MySQL DISTINCT語句
在本教學中,您將學習如何使用MySQL DISTINCT子句與SELECT語句一起組合來消除結果集中的重複行。
1. MySQL DISTINCT子句簡介
從表中查詢資料時,可能會收到重複的行記錄。為了刪除這些重複行,可以在SELECT語句中使用DISTINCT子句。
DISTINCT子句的語法如下:
SELECT DISTINCT
columns
FROM
table_name
WHERE
where_conditions;
2. MySQL DISTINCT範例
下面來看看一個使用DISTINCT子句從employees表中選擇員工的唯一姓氏(lastName)的簡單範例。
首先,使用SELECT語句從employees表中查詢員工的姓氏(lastName),如下所示:
SELECT
lastname
FROM
employees
ORDER BY lastname;
執行上面查詢語句,得到以下結果 -
mysql> SELECT lastname FROM employees ORDER BY lastname;
+-----------+
| lastname |
+-----------+
| Bondur |
| Bondur |
| Bott |
| Bow |
| Castillo |
| Firrelli |
| Firrelli |
| Fixter |
| Gerard |
| Hernandez |
| Jennings |
| Jones |
| Kato |
| King |
| Marsh |
| Murphy |
| Nishi |
| Patterson |
| Patterson |
| Patterson |
| Thompson |
| Tseng |
| Vanauf |
+-----------+
23 rows in set
可看到上面結果中,有好些結果是重複的,比如:Bondur,Firrelli等,那如何做到相同的結果只顯示一個呢?要刪除重複的姓氏,請將DISTINCT子句新增到SELECT語句中,如下所示:
SELECT DISTINCT
lastname
FROM
employees
ORDER BY lastname;
執行上面查詢,得到以下輸出結果 -
mysql> SELECT DISTINCT lastname FROM employees ORDER BY lastname;
+-----------+
| lastname |
+-----------+
| Bondur |
| Bott |
| Bow |
| Castillo |
| Firrelli |
| Fixter |
| Gerard |
| Hernandez |
| Jennings |
| Jones |
| Kato |
| King |
| Marsh |
| Murphy |
| Nishi |
| Patterson |
| Thompson |
| Tseng |
| Vanauf |
+-----------+
19 rows in set
當使用DISTINCT子句時,重複的姓氏(lastname)在結果集中被消除。
3. MySQL DISTINCT和NULL值
如果列具有NULL值,並且對該列使用DISTINCT子句,MySQL將保留一個NULL值,並刪除其它的NULL值,因為DISTINCT子句將所有NULL值視為相同的值。
例如,在customers表中,有很多行的州(state)列是NULL值。 當使用DISTINCT子句來查詢客戶所在的州時,我們將看到唯一的州和NULL值,如下查詢所示:
SELECT DISTINCT
state
FROM
customers;
執行上面查詢語句後,輸出結果如下 -
mysql> SELECT DISTINCT state FROM customers;
+---------------+
| state |
+---------------+
| NULL |
| NV |
| Victoria |
| CA |
| NY |
| PA |
| CT |
| MA |
| Osaka |
| BC |
| Qubec |
| Isle of Wight |
| NSW |
| NJ |
| Queensland |
| Co. Cork |
| Pretoria |
| NH |
| Tokyo |
+---------------+
19 rows in set
4. MySQL DISTINCT在多列上的使用
可以使用具有多個列的DISTINCT子句。 在這種情況下,MySQL使用所有列的組合來確定結果集中行的唯一性。
例如,要從customers表中獲取城市(city)和州(state)的唯一組合,可以使用以下查詢:
SELECT DISTINCT
state, city
FROM
customers
WHERE
state IS NOT NULL
ORDER BY state , city;
執行上面查詢,得到以下結果 -
mysql> SELECT DISTINCT state, city FROM customers WHERE state IS NOT NULL ORDER BY state ,city;
+---------------+----------------+
| state | city |
+---------------+----------------+
| BC | Tsawassen |
| BC | Vancouver |
| CA | Brisbane |
| CA | Burbank |
| CA | Burlingame |
| CA | Glendale |
| CA | Los Angeles |
| CA | Pasadena |
| CA | San Diego |
| CA | San Francisco |
| CA | San Jose |
| CA | San Rafael |
| Co. Cork | Cork |
| CT | Bridgewater |
| CT | Glendale |
| CT | New Haven |
| Isle of Wight | Cowes |
| MA | Boston |
| MA | Brickhaven |
| MA | Cambridge |
