全網首發國內聯邦學習框架研究
前言
受到近年來對隱私資料的安全性重視,各國頒佈的相關的法律法規維護個人資料的安全性以及隱私性,企業與企業之間,甚至於部門與部門之間形成資料孤島的現象,一定程度地降低社會效率,在以上各種因素的影響下,聯邦學習應運而生,尤其是在2020年年初,國內乘著AI基礎設施演演算法元件在社會各業紛紛落地的契機,聯邦學習框架也伴隨著進入了我們的視線。
接下主要對國內的聯邦學習框架從各個方向進行研究,為後面應用落地提供技術方案選擇。
微眾銀行FATE
FATE (Federated AI Technology Enabler) 是微眾銀行AI部門發起的開源專案,為聯邦學習生態系統提供了可靠的安全計算框架。FATE專案使用多方安全計算 (MPC) 以及同態加密 (HE) 技術構建底層安全計算協定,以此支援不同種類的機器學習的安全計算,包括邏輯迴歸、基於樹的演演算法、深度學習和遷移學習等。
開源地址:https://github.com/FederatedAI/
演演算法支援
FATE目前支援三種型別聯邦學習演演算法:橫向聯邦學習、縱向聯邦學習以及遷移學習。
Federatedml模組包括許多常見機器學習演演算法聯邦化實現。所有模組均採用去耦的模組化方法開發,以增強模組的可延伸性。具體來說,主要提供:
-
聯邦統計: 包括隱私交集計算,並集計算,皮爾遜係數等。
-
聯邦特徵工程:包括聯邦取樣,聯邦特徵分箱,聯邦特徵選擇等。
-
聯邦機器學習演演算法:包括橫向和縱向的聯邦LR, GBDT, DNN,遷移學習等。
-
模型評估:提供對二分類,多分類,迴歸評估,聯邦和單邊對比評估。
-
安全協定:提供了多種安全協定,以進行更安全的多方互動計算。
詳細演演算法清單: https://github.com/FederatedAI/DOC-CHN/tree/master/Federatedml
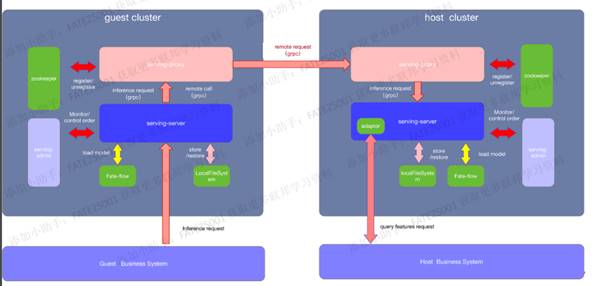
Fate整體架構
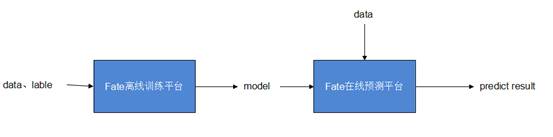
Fate主要分成以FateFlow以及FederatedML為主體的離線訓練平臺,以及以FateServing為主體的線上預測平臺。
離線訓練平臺
架構
其中離線平臺的整體架構如下:
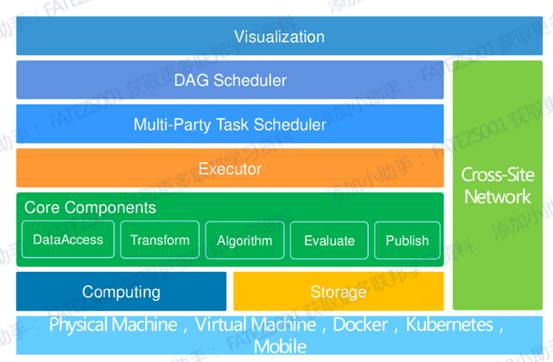
離線訓練平臺的架構通過上圖來看已經很明晰了,主要分成基礎設施層、計算儲存層、核心元件層、任務執行層、任務排程層、視覺化面板層以及跨網路互動層。
-
