商業資料分析從入門到入職(5)Python基本語法和資料型別
文章目錄
各位看官朋友,最近「GEEK+」原創·博主大賽TOP 50榜單投票,各位有票的捧個票場,沒票的捧個人場,點選https://tp.wjx.top/jq/91687657.aspx,投給第3個cutercorley,如下:
投出您最寶貴的一票,您的支援與鼓勵是我繼續創作、不斷努力的動力,我將繼續為大家貢獻原創文章、為您排憂解難。

一、從計算機到Python
1.計算機與程式思維
計算機最核心的三個部分為CPU、記憶體和硬碟,都在主機板上面,除此之外,還包括鍵盤、滑鼠等輸入裝置和螢幕等輸出裝置,如下:

CPU用於進行計算,硬碟用於儲存資料和檔案,記憶體(包括快取)用於連線CPU和硬碟,作為兩者的緩衝,可以加快讀取和處理速率。
馮·諾依曼架構如下:
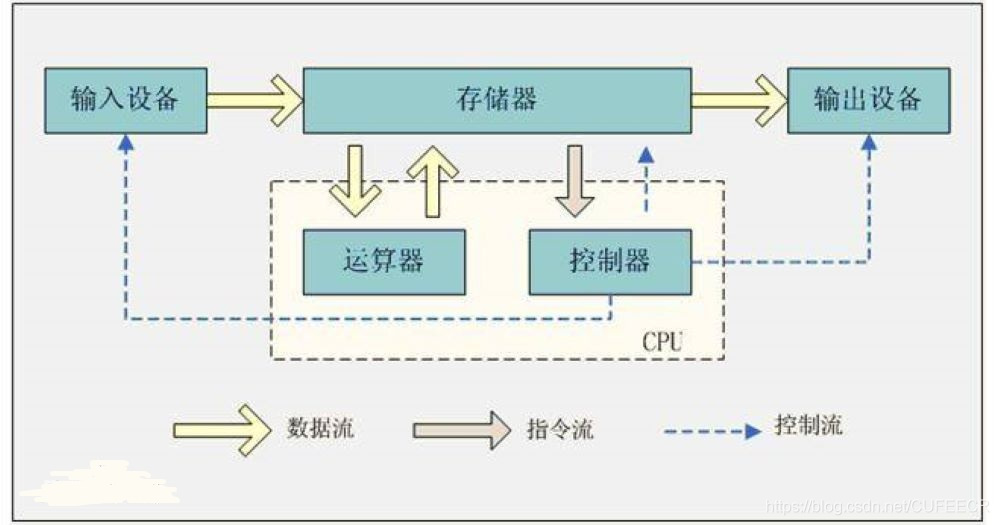
程式是指定如何執行計算的一系列指令,可以說,程式就是寫給計算機的菜譜,計算機通過輸入逐行讀取命令並執行,有輸出則輸出結果。
但是程式思維和普通思維不太一樣,比如:
對於一個陳述性知識(Declarative Knowledge)y是x的平方根,當且僅當y*y=x,但是對於程式性知識(lmperative Knowledge)可能就不是這麼表現的,可能如下:
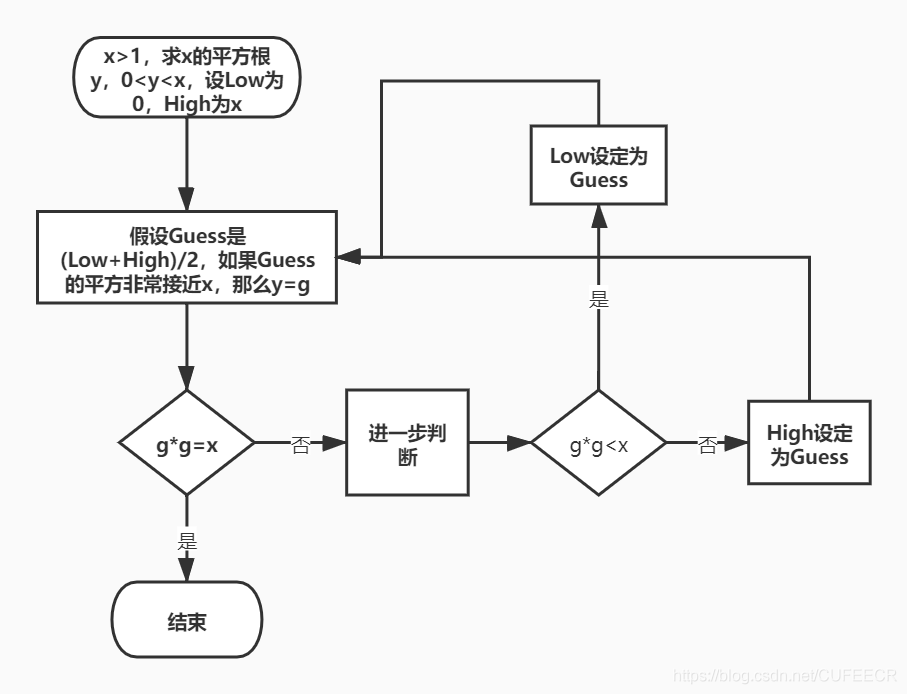
很明顯,兩種思維是有很大區別的。
在人的語言中,很多語句存在歧義,計算機不一定能理解,因此需要專門的程式語言。
有一個典型的笑話:
老婆給當程式設計師的老公打電話:「下班順路買一斤包子帶回來,如果看到賣西瓜的,買一個。」
當晚,程式設計師老公手捧一個包子進了家門。。。
老婆怒道:「你怎麼就買了一個包子?!」
老公答曰:「因為看到了賣西瓜的。」
這雖然是一個笑話,但是也說明計算機語言需要精確的表達,如果存在歧義就可能會出現不一樣的結果。
程式設計師在碼程式碼時經常會思考兩個問題:
(1)It doesn’t work,…,why?
(2)It works,…,why?
這也是程式設計師很正常的狀態。
程式設計師發展道路可以如下:
- 學習基本語法
- 讀別人的程式碼
- 修改別人的程式碼
- 開始寫自己的小程式
- 參與開源專案
寫程式應該遵循以下步驟:
- 問題表述
有什麼,要實現什麼。 - 設計計劃
如何實現,需要什麼。 - 編碼與偵錯
編碼與錯誤驗證。 - 評價
評價是否合理。 - 改進(重構)
優化或重新編寫。
程式語言的元素如下:
- 詞彙
變數Variables和保留詞彙Reserved words。
Python中的保留詞彙包括FALSE、class、is、finally、return、None、if、for、lambda、continue、True、def、from、while、nonlocal、and、del、global、with、not、elif、yield、try、as、or、else、assert、import、pass、break、in、raise、except等。 - 句子結構
- 語法Syntax
- 語意Semantics
- 程式結構
為某個目的構造程式。
程式中的基本指令包括:
- input資料輸入
從鍵盤、檔案或其他裝置獲取資料。 - output輸出
在螢幕上顯示資料或將資料傳送到檔案或其他裝置。 - math計算
執行基本的數學運算,如加法和乘法。 - conditional execution條件執行
檢查某些情況並執行適當的程式碼。 - repetition重複
重複地做一些動作,通常有一些變化。
其中,後兩者用於控制邏輯。
程式中常見的基本資料型別如下:
- Integer整型
-3、100等整數。 - Float浮點型
帶小數點的數位,如3.14159,或某些指數,如1.0e8或10000.0。 - Boolean布林型
