python爬蟲實戰二:豆瓣讀書top250爬取
前言
本文主要介紹了對豆瓣讀書top250的資料爬取與資料預處理,主要運用的庫是re,request,Beautifulsoup,lxml。本文側重於總結我在爬蟲時遇到的一些坑,以及我對待這些坑的方法。文末附上了爬取的程式碼與資料。這是我的第一個爬蟲實戰:豆瓣電影top250的姊妹版。
爬蟲
定義下載連結函數
在下載網頁的時候,經常會遇到報錯的情況。為了減少不必要的報錯,下載的時候可以注意以下三點:
- 每次下載之間進行停頓,否則可能會遭到封禁
- 新增header,進行偽裝,假裝自己不是爬蟲。不過header的內容好像可以隨意取
- 新增編碼,decode = ‘utf-8’,否則爬取的內容可能是亂碼
# 引入庫
import re
import pandas as pd
import time
import urllib.request
from lxml.html import fromstring
from bs4 import BeautifulSoup
# 下載連結
def download(url):
print('Downloading:', url)
request = urllib.request.Request(url)
request.add_header('User-agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36') #進行偽裝
resp = urllib.request.urlopen(request)
html = resp.read().decode('utf-8') #utf-8編碼
time.sleep(3) #間隔3s,防止被封禁
return html
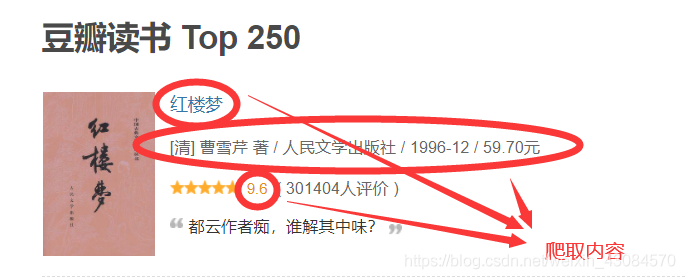
爬取內容的選擇
我在爬取豆瓣電影時,採用的方式是,下載每一個索引頁,然後再下載每個索引頁上的全部電影內容。總共有10個索引頁,每頁上有25個電影資訊,這樣就要下載 25*10+10=260 個網站。這樣做固然可以增加些許的爬取資訊,但是很明顯的一個弊端就是耗時較久。

而我在爬取豆瓣讀書時,採用的方式是,下載每一個索引頁,然後直接提取索引頁上的書籍資訊(在書名下面)。這樣僅需下載10個網頁!而且,當我按爬豆瓣電影的老方法,爬取豆瓣讀書時,我發現自己很難定位到作者這個資訊。這啟示我們要靈活選擇爬取內容的方式。
定位方式的選擇
第一篇豆瓣電影中提到過爬蟲定位有三種方法:
- 通過正規表示式定位
- 通過Beautifulsoup中find函數定位
- 通過lxml中Xpath定位
那麼具體該用那種方法呢?我的原則是:簡單為上
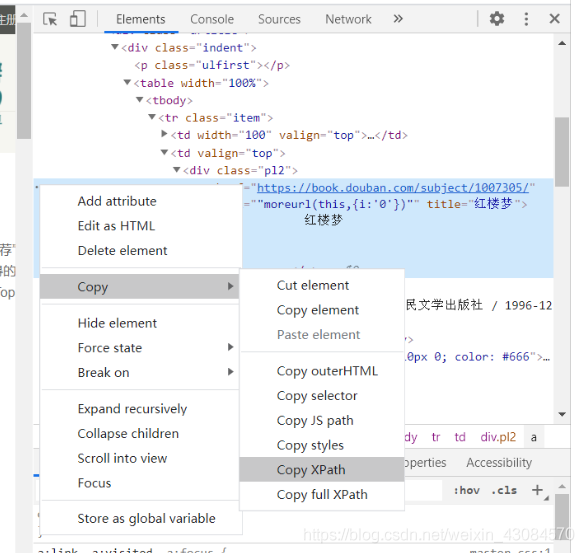
我個人建議首選Xpath,因為最簡單無腦,直接按 F12,然後選中要爬取的內容,右鍵copy xpath,其次可以使用Beautifulsoup中的find函數定位,不到萬不得已,儘量不用正規表示式。
例如讀取書名時採用xpath的定位方法,不過這裡有兩點要注意:
- xpath中需要去掉 /tbody
- 需要用 .strip() 去掉換行符和空格
# 待爬取內容
name = []
rate = []
info = []
# 迴圈爬取每頁內容
for k in range(10):
url = download('https://book.douban.com/top250?start={}'.format(k*25))
tree = fromstring(url)
soup = BeautifulSoup(url)