在基礎設施層的話,Fate主要支援Docker形式的部署,雖然也支援二進位制,但是用Docker還是能降低物理環境的差異性,便於落地,而且Fate友好地提供KubeFATE模式,如果是開發或者測試場景, 推薦使用docker-compose部署方式. 這種模式僅僅需要 Docker 環境。 如果生產環境或者大規模部署, 推薦使用Kubernetes方式來管理FATE系統。
-
在計算儲存層,主要以EggRoll以及Spark作為分散式計算引擎,據我瞭解Spark應該是v1.4版本的新特性之一,而EggRoll跟Spark的比較下,Spark是相對成熟而且資料比較多,Spark跟EggRoll的主要差別就是Spark的儲存使用HDFS,EggRoll是把儲存和計算繫結在一起的,就是不傳輸資料,而是把計算邏輯傳輸到資料所在的地方去執行。由於計算邏輯較小,所以不需要進行大規模的資料移動。
-
核心元件層主要提供資料許可權、資料互動、演演算法相關、模型訓練評估釋出相關的實現。
-
上面的任務執行層以及排程層,主要是FateFlow這個模組去實現這部分功能,籠統的說明就是聯邦學習建模Pipeline 排程和生命週期管理工具,為使用者構建端到端的聯邦學習pipeline生產服務。實現了pipeline的狀態管理及執行的協同排程,同時自動追蹤任務中產生的資料、模型、指標、紀錄檔等便於建模人員分析。
使用流程
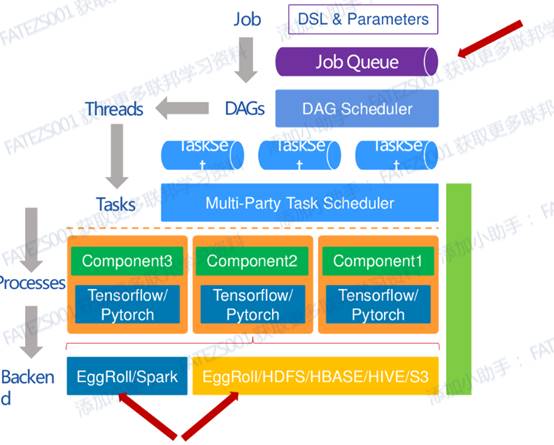
開發者通過編寫DSL構建自己模型訓練的pipeline,提交Job到任務佇列,然後任務排程器從佇列拉取任務,排程不同的計算節點執行pipeline。
部署架構
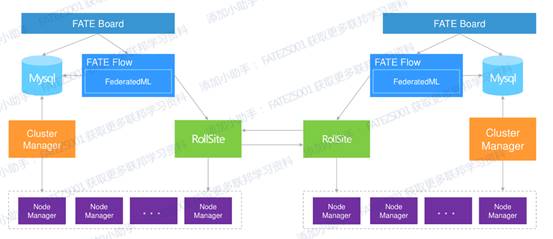
下面是v1.4的多節點部署架構圖,可以看到對於多節點(主要是guest跟host兩種角色)的部署元件主要有:
| 軟體產品 | 元件 | 說明 |
|---|---|---|
| fate | fate_flow | 聯合學習任務流水線管理模組,每個party只能有一個此服務 |
| fate | fateboard | 聯合學習過程視覺化模組,每個party只能有一個此服務 |
| eggroll | clustermanager | cluster manager管理叢集,每個party只能有一個此服務 |
| eggroll | nodemanager | node manager管理每臺機器資源,每個party可有多個此服務,但一臺伺服器置只能有一個 |
| eggroll | rollsite | 跨站點或者說跨party通訊元件,相當於proxy+federation,每個party只能有一個此服務 |
| mysql | mysql | 資料儲存,clustermanager和fateflow依賴,每個party只需要一個此服務 |