其值為True或False。 - String字串
文字字元序列。
2.Python的特點和應用
Python是一門計算機程式語言,可以理解為人對計算機的指令。
Python之所以這麼火,與它的特點有關:
- 簡潔美觀
- 廣泛的第三方庫支援
很多人基於Python開發出現成的功能,別人可以直接使用,並且體系逐漸完善,使用起來越來越方便。 - 支援大多數現代雲平臺
- 最新機器學習框架
Python的典型應用包括資料分析、軟體開發兩大領域:
Python中有很多庫支援資料分析,包括numpy、pandas、scipy、matplotlib、networkx等;
支援軟體開發的庫包括Django、Flask和Pyramid等,包括Dropbox、Youtube、Instagram、豆瓣、知乎、魔獸世界等網站和應用都是完全或部分使用Python實現的。
雖然對於視訊流、3D遊戲等應用,Python還是存在一定的侷限,但是它的確有著廣泛的應用,所以在IT領域的各個子領域可以使用Python這同一門語言。
Python比較年輕,但是發展迅速,並且從2010年以後由於資料分析等應用得到了快速發展。
同時由於其開源免費,相比於SAS等其他語言,能夠更容易被使用者接受,進一步擴大了其應用。
為什麼會選擇Python作為入門和開發語言:
- 易學
- 簡單與可讀性
- 包支援
- 更快
- 處理巨量資料
3.工具選擇和安裝
Python存在Python2和Python3兩個版本,現在Python2已經停止更新,Python3已逐漸成為主流。
Python最常用的IDE(整合式開發環境,lntegrated Development Environment)是PyCharm,但是隻有專業版(付費)才支援科學計算和資料分析,社群版(免費)不支援科學計算,因此進行資料分析和科學計算還有其他選擇,這裡選擇專業的科學分析工具集Anaconda,並且選擇Python3版本。
由於在官網中下載較慢,因此我已經將Anaconda安裝包下載整理好了,可以直接點選加QQ群
963624318 在群資料夾Python相關安裝包中下載即可。
安裝和普通軟體安裝類似,直接點下一步即可,只是需要注意,在選擇是否新增環境變數時需要勾選,這樣就可以直接在命令列中執行相關命令,在Anaconda安裝好之後,Python也自動安裝,並且安裝了科學計算一般所需要的庫,不需要自己再專門安裝。
安裝好之後,按WIN鍵可以看到,應用列表中有Anaconda包含的工具集合,如下:
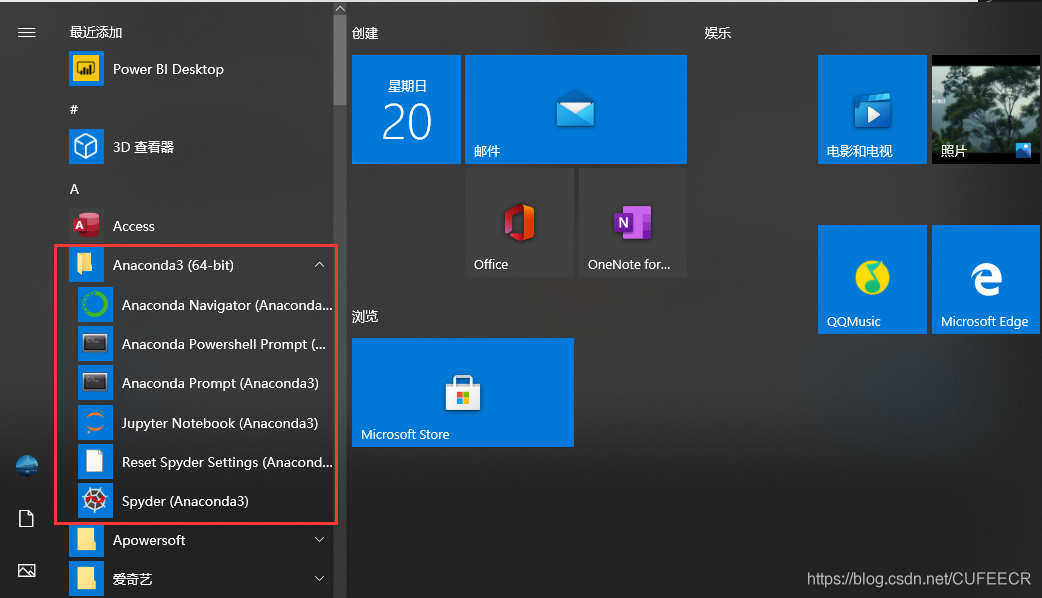
對於編寫程式碼,有三個層次的工具:
-
Editor
程式碼編輯器,包括互動式的程式設計環境Text、Sublime Text、Notepad++、VSCode等。
編輯器可以編寫程式碼,但是一般不能獨立執行程式碼。 -
IDE
整合式開發環境,即lntegrated Development Environment,如PyCharm。
IDE不僅可以編寫程式碼,還可以執行程式碼,同時還提供程式碼高亮、偵錯、程式碼上傳、版本控制等複雜功能,更適合開發大型工程。 -
REPL
全稱Read-Evalulate-Print Loop,即讀取-求值-輸出迴圈,也就是互動式的程式設計環境,如Jupyter Notebook。
其特點如下:
(1)優點- 筆電形式
- 良好的實驗環境
- 方便生成報告
- 免費
(2)缺點
- 不便於版本控制
- 檔案組織形式凌亂
4.Jupyter Notebook的基本使用
點選WIN鍵並按下圖操作:
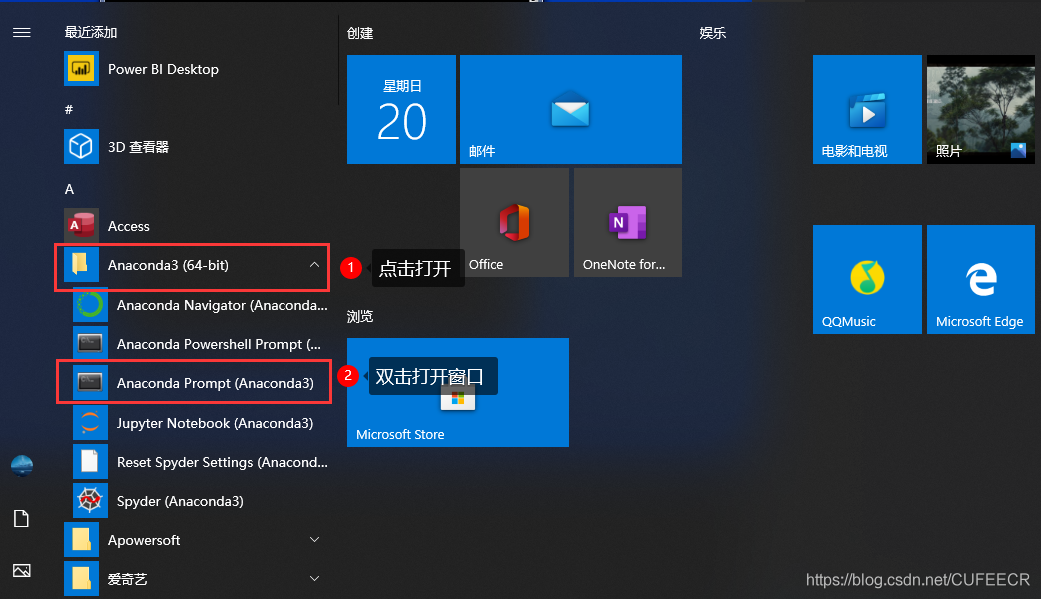
會彈出一個視窗,接下來按下面示意操作即可開啟jupyter notebook:
可以看到,開啟後是一個命令列,所在的目錄在系統家目錄下,我們一般需要在自己的工作目錄下讀取和儲存檔案,因此可以通過輸入cd XXX(XXX為自己所需要執行的目錄,在資源管理器中複製即可)跳轉到所需目錄;
