Python-docx實戰:同事要我幫忙補寫178份日報!別吧
前言
不久前,一個同事有個專案要向領導交差,其中一部分工作是根據 excel 表中的每日資料,按格式整理成日報寫入 word。好傢伙!足足 178 天的量要補,如果要靠複製貼上,豈不是肝到吐血,(你給我自己解決啊!)好吧ojbk,是時候祭出 Python 辦公自動化了。

一、基礎資料整理
首先讓我們來看看資料樣本和輸出檔案的需求(敏感資料已做和諧處理):原始 excel 檔案中有 n 個子表,每個子表為一天的資料,存在無記錄和有記錄(部門數 ≥ 1,每個部門記錄數 ≥ 1)兩種情況,需分別整理成兩種日報,一為純文字描述,二為附帶表格的檔案。


擼起袖子,開罵!哦不,開始寫程式碼!
先將子表合成一個,便於統一觀察每日資料記錄的規律,也方便後期處理。使用 xlrd 庫讀表,獲取工作簿中的活動表名,再使用 pandas 庫遍歷子表以合併,dataframe 格式的資料對 excel 表的相性絕佳。
def merge_sheet(filepath): # 合併多個同表頭的子表
wb = xlrd.open_workbook(filepath)
sheets = wb.sheet_names()
df_total = pd.DataFrame()
for name in sheets:
df = pd.read_excel(filepath, sheet_name=name)
df_total = df_total.append(df)
df_total.to_excel("merge.xlsx", index=False)
二、輸出兩種日報
(一)、純文字檔案
根據需要輸出的日報樣式,輸出無記錄的日報只需讀取【日期】列和【填報部門】列,將【填報部門】列為無的日期段按每日輸出即可。觀察原表資料,直接篩選無填報記錄的資料丟到命名為「無」的子表裡。
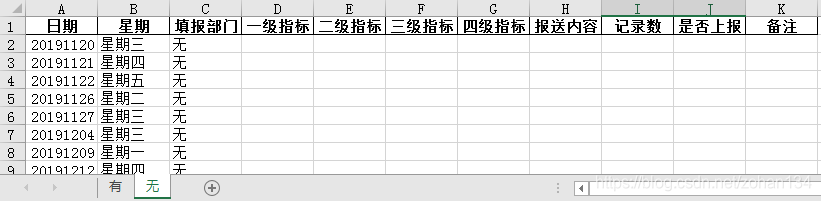
這裡也可以利用 .groupby() 對【填報部門】列分組,取「無」的那一組,可是要注意一點:雖然 Python 很強大,但不需要將所有事情都交給 Python 做。
匯入庫和模組如下:
import pandas as pd
import xlrd
from docx import Document
from docx.shared import Pt
from docx.shared import Inches
from docx.oxml.ns import qn
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.enum.section import WD_ORIENTATION
基本流程很簡單,讀入無填報記錄的資料,按日期輸出 word 檔案。
def wu_to_word(filepath):
df = pd.read_excel(filepath, sheet_name="無")
date_list = list(df['日期'])
for d in date_list:
filename = wordname+str(d)+").docx" # 輸出的word檔名
title = "("+str(d)[:4]+"."+str(d)[4:6]+"."+str(d)[6:8]+")" # 副標題日期XXXX.XX.XX
word = str(d)[:4]+"年"+str(d)[4:6]+"月"+str(d)[6:8]+"日" # 開頭、落款日期XXXX年XX月XX日
wu_doc(title, word, filename)
print(f"檔案:{filename},{title},{word} 已儲存")
每份檔案都會用到的同樣的內容也可以先設定好。
wordname = 「XX公司業務資料表(日報」
all_title = " XX公司業務報告"
生成 word 內容,不加表格的情況下還是比較容易實現的,注意調整好格式。
def wu_doc(title,word,filename): # 傳入副標題日期,文段開頭及落款的日期,檔名
doc = Document() # 建立檔案物件
section = doc.sections[0] # 獲取頁面節點
section.orientation = WD_ORIENTATION.LANDSCAPE # 頁面方向設為橫版
new_width, new_height = section.page_height, section.page_width # 將原始長寬互換,實現將豎版頁面變為橫版
section.page_width = new_width
section.page_height = new_height
# 段落的全域性設定
doc.styles['Normal'].font.name = u'宋體' # 字型
doc.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋體') # 中文字型需再新增這個設定
doc.styles['Normal'].font.size = Pt(14) # 字號 四號對應14
t1 = doc.add_paragraph() # 新增一個段落
t1.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中
_t1 = t1.add_run(all_title) # 新增段落內容(大標題)
_t1.bold = True # 加粗
_t1.font.size = Pt(22)
t2 = doc.add_paragraph() # 再新增一個段落
t2.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中
_t2 = t2.add_run(title + "\n") # 新增段落內容(副標題)
_t2.bold = True
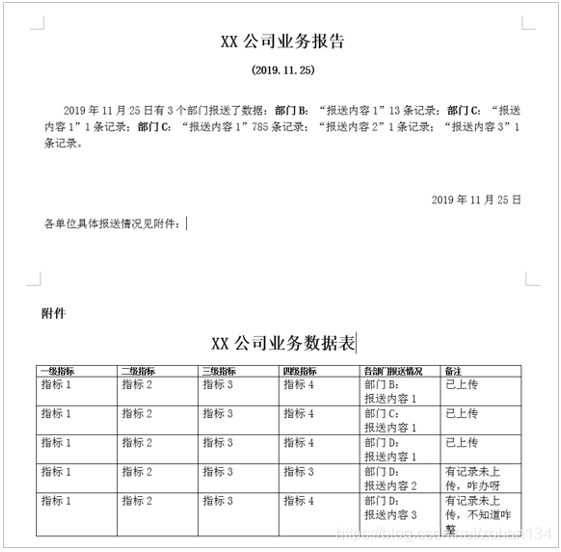