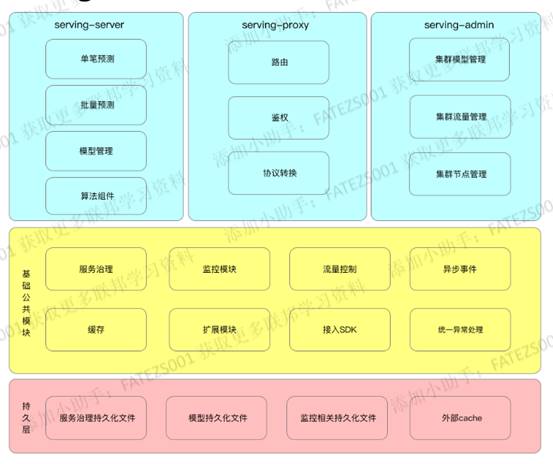
線上預測平臺
架構
線上預測平臺主要通過載入離線訓練平臺訓練模型實現線上預測功能。
線上預測平臺主要由以下三個元件構成:
-
Serving-server:預測功能的核心模組,提供演演算法元件,實現基於模型的預測功能。
-
Serving-proxy:在多方互動的時候提供路由功能,協定轉換你功能,一般guest與host之間都是通過Serving-proxy進行通訊。
-
Serving-admin:提供叢集管理功能,實現視覺化管理。
具體架構如下:
使用流程

-
打包部署:從Fate倉庫下載Fate-Serving的相關模組編譯打包執行在本地,目前主要基於java開發,需要java環境。
-
推播模型:從Fate-Flow裡面獲取模型,載入到Fate-Serving。
-
模型初始化:Fate-Serving將模型load到本地並初始化到記憶體。
-
註冊模型介面:Serving-Server將模型的資訊轉換成介面資訊註冊到註冊中心,主要基於GRPC協定。
-
提供服務:呼叫方從註冊中心拉取該模型的介面地址並行起呼叫。
部署架構
效率分析
以下材料來自於:https://blog.csdn.net/hellompc/article/details/105705745
LR演演算法測試
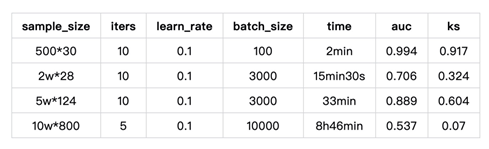
FATE在訓練10W*800樣本時(做過歸一化後)發現loss值雖在小範圍內波動,但最終結果亦沒有達到收斂。
樹類演演算法測試
[外連圖片轉存失敗,源站可能有防盜img]!鏈機制,建(https://img-WIQlog.csdnimg.cn/img_convert/213faedbc259861c614b34106a6265cc.png#pic_centerhtps://img-log.csdnimg.cn/img_convert/23d13faedbc259861c14b3646a6264cc.png)]
相關介面
任務總體概況:
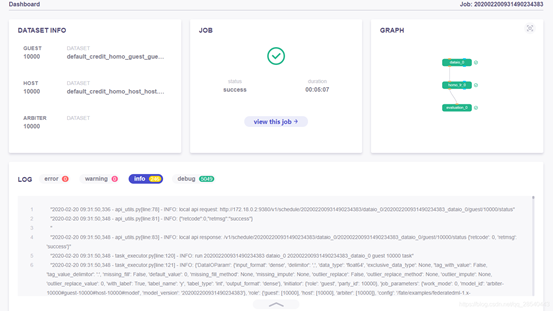
任務詳細資訊:
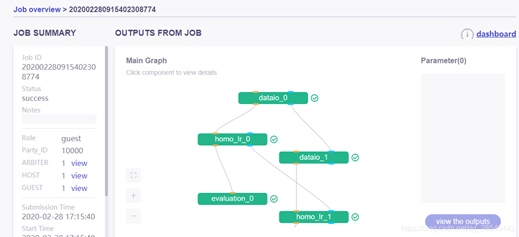
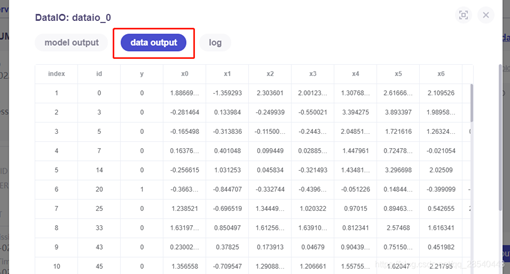
任務步驟輸出模型/資料檢視:
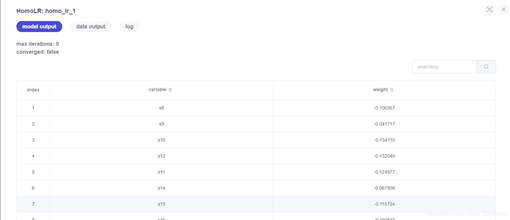
模型訓練結果檢視:
具體操作
參考:https://blog.csdn.net/qq_28540443/article/details/104562797