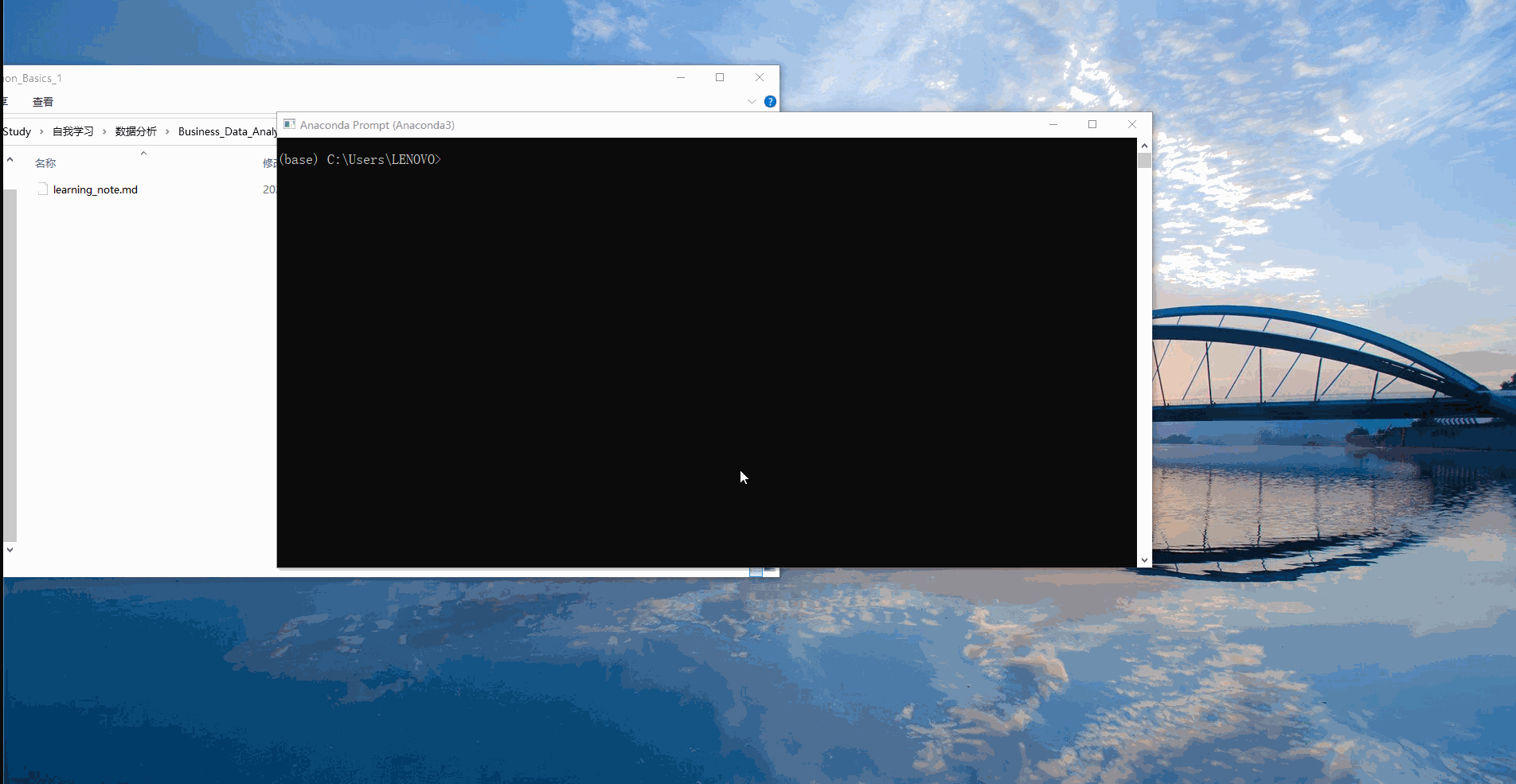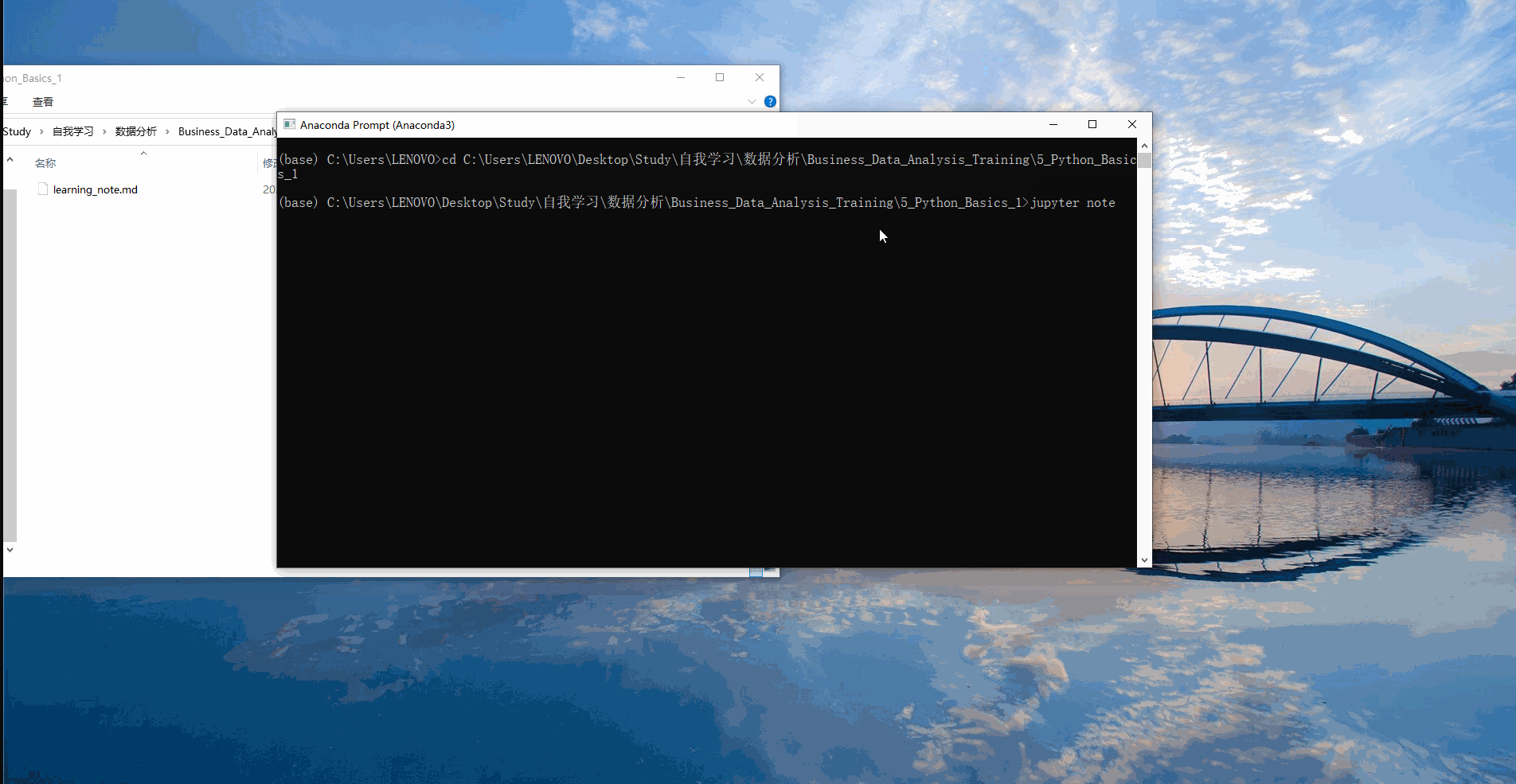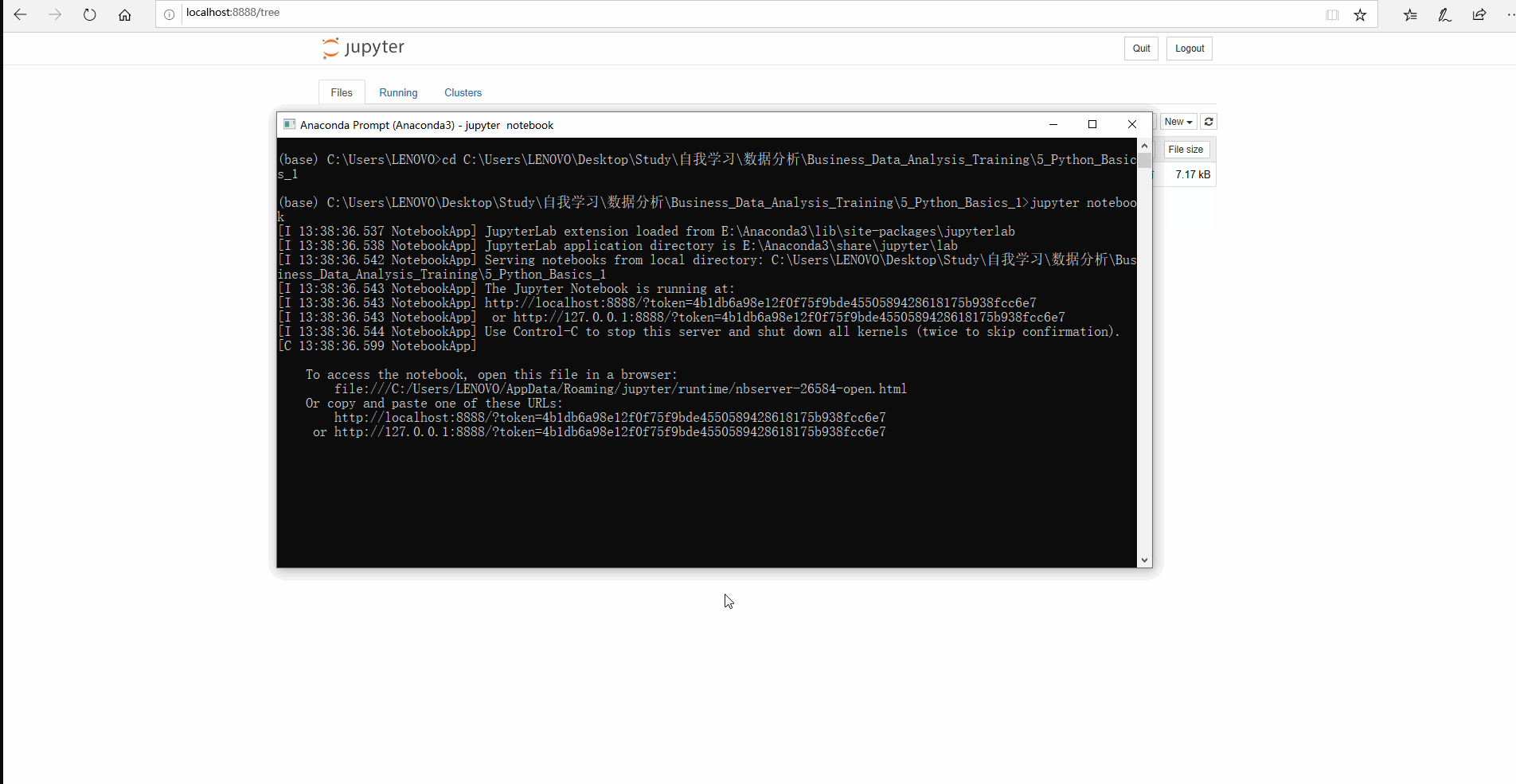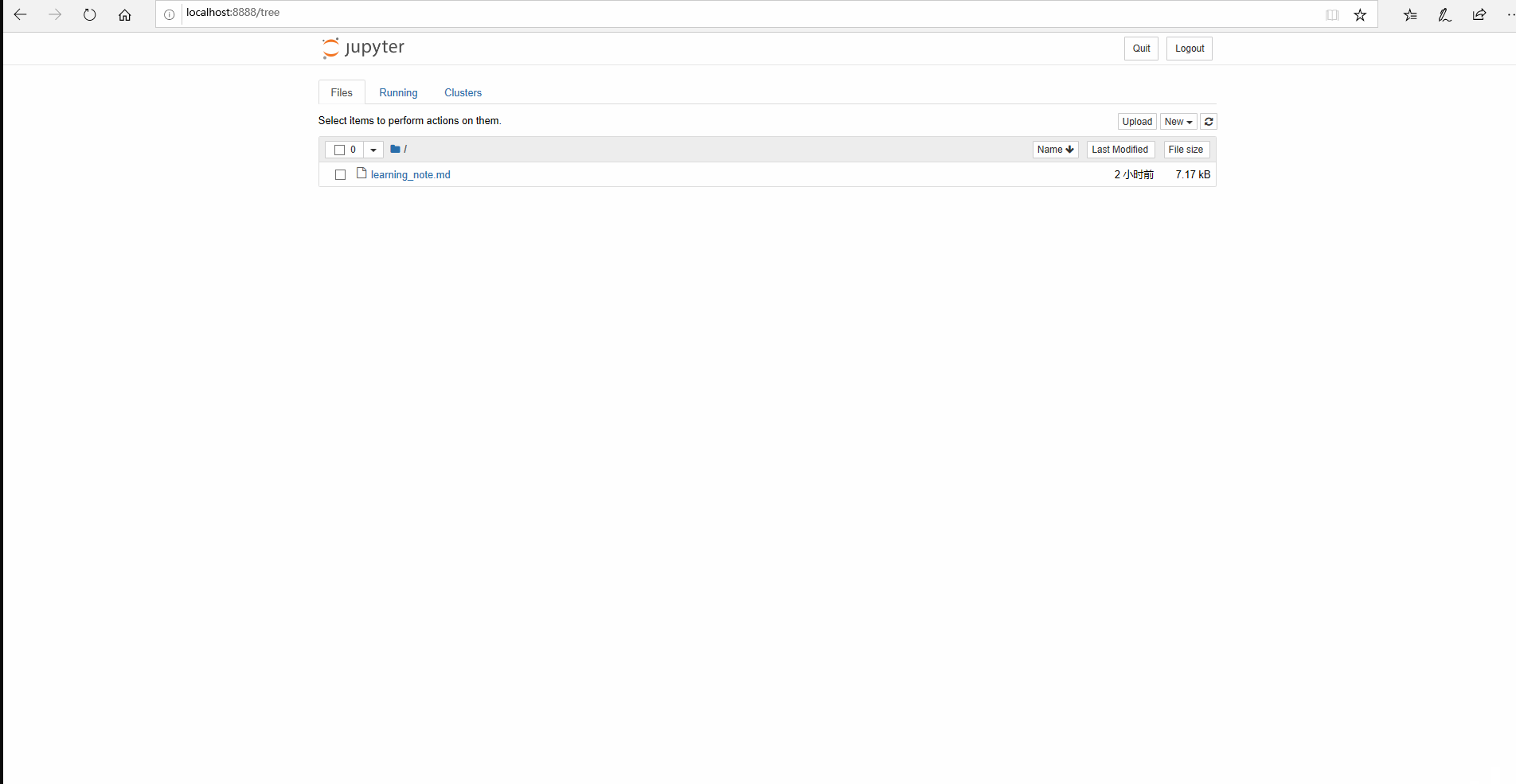
開啟notebook是通過輸入jupyter notebook命令實現的,執行完後,會使用電腦的預設瀏覽器開啟一個網頁介面,所有的操作都在這個網頁中進行,會讀取當前工作目錄中的所有檔案,資源管理器中對檔案的操作都會同步到notebook中;
如果想要在其他瀏覽器開啟,只需要複製URL到瀏覽器中存取即可。
基礎操作如下:
也可以新建notebook檔案,示意如下:
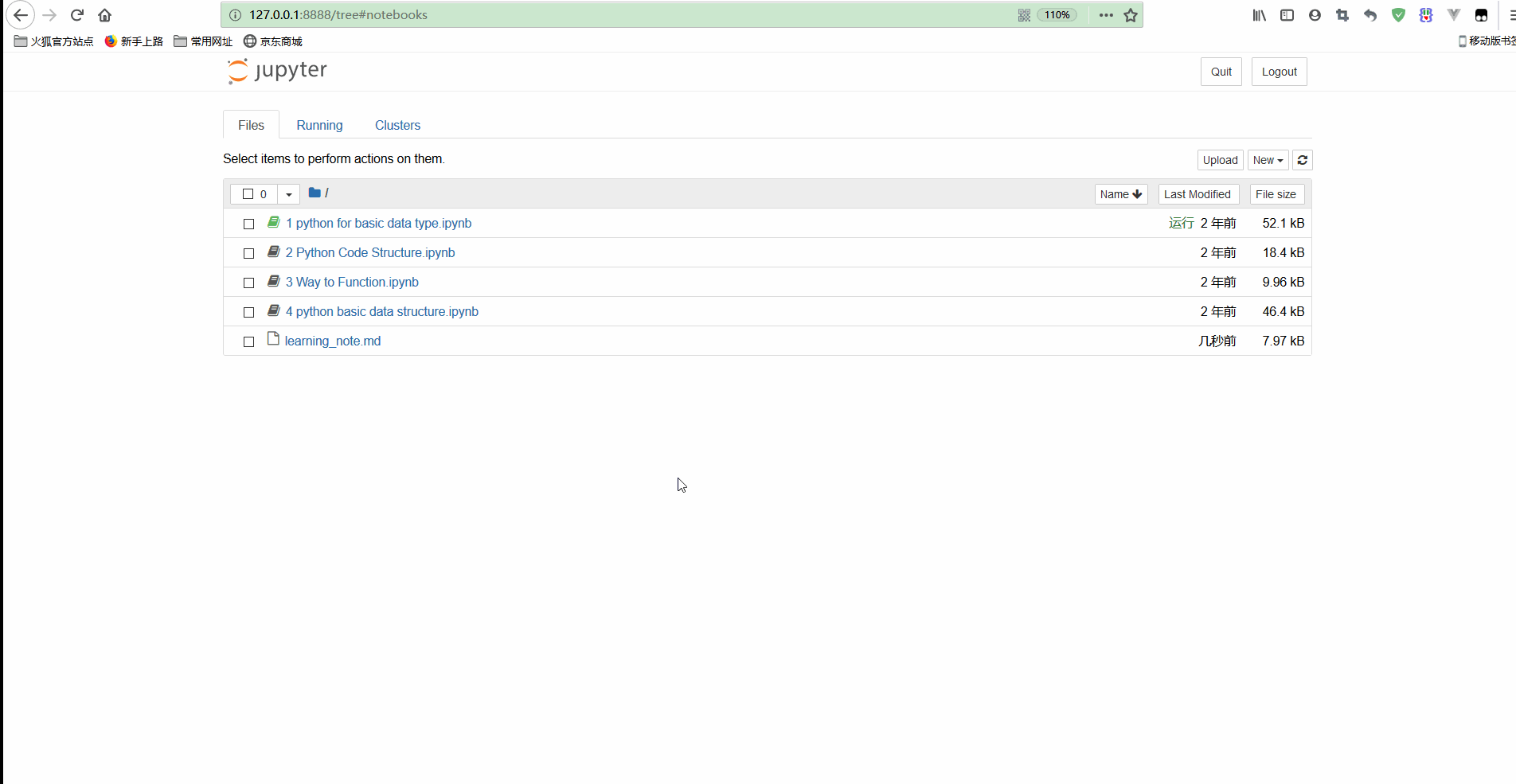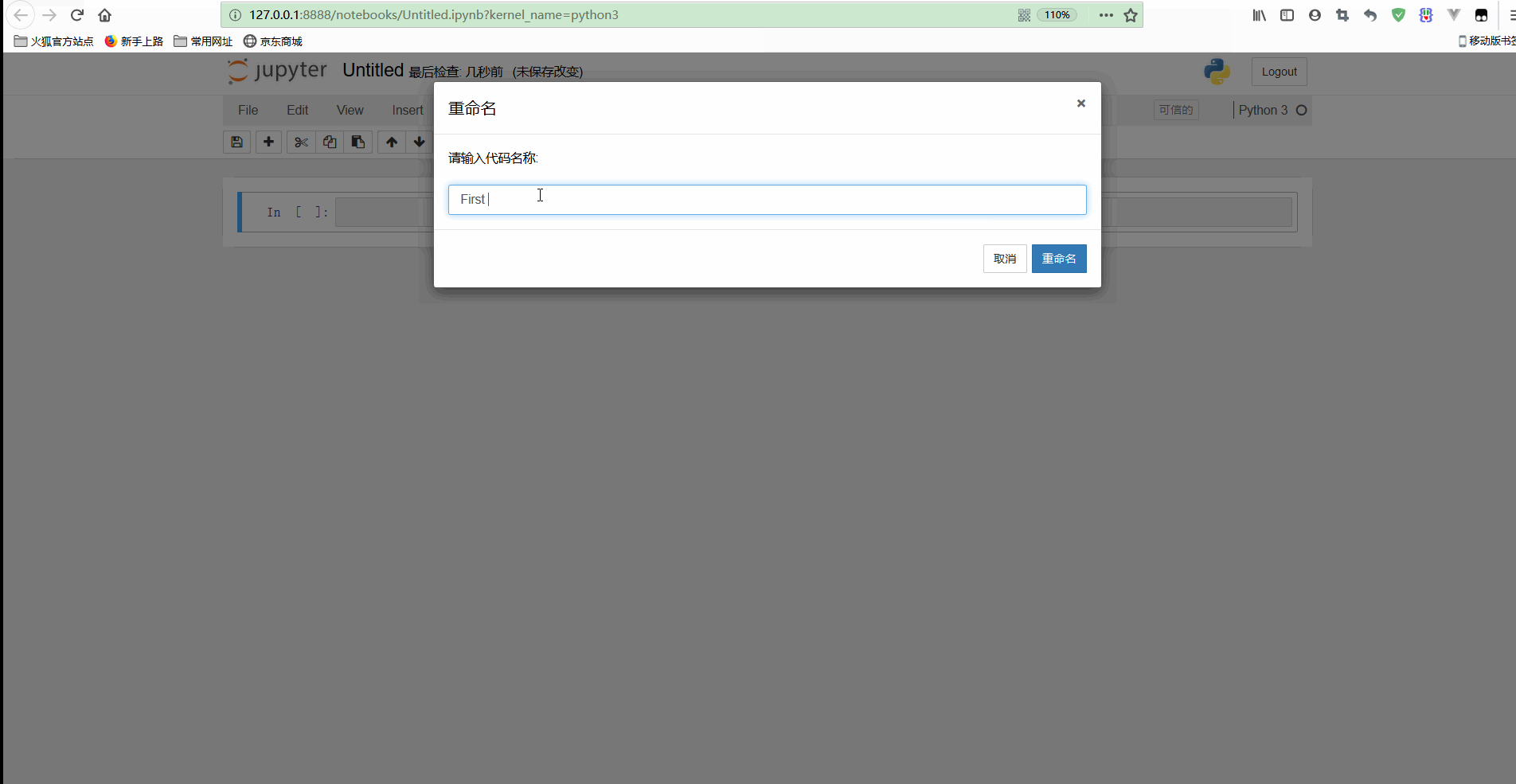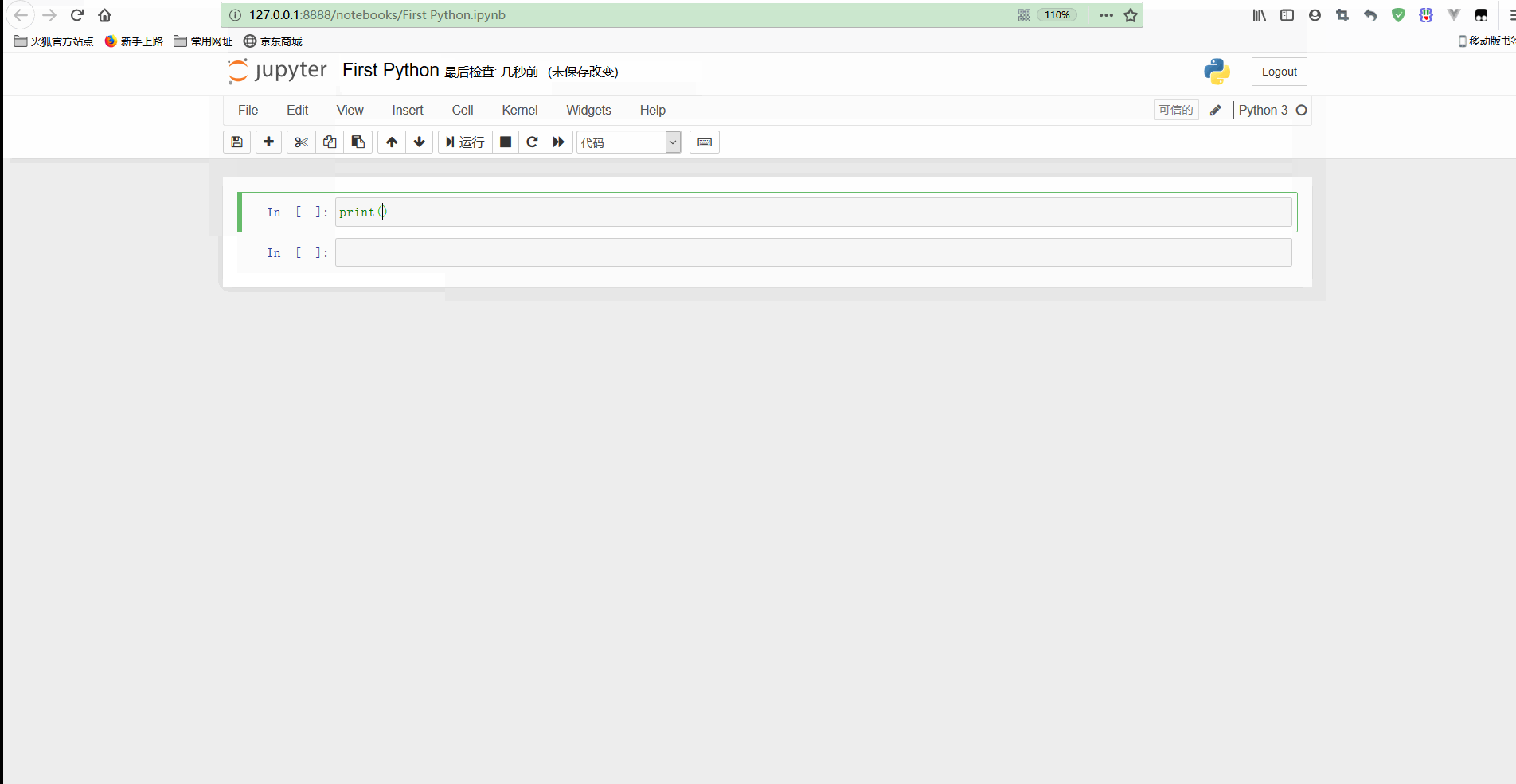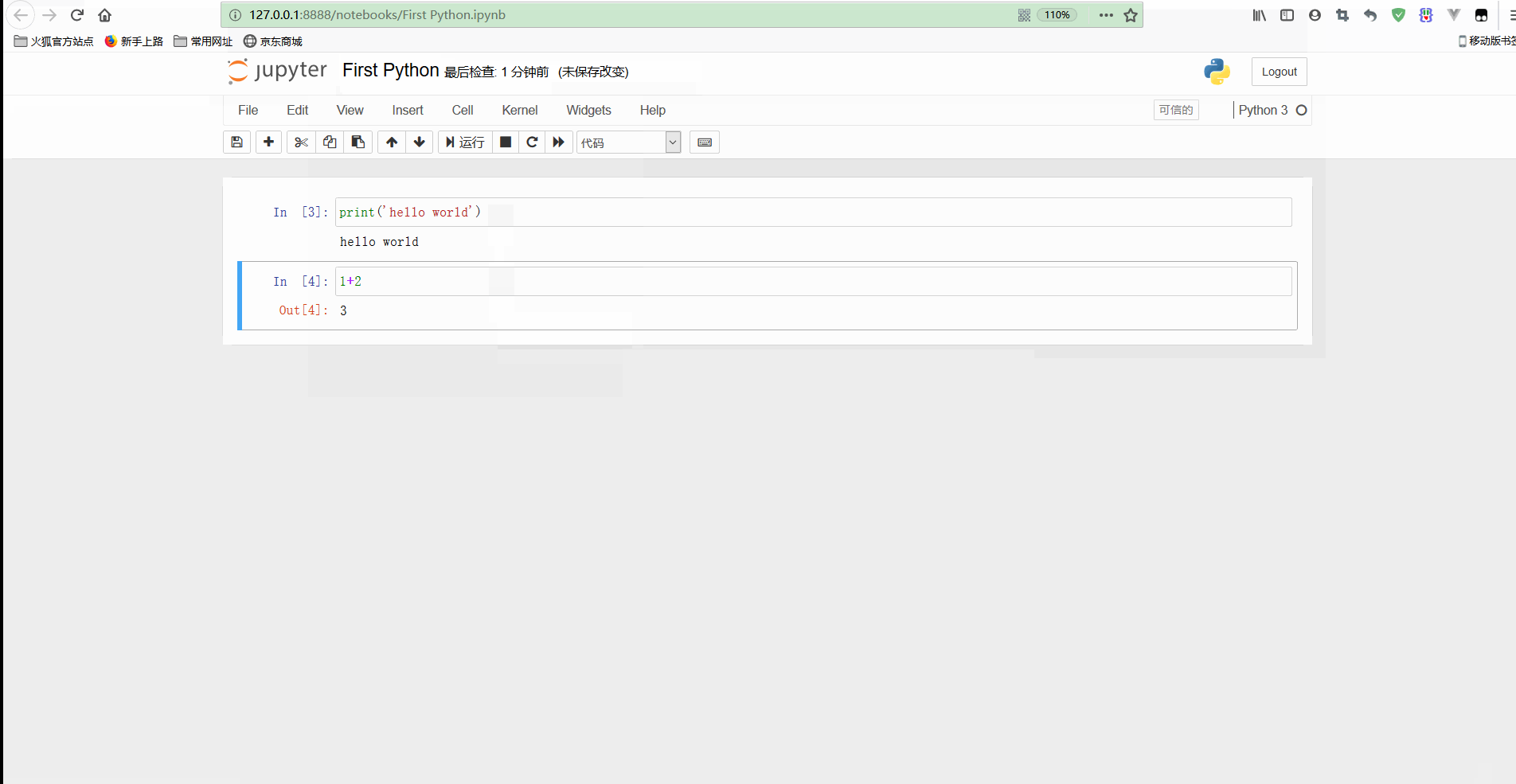
可以看到,可以對新建的檔案進行命名,同時在資料夾中也可以看到新建立的檔案First Python.ipynb;
一個Input或Output框稱為一個Cell,Cell中可以執行程式碼,輸入完畢之後按CTRL+Enter即可執行程式碼,還可以按Shift+ENter允許當前Cell並自動跳轉到下一個Cell;
Cell左邊的[]中的數位表示執行的順序,先執行的數位較小,後執行的數位較大,如果是*則表示仍在執行、還未結束,此時也不能繼續執行其他cell中的程式碼。
還有進一步操作:
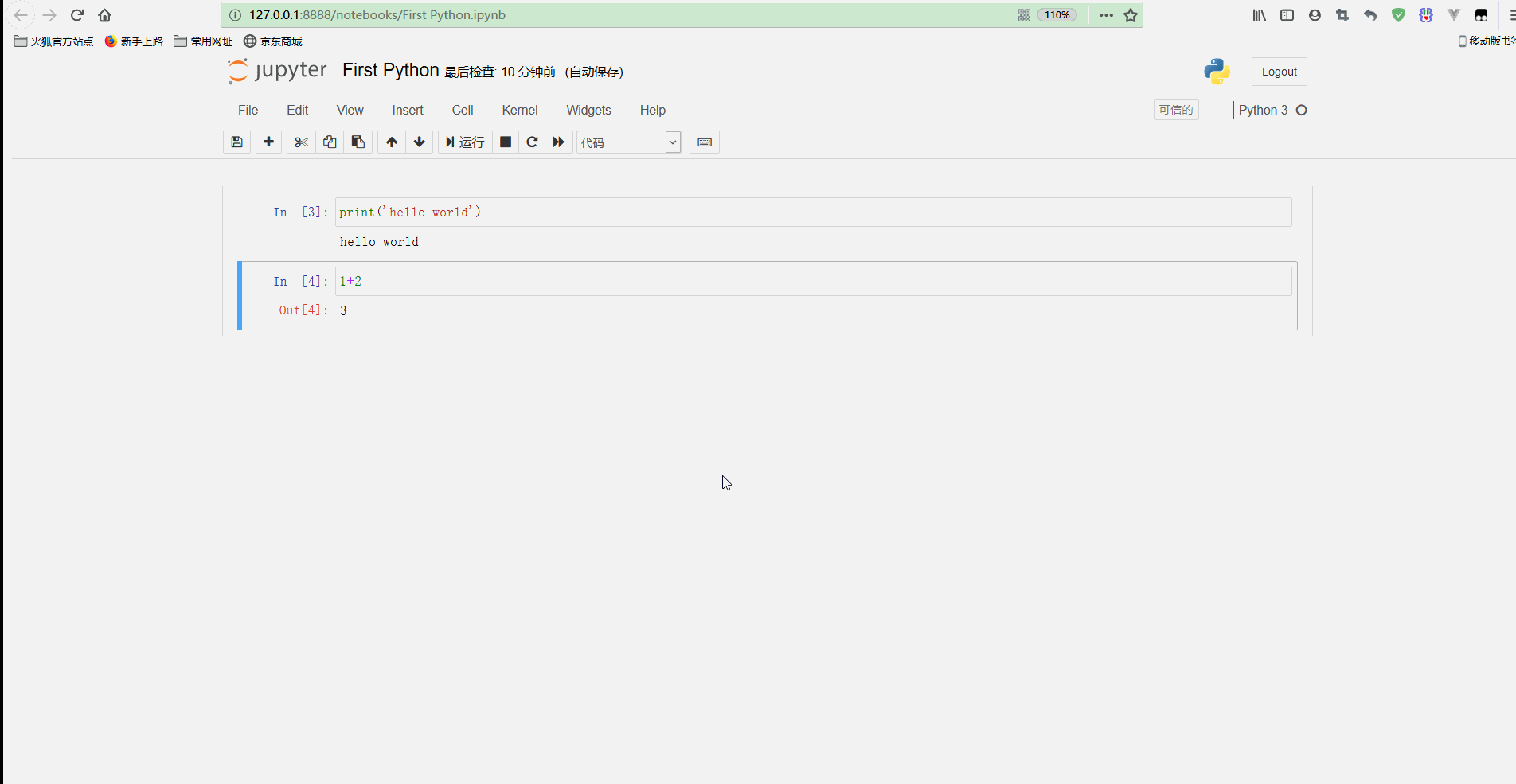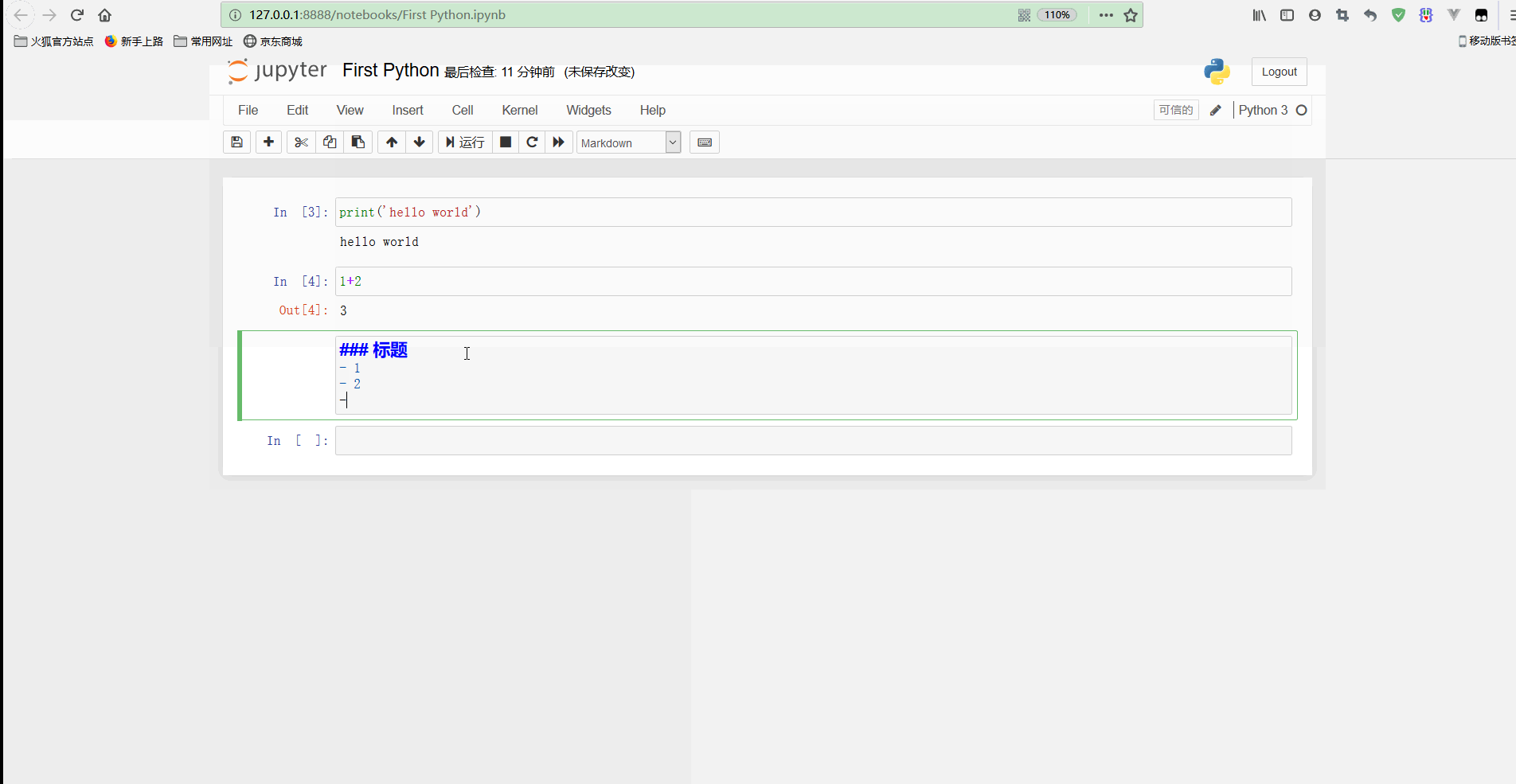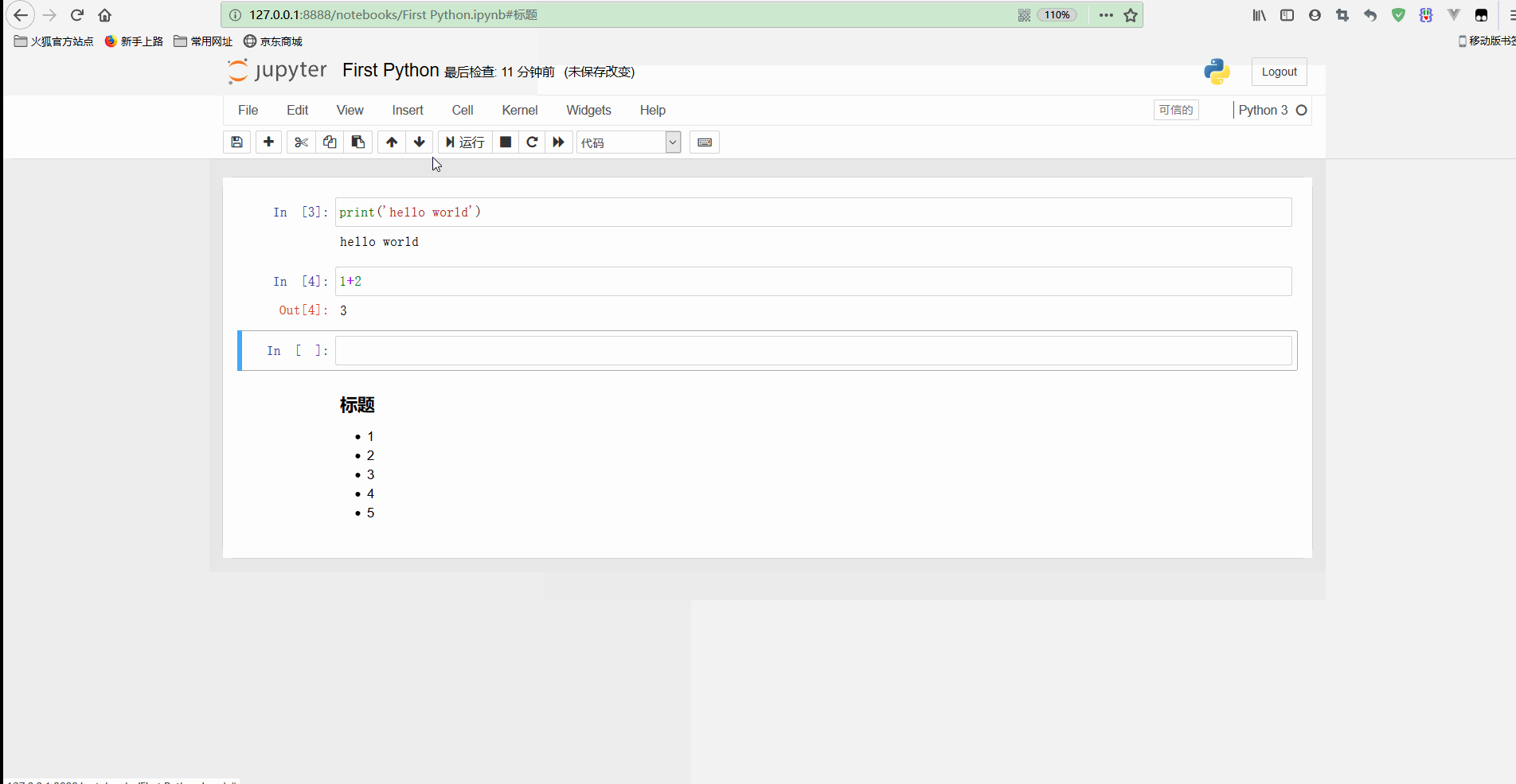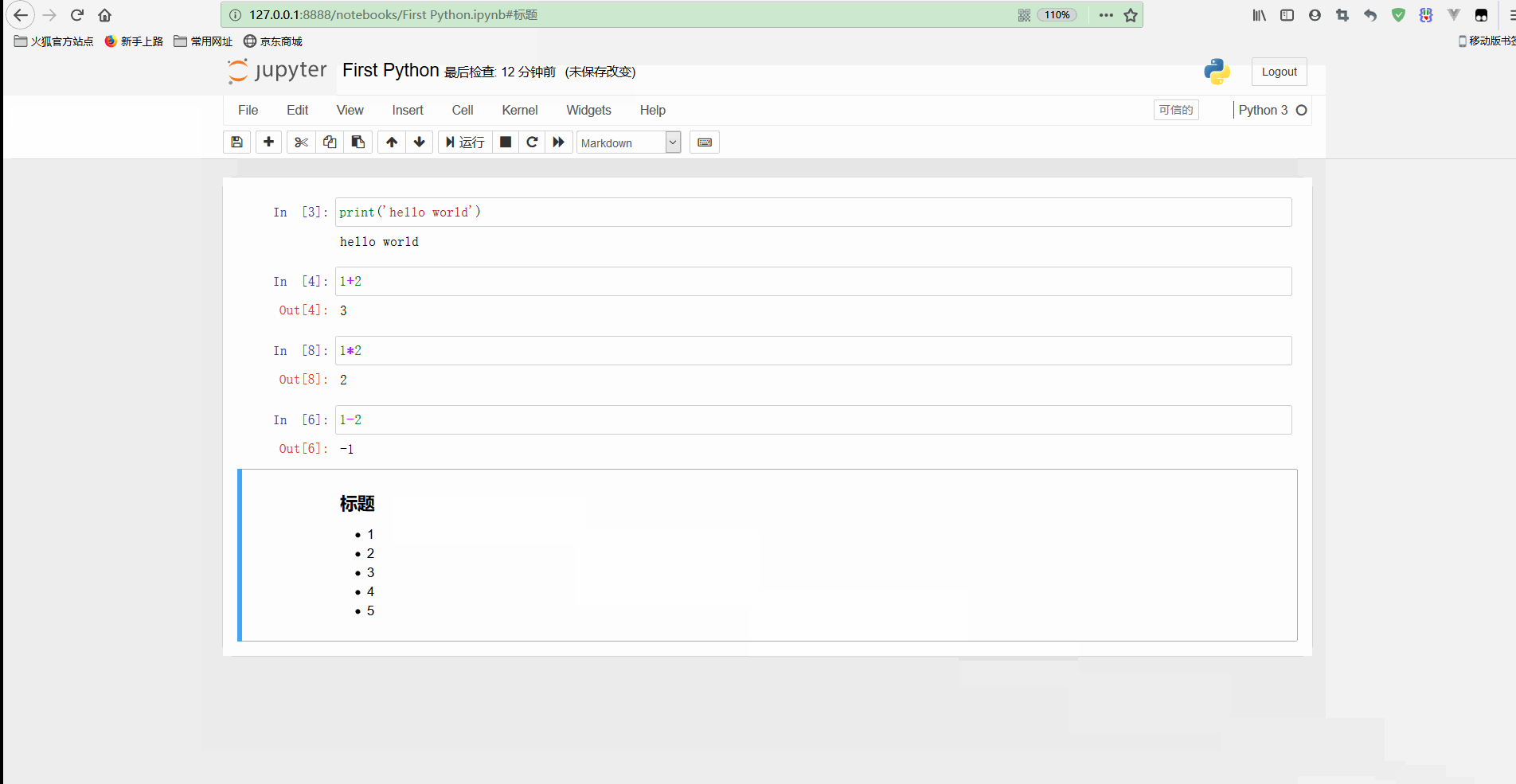
可以看到,Cell可以方便地新增、刪除或者在指定位置插入;
同時Cell中也可以選擇型別,除了程式碼還可以是Markdown和標題等,也是按CTRL+Enter即可顯示有樣式的文字,並且支援多種型別混合。
二、Python的簡單使用
1.print函數的使用
學習一門新的語言就像開啟一個新的世界,計算機輸出hello world就是在向世界打招呼,輸入:
print("Hello World! 你好,世界! Hola mundo!")
輸出:
Hello World! 你好,世界! Hola mundo!
如需本節同步
ipynb檔案,可以直接點選加QQ群
輸入:
print("Hello World!")
print("Hello Again")
print("This is the 3rd line, \n","and this is also the 3rd line.")
print("This is the 3rd line, \
and this is also the 3rd line.")
輸出:
Hello World!
Hello Again
This is the 3rd line,
and this is also the 3rd line.
This is the 3rd line, and this is also the 3rd line.
可以看到:
\n表示換行,後面的內容會換行輸出;
\可以將一行字串換行輸入,但是實際上還是一行。
2.notebook中進行計算
notebook最主要的功能就是進行計算和資料分析。
輸入:
4+5
輸出:
9
再如:
print(4-5)
print(4*5)
輸出:
-1