| MA | New Bedford |
| NH | Nashua |
| NJ | Newark |
| NSW | Chatswood |
| NSW | North Sydney |
| NV | Las Vegas |
| NY | NYC |
| NY | White Plains |
| Osaka | Kita-ku |
| PA | Allentown |
| PA | Philadelphia |
| Pretoria | Hatfield |
| Qubec | Montral |
| Queensland | South Brisbane |
| Tokyo | Minato-ku |
| Victoria | Glen Waverly |
| Victoria | Melbourne |
+---------------+----------------+
37 rows in set
沒有DISTINCT子句,將查詢獲得州(state)和城市(city)的重複組合如下:
SELECT
state, city
FROM
customers
WHERE
state IS NOT NULL
ORDER BY state , city;
執行上面查詢,得到以下結果 -
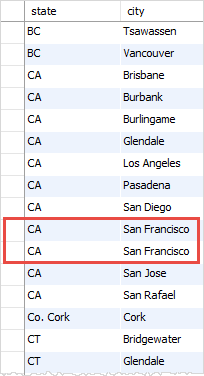
5. DISTINCT子句與GROUP BY子句比較
如果在SELECT語句中使用GROUP BY子句,而不使用聚合函式,則GROUP BY子句的行為與DISTINCT子句類似。
以下語句使用GROUP BY子句來選擇customers表中客戶的唯一state列的值。
SELECT
state
FROM
customers
GROUP BY state;
執行上面查詢,得到以下結果 -
mysql> SELECT state FROM customers GROUP BY state;
+---------------+
| state |
+---------------+
| NULL |
| BC |
| CA |
| Co. Cork |
| CT |
| Isle of Wight |
| MA |
| NH |
| NJ |
| NSW |
| NV |
| NY |
| Osaka |
| PA |
| Pretoria |
| Qubec |
| Queensland |
| Tokyo |
| Victoria |
+---------------+
19 rows in set
可以通過使用DISTINCT子句來實現類似的結果:
mysql> SELECT DISTINCT state FROM customers;
+---------------+
| state |
+---------------+
| NULL |
| NV |
| Victoria |
| CA |
| NY |
| PA |
| CT |
| MA |
| Osaka |
| BC |
| Qubec |
| Isle of Wight |
| NSW |
| NJ |
| Queensland |
| Co. Cork |
| Pretoria |
| NH |
| Tokyo |
+---------------+
19 rows in set
一般而言,DISTINCT子句是GROUP BY子句的特殊情況。 DISTINCT子句和GROUP BY子句之間的區別是GROUP BY子句可對結果集進行排序,而DISTINCT子句不進行排序。
如果將ORDER BY子句新增到使用DISTINCT子句的語句中,則結果集將被排序,並且與使用GROUP BY子句的語句返回的結果集相同。
SELECT DISTINCT
state
FROM
customers
ORDER BY state;
執行上面查詢,得到以下結果 -
mysql> SELECT DISTINCT state FROM customers ORDER BY state;
+---------------+
| state |
+---------------+
| NULL |
| BC |
| CA |
| Co. Cork |
| CT |
| Isle of Wight |
| MA |
| NH |
| NJ |
| NSW |
| NV |
| NY |
| Osaka |
| PA |
| Pretoria |
| Qubec |
| Queensland |
| Tokyo |
| Victoria |
+---------------+
19 rows in set
6. MySQL DISTINCT和聚合函式
可以使用具有聚合函式(例如SUM,AVG和COUNT)的DISTINCT子句中,在MySQL將聚合函式應用於結果集之前刪除重複的行。
例如,要計算美國客戶的唯一state列的值,可以使用以下查詢:
SELECT
COUNT(DISTINCT state)
FROM
customers
WHERE
country = 'USA';
執行上面查詢,得到以下結果 -
mysql> SELECT COUNT(DISTINCT state) FROM customers WHERE country = 'USA';
+-----------------------+
| COUNT(DISTINCT state) |
+-----------------------+
| 8 |
+-----------------------+
1 row in set
7. MySQL DISTINCT與LIMIT子句
如果要將DISTINCT子句與LIMIT子句一起使用,MySQL會在查詢LIMIT子句中指定的唯一行數時立即停止搜尋。
以下查詢customers表中的前3個非空(NOT NULL)唯一state列的值。
mysql> SELECT DISTINCT state FROM customers WHERE state IS NOT NULL LIMIT 3;
+----------+
| state |
+----------+
| NV |
| Victoria |
| CA |
+----------+
3 rows in set
在本教學中,我們學習了使用MySQL DISTINCT子句的各種方法,例如消除重複行和計數非NULL值。