PostgreSQL分組(GROUP BY子句)
PostgreSQL GROUP BY子句用於將具有相同資料的表中的這些行分組在一起。 它與SELECT語句一起使用。
GROUP BY子句通過多個記錄收集資料,並將結果分組到一個或多個列。 它也用於減少輸出中的冗餘。
語法:
SELECT column-list
FROM table_name
WHERE [conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
注意:在
GROUP BY多個列的情況下,您使用的任何列進行分組時,要確保這些列應在列表中可用。
看看下面的例子:
我們來看一下表「EMPLOYEES」,具有以下資料。
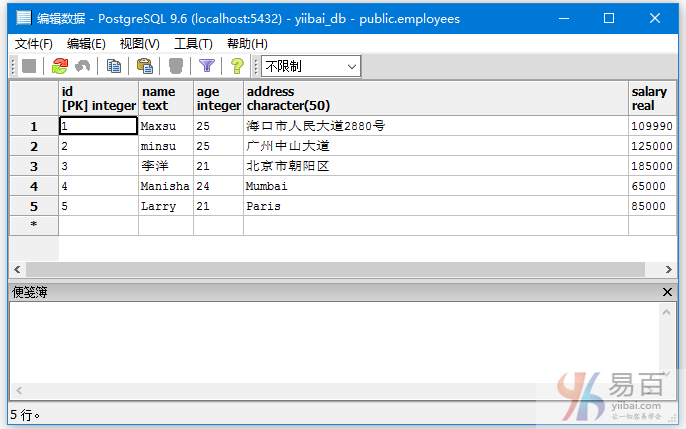
執行以下查詢:
SELECT NAME, SUM(SALARY)
FROM EMPLOYEES
GROUP BY NAME;
查詢得到如下結果 -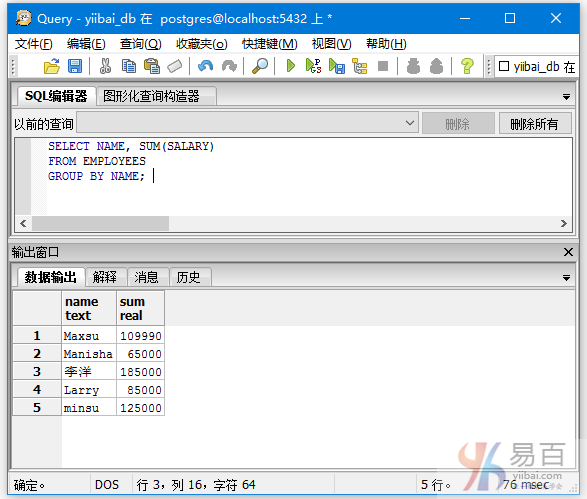
如何減少冗餘資料:
再來看看下面這個例子:
我們在「EMPLOYEES」表中插入一些重複的記錄。新增以下資料:
INSERT INTO EMPLOYEES VALUES (6, '李洋', 24, '深圳市福田區中山路', 135000);
INSERT INTO EMPLOYEES VALUES (7, 'Manisha', 19, 'Noida', 125000);
INSERT INTO EMPLOYEES VALUES (8, 'Larry', 45, 'Texas', 165000);
現在有以下資料,有一些資料是重複的 -
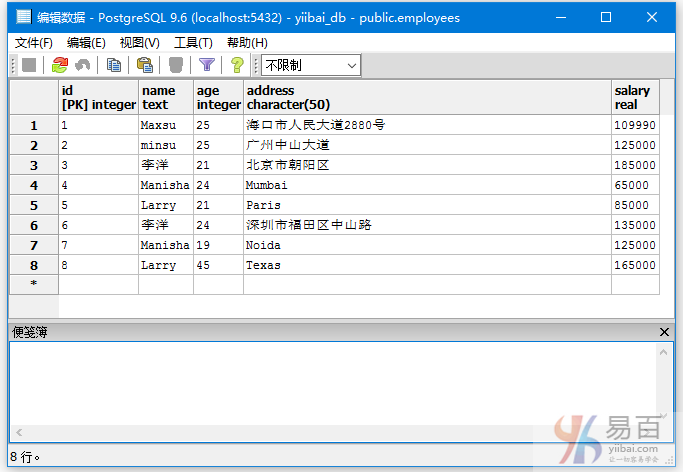
執行以下查詢以消除冗餘:
SELECT NAME, SUM(SALARY)
FROM EMPLOYEES
GROUP BY NAME;
上面的SQL語句是按名字(NAME)執行分組統計每個名字的薪水總額,如:兩個名字叫作李洋的薪水總額是:320000等等,得到結果如下 -
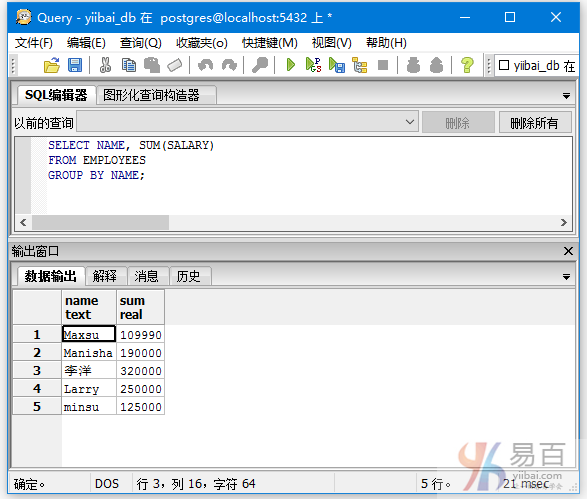
在上面的例子中,當我們使用GROUP BY NAME時,可以看到重複的名字資料記錄被合併。 它指定GROUP BY減少冗餘。