20
如果程式碼中存在錯誤會丟擲異常,例如:
print(8 + )
輸出:
File "<ipython-input-6-74de9a467743>", line 1
print(8 + )
^
SyntaxError: invalid syntax
顯然,沒有輸出結果,反而提示語法錯誤;
需要滿足運算的條件才能正常執行。
但是下面就不會報錯:
print('8+')
列印:
8+
這是因為將其放入單引號''或雙引號""中,使之成為字串,字串是可以列印的。
再如:
110/12.97
輸出:
8.481110254433307
但是輸出時,最後一次操作的結果將自動列印出來,前面的程式碼會執行但是不輸出。
如下:
111*222
333*444
輸出:
147852
此時指輸出了333*444的結果,並未輸出111*222的結果,此時要輸出該結果,只需要使用print()函數即可,如下:
print(111*222)
print(333*444)
輸出:
24642
147852
此時可以全部輸出。
除此之外,也可以使用display()函數,如下:
display(111*222, 333*444)
輸出:
24642
147852
3.Python基本語法規範
程式設計都應該遵循一定的程式碼規範,這樣既可以美化程式碼,也可以讓別人更加直觀地閱讀程式碼、不至於不理解或產生誤會。
Python也一樣,有自己的規範,即為PEP8(Python Enhancement Proposal 8,Python8號增強方案),規定了優雅的Python程式碼應該具有的格式。
=是賦值運運算元,如下:
number_of_cars = 34
即是將34賦值給變數number_of_cars,以後number_of_cars即代表數值34。
Python中,有時候空格是有意義的,一般程式碼用4個空格或者製表符Tab進行縮排、控制程式碼結構。
如下:
x = 8
if x < 7:
print(x)
會報錯:
File "<ipython-input-13-29d07b2c12b7>", line 4
print(x)
^
IndentationError: expected an indented block
修改為如下就不會報錯:
x = 8
if x < 7:
print(x)
同時需要注意語意上的問題,避免出現語意和邏輯上的錯誤。
如下:
x=8
if x < 7:
print("x is smaller than 7")
print("x is bigger than 7")
顯然,這雖然不會報錯,但是在語意上是有問題的。
在Python中,一切都是作為物件實現的:
我們可以將一個物件看作一個包含一段資料的盒子;
物件的型別決定了可以對物件(資料)執行的操作,例如,數位可以進行四則運算。
在賦值運運算元左側的為變數,右側的是值,右側也可以是變數。
如下:
speed_of_liuxiang=110/12.97
distance= 1000
time = distance/speed_of_liuxiang
print(time)
print(time/60)
輸出:
117.9090909090909
1.965151515151515
其中,110/12.97是值,speed_of_liuxiang是變數,通過賦值運運算元=
實現將右側的值賦值給左側,這也是我們在Python中定義變數的方式;
但是,在Python中變數只是名稱,賦值不復制值,它只是將一個名稱附加到包含資料的物件上,可以把變數理解為貼到物件上的標籤,如下:
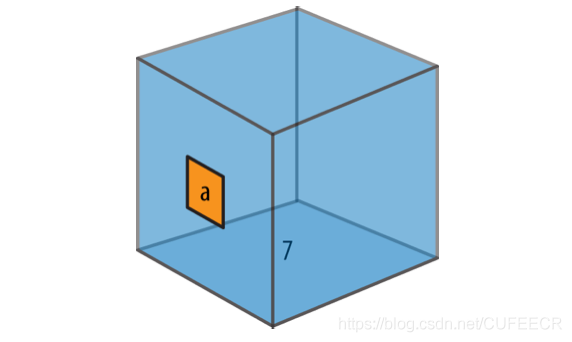
物件在盒子中,盒子上的標籤就是變數,可以參照到物件。
三、Python基本數值資料型別
Python中有4種內建數值資料型別:
- 整型int
- 浮點型float
- 布林型bool
- 字串str
1.整型
