CHM知多少??
2020-09-21 15:00:22
什麼是CHM ?
1、CHM 全稱:ConcurrentHashMap 是J.U.C工具包中所提供的,顯然是個map集合,而且是個執行緒安全的HashMap,既然是執行緒安全的那麼顯然下並行場景下用的還是比較頻繁的。
2、CHM作用和HashMap差不太多,也可以說是一個執行緒安全的HashMap
3、使用和普通的Map是一致的,包含put,get 方法等
ConcurrentHashMap chmMap = new ConcurrentHashMap();
chmMap.put("key","value");
chmMap.get("key");
CHM的發展
這裡為什麼說下它的發展呢,是因為在jdk1.7和jdk1.8這2個版本下發生了一些比較大的變化(即對它進行的優化升級)
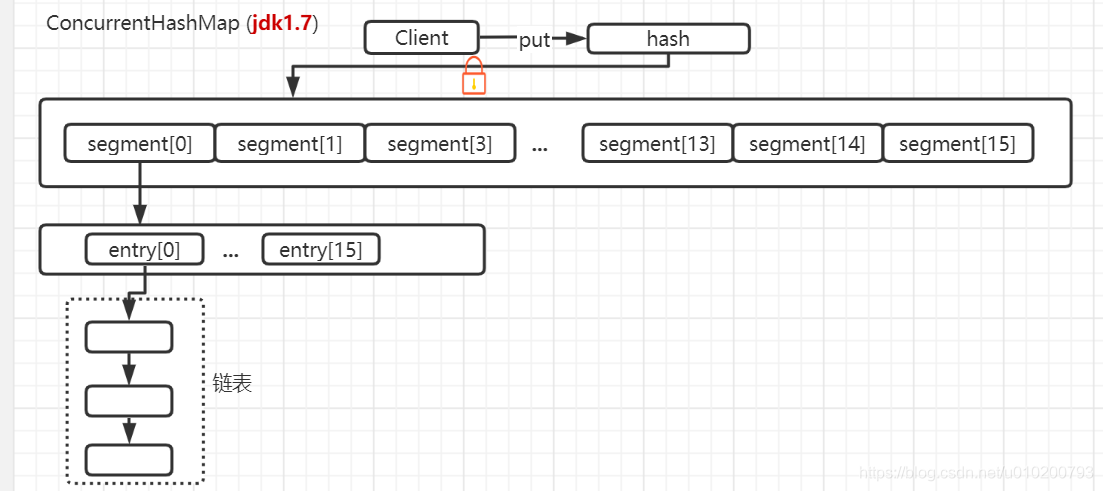
jdk1.7版本的主要內容:jdk1.7線上程安全方面主要利用到了分段鎖(segment),簡單的說一個CHM是由N(初始化16)個segment組成的,這樣的話就通過在每個segment端上加鎖來控制執行緒安全的。
如下圖:
jdk1.8 針對jdk1.7做了些改進 主要有如下:
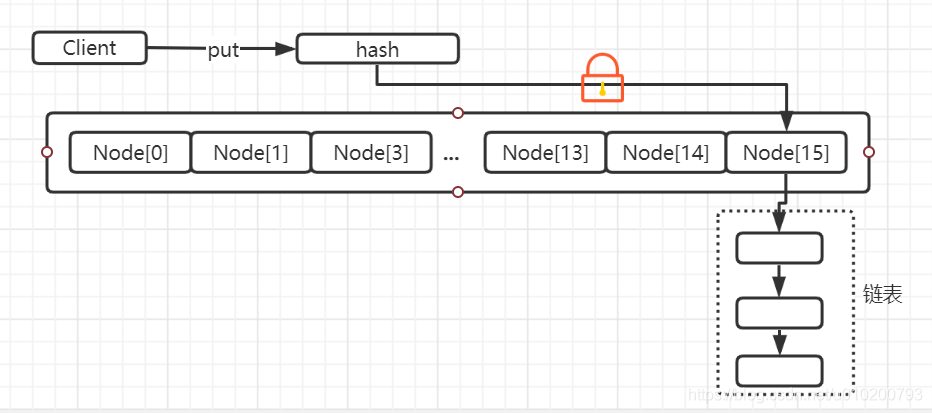
1、取消了segement分段鎖這部分
2、由原來的數位+單向連結串列 改為 陣列+單向連結串列(或紅黑樹)
原因: 1、去掉segment的分段鎖,使得鎖的範圍更小了,減少了阻塞的概率,提升鎖的效率。
2、陣列+連結串列,缺點:單向連結串列的時間複雜度為0(n),如果同一個節點hash碰撞過多的話,那麼這個節點的單向連結串列的長度就很可能成為整個map查詢的瓶頸了。因此優化了當單向連結串列的長度增加到了8(預設),那麼就會由原來的連結串列轉為紅黑樹,紅黑樹的查詢效率比連結串列要高很多0(logn),利用了二分查詢等機制,加速了查詢速度。
如下圖:
CHM的原理淺析
初始化
// 初始化陣列
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
// 迴圈存在多執行緒競爭的情況下
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0) // 以及被其他執行緒搶到了,開始初始化了
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try { // cas原子操作,標記已經在初始化了,與第一個if相對應
if ((tab = table) == null || tab.length == 0) {
// 預設初始值16 。
// private static final int DEFAULT_CAPACITY = 16;
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2); //擴容因子,下次需要擴容的大小(0.75)
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
//鍵不能為空,否則報錯
if (key == null || value == null) throw new NullPointerException();
//hash
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
// 初始化 陣列
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // 判斷是否為樹
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// static final int TREEIFY_THRESHOLD = 8;
if (binCount != 0) {
// 如果節點數,大於初始值預設8),那麼轉成紅黑樹
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
============
Class<?> ak = Node[].class;
ABASE = U.arrayBaseOffset(ak);
int scale = U.arrayIndexScale(ak);
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
=============
@SuppressWarnings("unchecked")
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
// 此方法 是通過獲取offset的偏移量 如上程式碼,實際等價於tab[i],那麼為什麼不這麼取值?
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
為什麼通過tabAt()單獨的去獲取值呢??不知直接用tab[i]更家直接的獲取值呢?
原因: 看程式碼上getObjectVolatile 雖然有volatile關鍵字,但是我們都知道,因為對 volatile 寫操作 happen-before 於 volatile 讀操作,
因此其他執行緒對 table 的修改均對 get 讀取可見的,由此可見直接tab[i] 不一定能獲取的最新的值。
雖然 table 陣列本身是增加了 volatile 屬性,但是「volatile 的陣列只針對陣列的參照具有volatile 的語意,而不是它的元素」。所以就直接用記憶體上的偏移量來獲取值。
個數計算
api 方法 - > chmMap.size();
這個計算計算個數由於涉及到多執行緒,那麼單純的計算個數是可能不準確的,因此這邊利用的分而治之的演演算法方式,來獲取最後的個數
/**
* Adds to count, and if table is too small and not already
* resizing, initiates transfer. If already resizing, helps
* perform transfer if work is available. Rechecks occupancy
* after a transfer to see if another resize is already needed
* because resizings are lagging additions.
*
* @param x the count to add
* @param check if <0, don't check resize, if <= 1 only check if uncontended
*/
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
// 求計算個數的table初始化 預設大小為2,後面也可以擴容
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean init = false;
try { // Initialize table
if (counterCells == as) {
CounterCell[] rs = new CounterCell[2];
rs[h & 1] = new CounterCell(x);
counterCells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}

擴容
資料遷移