python爬蟲練習(1)批次下載素材公社(‘https://www.tooopen.com/img‘)任意型別圖片
2020-09-21 14:00:15
**整體思路大致就是 輸入你想要爬取的圖片分類 加上你想下載的幾頁 即可實現批次下載
下面展示分步驟程式碼+具體的思路:
一、生成一個儲存圖片的資料夾
這裡是把資料夾建立在.py檔案的同級目錄了 可以根據自己設定
path = os.getcwd() #獲取當前檔案所在路徑
path_name = path + '/' + '素材公社'
if not os.path.exists(path_name):
os.mkdir(path_name)
二、獲取圖片分類選項和url 生成字典
這裡要下載的分類選項不包括風景圖片 人物圖片等大類
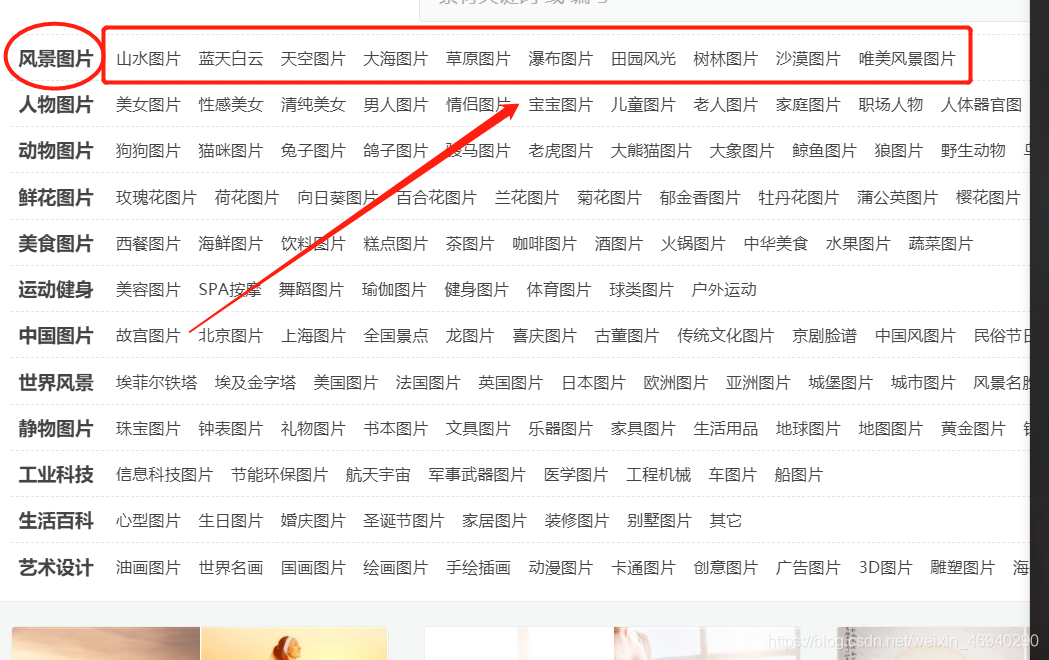
觀察連結末尾在推導式中用if條件語句可將大類選項篩選掉
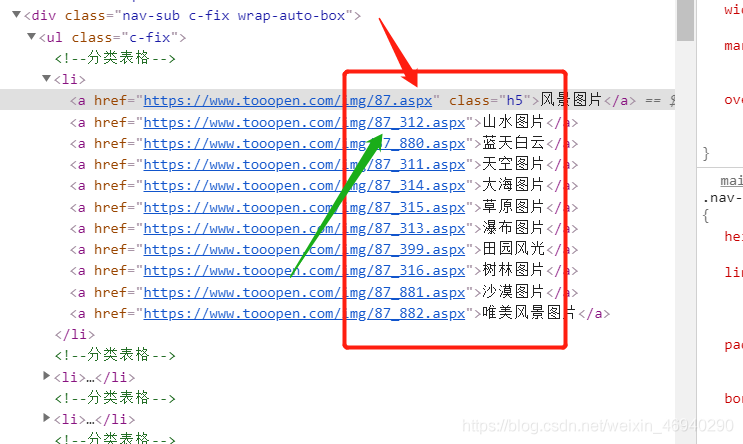
def get_meun():
url = 'https://www.tooopen.com/img'
res = requests.get(url, headers=headers)
html = etree.HTML(res.text)
urls = html.xpath('/html/body/div[3]/div/div/ul/li/a/@href')
names = html.xpath('/html/body/div[3]/div//div/ul/li/a/text()')
dic = {k: v for k, v in zip(names, urls) if '_' in v}
return dic
三 、 下載圖片
檢查原始碼觀察我們發現
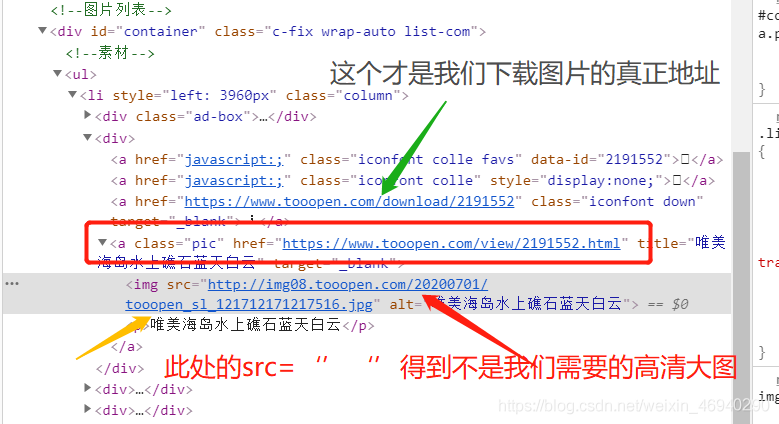
所以
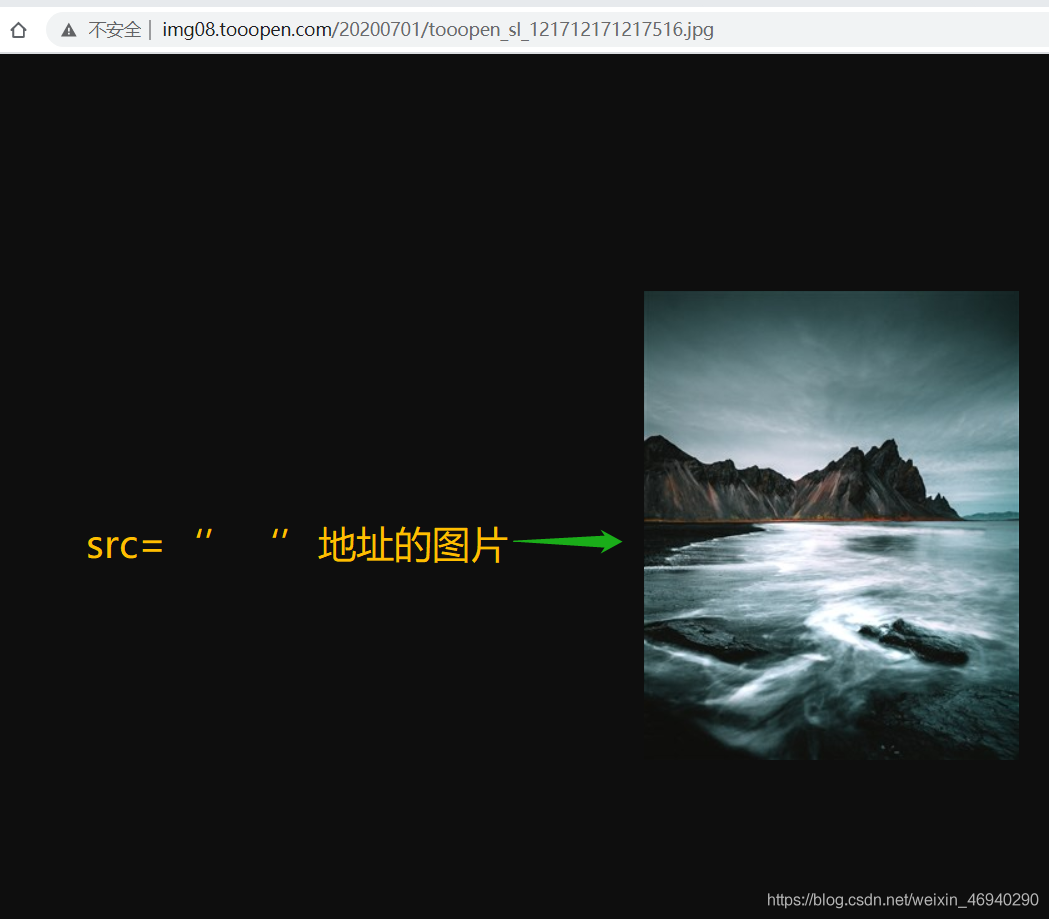
進入圖片真正的下載地址 尋找高清大圖的下載連結
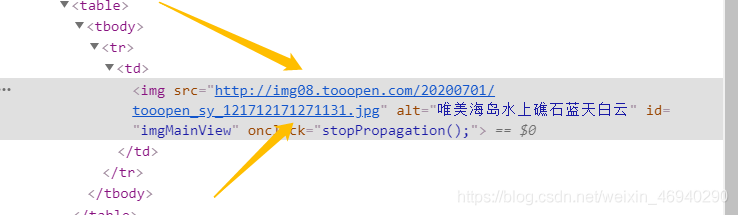
此處的url就是 我們需要的高清大圖的連結 下載即可
程式碼如下:
# 下載圖片
def download_img(url, start, end):
count = 0 # 計數 下載多少張圖片
url1 = url.replace('.aspx', '_1_{}.aspx')# 每頁的真正網頁格式
img_urls1 = [] #存放圖片下載地址
img_names = []
for i in range(start, end + 1):
url2 = url1.format(i)
res = requests.get(url2, headers=headers).text
img_url = re.findall(r'a class="pic" href="(.*?)"', res)
img_name = etree.HTML(res).xpath('/html/body/div[5]/ul/li/div/a/img/@alt')
# img_names.append(img_name)
# img_urls1.append(img_url)
img_urls1 += img_url
img_names += img_name
# print(img_urls1)
# print(img_names)
img_urls2 = []
for j in img_urls1:
res2 = requests.get(j, headers=headers).text
img_url2 = etree.HTML(res2).xpath('/html/body/table/tr/td/img/@src')
#img_url2 = re.findall(r'<img src="(.*?)" title=' alt=', res2)# 圖片真正的下載連結
img_urls2 += img_url2
# print(img_urls2)
for u, n in zip(img_urls2, img_names):
file_name = n + '.jpg'
img_content = requests.get(u, headers=headers).content
with open(path_name + '/' + file_name, 'wb') as f:
f.write(img_content)
count += 1
time.sleep(random.randint(1,2)) #美爬取一張圖片 休眠 防止存取頻率過快被反爬
print('\n' + '-' * 15 + ' 已成功為您下載{}張圖片 '.format(count) + '-' * 15 + '\n')
四、輸入我們想要下載圖片的分類和頁數 啟動圖片下載器開始下載
def main():
pic_dic = get_meun()
choice = input('請輸入您想下載的圖片型別:')
url3 = pic_dic.get(choice)
print('=' * 15 + ' 圖片下載器啟動 ' + '=' * 15)
start_page = int(input("請輸入起始頁碼: "))
end_page = int(input("請輸入結束頁碼: "))
print('~已開始為您下載~')
download_img(url3, start_page, end_page)
五、為了防止被反爬我們可以多用一些user_agent 偽裝請求頭
user_agent = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
六、下面是我寫的程式碼
import requests
from lxml import etree
import re
import os
import time
import random
# 定義在當前.py檔案的目錄下建立資料夾
path = os.getcwd()
path_name = path + '/' + '素材公社'
if not os.path.exists(path_name):
os.mkdir(path_name)
# 獲取圖片分類選項表單 生成字典
def get_meun():
url = 'https://www.tooopen.com/img'
res = requests.get(url, headers=headers)
html = etree.HTML(res.text)
urls = html.xpath('/html/body/div[3]/div/div/ul/li/a/@href')
names = html.xpath('/html/body/div[3]/div//div/ul/li/a/text()')
dic = {k: v for k, v in zip(names, urls) if '_' in v}
return dic
# 下載圖片
def download_img(url, start, end):
count = 0 # 計數 下載多少張圖片