整型即整數。
輸入:
123
輸出:
123
但是輸入05,會報錯:
File "<ipython-input-21-65e6e002a62d>", line 1
05
^
SyntaxError: leading zeros in decimal integer literals are not permitted; use an 0o prefix for octal integers
所以整型不能以0開頭。
輸入:
123,456,789
輸出:
(123, 456, 789)
此時資料型別已經改變,不再是整型,而是元組。
整型的運算如下:
a = 5
a += 2
display(1 + 2, a, a-3,9//5,9/5,9%5,2+3*4)
輸出:
3
7
4
1
1.8
4
14
其中,a += 2是a = a + 2的簡寫;
//是地板除,即向下取整;
/的結果是浮點型;
%表示求模,即求相除的餘數。
在Python3中,int可以處理任何整數,無論它有多大,都不會導致溢位。
如下:
a = 10**100
display(a, a*a)
輸出:
10000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
可以看到,數足夠大,但是並沒有溢位;
**表示冪運算。
還可以轉化為其他進位制:
display(10,0b10,0o10,0x10)
輸出:
10
2
8
16
其中,無修飾預設為10進位制,0b修飾為二進位制,0o修飾為八進位制,0x為十六進位制。
2.浮點型
浮點型即小數。
可以使用type(variable)來獲取變數的型別。例如,type(1)返回int,type(1.2)返回float。
輸入:
a = 98.5
type(a)
輸出:
float
也可以使用科學計數法,如輸入9.8125e2,輸出981.25。
Python提供了很多有用的數學函數,包括在math庫中。
要使用它們,必須先通過命令import math匯入。
使用示意如下:
import math
display(math.pi, math.e, math.floor(98.6), math.ceil(98.6), math.pow(2, 3), 2**3, math.sqrt(25))
輸出:
3.141592653589793
2.718281828459045
98
99
8.0
8
5.0
可以看到,math.pow()方法得出的都是浮點型,而**的結果需要根據參與運算的數值的型別。
3.布林型
布林型只有兩個值,即True和False,表示邏輯判斷的真假。
運算如下:
display(type(1 < 2), (2 < 1) or (1 < 2), not (2 < 1), (2 < 1) and (1 < 2), (2 == 1), (2 != 1))
輸出:
bool
True
True
False
False
True
其中,or表示或運算,not表示非運算,and表示且運算;
==用於判斷兩個變數值是否相等,是邏輯運運算元,需要注意與=不同,它是賦值運運算元。
4.字串
字串是Python中眾多序列中的一個,它是一個字元序列。
輸入:
s = 'this is a string'
display(type(s), "this is also a string", "I'm a string")
輸出:
str
'this is also a string'
"I'm a string"
可以看到,字串可以由單引號或者雙引號包裹、並且需要成對出現,使用上兩者沒什麼區別,但是兩者可以實現巢狀,即雙引號中可以用單引號,單引號中可以用雙引號。
還可以在雙引號中使用雙引號,此時需要使用\進行跳脫,如下:
s = "He said: \"I'm a string\""
print(s)
輸出:
He said: "I'm a string"
