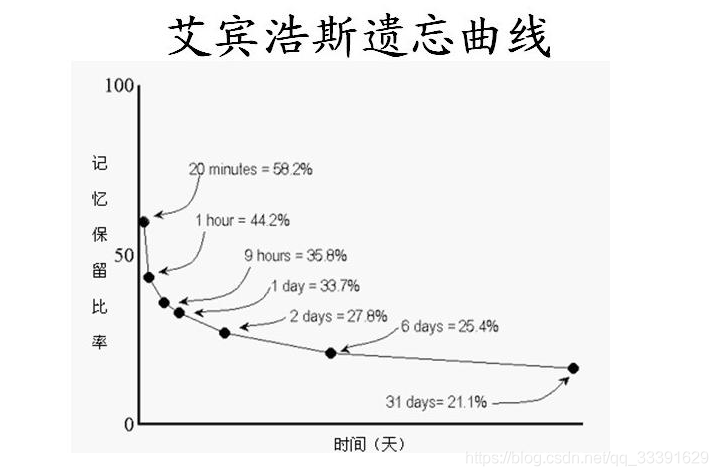
我們取6天記憶剩餘量約為25.4%這個值,按每秒閱讀7個字,那麼6天閱讀的總字數為6*24*60*60*7,將其代入牛頓冷卻公式可以求得遺忘係數:
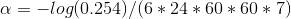
三、基於最大概率的分詞。
例子:我去吃飯了。
為了簡單,就以二元模型為例,即最終的詞語最大長度為2。
它的分詞結果有如下情況:
我 去 吃 飯 了
我去 吃 飯 了
我 去吃 飯 了
。。。等等情況,而這些情況出現的概率分別是
p1=p(我)*p(去)*p(吃)*p(飯)*p(了)
p2=p(我)*p(去|我)*p(吃)*p(飯)*p(了)
p3=p(我)*p(去)*p(吃|去)*p(飯)*p(了)
。。。等等情況。
最終正確的分詞結果是「我 去 吃飯 了」,也就是說這一結果的概率是最大的,這其實就是一個序列標註問題,標籤有S(single,單個)、B(首字)、I(非首字),最終正確的標籤結果就是「SSBIS」,此時問題就變成了找出哪種情況或序列出現的概率最大(前向演演算法)且各個字的標籤分別是什麼(定位),前向演演算法加定位那不就是維特比演演算法麼,維特比演演算法就是用前向演演算法求哪種隱藏狀態有最大可能生成觀測序列,同時求解的時候加上標記用於反向找隱藏狀態。這裡另外提一下,既然是序列標註問題,那麼用來做NER的fcn、bilstm+crf也是可以用來做分詞的,當然,用這些方法就需要準備一些標註資料了,畢竟是有監督的學習。
2、非主流自然語言處理——遺忘演算法系列(二):大規模語料詞庫生成