#找出該頁所有書籍資訊
for k in range(25):
name.append(tree.xpath('//*[@id="content"]/div/div[1]/div/table[{}]/tr/td[2]/div[1]/a/text()'.format(k+1))[0].strip())
rate.append(soup.find_all('span',{'class':'rating_nums'})[k].get_text())
info.append(soup.find_all('p',{'class':'pl'})[k].get_text())
# 拼接
book_data = pd.concat([name_pd, rate_pd, info_pd], axis=1)
book_data.columns=['書名', '評分', '資訊']
book_data.head()
資料預處理
接下來將以上讀取到的資料進行預處理:
- 將變數 資訊 分割成 作家,出版社,出版年,定價
- 存在兩個異常資料,需要手動調整
- 用正規表示式提取 出版年中的年份,定價中的數位部分
- 過河拆橋,刪去 資訊 變數
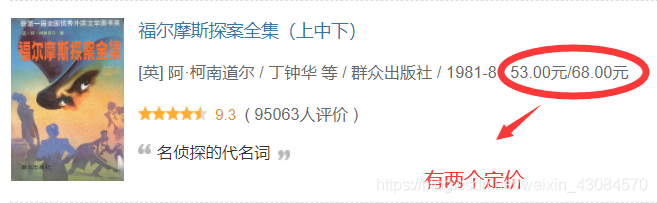
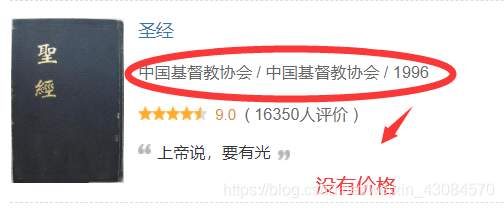
需要注意的是 作家,出版社,出版年,定價 是按位元置索引找出來的,但是這裡存在兩個異常資料,需要自己手動調整:
具體程式碼如下:
# 資料預處理:
# 將資訊分割
Info = book_data['資訊'].apply(lambda x: x.split('/'))
# 提取資訊
book_data['作家'] = Info.apply(lambda x: x[0])
book_data['出版社'] = Info.apply(lambda x: x[-3])
book_data['出版年'] = Info.apply(lambda x: x[-2])
book_data['定價'] = Info.apply(lambda x: x[-1])
# 手動調整
book_data.iloc[9,4] = '群眾出版社'
book_data.iloc[9,5] = '1981'
book_data.iloc[184,5] = '1996'
book_data.iloc[184,6] = '0'
#提取年份
f = lambda x: re.search('[0-9]{4,4}', x).group()
book_data['出版年'] = book_data['出版年'].apply(f)
#提取定價
g = lambda x: re.search('([0-9]+\.[0-9]+|[0-9]+)', x).group()
book_data['定價'] = book_data['定價'].apply(g)
book_data = book_data.drop(['資訊'], axis =1)
# 輸出
outputpath='c:/Users/zxw/Desktop/修身/與自己/資料分析/資料分析/爬蟲/豆瓣讀書/book.csv' ## 路徑需要自己改!
book_data.to_csv(outputpath,sep=',',index=False,header=True,encoding='utf_8_sig')
後記
目前自己對爬蟲算是初步瞭解了,接下來可能會考慮學習 機器學習 的內容,先從 An Introduction to Statistical Learning with R 寫起吧