可以看到,在雙引號包含的字串中也可以用雙引號作為普通字元,這是通過跳脫實現的,跳脫即使需要跳脫的字元失去其特殊的意義、作為一個普通的字元。
跳脫字元還可以用於換行符等其他特殊字元,如下:
long_s = "You can put a long string that \ntakes up multiple lines here"
print(long_s)
輸出:
You can put a long string that
takes up multiple lines here
用3層單引號或雙引號即可實現字串換行並保留原格式,如下;
s = '''
This is the first line
This is the second line
'''
print(s)
輸出:
This is the first line
This is the second line
5.型別轉換
不同的型別的資料之間可以進行型別轉換。
浮點數轉化為字串如下:
a = str(98.6)
display(a,type(a))
輸出:
'98.6'
str
再如:
display(str(True), float('98.6'), int('-123'))
輸出:
'True'
98.6
-123
如果混合了不同的數值型別,Python將嘗試進行轉換再進行運算。
如下:
display(1 + 2.0, True + 3)
輸出:
3.0
4
但是,一般不能將字串與數位進行混合運算,除非操作有意義(字串組合和重複);
同時,轉化後的型別一般不能再進行轉換之前所屬型別的操作,如浮點數轉換為字串後,不能再進行數值運算。
如下:
3.88+"28"
輸出:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-45-7c94633b599a> in <module>
----> 1 3.88+"28"
TypeError: unsupported operand type(s) for +: 'float' and 'str'
可以轉化為相同的型別再進行計算:
print(int(3.88) + int("28"))
print(int(-2.95) + int("28"))
print(float(3) + float("28"))
print(str(3.88) + str(28))
輸出:
31
26
31.0
3.8828
可以看到,字串與字串實際上是字串的拼接。
四、字串操作
1.結合與重複
字串可以進行結合與重複操作。
結合即字串的拼接,如下:
template = "My name is"
name = "Corley"
greeting = template + " " + name + "."
print(greeting)
輸出:
My name is Corley.
重複是將一個字串重複指定次數,如下:
laugh = 5 * "Ha "
print(laugh)
輸出:
Ha Ha Ha Ha Ha
2.提取與切片
字串還可以進行提取和切片。
如下:
letters = "abcdefghijklmnopqrstuvwxyz"
letters[0]
輸出:
'a'
其中0是下標,下標即各位字元位置的數位表示,範圍是0到length-1(length是字串的長度)。
如果下標超出範圍會報錯,如下:
letters = "hello world"
letters[25]
報錯:
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-51-17d500830d0d> in <module>
1 letters = "hello world"
----> 2 letters[25]
IndexError: string index out of range
還可以用負數下標,如下:
letters[-2]