doc.add_paragraph(word + "無記錄。\n\n").paragraph_format.first_line_indent = Inches(0.35) # 新增段落同時新增內容,並設定首行縮排
doc.add_paragraph(word).paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT # 落款日期右對齊
doc.save(dir+filename) # 按路徑+檔名儲存
執行!104 份無填報記錄的日報就寫好啦,乾脆就這樣交差吧,剩下的不想研究了哈哈哈。

(二)、附表格檔案
有報送記錄的資料處理起來相對複雜一點,先看一下原始資料。
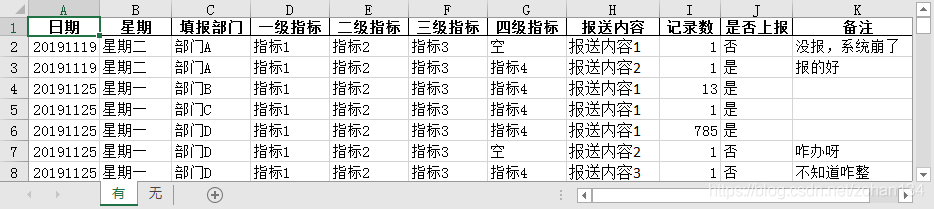
比如 X 年 X 月 X 日,有 N 個部門填報了資料,根據檔案樣例,文段描述部分需要整理成如下格式:
部門 A:「報送內容1」 X條記錄;「報送內容2」 Y條記錄;部門 B:……;部門 C:……;
而附件表格部分需整理成如下格式,可以預想把每一行需要的資料整理一個 list,按行寫入表格:
| 一級指標 | 二級指標 | 三級指標 | 四級指標 | 各部門報送情況 | 備註 |
|---|---|---|---|---|---|
| lalala | hahaha | balabala | 若為空則沿用上級 | 部門A:報送內容1 | 有記錄未上傳,沒報,系統崩了 |
| aaa | bbb | ccc | ddd | 部門A:報送內容2 | 已上傳,報的好 |
| … | … | … | … | 部門B:報送內容1 | … |
基本流程類似,讀表後先按日期分組,每一組含一天中的一個或多個部門資料,再生成某一天的附件需要的表格,接著整理文段描述,最後按日期輸出每一天的 word 檔案。
def what_to_word(filepath):
df = pd.read_excel(filepath, sheet_name="有")
df.fillna('', inplace=True) # 替換nan值為空字元
dates = [] # 日期列表
df_total = [] # 分日期存的所有df
list_total = [] # 每一份word中需要的表資料合集
for d in df.groupby('日期'):
dates.append(d[0])
df_total.append(d[1])
for index,date in enumerate(dates):
list_oneday = [] # 某一個word所需的表資料
for row in range(len(df_total[index])):
list_row = get_table_data(df_total, index, row) # 其中一行資料
list_oneday.append(list_row)
list_total.append(list_oneday)
for index, date in enumerate(dates):
filename = wordname+str(date)+").docx" # 輸出的word檔名
title = "("+str(date)[:4]+"."+str(date)[4:6]+"."+str(date)[6:8]+")" # 副標題日期XXXX.XX.XX
word = str(date)[:4]+"年"+str(date)[4:6]+"月"+str(date)[6:8]+"日" # 開頭、落款日期XXXX年XX月XX日
sentence = get_sentence(df_total, index) # 某一天的文段描述
what_doc(title, word, sentence, list_total[index], filename) #傳入需要的內容後輸出檔案
print(f"檔案:{filename} 已儲存")
下面讓我們分別看看整理表格、整理文段、輸出檔案是如何實現的。
1、整理表格
獲取 excel 表中的一行資料(說明:df_total[df_index] 為一個 dataframe,其 values 為一個二維的 numpy 陣列),整理各級指標、各部門報送情況和備註,返回一個列表。
def get_table_data(df_total, df_index, table_row):
list1 = df_total[df_index].values[table_row] # excel表中的一行
list2 = list1[3:7] # 一至四級指標
for i in range(len(list2)): # 當前指標為空則沿用上級指標
if list2[i] == '空' and i != 0:
list2[i] = list2[i - 1]
content = list1[2] + ":\n" + list1[-4] # 報送內容
if '否' in list1[-2]: # 備註
remark = '有記錄未上傳,' + str(list1[-1])
else:
remark = '已上傳'
list3 = list2.tolist() # 需填入word中的表資料,由numpy陣列轉為list列表
list3.append(str(content))
list3.append(str(remark))
return list3
2、整理文段
對當日資料中的【填報部門】列中的唯一值計數,得知有 N 個部門填報了資料。對部門分組,獲取其相關資訊,組合成 [(報送內容,記錄數,是否上報,備註)] 的格式,再整理出形如 「有N個部門報送了資料:部門X:「 報送內容XXX 」 X條記錄;… …」 的描述串。
def get_sentence(df_total, df_index):
df_oneday = df_total[df_index]
num = df_oneday['填報部門'].nunique() # 部門的數量
group = [] # 部門名稱
detail = [] # 組合某個部門的資料,其中元素為元組格式(, , , )