url1 = url.replace('.aspx', '_1_{}.aspx')# 每頁的真正網頁格式
img_urls1 = [] #存放圖片下載地址
img_names = []
for i in range(start, end + 1):
url2 = url1.format(i)
res = requests.get(url2, headers=headers).text
img_url = re.findall(r'a class="pic" href="(.*?)"', res)
img_name = etree.HTML(res).xpath('/html/body/div[5]/ul/li/div/a/img/@alt')
# img_names.append(img_name)
# img_urls1.append(img_url)
img_urls1 += img_url
img_names += img_name
# print(img_urls1)
# print(img_names)
img_urls2 = []
for j in img_urls1:
res2 = requests.get(j, headers=headers).text
img_url2 = etree.HTML(res2).xpath('/html/body/table/tr/td/img/@src')
#img_url2 = re.findall(r'<img src="(.*?)" title=' alt=', res2)# 圖片真正的下載連結
img_urls2 += img_url2
# print(img_urls2)
for u, n in zip(img_urls2, img_names):
file_name = n + '.jpg'
img_content = requests.get(u, headers=headers).content
with open(path_name + '/' + file_name, 'wb') as f:
f.write(img_content)
count += 1
time.sleep(random.randint(1,2)) #美爬取一張圖片 休眠 防止存取頻率過快被反爬
print('\n' + '-' * 15 + ' 已成功為您下載{}張圖片 '.format(count) + '-' * 15 + '\n')
def main():
pic_dic = get_meun()
choice = input('請輸入您想下載的圖片型別:')
url3 = pic_dic.get(choice)
print('=' * 15 + ' 圖片下載器啟動 ' + '=' * 15)
start_page = int(input("請輸入起始頁碼: "))
end_page = int(input("請輸入結束頁碼: "))
print('~已開始為您下載~')
download_img(url3, start_page, end_page)
user_agent = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
if __name__ == '__main__':
headers = {
"Referer": "https://www.tooopen.com/img",
"User_Agent": random.choice(user_agent)
}
main()
總結 :
簡單爬取資料思路原理:
獲取網頁資訊—解析頁面資訊—模擬翻頁—匹配所需資料—下載到本地檔案