輸出:
'l'
負數表示從後往前計數,範圍是從-1到-length。
使用slice從字串中提取子字串的方法是[start:end:step],有很多具體實現方式,以letters = "hello world"為例進行說明:
| 方式 | 含義 | 舉例輸入 | 輸出 |
|---|---|---|---|
| [:] | 提取整個字串 | letters[:] | ‘hello world’ |
| [start:] | 從start下標開始到結束 | display(letters[2:],letters[-3:]) | ‘llo world’\n’rld’ |
| [:end] | 從開始到end-1下標 | display(letters[:5], letters[:100]) | ‘hello’\n’hello world’ |
| [start:end] | 從start下標end-1下標 | display(letters[2:5],letters[-6:-2],letters[-2:-6]) | ‘llo’\n’ wor’\n’’ |
| [start: end:step] | 從start下標end-1下標,以step為間隔跳過字元 | display(letters[1:5:2],letters[7:1:-2],letters[::7],letters[::-1]) | ‘el’\n’o l’\n’ho’\n’dlrow olleh’ |
可以看到,在切片時,如果end引數超出下表範圍,不會報錯,而是直接切片到字串尾;
如果start大於end,並且不指定step或step為正時,會取不到字元,返回空字串,此時要想取到字元,需要使step為負數;
[::-1]用於將字串倒序排列。
3.獲取長度
獲取字串長度使用len()方法。
如下:
len(letters)
輸出:
11
4.分割和合並
分割字串使用split()方法,如下:
lan = "python ruby c c++ swift"
lan.split()
輸出:
['python', 'ruby', 'c', 'c++', 'swift']
可以看到,分割得到的結果是列表;
在沒有給split()傳引數時,預設使用空格進行分割。
還可以指定分割字元(串),傳入指定的字元(串)到split()方法中即可按照指定的字元(串)進行切割,如下:
todos = "download python, install, download ide, learn"
todos.split(', ')
輸出:
['download python', 'install', 'download ide', 'learn']
可以使用join()方法拼接列表中的字串成為一個新字串。
如下:
','.join(['download python', 'install', 'download ide', 'learn'])
輸出:
'download python,install,download ide,learn'
5.替換
呼叫replace()方法進行字串替換。
如下:
s = 'I like C. I like C++. She likes Python'
s.replace('like', 'hate')
輸出:
'I hate C. I hate C++. She hates Python'
可以看到,所有like都被替換成hate。
還可以指定替換次數如下:
s.replace('like', 'hate', 2)
輸出:
'I hate C. I hate C++. She likes Python'
顯然,此時只替換了2次。
6.佈局
字串可以設定長度和對齊方式,如果字串長度不夠則用空格將前後補全。
如下:
align = 'Learn how to align'
