DeepAI 視界深度學習資料集大放送【一】
想要資料集?還想要標註好的資料集?你還想白嫖演演算法?還想白嫖訓練好的模型?
看到這篇文章你就找對地方了


一 [NLP] 50萬閒聊語料
公眾號回覆:閒聊

二 密集人群檢測
公眾號回覆:密集人群檢測
三疲勞駕駛資料集
公眾號回覆:pilao
四 文字生成與文字分類資料集
公眾號回覆:文字生成
五 實體命名識別
公眾號回覆:實體命名識別
六 臉部辨識
公眾號回覆:臉部辨識
七 車牌資料集
公眾號回覆:車牌
八 自動駕駛資料集
公眾號回覆:自動駕駛
九 異常行為資料集
公眾號回覆:異常行為
十 人臉關鍵點檢測
公眾號回覆:人臉關鍵點檢測
十一 高空車輛資料集
公眾號回覆:高空車輛
十二 安全帽+頭盔+演演算法
公眾號回覆:頭盔
十三 吸菸手勢
公眾號回覆:吸菸手勢
十四 香菸資料+演演算法
公眾號回覆:香菸
十五 10萬煙霧數火災資料
公眾號回覆:煙霧
十六 十萬口罩資料集
公眾號回覆:口罩
十七 車道線資料
公眾號回覆:車道線
十八 車輛識別資料+模型
公眾號回覆:車輛識別
十九 車輛檢測資料集
公眾號回覆:車輛檢測
二十 無人機檢測
公眾號回覆:無人機
二十一 X光安檢
公眾號回覆:安檢
二十二 【語音識別】嬰兒啼哭
公眾號回覆:嬰兒啼哭
二十三 老鼠檢測
公眾號回覆:老鼠
二十四 工業缺陷檢測
包含:
[外連圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-2tmMpH3Z-1600599291774)(D:\CSDN\pic\新建資料夾 (2)]\1600595297522.png)
公眾號回覆:工業缺陷檢測
二十五 交通卡口 車輛計數
公眾號回覆:車輛計數
二十六 電動車
公眾號回覆:電動車
二十七 醫療ct
公眾號回覆醫療ct
二十八 YOLOv3 口罩檢測
公眾號回覆:v3口罩
二十九 漂流物檢測
公眾號回覆:漂流物
三十 昆蟲檢測

公眾號回覆:昆蟲
下文Reference:
Memory 逆光:
https://blog.csdn.net/weixin_44936889/article/details/107029111
一、無人駕駛資料集:
1. The H3D Dataset:
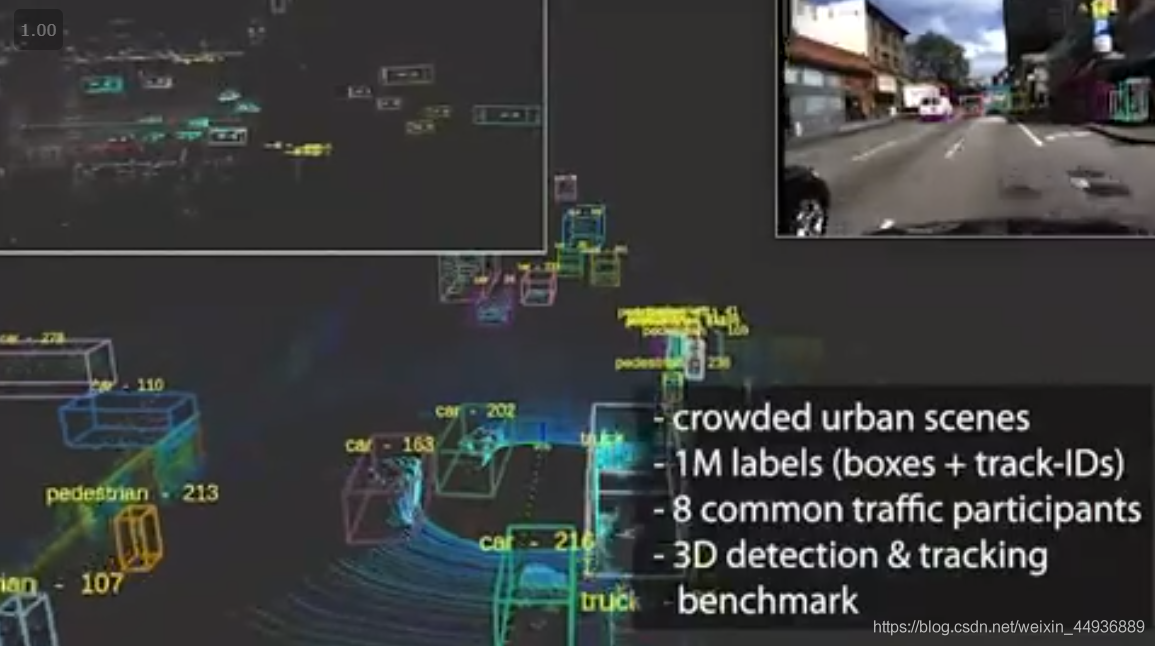
官網:
https://usa.honda-ri.com/h3d
論文地址:
https://arxiv.org/abs/1903.01568
簡介:
本田研究所於2019年3月釋出其無人駕駛方向資料集。本資料集使用3D LiDAR掃描器收集的大型全環繞3D多目標檢測和跟蹤資料集。 其包含160個擁擠且高度互動的交通場景,在27,721幀中共有100萬個標記範例。
2. nuscenes:

官網:
https://www.nuscenes.org/
論文地址:
https://arxiv.org/abs/1903.11027
簡介:
安波福於2019年3月正式公開了其資料集,並已在GitHub公開教學。資料集擁有從波士頓和新加坡收集的1000個「場景」的資訊,包含每個城市環境中都有的最複雜的一些駕駛場景。該資料集由140萬張影象、39萬次鐳射雷達掃描和140萬個3D人工註釋邊界框組成,是迄今為止公佈的最大的多模態3D 無人駕駛資料集。
3. ApolloCar3D:

官網:
http://apolloscape.auto/car_instance.html
論文地址:
https://arxiv.org/abs/1811.12222v1
簡介:
該資料集包含5,277個駕駛影象和超過60K的汽車範例,其中每輛汽車都配備了具有絕對模型尺寸和語意標記關鍵點的行業級3D CAD模型。該資料集比PASCAL3D +和KITTI(現有技術水平)大20倍以上。
4. KITTI Vision Benchmark Suite:
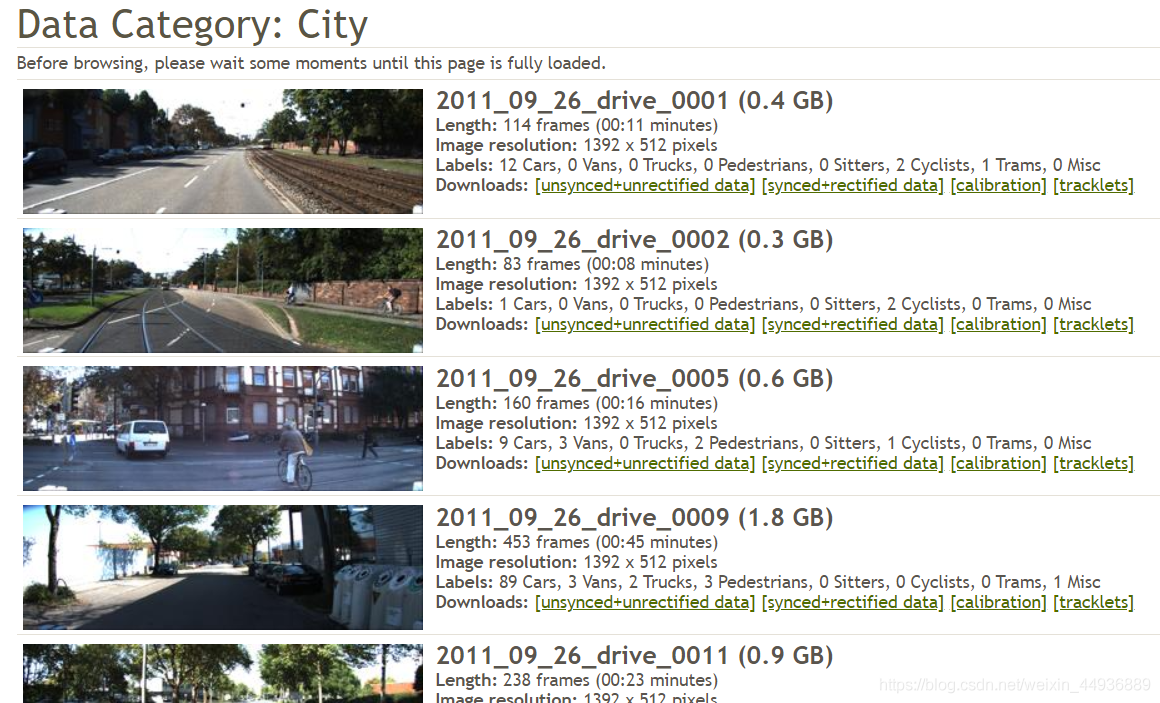
官網:
http://www.cvlibs.net/datasets/kitti/raw_data.php
論文地址:
http://www.cvlibs.net/publications/Geiger2012CVPR.pdf
簡介:
KITTI資料集由德國卡爾斯魯厄理工學院和豐田美國技術研究院聯合創辦,用於評測立體影象(stereo),光流(optical flow),視覺測距(visual odometry),3D物體檢測(object detection)和3D跟蹤(tracking)等計算機視覺技術在車載環境下的效能。KITTI包含市區、鄉村和高速公路等場景採集的真實影象資料,每張影象中最多達15輛車和30個行人,還有各種程度的遮擋與截斷。整個資料集由389對立體影象和光流圖,39.2 km視覺測距序列以及超過200k 3D標註物體的影象組成[1] ,以10Hz的頻率取樣及同步。總體上看,原始資料集被分類為’Road’, ’City’, ’Residential’, ’Campus’ 和 ’Person’。對於3D物體檢測,label細分為car, van, truck, pedestrian, pedestrian(sitting), cyclist, tram以及misc組成。
5. Cityscape Dataset:

官網地址:
https://www.cityscapes-dataset.com/
論文地址:
https://arxiv.org/abs/1604.01685
簡介:
專注於對城市街景的語意理解。 大型資料集,包含從50個不同城市的街景中記錄的各種立體視訊序列,高品質的畫素級註釋為5000幀,另外還有一組較大的20000個弱註釋幀。 因此,資料集比先前的類似嘗試大一個數量級。 可以使用帶註釋的類的詳細資訊和註釋範例。
6. Mapillary Vistas Dataset:

官網地址:
https://www.mapillary.com/dataset/vistas?pKey=xyW6a0ZmrJtjLw2iJ71Oqg&lat=20&lng=0&z=1.5
論文地址:
https://openaccess.thecvf.com/content_ICCV_2017/papers/Neuhold_The_Mapillary_Vistas_ICCV_2017_paper.pdf
簡介:
資料集是一個新穎的大規模街道級影象資料集,包含25,000個高解析度影象,註釋為66個物件類別,另有37個類別的特定於範例的標籤。通過使用多邊形來描繪單個物件,以精細和細粒度的樣式執行註釋。
7. CamVid:
官網地址:
http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/
論文地址:
http://www0.cs.ucl.ac.uk/staff/G.Brostow/papers/Brostow_2009-PRL.pdf
簡介:
劍橋駕駛標籤視訊資料庫(CamVid)是第一個具有物件類語意標籤的視訊集合,其中包含後設資料。 資料庫提供基礎事實標籤,將每個畫素與32個語意類之一相關聯。 該資料庫解決了對實驗資料的需求,以定量評估新興演演算法。 雖然大多數視訊都使用固定位置的閉路電視風格相機拍攝,但我們的資料是從駕駛汽車的角度拍攝的。 駕駛場景增加了觀察物件類的數量和異質性。
8. Caltech Pedestrian Dataset:

官網地址:
http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/
論文地址:
https://pdollar.github.io/files/papers/DollarCVPR09peds.pdf
簡介:
加州理工學院行人資料集包括大約10小時的640x480 30Hz視訊,這些視訊來自在城市環境中通過常規交通的車輛。 大約250,000個幀(137個近似分鐘的長段)共有350,000個邊界框和2300個獨特的行人被註釋。 註釋包括邊界框和詳細遮擋標籤之間的時間對應。 更多資訊可以在我們的PAMI 2012和CVPR 2009基準測試檔案中找到。
9. Comma.ai:
官網地址:
https://comma.ai/
論文地址:
https://arxiv.org/abs/1812.05752
簡介:
7.25小時的高速公路駕駛。 包含10個可變大小的視訊片段,以20 Hz的頻率錄製,相機安裝在Acura ILX 2016的擋風玻璃上。與視訊平行,還記錄了一些測量值,如汽車的速度、加速度、轉向角、GPS座標,陀螺儀角度。 這些測量結果轉換為均勻的100 Hz時基。
10. Oxford’s Robotic Car:
官網地址:
https://robotcar-dataset.robots.ox.ac.uk/
論文地址:
https://journals.sagepub.com/doi/abs/10.1177/0278364916679498
簡介:
超過100次重複對英國牛津的路線進行一年多采集拍攝。 該資料集捕獲了許多不同的天氣,交通和行人組合,以及建築和道路工程等長期變化。
11. BBD1000K:
官網地址:
https://bdd-data.berkeley.edu/
論文地址:
https://bair.berkeley.edu/blog/2018/05/30/bdd/
簡介:
超過100K的視訊和各種註釋組成,包括影象級別標記,物件邊界框,可行駛區域,車道標記和全幀範例分割,該資料集具有地理,環境和天氣多樣性。
12. Udacity Dataset:

官網地址:
https://github.com/udacity/self-driving-car
論文地址:
https://ieeexplore.ieee.org/abstract/document/8460913
簡介:
Udacity 開放無人駕駛訓練資料,為世界上每個希望進入這個行業的人提供學習的機會。現在Udacity開放了原始碼和對應的訓練模型,主要包含了如下內容:
- Deep Learning Steering Models : 通過多層神經網路預測汽車轉向角
- Camera Mount :攝像頭及鏡頭安裝的硬體標準
- Annotated Driving Datasets :已經標註過的駕駛資料 3.3G
- Driving Datasets :超過10個小時的駕駛資料(雷達、攝像頭等) 290G
- ROS Steering Node : 與ROS節點的對接方式
13. NCLT Dataset:

官網地址:
http://robots.engin.umich.edu/nclt/
論文地址:
http://robots.engin.umich.edu/nclt/nclt.pdf
簡介:
包括全方點陣影象,3D鐳射雷達,平面鐳射雷達,GPS和本體感應感測器,用於使用Segway機器人收集的測距。並新增了地面真實姿勢估計中關鍵幀的協方差。這些邊緣協方差是從SLAM圖中提取的,並以與資料集中其他協方差相同的格式記錄。
14. Ford Campus Vision and Lidar DataSet:
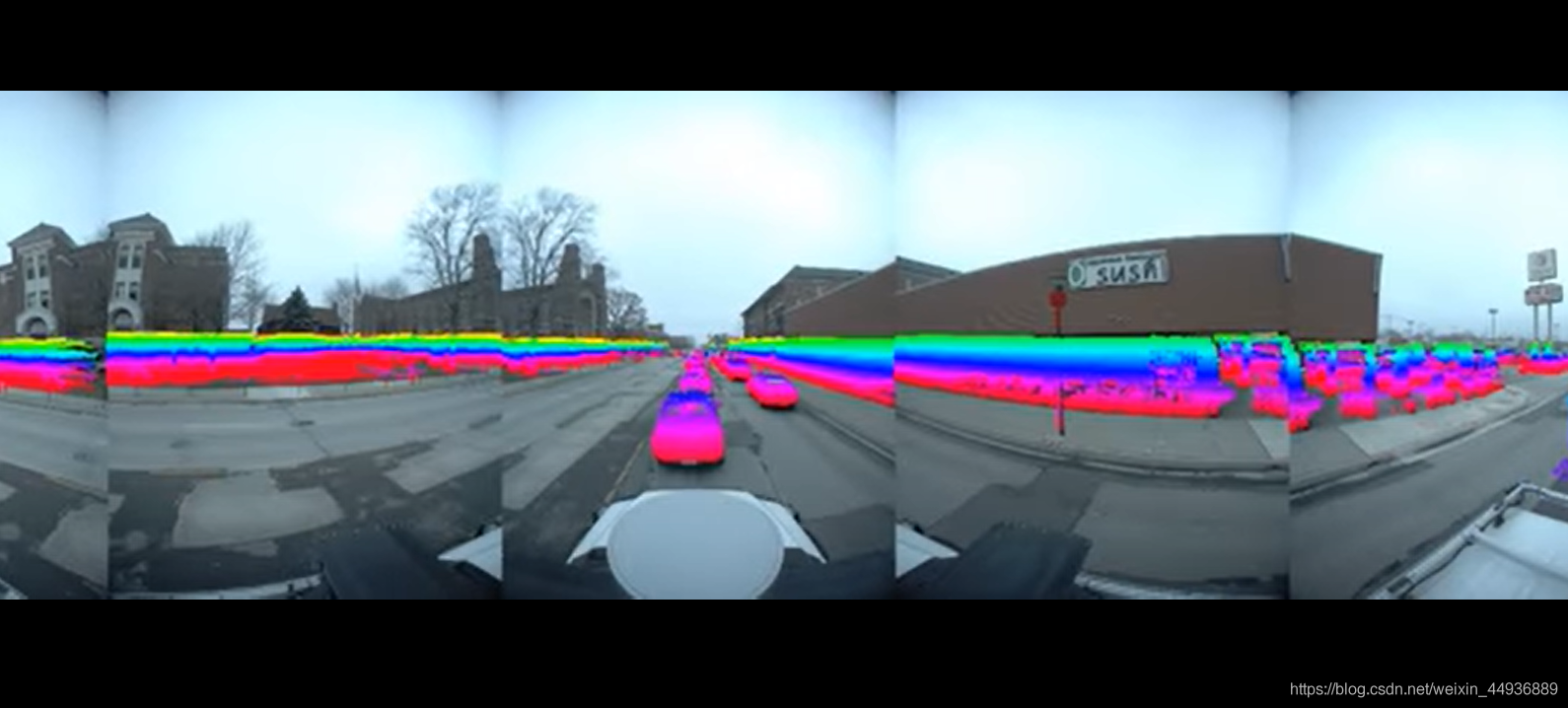
官網地址:
http://robots.engin.umich.edu/SoftwareData/Ford
論文地址:
http://robots.engin.umich.edu/uploads/SoftwareData/Ford/ijrr2011.pdf
簡介:
提供了基於改進的福特F-250皮卡車的自動地面車輛測試臺收集的資料集。該車輛配備了專業(Applanix POS LV)和消費者(Xsens MTI-G)慣性測量裝置(IMU),Velodyne 3D鐳射雷達掃描器,兩個推掃式前視Riegl鐳射雷達和Point Grey Ladybug3全向攝像頭系統。在這裡,我們提供了這些安裝在車輛上的感測器的時間記錄資料,這些資料是在2009年11月至12月期間在福特研究園區和密歇根州迪爾伯恩市區附近駕駛車輛時收集的。這些資料集中的車輛路徑軌跡包含多個比例尺閉環,對於測試各種最新狀態的計算機視覺和SLAM(同時定位和對映)演演算法應該很有用。
15. DIPLECS Autonomous Driving Datasets:
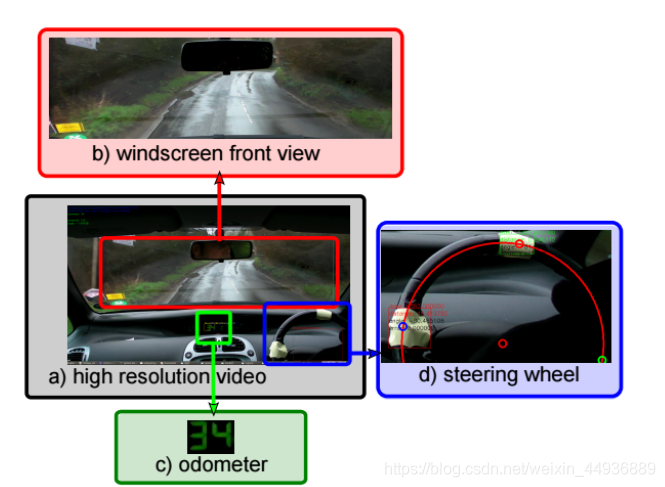
官網地址:
https://cvssp.org/data/diplecs/
論文地址:
https://www.researchgate.net/publication/331723628
簡介:
通過在Surrey鄉村周圍駕駛的汽車中放置高清攝像頭來記錄資料集。 該資料集包含大約30分鐘的駕駛時間。 視訊為1920x1080,採用H.264編解碼器編碼。 通過跟蹤方向盤上的標記來估計轉向。 汽車的速度是從汽車的速度表OCR估算的(但不保證方法的準確性)。
16. The SYNTHIA dataset:

官網地址:
http://synthia-dataset.net/
論文地址:
https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Ros_The_SYNTHIA_Dataset_CVPR_2016_paper.pdf
簡介:
包括從虛擬城市渲染的照片般逼真的幀集合,併為13個類別提供精確的畫素級語意註釋:天空,建築,道路,人行道,圍欄,植被,杆,汽車,標誌,行人, 騎自行車的人,車道標記。
二、交通標識資料集:
1. LaRA:

官網地址:
http://www.lara.prd.fr/lara
論文地址:
暫無
簡介:
巴黎的交通訊號燈資料集。
2. KUL Belgium Traffic Sign Dataset:

官網地址:
https://people.ee.ethz.ch/~timofter/traffic_signs/
論文地址:
https://people.ee.ethz.ch/~timofter/publications/Mathias-IJCNN-2013.pdf
簡介:
具有10000多個交通標誌註釋的大型資料集,數千個物理上不同的交通標誌。 用8個高解析度攝像頭錄製的4個視訊序列安裝在一輛麵包車上,總計超過3個小時,帶有交通標誌註釋,攝像機校準和姿勢。 大約16000張背景圖片。 這些材料通過GeoAutomation在比利時,佛蘭德斯地區的城市環境中捕獲。
3. LISA Traffic Sign Dataset:
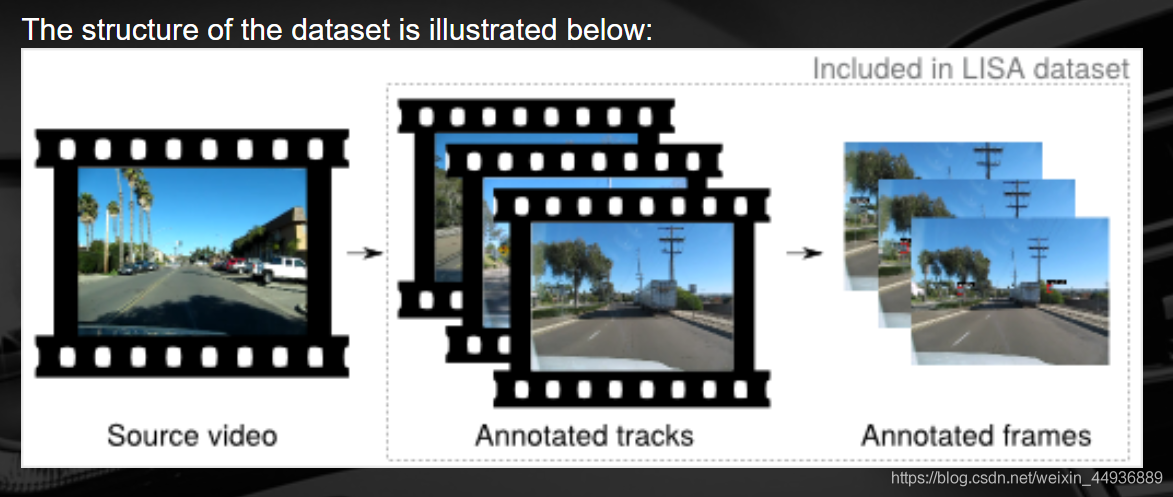
官網地址:
http://cvrr.ucsd.edu/LISA/vehicledetection.html
論文地址:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.926.7532&rep=rep1&type=pdf
簡介:
LISA交通標誌資料集是一組包含美國交通標誌的視訊和帶註釋的幀。它分為兩個階段釋出,一個階段僅包含圖片,一個階段同時包含圖片和視訊。這些影象現在可用,而完整的資料集正在進行中,並將很快提供。(官網也有車輛和紅綠燈檢測資料集)
4. Bosch Small Traffic Lights Dataset:

官網地址:
https://hci.iwr.uni-heidelberg.de/content/bosch-small-traffic-lights-dataset
論文地址:
https://ieeexplore.ieee.org/document/7989163/
簡介:
該資料集包含13427個解析度為1280x720畫素的攝像機影象,幷包含約24000個帶註釋的交通訊號燈。註釋包括交通訊號燈的邊界框以及每個交通訊號燈的當前狀態。相機影象以原始的12位元HDR影象的形式提供,該原始HDR影象是通過紅-清晰-藍色濾鏡拍攝的,以及重構的8位元RGB彩色影象。RGB影象用於偵錯,也可以用於訓練。
5. CCTSDB:

官網地址:
https://github.com/csust7zhangjm/CCTSDB
論文地址:
https://doi.org/10.3390/a10040127
簡介:
CSUST Chinese Traffic Sign Detection Benchmark 中國交通資料集由長沙理工大學綜合交通運輸巨量資料智慧處理湖南省重點實驗室張建明老師團隊製作完成。到目前為止,已經上傳影象15734張,全部的groundtruth也已經上傳。 宣告:目前的標註資料只有三大類:指示標誌、禁止標誌、警告標誌。
6. DFG:
官網地址:
https://www.vicos.si/Downloads/DFGTSD
論文地址:
https://arxiv.org/pdf/1904.00649.pdf
簡介:
包括 200 個交通標誌類別捕獲在斯洛維尼亞公路跨越約 7,000 高解析度影象。影象是由斯洛維尼亞 DFG 諮詢公司提供和註釋的。RGB 影象是通過安裝在一輛汽車上的攝像頭獲得的,這輛汽車行駛在斯洛維尼亞六個不同的自治市。這些影象資料是在農村和城市地區獲得的。從收集的大量資料中,只選擇了包含至少一個交通標誌的影象。此外,選擇是這樣進行的,通常有一個顯著的場景變化之間的任何一對選定的連續影象。
7. GTSRB:

官網地址:
https://www.kaggle.com/meowmeowmeowmeowmeow/gtsrb-german-traffic-sign
論文地址:
https://www.researchgate.net/publication/224260296_The_German_Traffic_Sign_Recognition_Benchmark_A_multi-class_classification_competition
簡介:
德國交通標誌基準測試是在2011年國際神經網路聯合會議(IJCNN)上舉行的多類,單影象分類挑戰。具有以下屬性:單影象,多類別分類問題;超過40個類別;總共超過50,000張影象;大型逼真的資料庫。
8. Mapillary Traffic Sign Dataset:

官網地址:
https://www.mapillary.com/dataset/trafficsign
論文地址:
https://arxiv.org/abs/1909.04422
簡介:
10萬幅高解析度影象,其中5.2萬幅影象所有交通標誌全標註,4.8萬幅影象部分標註;
300個交通標誌類別,32萬+個包圍框;
覆蓋全球6大洲多個地理位置;
含有天氣、季節、時刻、相機和視角等的多樣性變化;
該庫非常值得做自動駕駛、目標檢測等的朋友參考。對於非商業性質的研究是完全免費的,商業應用則需要聯絡官方獲得授權。
9. Tsinghua-Tencent 100K
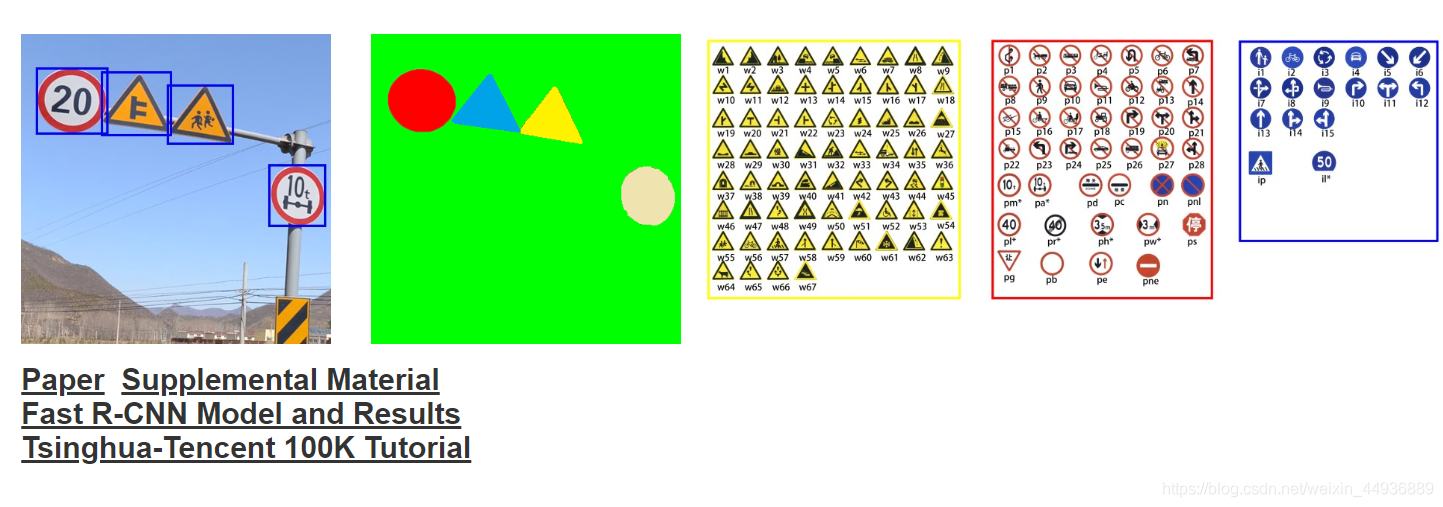
官網地址:
https://cg.cs.tsinghua.edu.cn/traffic-sign/tutorial.html
論文地址:
https://cg.cs.tsinghua.edu.cn/traffic-sign/0682.pdf
簡介:
清華和騰訊合作,part1 17.8G。號稱建立了一個大型交通標誌的benchmark,有超過100k的影象資料集,包含了30k的交通標誌,這些影象涵蓋了照明度和天氣變換的差異。原始碼和CNN模型都是公開可用的。
三、車輛檢測資料集:
1. VOC2012:

官網地址:
https://arleyzhang.github.io/articles/1dc20586/
論文地址:
https://pjreddie.com/media/files/VOC2012_doc.pdf
簡介::
PASCAL VOC挑戰賽 (The PASCAL Visual Object Classes )是一個世界級的計算機視覺挑戰賽, PASCAL全稱:Pattern Analysis, Statical Modeling and Computational Learning,是一個由歐盟資助的網路組織。
該挑戰的主要目標是從現實場景中的多個視覺物件類別中識別物件(即非預先分割的物件)。從根本上說,這是一個監督學習的問題,因為它提供了一組帶有標籤的影象的訓練。已選擇的二十個物件類是:
人:人
動物:鳥,貓,牛,狗,馬,綿羊
車輛:飛機,自行車,輪船,公共汽車,汽車,摩托車,火車
室內:瓶子,椅子,餐桌,盆栽,沙發,電視/顯示器
有3個主要的物件識別競賽:分類,檢測和分割,動作分類競賽和ImageNet進行的大規模識別競賽。此外,在人員佈局方面還開展了「品嚐」競賽。
2. MS COCO dataset:
官網地址:
https://cocodataset.org/#home
論文地址:
https://arxiv.org/pdf/1405.0312.pdf
簡介::
COCO資料集是一個大型的、豐富的物體檢測,分割和字幕資料集。這個資料集以scene understanding為目標,主要從複雜的日常場景中擷取,影象中的目標通過精確的segmentation進行位置的標定。影象包括91類目標,328,000影像和2,500,000個label。
COCO資料集有91類,雖然比ImageNet和SUN類別少,但是每一類的影象多,這有利於獲得更多的每類中位於某種特定場景的能力,對比PASCAL VOC,其有更多類和影象。
3. UA-DETRAC:

官網地址:
http://detrac-db.rit.albany.edu/
論文地址:
https://arxiv.org/pdf/1511.04136.pdf
簡介::
UA-DETRAC是一個具有挑戰性的真實世界多目標檢測和多目標跟蹤基準。該資料集包括在中國北京和天津的24個不同地點使用Cannon EOS 550D相機拍攝的10小時視訊。視訊以每秒25幀(fps)的速度錄製,解析度為960×540畫素。UA-DETRAC資料集中有超過14萬個幀,手動註釋了8250個車輛,總共有121萬個標記的物件邊界框。我們還對目標檢測和多目標跟蹤中的最新方法以及本網站中詳述的評估指標進行基準測試。
4. Boxcar:

官網地址:
https://hyper.ai/datasets/9213
論文地址:
https://www.cv-foundation.org/openaccess/content_cvpr_2016/app/S12-56.pdf
簡介::
BoxCars116k 資料集由布林諾理工大學釋出,包括 116000 張車輛影象。這些影象皆由多個監控攝像頭拍攝,且來自於多個觀察點。該資料集可被用作於交通車輛檢測等領域的研究。
5. BIT車輛資料集:

官網地址:
http://iitlab.bit.edu.cn/mcislab/vehicledb/
論文地址:
暫無
簡介::
資料集包含9,850輛車輛影象。資料集中有16001200和19201080的影象,分別來自於兩個不同時間和地點的相機。影象包含光照條件、尺度、車輛表面顏色和視點的變化。由於捕捉延遲和車輛尺寸的原因,一些車輛的頂部或底部沒有包含在影象中。在一幅影象中可能有一輛或兩輛車,因此每輛車的位置都是預先註釋的。該資料集還可用於評價車輛檢測的效能。資料集中的所有車輛被分為六類:公共汽車、微型客車、小型貨車、轎車、SUV和卡車。每車型車輛數量分別為558、883、476、5922、1392、822輛。
6. Vehicle Image Dataset:

官網地址:
https://www.gti.ssr.upm.es/data/Vehicle_database.html
論文地址:
暫無
簡介::
該資料庫包含3425 張車輛後方影象從不同的角度拍攝,並從不包含車輛的道路序列中提取了3900張影象。選擇影象以使車輛類別的代表性最大化,這自然包括高可變性。
7. Nepalese Vehicles:

官網地址:
https://github.com/sdevkota007/vehicles-nepal-dataset
論文地址:
暫無
簡介::
該影象資料集是我最後一年的本科專案「 使用影象處理進行車輛檢測和道路交通擁堵測繪」的一部分。總共30部交通視訊,每部約。從加德滿都的不同街道拍攝了4分鐘,並從視訊幀中手動裁剪了車輛的影象。
8. TME Motorway Dataset:

官網地址:
http://cmp.felk.cvut.cz/data/motorway/
論文地址:
http://cmp.felk.cvut.cz/data/motorway/paper/itsc2012.pdf
簡介::
由28個視訊片段組成,總計27分鐘的視訊,該資料集包括30,000多個帶有車輛註釋的幀。

請把你需要的資料集寫在評論區~
Reference:
Memory 逆光:
https://blog.csdn.net/weixin_44936889/article/details/107029111