富數FMPC
富數多方安全計算平臺(FMPC )是上海富數科技旗下產品,目前未開源,主要通過體驗或者服務購買方式使用。
產品官網地址:https://www.fudata.cn/
富數科技是安全計算的領跑者。公司立足於領先的安全計算與人工智慧技術,幫助合規資料來源搭建巨量資料安全建模的橋樑,落地金融、政務、醫療、行銷等業務場景,釋放巨量資料的商業價值;聚合海量資料來源和應用場景,形成安全的資料價值流通平臺。通過連線、互動、結網, 建設安全的資料網際網路生態。
相較於上面提到的Fate,FMPC是一匹黑馬,下面簡單說明一下他的四大產品模組:
1)聯邦學習FMPC:
原始資料不出門,參與各方本地建模;沒有敏感資料流通,互動中間計算結果;參與方只有自己模型引數,
整個模型被保護;私有化部署;開放API快速開發;支援主流機器學習演演算法;LR, DT, RF, Xgboost…;建模速度快3倍;密文訓練精度誤差<1%
2)多方安全計算:
落地應用計算量1.1萬+次/天;支援多方資料安全求交;支援一次多項式;支援多方歸因統計分析;支援多方多維資料鑽取分析;私有化部署
3)匿蹤查詢:
支援100億+條記錄;秒級響應時間;查詢授權存證;甲方查詢資訊不洩露;加密隧道避免中間留存;私有化部署。
4)聯盟區塊鏈:
聯盟節點30+;高效能擴充套件1萬TPS;合約呼叫20萬次/天;電子存證和智慧合約;隱私保護協定;快捷部署場景應用;開源開發社群。
存取地址:https://www.unitedata.link/
經過檢視,目前開放的鏈是有故障狀態。
下面材料主要參考於:https://blog.csdn.net/hellompc/article/details/104822723
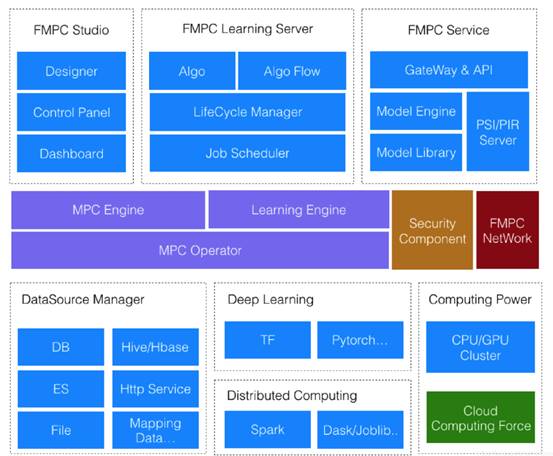
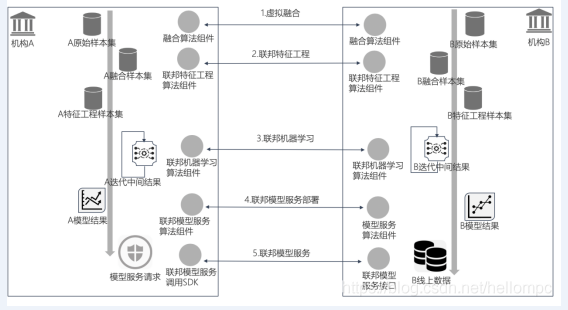
整體架構
FMPC目前公開的技術架構如下:
技術原理:
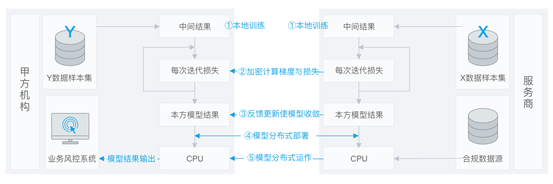
在確定共有使用者群體後,就可以利用這些資料訓練機器學習模型。以線性迴歸模型為例,訓練過程可分為以下 5 步:
第①步:A和B把各自公鑰分發給對方,用以對訓練過程中需要交換的資料進行加密;
第②步:A和B分別進行原生的訓練,產生不含敏感資訊的中間結果。
第③步:A和B之間以加密形式互動用於計算梯度的中間結果;
第④步:A和B分別基於加密的梯度值進行計算,同時 B 根據其標籤資料計算損失,並彙總計算總梯度;
第⑤步:A和B根據新計算的梯度更新各自模型的引數。
使用流程
雖然目前需要申請體驗才能看到相關的使用流程,但根據目前網上查到的相關資料,主要分成以下幾個步驟:
部署架構
未公開
演演算法支援
未公開
效率分析
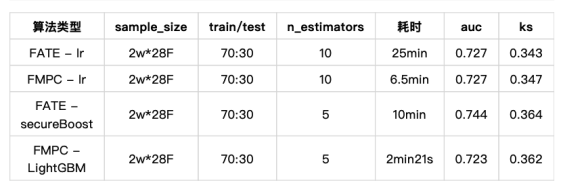
為了模擬真實業務場景,本次測試準備瞭如下兩份樣本:
樣本A:兩萬行資料,1列索引列欄位,26個特徵欄位
樣本B:兩萬行資料,1列索引列欄位,1列目標值字典,2個特徵欄位
在同等環境下同時部署FATE1.2/FMPC兩套產品,每次執行任務只獨立執行其中一款,得到指標如下:
結果分析
根據以上兩款產品使用流程可以看出,兩款產品均實現並完成安全建模的閉環流程,但在某些方面還存在一定差異。
1)產品角度:FATE更偏向於面向技術人員,使用者需要具有一定開發能力及演演算法功底;FMPC更偏向於面向業務人員,使之能在清晰的介面視覺化操作。
2)功能健全程度:FATE具有基本建模功能,包括資料上傳,模型訓練,模型評估,模型預測;FMPC在此基礎上新增了特徵分析及特徵篩選功能,更貼近實際業務場景需求。
3)效能角度:FATE的secureBoost較lr相比訓練速度更快,模型精度更高,執行時間在業內屬於可接受範圍;FMPC與之相比,開創性地採用「鬆弛迭代法「,在保持精度和準確性的同時,速度提升了3倍左右,在實際業務的多次的迭代和調參中會有較明顯的優勢。
相關介面
資料集上傳:FMPC上傳檔案有四種方式,分別為本地csv、url、DB資料庫、介面方式,以csv檔案為例,通過頁面點選欲上傳的本地檔案路徑,並填入檔案相關資訊,設定許可權:

資料虛擬融合(利用不經意傳輸機制進行的加密資料對齊):
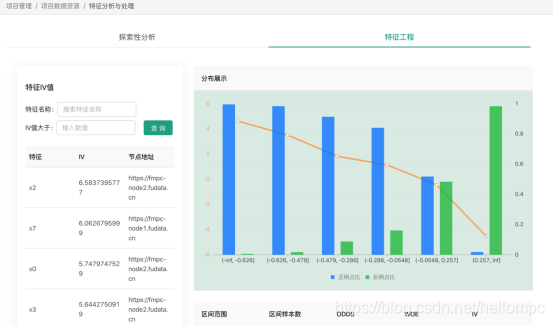
資料分析及特徵篩選:
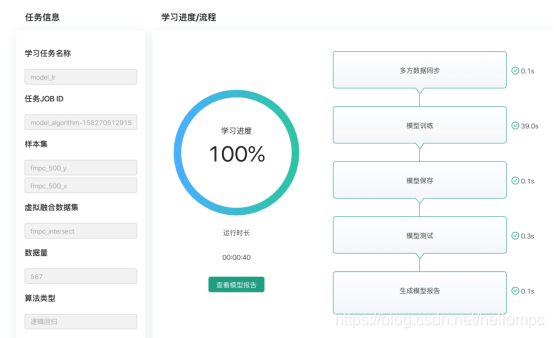
建模管理:
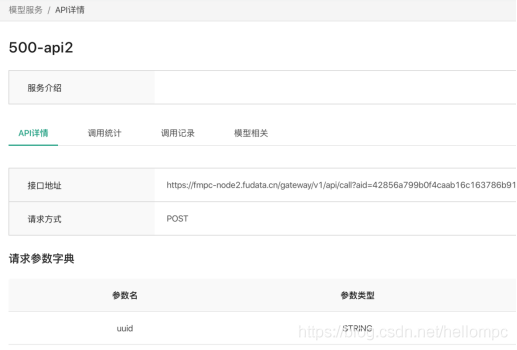
預測介面呼叫:
百度PaddleFL
PaddleFL是一個基於PaddlePaddle的開源聯邦學習框架。研究人員可以很輕鬆地用PaddleFL複製和比較不同的聯邦學習演演算法。開發人員也可以從paddleFL中獲益,因為用PaddleFL在大規模分散式叢集中部署聯邦學習系統很容易。PaddleFL提供很多聯邦學習策略及其在計算機視覺、自然語言處理、推薦演演算法等領域的應用。此外,PaddleFL還將提供傳統機器學習訓練策略的應用,例如多工學習、聯邦學習環境下的遷移學習。依靠著PaddlePaddle的大規模分散式訓練和Kubernetes對訓練任務的彈性排程能力,PaddleFL可以基於全棧開源軟體輕鬆地部署。
開源地址:https://github.com/PaddlePaddle/PaddleFL