display(align.center(30),align.ljust(30),align.rjust(30))
輸出:
' Learn how to align '
'Learn how to align '
' Learn how to align'
可以看到,有居中、向左和向右對齊。
strip()方法用於去掉字串前後的空格,如下:
ralign = align.rjust(30)
ralign.strip()
輸出:
'Learn how to align'
7.其他操作
對於字串,還有很多其他使用的方法,以py_desc = "Python description: Python is a programming language that lets you work quickly and integrate systems more effectively."為例進行簡單說明:
| 方法 | 含義 | 輸入 | 輸出 |
|---|---|---|---|
| startswith() | 字串是否以某個子串開頭 | py_desc.startswith(‘Python’) | True |
| endswith() | 字串是否以某個子串結尾 | py_desc.endswith(‘effectively’) | False |
| find() | 字串中某個子串第一次出現的位置 | py_desc.find(‘language’) | 44 |
| isalnum() | 字串是否只包含字母和數位 | py_desc.isalnum() | False |
| count() | 字串中某個子串出現的次數 | py_desc.count(「Python」) | 2 |
| strip() | 去掉字串開頭和結尾的某個字元 | py_desc.strip(’.’) | ‘Python description: Python is a programming language that lets you work quickly and integrate systems more effectively’ |
| upper() | 將一個字串轉化成大寫形式 | py_desc.upper() | ‘PYTHON DESCRIPTION: PYTHON IS A PROGRAMMING LANGUAGE THAT LETS YOU WORK QUICKLY AND INTEGRATE SYSTEMS MORE EFFECTIVELY.’ |
| title() | 將一個字串轉化為標題的形式,即單詞的首字母大寫 | py_desc.title() | ‘Python Description: Python Is A Programming Language That Lets You Work Quickly And Integrate Systems More Effectively.’ |
對於一個方法或函數,如果不知道含義和用法,可以輸入?物件名.方法名或函數名來檢視幫助檔案,例如輸入:
?py_desc.title
在網頁下方就會彈出一個視窗,用來解釋str.title的意義和用法:
Signature: py_desc.title()
Docstring:
Return a version of the string where each word is titlecased.
More specifically, words start with uppercased characters and all remaining
cased characters have lower case.
Type: builtin_function_or_method
除此之外,還可以檢視Python官方檔案,地址為https://docs.python.org/3/,在右上角搜尋方塊中輸入方法或函數的關鍵字即可查詢到相關的含義和用法說明。