info = '' # 報送情況描述
for item in df_oneday.groupby('填報部門'):
group.append(item[0])
detail.append(
list(
zip(
list(item[1]['報送內容']),
list(item[1]['記錄數']),
list(item[1]['是否上報']),
list(item[1]['備註'])
)
)
)
for index, g in enumerate(group): # 整理每個部門的填報情況
mes = str(g)+':' # 部門開頭
for i in range(len(detail[index])):
_mes = detail[index][i]
if int(_mes[1])>0:
mes = mes + f'「{_mes[0]}」{_mes[1]}條記錄;'
info = info + mes
info = info[:-1]+"。" #將最後一個分號替換成句號
sentence = f"有{num}個部門報送了資料:{info}"
return sentence
3、輸出檔案
(耐心警告!)調整 word 中的文字和表格樣式的操作比較繁瑣,需一步一步設定,預設表頭如下:
table_title = [‘一級指標’, ‘二級指標’, ‘三級指標’, ‘四級指標’, ‘各部門報送情況’, ‘備註’]
其他詳見程式碼註釋。
def what_doc(title, word, sentence, table, filename): # 傳入副標題日期,開頭/落款日期,文段,表資料,檔名
doc = Document()
section = doc.sections[0]
new_width, new_height = section.page_height, section.page_width
section.orientation = WD_ORIENTATION.LANDSCAPE
section.page_width = new_width
section.page_height = new_height
# 段落的全域性設定
doc.styles['Normal'].font.name = u'宋體' # 字型
doc.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋體') # 中文字型需再新增這個設定
doc.styles['Normal'].font.size = Pt(14) # 字號 四號對應14
t1 = doc.add_paragraph() # 大標題
t1.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中
_t1 = t1.add_run(all_title)
_t1.bold = True
_t1.font.size = Pt(22)
t2 = doc.add_paragraph() # 副標題
t2.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中
_t2 = t2.add_run(title + "\n")
_t2.bold = True
doc.add_paragraph(word + sentence +"\n\n").paragraph_format.first_line_indent = Inches(0.35) # 首行縮排
doc.add_paragraph(word).paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT # 右對齊
doc.add_paragraph("各部門具體報送情況見附件:")
doc.add_page_break() # 分頁---------------------------------------------------------------
fujian = doc.add_paragraph().add_run("\n附件")
fujian.bold = True
fujian.font.size = Pt(16)
t3 = doc.add_paragraph() # 附件大標題
t3.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中
_t3 = t3.add_run("XX公司業務資料表")
_t3.bold = True
_t3.font.size = Pt(22)
rows = len(table)+1
word_table = doc.add_table(rows=rows, cols=6, style='Table Grid') # 建立rows行、6列的表格
word_table.autofit=True # 新增框線
table = [table_title] + table # 固定的表頭+表資料
for row in range(rows): # 寫入表格
cells = word_table.rows[row].cells
for col in range(6):
cells[col].text = str(table[row][col])
for i in range(len(word_table.rows)): # 遍歷行列,逐格修改樣式
for j in range(len(word_table.columns)):
for par in word_table.cell(i, j).paragraphs: # 修改字號
for run in par.runs:
run.font.size = Pt(10.5)
for par in word_table.cell(0, j).paragraphs: # 第一行加粗
for run in par.runs:
run.bold = True
doc.save(dir+filename)
執行!74份有記錄的日報也寫好啦,一共178份。
一頓操作猛如虎,總算是批次生成了日報,盒飯該加個雞腿子了吧… …