筆者對PaddlePaddle這個深度學習框架也是挺熟悉的,也使用過一二,從易用性以及演演算法效率來看,都不遜色,尤其背靠百度的資訊庫,PaddlePaddle提供的預訓練模型的準確率也很高,基本可以開箱即用。
整體架構
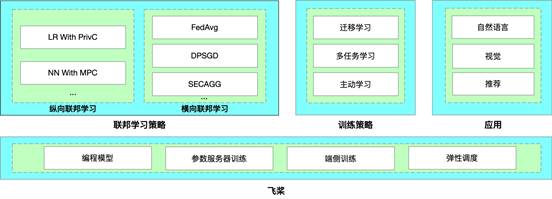
PaddleFL演演算法支援:
A. 聯邦學習策略
縱向聯邦學習: 帶privc的邏輯迴歸,帶ABY3的神經網路
橫向聯邦學習: 聯邦平均 ,差分隱私,安全聚合
B. 訓練策略
多工學習
遷移學習
主動學習
PaddleFL 中主要提供兩種解決方案:Data Parallel 以及 Federated Learning with MPC (PFM)。
通過Data Parallel,各資料方可以基於經典的橫向聯邦學習策略(如 FedAvg,DPSGD等)完成模型訓練。
此外,PFM是基於多方安全計算(MPC)實現的聯邦學習方案。作為PaddleFL的一個重要組成部分,PFM可以很好地支援聯邦學習,包括橫向、縱向及聯邦遷移學習等多個場景。既提供了可靠的安全性,也擁有可觀的效能。
使用流程
Paddle FL MPC 中的安全訓練和推理任務是基於高效的多方計算協定實現的,如ABY3
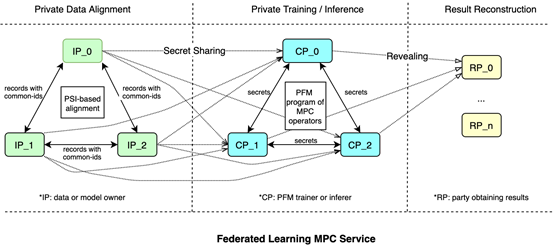
在ABY3中,參與方可分為:輸入方、計算方和結果方。輸入方為訓練資料及模型的持有方,負責加密資料和模型,並將其傳送到計算方。計算方為訓練的執行方,基於特定的多方安全計算協定完成訓練任務。計算方只能得到加密後的資料 及模型,以保證資料隱私。計算結束後,結果方會拿到計算結果並恢復出明文資料。每個參與方可充當多個角色,如一個資料擁有方也可以作為計算方參與訓練。
PFM的整個訓練及推理過程主要由三個部分組成:資料準備,訓練/推理,結果解析。
A. 資料準備
私有資料對齊: PFM允許資料擁有方(資料方)在不洩露自己資料的情況下,找出多方共有的樣本集合。此功能在縱向聯邦學習中非常必要,因為其要求多個資料方在訓練前進行資料對齊,並且保護使用者的資料隱私。
資料加密及分發:在PFM中,資料方將資料和模型用祕密共用[10]的方法加密,然後用直接傳輸或者資料庫儲存的方式傳到計算方。每個計算方只會拿到資料的一部分,因此計算方無法還原真實資料。
B. 訓練/推理
PFM 擁有與PaddlePaddle相同的執行模式。在訓練前,使用者需要定義MPC協定,訓練模型以及訓練策略。paddle_fl.mpc中提供了可以操作加密資料的運算元,在執行時運算元的範例會被建立並被執行器依次執行。
C. 結果重構
安全訓練和推理工作完成後,模型(或預測結果)將由計算方以加密形式輸出。結果方可以收集加密的結果,使用PFM中的工具對其進行解密,並將明文結果傳遞給使用者。
部署架構
Paddle FL的部署基於docker或者k8s
整體部署架構如下:
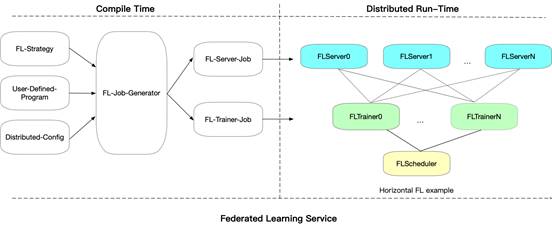
在PaddeFL中,用於定義聯邦學習任務和聯邦學習訓練工作的元件如下:
A. 編譯時
FL-Strategy: 使用者可以使用FL-Strategy定義聯邦學習策略,例如Fed-Avg。
User-Defined-Program: PaddlePaddle的程式定義了機器學習模型結構和訓練策略,如多工學習。
Distributed-Config: 在聯邦學習中,系統會部署在分散式環境中。分散式訓練設定定義分散式訓練節點資訊。
FL-Job-Generator: 給定FL-Strategy, User-Defined Program 和 Distributed Training Config,聯邦引數的Server端和Worker端的FL-Job將通過FL Job Generator生成。FL-Jobs 被傳送到組織和聯邦引數伺服器以進行聯合訓練。
B. 執行時
FL-Server: 在雲或第三方叢集中執行的聯邦引數伺服器。
FL-Worker: 參與聯合學習的每個組織都將有一個或多個與聯合引數伺服器通訊的Worker。
FL-Scheduler: 訓練過程中起到排程Worker的作用,在每個更新週期前,決定哪些Worker可以參與訓練。
演演算法支援
縱向聯邦學習: 帶privc的邏輯迴歸,帶ABY3的神經網路
橫向聯邦學習: 聯邦平均 ,差分隱私,安全聚合
效率分析
資料集:
https://paddle-zwh.bj.bcebos.com/gru4rec_paddlefl_benchmark/gru4rec_benchmark.tar
| Dataset | training methods | FL Strategy | recall@20 |
|---|---|---|---|
| the whole dataset | private training | 0.504 | |
| the whole dataset | federated learning | FedAvg | 0.504 |
| 1/4 of the whole dataset | private training | 0.286 | |
| 1/4 of the whole dataset | private training | 0.277 | |
| 1/4 of the whole dataset | private training | 0.269 | |
| 1/4 of the whole dataset | private training | 0.282 |
相關介面
無提供介面
京東九數聯邦學習9NFL
基於業務需要,京東自研的聯邦學習平臺:九數聯邦學習平臺(9NFL)於2020年初正式上線。九數聯邦學習平臺(9NFL)基於京東商業提升事業部9N機器學習平臺進行開發,在9N平臺離線訓練,離線預估,線上inference、模型的發版等功能的基礎上,增加了多工跨域排程、跨域高效能網路、大規模樣本匹配、大規模跨域聯合訓練、模型分層級加密等功能。整個平臺可以支援百億級/百T級超大規模的樣本匹配、聯合訓練,並且針對跨域與跨公網的複雜環境,對可用性與容災設計了一系列的機制與策略,保障整個系統的高吞吐、高可用、高效能。
開源地址:https://github.com/jd-9n/9nfl
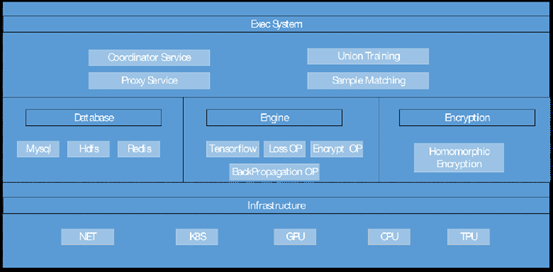
整體架構
整個系統分為四個大模組:
-
整體排程與轉發模組
整體控制資料求交與訓練的排程 訓練器的配對工作 高效的流量轉發 -
資源管理與排程模組
使用k8s遮蔽底層資源差異 使用k8s進行資源的動態排程 -
資料求交模組
大規模多模態跨域資料整合 非同步分散式框架提升拼接效率 -
訓練器模組
分散式框架訓練支援,提升系統的吞吐效能 異常恢復、failover機制 高效的網路傳輸協定設計
使用流程
9NFL主要的使用流程為:
1.資料準備
2.資料求交
3.模型訓練
部署架構
目前根據開源的程度,9NFL並未完全開源,從檔案來看也是基於Docker模式的部署。
演演算法支援
主要基於tensorflow。
效率分析
暫無
相關介面
無介面
總結
按照框架的成熟度來說,目前開源的框架裡面Fate是相對較為成熟的,而且在演演算法以及架構方向不斷優化,開源社群成熟。而FMPC就目前研究來說,他較之Fate在業務操作易用性上面領先一個身位,Fate、PaddleFL、9NFL目前操作介面都是沒有的,雖然Fate有完善的監控介面,因此FMPC對於業務場景落地還是稍有優勢。現在聯邦學習正在不斷髮展,雖然目前落地的案例並不多,但是相信在不久的將來,在各方的共同學習努力下,必能共同進步,推動聯邦學習真正落地,保障個人資料隱私,解決資料孤島問題。
參考資料
https://github.com/FederatedAI/
https://blog.csdn.net/hellompc/article/details/105705745
https://blog.csdn.net/qq_28540443/article/details/104562797
https://blog.csdn.net/hellompc/article/details/104822723